当前位置:网站首页>LSTM applied to MNIST dataset classification (compared with CNN)
LSTM applied to MNIST dataset classification (compared with CNN)
2022-07-05 10:49:00 【Don't wait for shy brother to develop】
LSTM be applied to MNIST Data set classification
1、 summary
LSTM Networks are sequential models , Generally, it is more suitable for dealing with sequence problems . Here it is used for the classification of handwritten digital pictures , In fact, it is equivalent to treating pictures as sequences .
a sheet MNIST The picture of the dataset is 28 × 28 28\times 28 28×28 Size , We can think of each line as a sequence input , So a picture is 28 That's ok , The sequence length is 28; Every line has 28 Data , Each sequence input 28 It's worth .
Here we can LSTM and CNN Compare the code results of .
2、LSTM Realization
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM,Dropout
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
2.1 Loading data sets
# Loading data sets
mnist = tf.keras.datasets.mnist
# Load data , The training set and test set have been divided when the data is loaded
# Training set data x_train The data shape of is (60000,28,28)
# Training set label y_train The data shape of is (60000)
# Test set data x_test The data shape of is (10000,28,28)
# Test set label y_test The data shape of is (10000)
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Normalize the data of training set and test set , It helps to improve the training speed of the model
x_train, x_test = x_train / 255.0, x_test / 255.0
# Turn the labels of training set and test set into single hot code
y_train = tf.keras.utils.to_categorical(y_train,num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test,num_classes=10)
# data size - The line has 28 Pixel
input_size = 28
# Sequence length - Altogether 28 That's ok
time_steps = 28
# Hidden layer memory block Number
cell_size = 50
2.2 Creating models
# Creating models
# The data input of the recurrent neural network must be 3 D data
# The data format is ( Number of data , Sequence length , data size )
# Loaded mnist The format of the data just meets the requirements
# Notice the input_shape There is no need to set the quantity of data when setting the model data input
model = Sequential([
LSTM(units=cell_size,input_shape=(time_steps,input_size),return_sequences=True),
Dropout(0.2),
LSTM(cell_size),
Dropout(0.2),
# 50 individual memory block Output 50 Value and output layer 10 Neurons are fully connected
Dense(10,activation=tf.keras.activations.softmax)
])
2.3 Define optimizer
adam = Adam(lr=1e-3)
2.4 Compile model
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
2.5 Training models
history=model.fit(x_train,y_train,batch_size=64,epochs=10,validation_data=(x_test,y_test))
2.6 Print model summary
model.summary()
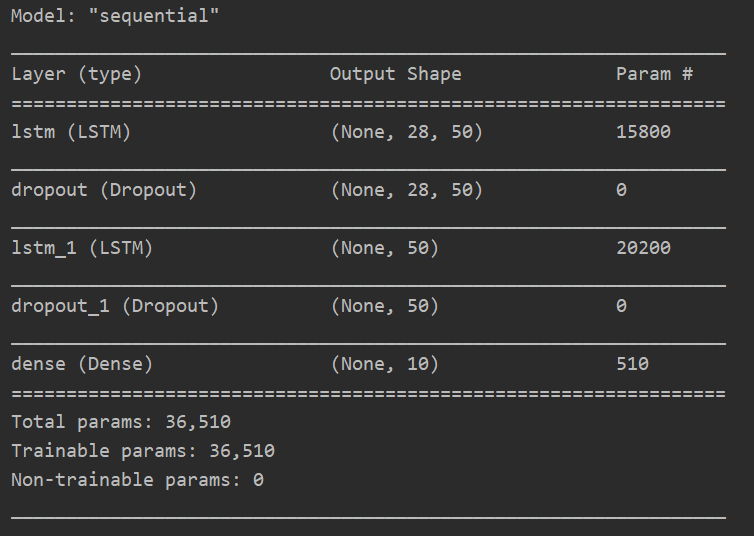
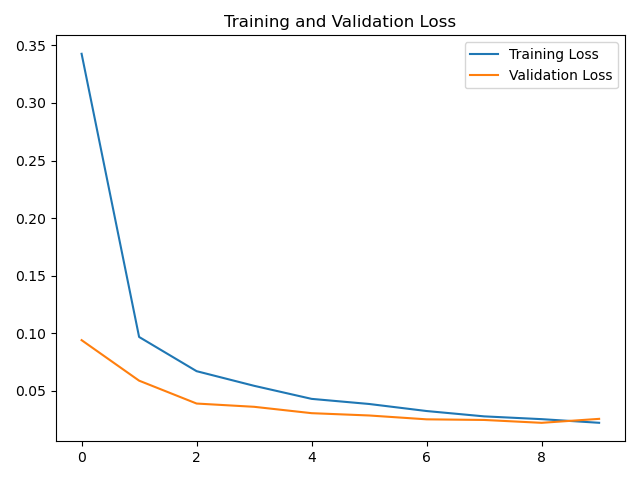
2.7 draw acc and loss curve
loss=history.history['loss']
val_loss=history.history['val_loss']
accuracy=history.history['accuracy']
val_accuracy=history.history['val_accuracy']
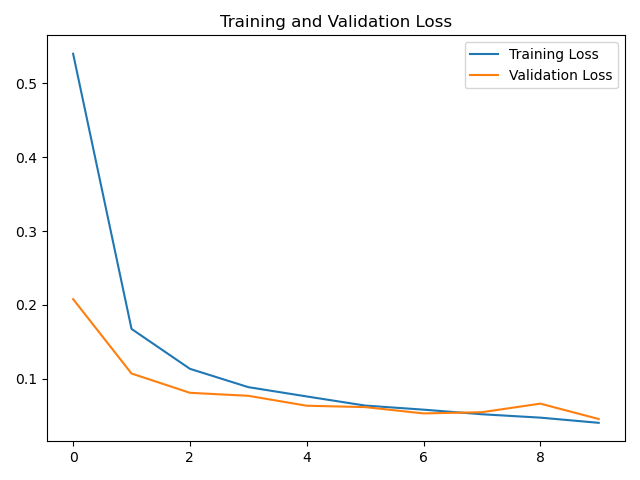
# draw loss curve
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
# draw acc curve
plt.plot(accuracy, label='Training accuracy')
plt.plot(val_accuracy, label='Validation accuracy')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
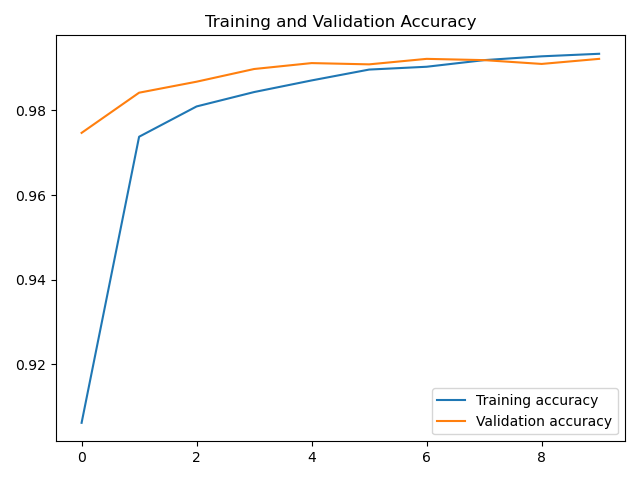

LSTM be applied to MNIST Data recognition can also get good results , But of course, the result is not as good as that of convolutional neural network .
3、CNN Realization
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Convolution2D,MaxPooling2D,Flatten
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
# Load data
mnist = tf.keras.datasets.mnist
# Load data , The training set and test set have been divided when the data is loaded
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Pay attention here , stay tensorflow in , When doing convolution, you need to turn the data into 4 Dimension format
# this 4 The dimensions are ( Number of data , Picture height , Image width , Number of picture channels )
# So here's the data reshape become 4 D data , The number of channels for black-and-white pictures is 1, The number of color picture channels is 3
x_train = x_train.reshape(-1,28,28,1)/255.0
x_test = x_test.reshape(-1,28,28,1)/255.0
# Turn the labels of training set and test set into single hot code
y_train = tf.keras.utils.to_categorical(y_train,num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test,num_classes=10)
# Define sequential model
model = Sequential()
# The first convolution layer
# input_shape input data
# filters Number of filters 32, Generate 32 A feature map
# kernel_size Convolution window size 5*5
# strides step 1
# padding padding The way same/valid
# activation Activation function
model.add(Convolution2D(
input_shape = (28,28,1),
filters = 32,
kernel_size = 5,
strides = 1,
padding = 'same',
activation = 'relu'
))
# The first pool
# pool_size Pool window size 2*2
# strides step 2
# padding padding The way same/valid
model.add(MaxPooling2D(pool_size = 2,strides = 2,padding = 'same'))
# Second convolution layer
# filters Number of filters 64, Generate 64 A feature map
# kernel_size Convolution window size 5*5
# strides step 1
# padding padding The way same/valid
# activation Activation function
model.add(Convolution2D(64,5,strides=1,padding='same',activation='relu'))
# The second pooling layer
# pool_size Pool window size 2*2
# strides step 2
# padding padding The way same/valid
model.add(MaxPooling2D(2,2,'same'))
# Flatten the output of the second pooling layer
# Is equivalent to (64,7,7,64) data ->(64,7*7*64)
model.add(Flatten())
# The first full connection layer
model.add(Dense(1024,activation = 'relu'))
# Dropout
model.add(Dropout(0.5))
# The second full connection layer
model.add(Dense(10,activation='softmax'))
# Define optimizer
adam = Adam(lr=1e-4)
# Define optimizer ,loss function, The accuracy of calculation during training
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
# Training models
history=model.fit(x_train,y_train,batch_size=64,epochs=10,validation_data=(x_test, y_test))
# Save the model
model.save('mnist_cnn.h5')
# Print model summary
model.summary()
loss=history.history['loss']
val_loss=history.history['val_loss']
accuracy=history.history['accuracy']
val_accuracy=history.history['val_accuracy']
# draw loss curve
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
# draw acc curve
plt.plot(accuracy, label='Training accuracy')
plt.plot(val_accuracy, label='Validation accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()
Model summary
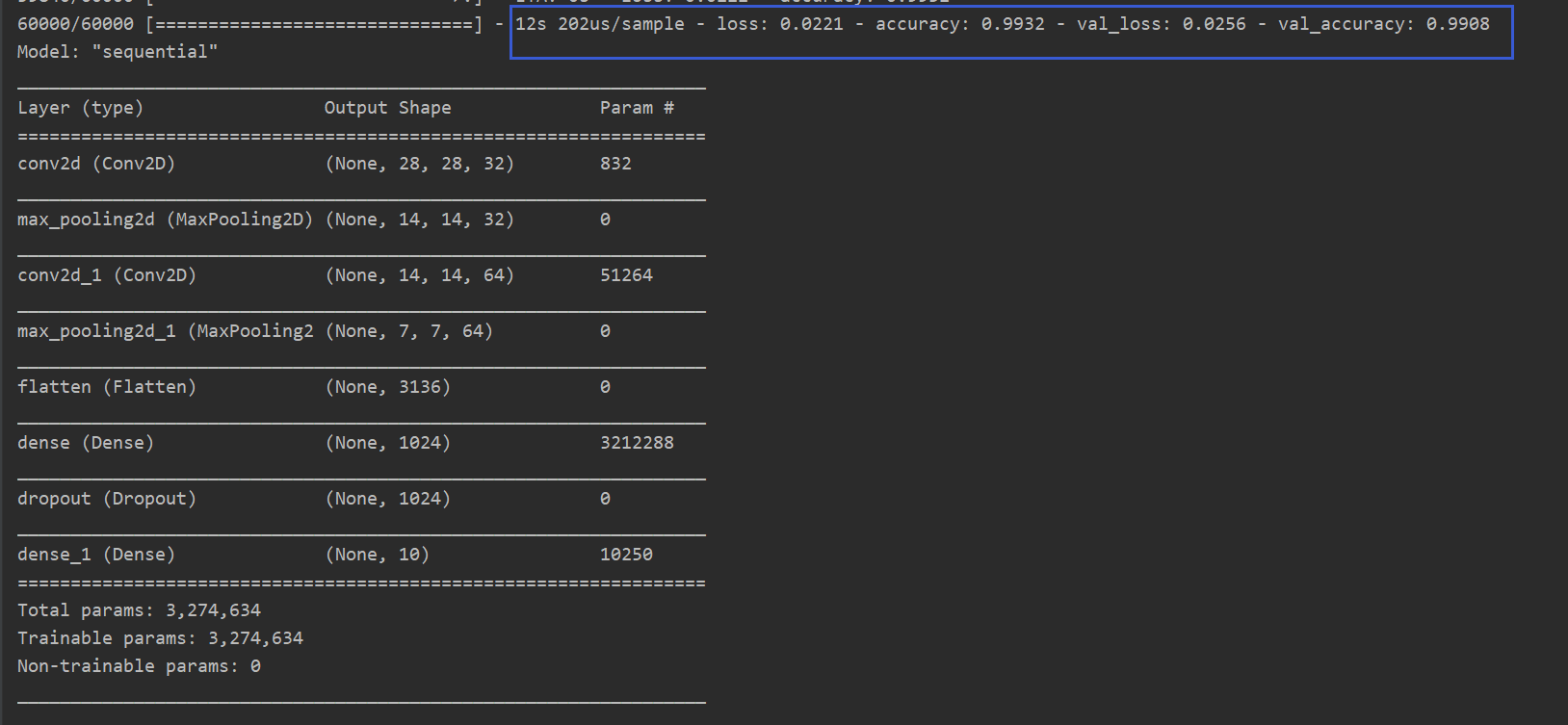
loss curve
acc curve
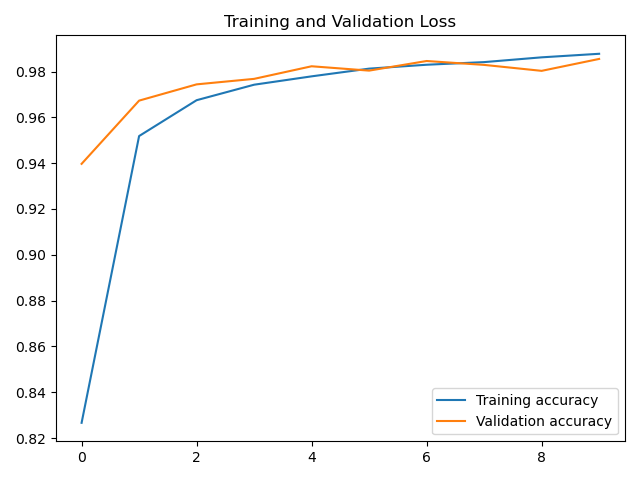
From the results ,CNN Do than LSTM More suitable for MNIST Classification of data sets .
边栏推荐
- Buried point 111
- 脚手架开发基础
- 函数///
- dsPIC33EP 时钟初始化程序
- Implement the rising edge in C #, and simulate the PLC environment to verify the difference between if statement using the rising edge and not using the rising edge
- TSQL–标示列、GUID 、序列
- 埋点111
- 小红书自研KV存储架构如何实现万亿量级存储与跨云多活
- Network security of secondary vocational group 2021 Jiangsu provincial competition 5 sets of topics environment + analysis of all necessary private messages I
- Go-3-the first go program
猜你喜欢

赛克瑞浦动力电池首台产品正式下线
【DNS】“Can‘t resolve host“ as non-root user, but works fine as root

csdn软件测试入门的测试基本流程

Go-3-第一个Go程序
![[vite] 1371 - develop vite plug-ins by hand](/img/7f/84bba39965b4116f20b1cf8211f70a.png)
[vite] 1371 - develop vite plug-ins by hand

Pseudo class elements -- before and after
Learning Note 6 - satellite positioning technology (Part 1)

Go语言-1-开发环境配置
"Everyday Mathematics" serial 58: February 27
go语言学习笔记-初识Go语言
随机推荐
【SWT组件】内容滚动组件 ScrolledComposite
使用GBase 8c数据库过程中报错:80000502,Cluster:%s is busy,是怎么回事?
vite//
关于vray5.2怎么关闭日志窗口
Web Components
Customize the left sliding button in the line in the applet, which is similar to the QQ and Wx message interface
iframe
Web Components
变量///
小红书自研KV存储架构如何实现万亿量级存储与跨云多活
微信小程序触底加载与下拉刷新的实现
正则表达式
【JS】提取字符串中的分数,汇总后算出平均分,并与每个分数比较,输出
赛克瑞浦动力电池首台产品正式下线
Web3 Foundation grant program empowers developers to review four successful projects
Golang应用专题 - channel
GO项目实战 — Gorm格式化时间字段
Cross page communication
Completion report of communication software development and Application
[paper reading] kgat: knowledge graph attention network for recommendation