当前位置:网站首页>【广告系统】增量训练 & 特征准入/特征淘汰
【广告系统】增量训练 & 特征准入/特征淘汰
2022-07-05 10:37:00 【CC‘s World】
一、增量训练
有时候训练数据是很多的,几十万几百万也是常有的事。虽然几十万几百万只看记录数不算多,但是如果有几百个特征呢,那数据集是很恐怖的,如果存成numpy.float类型,那绝对是把内存吃爆。我就是在这种情况下,开始考虑增量模型的增量训练。
在超大数据集上,一般有这么几种方法:1. 对数据进行降维,2. 增量训练,使用流式或类似流式处理,3. 上大机器,高内存的,或者用spark集群。
增量训练,其实和在线学习是一个意思,在线学习的典型代表是用SGD优化的logistics regress,先用数据初始化参数,线上来一个数据更新一次参数,虽然时间的推移,效果越来越好。这样就避免了离线更新模型的问题。
增量训练主要有两个作用,一个是想办法利用全部的数据,另一个是想办法及时利用新的数据。可以提高模型的时效性、样本容量和节省集群资源。
推荐场景通常由于引入了大量的ID类特征从而导致存在海量稀疏参数,例如在经典YouTube DNN模型中,使用用户观看过的视频以及用户历史search tokens作为主要Embedded特征。根据论文中论述,YouTube DNN中candidate video以及search tokens均有百万之巨。在此基础上如果再使用交叉特征,就会使参数爆炸问题进一步加剧。
推荐场景低频的ID类特征同样会给系统带来过拟合的风险,针对这个问题,我们设计了特征准入/退出机制策略,方便根据具体模型预设的表达能力,调整低频稀疏参数对模型的影响。
二、特征准入
商业场景中,时时刻刻都会有新的样本产生,新的样本带来新的特征。有一些特征出现频次较低,如果全部加入到模型中,一方面对内存来说是个挑战,另外一方面,低频特征会带来过拟合。因此会制定一些特征准入机制,包括基于概率进行过滤,布隆过滤器等。
训练框架会对新特征设置特征准入的“门槛”来防止低频特征频繁的出入。我们提供了两种机制来限定新增特征准入:
- 概率新增,每次遇到新增特征时,根据预设分布生成概率,控制特征准入;
- 使用Counting Bloom Filter对新增特征出现次数进行统计,当次数超过阈值时,准入。
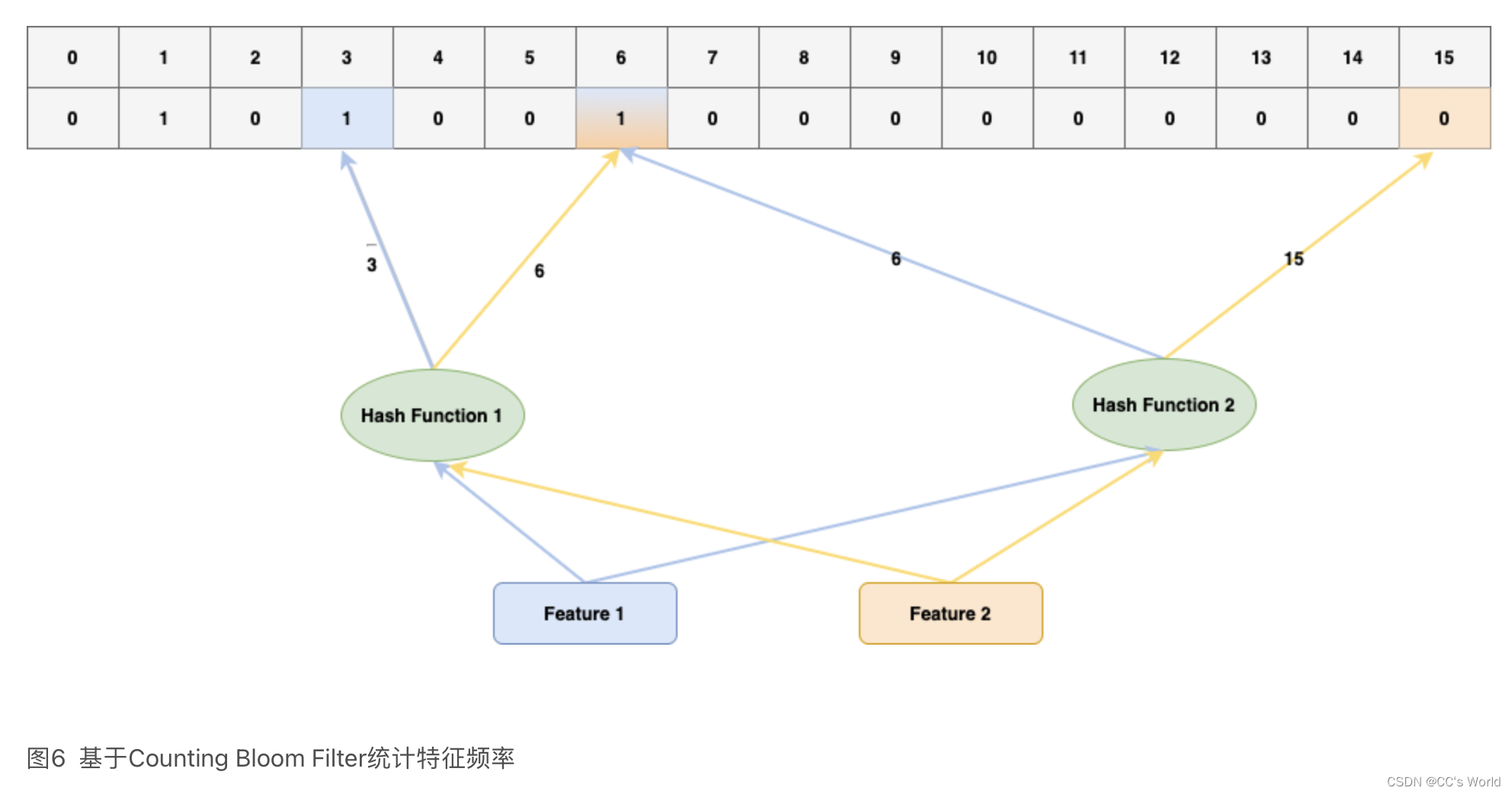
上图简要描述了CBF的原理,假设容量是16,两个hash函数用作Feature ID到Index的映射。查询特征频率时,Feature1经过Hash Function1和 Hash Function2分别得到Slot 3和 Slot 6,两个Slot值均为1,Feature出现次数可以认为是1。Feature2经过Hash Function1和 Hash Function2分别得到Slot 6和 Slot 15。两个Slot值分别为1和0,Feature2出现次数可以认为是0。即映射到所有Slot中 Value最小值。

三、特征淘汰
有一些特征长时间不更新会失效。为了缓解内存压力,提高模型的时效性,需要淘汰过时的特征,制定淘汰规则。
对于已经准入的特征,提供以下三种方式判断是否处于低频状态:
- 更新时间。如果一个特征长时间没有被更新,认为已经处于低频状态;
- L2范数。如果一个特征L2范数计算结果过小,认为已经处于低频状态;
- 统计值综合得分。支持用户提供自定义函数,通过特征统计值(曝光数,点击数,点赞数,评论数等)来计算特征综合分数,分数小于阈值认为处于低频状态。
被判定处于低频状态的特征会被淘汰屏蔽,下次再次出现时会被当做新特征对待。

使用特征准入&退出后,推荐模型普遍能够减少到未使用时四分之一大小,线上预测AUC在千分位保持持平。
参考资料
边栏推荐
- 【js学习笔记五十四】BFC方式
- Bidirectional RNN and stacked bidirectional RNN
- iframe
- 谈谈对Flink框架中容错机制及状态的一致性的理解
- Network security of secondary vocational group 2021 Jiangsu provincial competition 5 sets of topics environment + analysis of all necessary private messages I
- Go项目实战—参数绑定,类型转换
- SqlServer定时备份数据库和定时杀死数据库死锁解决
- Explanation of message passing in DGL
- Node の MongoDB Driver
- 关于vray 5.2的使用(自研笔记)(二)
猜你喜欢

2022年危险化学品生产单位安全生产管理人员特种作业证考试题库模拟考试平台操作
Some understandings of heterogeneous graphs in DGL and the usage of heterogeneous graph convolution heterographconv

Web3基金会「Grant计划」赋能开发者,盘点四大成功项目

Broyage · fusion | savoir que le site officiel de chuangyu mobile end est en ligne et commencer le voyage de sécurité numérique!

The first product of Sepp power battery was officially launched
Honing · fusion | know that the official website of Chuangyu mobile terminal is newly launched, and start the journey of digital security!

About the use of Vray 5.2 (self research notes)

第五届 Polkadot Hackathon 创业大赛全程回顾,获胜项目揭秘!

2022鹏城杯web
小红书自研KV存储架构如何实现万亿量级存储与跨云多活
随机推荐
uniapp
Web3基金会「Grant计划」赋能开发者,盘点四大成功项目
dsPIC33EP 时钟初始化程序
基于昇腾AI丨以萨技术推出视频图像全目标结构化解决方案,达到业界领先水平
Taro advanced
Blockbuster: the domestic IDE is released, developed by Alibaba, and is completely open source!
Crawler (9) - scrape framework (1) | scrape asynchronous web crawler framework
web安全
Web Security
Nuxt//
上拉加载原理
数据库中的范式:第一范式,第二范式,第三范式
重磅:国产IDE发布,由阿里研发,完全开源!
go语言学习笔记-初识Go语言
Nuxt//
Honing · fusion | know that the official website of Chuangyu mobile terminal is newly launched, and start the journey of digital security!
关于 “原型” 的那些事你真的理解了吗?【上篇】
数据类型 ntext 和 varchar 在not equal to 运算符中不兼容 -九五小庞
Cross page communication
Go语言-1-开发环境配置