当前位置:网站首页>Develop your own text recognition application with Tesseract
Develop your own text recognition application with Tesseract
2022-08-04 21:32:00 【ReyZhang】
前言
这次和⼤Chat at home⽂Word recognition related topics.⼤At home, there must be various types of scanning APP 不陌⽣.拿着⼿camera facing any⽂字,directly into the camera⽂Word content is converted into ⼿Onboard editable strings.
完整的 OCR 算法,并不简单.It involves image recognition algorithms,as well as from Fig⽚identified in⽂Words can be converted into our program⽤的⼆进制形式.This also includes different languages⾔how to recognize characters,How to more accurately identify and so on.
设想⼀下,如果作为开发者,让你⾃⼰Develop this from scratch⼀套算法,I'm afraid it will cost a lot⼤⼒⽓.不过好消息是,我们⽣Live in this age of open source,There are many seniors who have already made the way for us.That's what we're going to talk about today, Tesseract就是这样⼀个开源库,给定任意⼀张图⽚,它可以识别出⾥⾯所有的⽂字内容,并且 API 接⼝使⽤⾮常简单.
Tesseract
Tesseract 是 Google 发布的⼀款 OCR 开源库,它⽀Holds multiple idioms⾔环境,以及运⾏环境,Including us⾥将要介绍的 iOS 环境.今天就⽤It leads⼤家开发⼀one belongs to you⾃⼰的 OCR 应⽤.
1.安装 Tesseract
最简单的⽅式是⽤过 Cocoapods,进⼊你的项⽬根⽬录,输⼊:
pod init
然后,编辑⽣成的 Podfile 配置⽂件:
target 'ocrSamples' do
use_frameworks!
pod 'TesseractOCRiOS'
end
将TesseractOCRiOS加⼊配置列表中,最后输⼊:
pod install
2,.配置⼯作
安装完成后,我们还需要进⾏⼀Simple configuration below,⾸先要在 Build Phases -> Link Binary With Libraries 中配置,项⽬需要的依赖库, CoreImage, libstdc++, 以及 TesseractOCRiOS ⾃⾝:
After configuring the dependency library,我们还需要将⽂Word recognition training data添加进来,What is the training data,TesseractOCRiOS识别图⽚的时候,It will be recognized according to the rules of this training data⽂字.⽐如中⽂,英⽂等,都有对应的训练数据,This can be understood as deep learning pre-trained models for us.⽤它来进⾏核⼼的识别算法.
Training data is required to follow不同语言来区分的,Tesseract There is a dedicated page listing all available training data:https://github.com/tesseract-ocr/tessdata/tree/3.04.00
For example, we need to recognize Simplified Chinese here,就可以下载 chi-sim this training data:

Then drag and drop the training data into ⼯程中: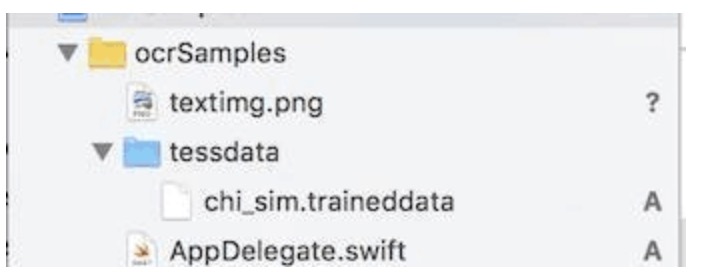
上图中的 chi_sim.traineddata is the training data we downloaded,这⾥⾯有⼀The point to note is that,这个⽂item must be present testdata 这个⽂件夹中.并且这个⽂folder to start with "Create Folder Reference" 的⽅drag and drop in:
This citation⽤⽅formula and other⼀种 "Create Groups" 的⽅What's the difference?
主要区别在于:
- 使⽤
引⽤⽅式Drag and drop in⽬录,在最后⽣成 APP 包的时候,Main Bunlde中是以testdata/chi_sim.traineddataThis path form saves our training data resources - 使⽤
"Create Groups"⽅式,It will be when it is finally stored忽略⽂Folder name的,最后存储在Main Bundle中的⽂件是以/chi_sim.traineddatastored in this path.
注意: ⽽ TesseractOCRiOS,By default it will be there testdata/chi_sim.traineddata This path looks for training data,所以如果使⽤"Create Groups" ⽅drag⼊,will cause luck⾏No training data was found,⽽报错.This detail requires special attention.
最后, 为了让 TesseractOCRiOS can be shipped correctly⾏,We also need to turn off BitCode,否则会报编译错误,We need to turn it off in both places,⼀个是⾄⼯程,另外⼀个是 Pods 模块,如下图: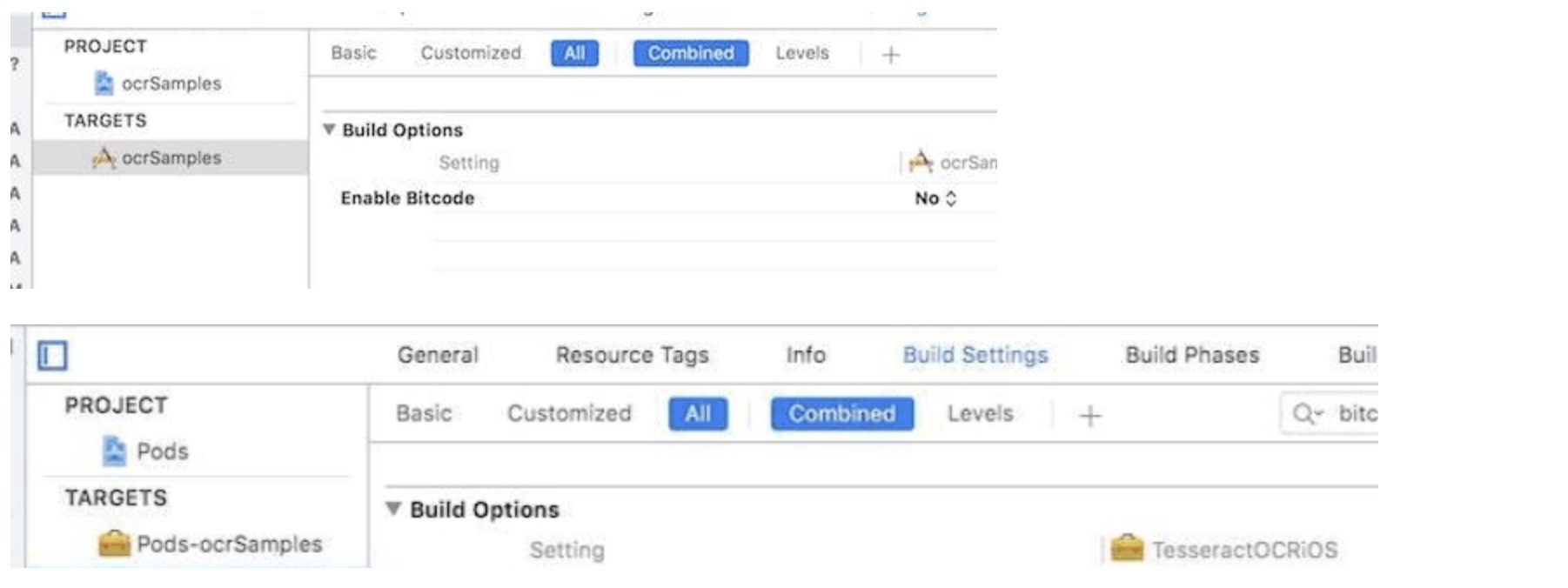
3. 开始编码
Complete the above preparations⼯作后,我们就可以开始编码了,这⾥只给⼤Home Show⽰最精简的代码.⾸First we need to be in the main world⾯上显⽰两个控件,⼀One is our pre-stored band⽂photo of words⽚,另外⼀个是⽤于展⽰识别结果的⽂本框:
override func viewDidLoad() {
super.viewDidLoad()
self.imageView = UIImageView(frame: CGRect(x: 0, y: 80, width: self.view.frame.size.width, height:
self.view.frame.size.width * 0.7))
self.imageView?.image = UIImage(named: "textimg")
self.view.addSubview( self.imageView!)
self.textView = UITextView(frame: CGRect(x: 0, y: labelResult.frame.origin.y + labelResult.frame.size.height + 20, width: self.view.frame.size.width, height: 200))
self.view.addSubview( self.textView!)
}
这⾥⾯We only write out the key code for initialization of the two controls,Other unimportant codes are omitted.Then you can tune⽤ TesseractOCRiOS 来进⾏⽂word recognized:
func recognizeText(image: UIImage) {
if let tesseract= G8Tesseract(language: "chi_sim") {
tesseract. engineMode= .tesseractOnly
tesseract. pageSegmentationMode= .auto
tesseract. image= image
tesseract.recognize()
self.textView?. text= tesseract.recognizedText
}
}
All identification related code is here⾥了.⾸先调⽤ G8Tesseract 进⾏初始化,我们传⼊The name of the training data,这⾥是 "chi_sim"Represents Simplified Chinese⽂.
engineModeThere are three modes to choose from, tesseractOnly,tesseractCubeCombined 和 cubeOnly.我们使⽤第⼀种模式,采⽤训练数据的⽅式. cubeOnly Consciousness is to make⽤更精准的 cube ⽅式, tesseractCubeCombined It is a combination of the two modes⽤.
cube Schema requires additional model data,⼤The example is this:
The picture above is in English⽂的 cube 识别模型.简体中⽂I haven't found the model yet,So we just in this instance⽤到了 tesseractOnly 模式.并且在没有 cube in the case of model data,我们是不⽤使⽤ tesseractCubeCombined 和 cubeOnly 的,Otherwise it will be because the model data does not exist⽽报错.⼤Home if you can find it⽂的 cube 模型,You are also welcome to stay⾔中反馈,This will make this⽂Word recognition is more accurate.
other tones⽤No need to say more,will be identified image 对象设置给 Tesseract.然后调⽤它的 recognize ⽅法进⾏识别,Finally the result will be identified tesseract.recognizedText 设置给 TextView.
Final luck⾏效果如下:
上⾯的图⽚I took it SwiftCafe ⽹站上⼀篇⽂Chapter photo⽚,from the identification results,还算⽐较准确.
总结
⼤Home from above⾯The code should also feel it, Tesseract Although provided essentially counts⽐较复杂的⽂Word recognition algorithm,But it provides access to developers⼝可以说得上是⾮常简单. OCR ⽂Word recognition as a whole,也可以算得上是 AI 的⼀个应⽤分⽀,在这个 AI ⼤⾏its time,即便掌握⼀些应⽤技术,It can also be very good for us developers⼤to broaden our horizons.发挥你的创意,也许类似Tesseract These components can help you create AI A newcomer of the times⽤.
Tesseract These components can help you create AI A newcomer of the times⽤.
当然, Tesseract ⽬前⾃⾝还有⼀些缺陷,⽐as it isOnly prints are recognized字体,⽽cannot be accurately identified⼿write font.But that⼜怎么样呢,It would have been quite complicated OCR 算法,可以让我们⽤⾮Often a small price should be paid⽤起来,还是⼀piece to the developer⾮A very happy thing.
照例,The sample project code in this article has been placed Github 中,You can download it directly if you need it:https://github.com/swiftcafex/Samples/tree/master/ocrSamples.
边栏推荐
- 【SQL之降龙十八掌】01——亢龙有悔:入门10题
- dotnet delete read-only files
- [2022 Hangzhou Electric Multi-School 5 1003 Slipper] Multiple Super Source Points + Shortest Path
- [Teach you to use the serial port idle interrupt of the STM32HAL library]
- DSPE-PEG-Aldehyde,DSPE-PEG-CHO,磷脂-聚乙二醇-醛基一种疏水18碳磷脂
- 【ubuntu20.04安装MySQL以及MySQL-workbench可视化工具】
- ini怎么使用? C#教程
- JdbcTemplate概述和测试
- 零基础都能拿捏的七夕浪漫代码,快去表白或去制造惊喜吧
- 如何将二叉搜索树转化为一个有序的双向链表(原树上修改)
猜你喜欢

随机推荐
Data warehouse (1) What is data warehouse and what are the characteristics of data warehouse
PMP证书在哪些行业有用?
dotnet 使用 lz4net 压缩 Stream 或文件
基于 Milvus 和 ResNet50 的图像搜索(部署及应用)
Win11如何设置软件快捷方式?
visual studio 2015 warning MSB3246
LayaBox---TypeScript---Example
如何一键重装Win11系统 一键重装系统方法
如何一键重装win7系统?重装win7系统详细教程
数电快速入门(五)(编码器的介绍以及通用编码器74LS148和74LS147的介绍)
DSPE-PEG-Aldehyde,DSPE-PEG-CHO,磷脂-聚乙二醇-醛基一种疏水18碳磷脂
Spss-一元回归实操
C语言知识大全(一)——C语言概述,数据类型
如何最简单、通俗地理解爬虫的Scrapy框架?
JdbcTemplate概述和测试
动手学深度学习_NiN
dotnet enables JIT multi-core compilation to improve startup performance
dotnet 删除只读文件
js数据类型、节流/防抖、点击事件委派优化、过渡动画
如何根据“前序遍历,中序遍历”,“中序遍历,后序遍历”构建按二叉树