当前位置:网站首页>torch单机多卡和多机多卡训练
torch单机多卡和多机多卡训练
2022-08-04 21:49:00 【爱CV】
前言 本文主要介绍单机多卡训练和多机多卡训练的实现方法和一些注意事项。其中单机多卡训练介绍两种实现方式,一种是DP方式,一种是DDP方式。多机多卡训练主要介绍两种实现方式,一种是通过horovod库,一种是DDP方式。
单机单卡训练
前面我们已经介绍了一个完整的训练流程,但这里由于要介绍单机多卡和多机多卡训练的代码,为了能更好地理解它们之间的区别,这里先放一个单机单卡也就是一般情况下的代码流程。
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_dataset = ...
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=...)
model = ...
optimizer = optim.SGD(model.parameters())
for epoch in range(opt.num_epoch):
for i, (input, target) in enumerate(train_loader):
input= input.to(device)
target = target.to(device)
...
output = model(input)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
单机多卡训练
单机多卡训练的部分有两种实现方式,一种是DP方式,一种是DDP方式。
nn.DataParallel(DP)
DP方式比较简单,仅仅通过nn.DataParallel对网络进行处理即可。
其它部分基本与单机单卡训练流程相同。
import torch
train_dataset = ...
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=...)
model = ...
model = nn.DataParallel(model.to(device), device_ids=None, output_device=None)
optimizer = optim.SGD(model.parameters())
for epoch in range(opt.num_epoch):
for i, (input, target) in enumerate(train_loader):
input= input.cuda()
target = target.cuda()
...
output = model(input)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
上面唯一关键的一句是在定义model后,使用nn.DataParallel把模型放到各个GPU上。
其中,device_dis有几种设置方式,如果设置为None, 如下几行源码所示,默认使用所有gpu
#nn.DataParallel中的源码
if device_ids is None:
device_ids = list(range(torch.cuda.device_count()))
if output_device is None:
output_device = device_ids[0
也可以手动指定用哪几个gpu。如下所示
gpus = [0, 1, 2, 3]
torch.cuda.set_device('cuda:{}'.format(gpus[0]))
model = nn.DataParallel(model.to(device), device_ids=None, output_device=gpus[0]
DDP方式
上面DP是比较简单的单机多卡的实现方式,但DDP是更高效的方式,不过实现要多几行代码。
该部分代码由读者投稿,非本人原创。
import torch
import argparse
import torch.distributed as dist
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
opt = parser.parse_args()
# 初始化GPU通信方式(NCCL)和参数的获取方式(env代表通过环境变量)。
dist.init_process_group(backend='nccl', init_method='env://')
torch.cuda.set_device(opt.local_rank)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
#使用 DistributedDataParallel 包装模型,
#它能帮助我们为不同 GPU 上求得的梯度进行 all reduce
#(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。
#all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值。
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(opt.num_epoch):
for i, (input, target) in enumerate(train_loader):
input= input.cuda()
target = target.cuda()
...
output = model(input)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
#运行命令
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 train.py
下面对这段代码进行解析。
设置local_rank参数,可以把这个参数理解为进程编号。该参数在运行上面这条指令时就会确定,每块GPU上的该参数都会不一样。
配置初始化方式,一般有tcp方式和env方式。上面是用的env,下面是用tcp方式用法。
dist.init_process_group(backend='nccl', init_method='tcp://localhost:23456'
通过local_rank来确定该进程的设备:torch.cuda.set_device(opt.local_rank)
数据加载部分我们在该教程的第一篇里介绍过,主要时通过torch.utils.data.distributed.DistributedSampler来获取每个gpu上的数据索引,每个gpu根据索引加载对应的数据,组合成一个batch,与此同时Dataloader里的shuffle必须设置为None。
多机多卡训练
多机多卡训练的一般有两种实现方式,一种是上面这个DDP方式,这里我们就不再介绍了,另一种是使用一个额外的库horovod。
Horovod
Horovod是基于Ring-AllReduce方法的深度分布式学习插件,以支持多种流行架构包括TensorFlow、Keras、PyTorch等。这样平台开发者只需要为Horovod进行配置,而不是对每个架构有不同的配置方法。
来自博客:
https://blog.csdn.net/weixin_44388679/article/details/106564349
该部分代码由读者投稿,非本人原创。
import torch
import horovod.torch as hvd
hvd.init()
torch.cuda.set_device(hvd.local_rank())
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model.cuda()
optimizer = optim.SGD(model.parameters())
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
for epoch in range(opt.num_epoch):
for i, (input, target) in enumerate(train_loader):
input= input.cuda()
target = target.cuda()
...
output = model(input)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
if hvd.rank()==0:
print("loss: ")
下面对以上代码进行简单的介绍。
与DDP相同的是,先初始化,再根据进程设置当前设备,然后使用torch.utils.data.distributed.DistributedSampler来产生每个GPU读取数据的索引。
不同的是接下来几个操作,horovod不需要使用torch.nn.parallel.DistributedDataParallel,而是通过使用horovod的两个库,通过hvd.DistributedOptimizer和hvd.broadcast_parameters分别对优化器和模型参数进行处理。
除了训练以外,其它操作基本都在主进程上完成,例如打印信息,保存模型等。通过最后if hvd.rank()==0来判定。
除了DDP和horovod这两种方式实现多机多卡以外,实际上在混合精度训练里的库apex也有对应的多机多卡训练实现方式,但这个我们就留到下一篇混合精度训练和半精度训练中来介绍。
边栏推荐
- docker 部署redis集群
- PowerCLi import license to vCenter 7
- C language knowledge (1) - overview of C language, data types
- Re24:读论文 IOT-Match Explainable Legal Case Matching via Inverse Optimal Transport-based Rationale Ext
- y87.第五章 分布式链路追踪系统 -- 分布式链路追踪系统起源(一)
- ES6高级-Promise的用法
- 【ubuntu20.04安装MySQL以及MySQL-workbench可视化工具】
- Moke, dynamic image resource package display
- 动手学深度学习_NiN
- 强网杯2022——WEB
猜你喜欢
![[Linear Algebra 02] 2 interpretations of AX=b and 5 perspectives of matrix multiplication](/img/38/764b447cf7d886500a9b99d7679cb6.png)
[Linear Algebra 02] 2 interpretations of AX=b and 5 perspectives of matrix multiplication
Android 面试——如何写一个又好又快的日志库?
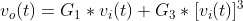
立方度量(Cubic Metric)
UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd6 in position 120: invalid continuation byte
Arduino 电机测速
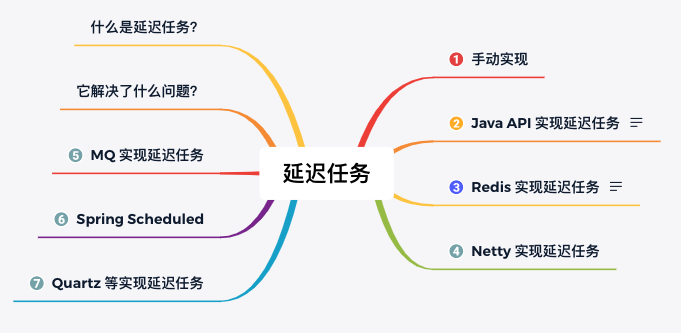
In action: 10 ways to implement delayed tasks, with code!
unity2D横版游戏教程9-对话框dialog
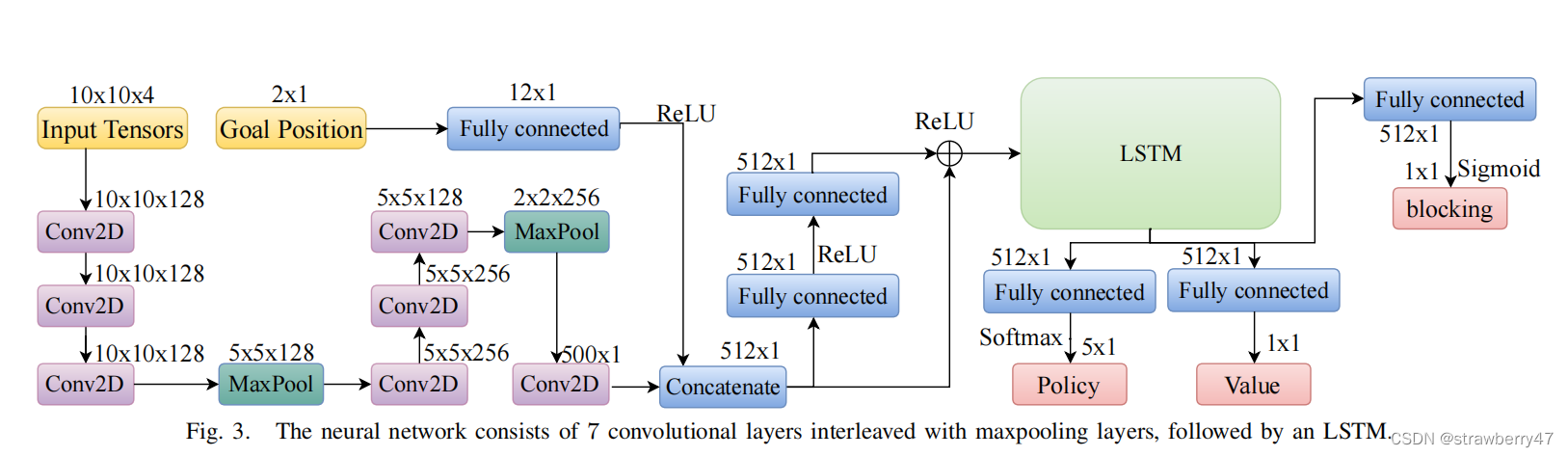
PRIMAL: Pathfinding via Reinforcement and Imitation Multi-Agent Learning Code Analysis
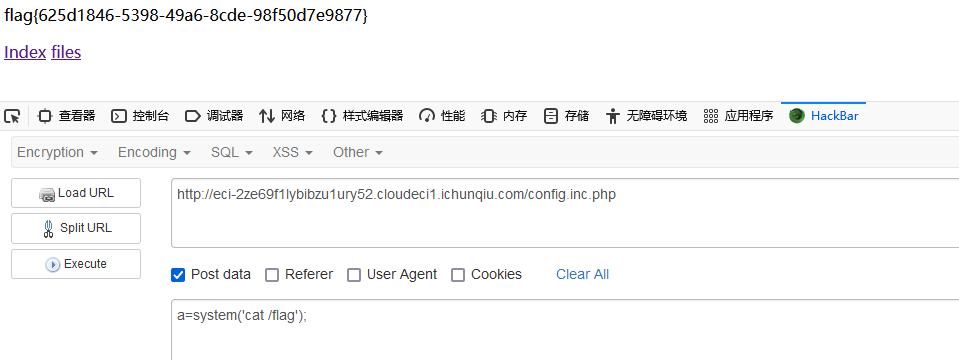
Qiangwang Cup 2022 - WEB
大势所趋之下的nft拍卖,未来艺术品的新赋能
随机推荐
多个平台显示IP属地,必须大力推行互联网实名制
开发deepstram的自定义插件,使用gst-dseaxmple插件进行扩充,实现deepstream图像输出前的预处理,实现图像自定义绘制图(精四)
stm32mp157系统移植 | 移植ST官方5.10内核到小熊派开发板
PMP证书在哪些行业有用?
Axure9基本交互操作(一)
ES6高级-Promise的用法
PCBA scheme design - kitchen voice scale chip scheme
基于 Milvus 和 ResNet50 的图像搜索(部署及应用)
Hardware factors such as CPU, memory, and graphics card also affect the performance of your deep learning model
经验分享|盘点企业进行知识管理时的困惑类型
Ramnit感染型病毒分析与处置
OC-类簇
mysql基础
热力学相关的两个定律
Unknown point cloud structure file conversion requirements
【PCBA program design】Grip dynamometer program
七夕,当爱神丘比特遇上牛郎和织女
未知点云结构文件转换需求
DGL安装教程
NFT宝典:你需要知道NFT的术语和定义