当前位置:网站首页>Working ideas of stability and high availability guarantee
Working ideas of stability and high availability guarantee
2022-07-26 03:59:00 【Young】
01 Deep understanding of stability and high availability
Stability and high availability are two old words . With experience and feeling, we know , Improve these two indicators of the system , The system will be healthier , The product will also have a better user experience . But if you want to define stability and high availability, how to express it ? What is the difference and connection between stability and high availability ? I think we should first understand these two problems , To set clear goals , Systematically formulate a complete and feasible scheme .
Search Wikipedia for stability , The definition is as follows :
Stability is a mathematical or engineering term , To determine whether a system produces a bounded output at a bounded input . if , Call the system stable ; If no , The system is called unstable .
Let's look at high availability :
High availability ( English :high availability, Abbreviation for HA),IT The term , The ability of a system to perform its functions without interruption , Represents the availability of the system . It's one of the criteria for system design . High availability systems can run longer than the components that make up the system .
First, extract the key words from the definition of stability – System 、 Input 、 Output . In our current technical framework , You can think of an application as a system , Service requests between applications are input , The service response is output , When the service response meets the expectation, the application system is considered to be stable . When they combine with each other to form a larger system , When expressed to users as business products , User's request as input , Product expression as output , When the product function runs normally, it can be considered that the product system is stable . Sum up , The definition of stability can be summarized as – When the system receives input , Can produce the right 、 The expected output , Call the system stable ; otherwise , Call the system unstable .
Back to the proposition , Why stability guarantee ? Can you put it another way to improve stability ? From the above definition, we can conclude that , Stability describes the behavior of a system . Whether a system is stable , Just as we evaluate a person's health , It is difficult to describe completely in a declarative way , To quantify . But it can be judged quickly by negative way . People reduce the incidence of diseases through good diet and living habits , Keep fit . The same is true for ensuring the stability of the system or improving the stability of the system , We need various methods to avoid those unstable situations . The so-called more stable , Objectively, there is no , It is a subjective desire to avoid or reduce the occurrence of instability .
Unlike stability , Usability is a quantifiable indicator , The formula of calculation is described in Wikipedia :
According to the system damage 、 Time that can't be used , And the time from non operational to operational , Compared with the total operation time of the system .
We often hear 3 individual 9(99.9%),4 individual 9(99.99%) The measure is the availability of the system , High availability is to ensure that this index of the system is maintained at a high level . In the definition and description of the formula , The running time of the system is divided into three parts
- The normal operation time of the system , That is, the time when the system is in a stable state .
- System damage 、 Time that can't be used , That is, the time when the system is in an unstable state .
- The time when the system recovers from inoperable to operable state , That is, the time for the system to recover from unstable state to stable state .
The availability of the system is positively correlated with the stability of the system . But in real life , The system cannot always be in a stable state . Reverse thinking , Convert the above formula , More conducive to our analysis :

thus , The goal of this proposition ,KPI It's clear . The goal of ensuring the stability and high availability of the system is to keep the system in a stable working state , No negative impact on users , Avoid online problems and P The occurrence of level 1 fault . The core kpi Is the availability of the system . In order to improve the availability of the system , We should first ensure the stability of the system , Reduce the occurrence of unstable conditions , Secondly, when the system fails due to various components , When an unstable state occurs , Be able to quickly discover and restore it to a stable and available state .
02 The core idea of stability and high availability guarantee
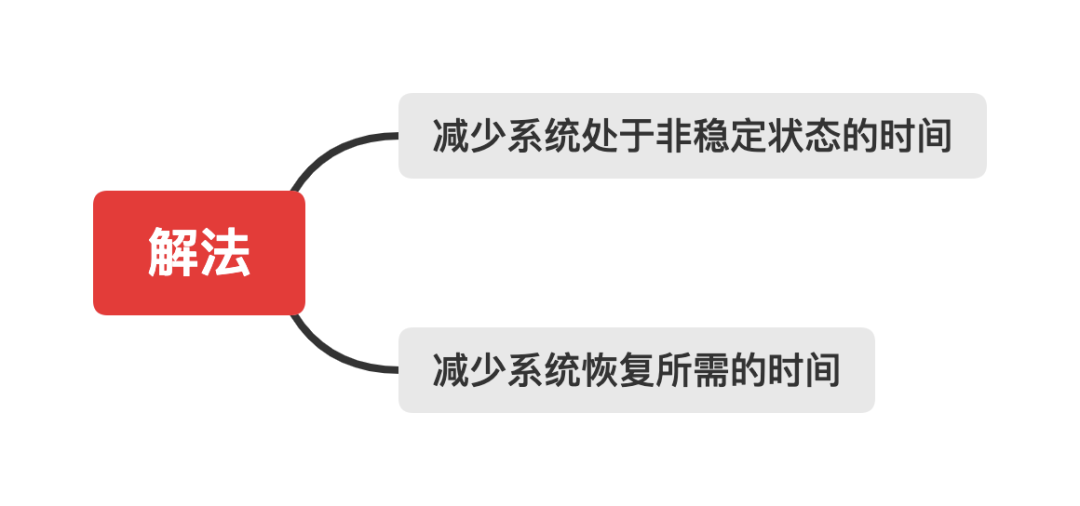
Through the deduction above , Aiming at the goal of improving system availability , We can get two basic ideas for solving problems . Take a , To solve the problem , The first task is to identify and define problems . Therefore, in order to improve the stability of the system , Let's first list the common unstable situations in application systems , Another remedy to the case :
function : An error occurred in the function performed by the application , Fall short of expectations .
Capacity : When the number of requests received by the system increases , The application cannot handle , An exception or timeout occurred , Cause service failure .
Security : When the system receives an unauthorized or malicious attack request , Application exceptions or even service failures .
Fault tolerance : For the wrong use of users , The application cannot properly handle .
When this happens , It means that the system is in an unstable state , We need to be able to find and deal with it in time . And the reasons for these problems , In software system, it can be divided into the following three categories :
Human failure : Inadequate thinking in all aspects of software development , Or various problems caused by careless execution .
Hardware failure : The Internet is not working , There's not enough space on the hard disk , Memory crash, etc .
Software failure : Thread pool exception ,JVM abnormal , Middleware or other dependent application services are abnormal .
For a dynamically evolving system , There is no way to reduce the probability of failure to 0, Only in the process of software production , Establish process specifications and mechanisms to minimize their occurrence . Secondly, for a running system , We need to establish and improve the monitoring and early warning mechanism to find the faults in the system in time , And make the system recover quickly through the implementation of the plan . Based on the above conclusion , In order to improve the availability of the system , We need to start from the following three aspects : Failure prevention , Fault discovery and recovery .

People are far more likely to make mistakes than machines , Therefore, the most important thing for fault prevention is to establish a set of mechanism , Reach a consensus within the team and continue to carry out R & D work in accordance with this process , So as to reduce personal factors ( reflection 、 perform 、 Status, etc ) Impact on system stability . And fault discovery and fault recovery , It is necessary to quickly find and recover system abnormalities through system monitoring and emergency plan , So as to minimize the impact of the fault . Let's take our daily product development process as an example , Slave function 、 Capacity 、 Security 、 Fault tolerant this 4 Starting from three core elements , A set of scheme is given for reference only .

01 R & D specifications
design phase
Team breakdown document template
High availability design specification
Encoding phase
Code specification
General code specification
Specification for engineering structures
The coverage rate of the test sheet is
- Single test pass rate
- Code coverage
Log specification
- Security vulnerability repair specification
Release stage
- Change specifications : SanBanFu
02 Capacity guarantee
Capacity assessment
- Machine capacity
- DB Capacity
- Cache capacity
Pressure measurement
Current limiting scheme
Downgrade plan
03 Monitoring alarm
Log specification
Monitoring and combing
- Application foundation monitoring
- Gateway monitoring
- Service monitoring
- Business monitoring
- Current limiting monitoring
Alarm specification
Data check
04 Emergency quick reaction
Daily plan
- Hardware exception plan
- Middleware exception plan
- Business exception plan
Big promotion plan
Implementation specification of the plan
03 summary
How to ensure stability and high availability is a huge proposition , A large number of articles can be found on the intranet for any small part of the content . The purpose of writing this article is to summarize my understanding of stability and high availability guarantee , Let's share a set of framework ideas of the system . I hope you can have a more comprehensive understanding of production safety after reading , No details .

边栏推荐
- Verilog implementation of key dithering elimination
- Wechat applet realizes music player (5)
- Save the image with gaussdb (for redis), and the recommended business can easily reduce the cost by 60%
- In PHP, you can use the abs() function to turn negative numbers into positive numbers
- File upload error: current request is not a multipart request
- 第十八章:2位a~b进制中均位奇观探索,指定整数的 3x+1 转化过程,指定区间验证角谷猜想,探求4份黑洞数,验证3位黑洞数
- Find My技术|物联网资产跟踪市场规模达66亿美元,Find My助力市场发展
- PHP method to find the location of session storage file
- php中可以使用取绝对值函数 abs() 将负数转成正数
- [MCU simulation project] external interrupt 0 controls 8 LED flashes
猜你喜欢
Realization of online shopping mall system based on JSP

Zkevm: summary of zkevm and L1 by Mina's CEO

zk-SNARK:关于私钥、环签名、ZKKSP

基于Caffe ResNet-50网络实现图片分类(仅推理)的实验复现
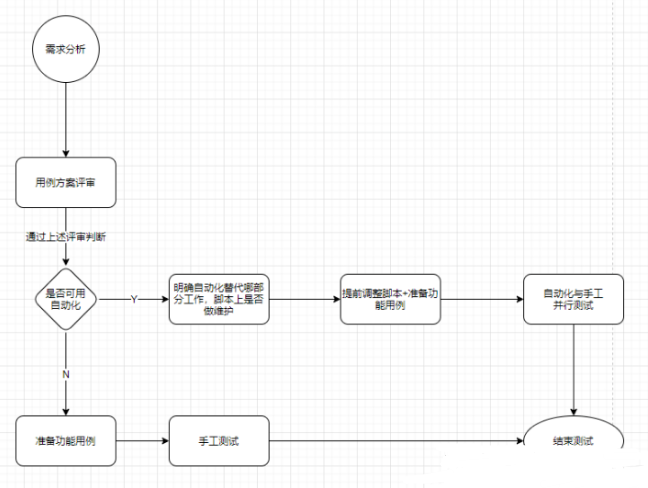
Six years of automated testing from scratch, I don't regret turning development to testing
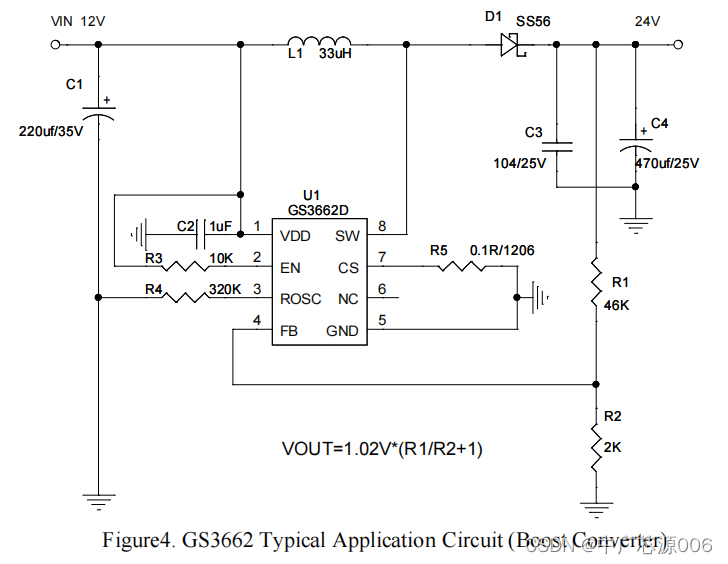
Portable power fast charging scheme 30W automatic pressure rise and fall PD fast charging

Summary of senior report development experience: understand this and do not make bad reports

Leetcode: 102. Sequence traversal of binary tree

Bond network mode configuration

研发了 5 年的时序数据库,到底要解决什么问题?
随机推荐
【单片机仿真项目】外部中断0控制8个发光二极管闪烁
E-commerce operator Xiaobai, how to get started quickly and learn data analysis?
Operator new, operator delete supplementary handouts
What is the problem of the time series database that has been developed for 5 years?
php eval() 函数可以将一个字符串当做 php 代码来运行
MySQL index failure scenarios and Solutions
基于SSM选课信息管理系统
Supervit for deep learning
Aike AI frontier promotion (7.18)
Wechat applet to realize music player (4) (use pubsubjs to realize inter page communication)
The PHP Eval () function can run a string as PHP code
通用测试用例写作规范
Save the image with gaussdb (for redis), and the recommended business can easily reduce the cost by 60%
leetcode: 102. 二叉树的层序遍历
电商运营小白,如何快速入门学习数据分析?
【程序员必备】七夕表白攻略:”月遇从云,花遇和风,晚上的夜空很美“。(附源码合集)
[create interactive dice roller application]
booking.com缤客上海面经
在 Istio 服务网格内连接外部 MySQL 数据库
Basic line chart: the most intuitive presentation of data trends and changes