当前位置:网站首页>Spark Tuning (III): persistence reduces secondary queries
Spark Tuning (III): persistence reduces secondary queries
2022-07-07 16:28:00 【InfoQ】
1. cause
2. Optimization starts
df = sc.sql(sql)
df1 = df.persist()
df1.createOrReplaceTempView(temp_table_name)
subdf = sc.sql(select * from temp_table_name)
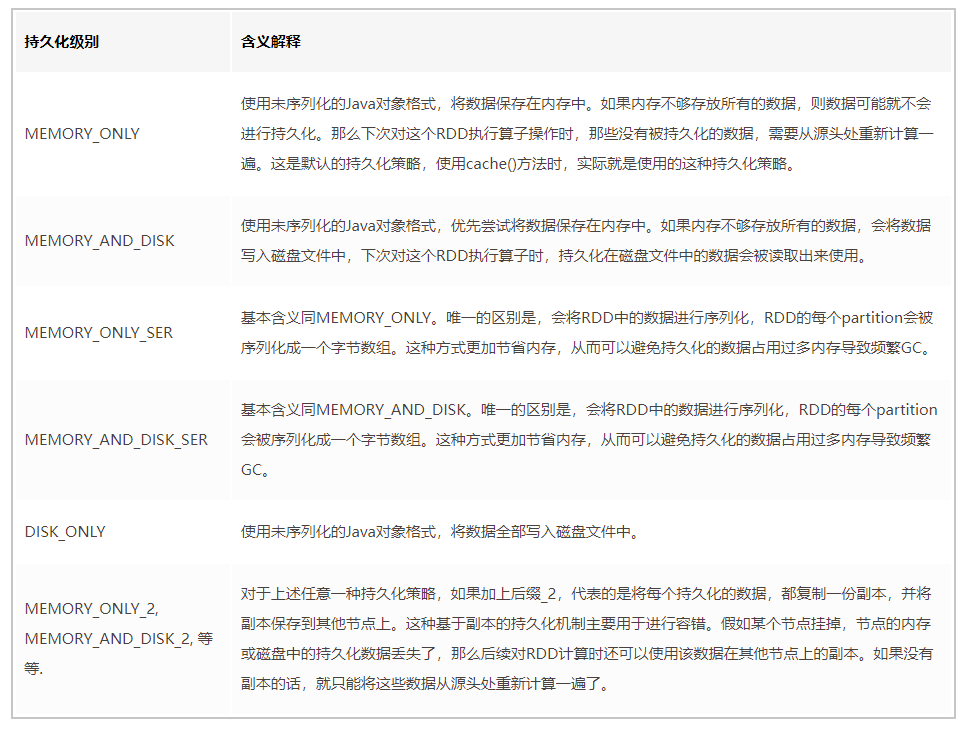
- By default , Of course, the highest performance is MEMORY_ONLY, But only if you have enough memory , More than enough to store the whole RDD All data for . Because there is no serialization or deserialization , This part of the performance overhead is avoided ; For this RDD The subsequent operator operations of , All operations are based on data in pure memory , There is no need to read data from the disk file , High performance ; And there's no need to make a copy of the data , And remote transmission to other nodes . But what we have to pay attention to here is , In the actual production environment , I'm afraid there are limited scenarios where this strategy can be used directly , If RDD When there are more data in ( For example, billions ), Use this persistence level directly , It can lead to JVM Of OOM Memory overflow exception .
- If you use MEMORY_ONLY Memory overflow at level , So it is recommended to try to use MEMORY_ONLY_SER Level . This level will RDD Data is serialized and stored in memory , At this point, each of them partition It's just an array of bytes , It greatly reduces the number of objects , And reduce the memory consumption . This is a level ratio MEMORY_ONLY Extra performance overhead , The main thing is the cost of serialization and deserialization . But subsequent operators can operate based on pure memory , So the overall performance is relatively high . Besides , The possible problems are the same as above , If RDD If there is too much data in , Or it may lead to OOM Memory overflow exception .
- If the level of pure memory is not available , Then it is recommended to use MEMORY_AND_DISK_SER Strategy , instead of MEMORY_AND_DISK Strategy . Because now that it's this step , Just explain RDD A lot of data , Memory can't be completely down . The serialized data is less , Can save memory and disk space overhead . At the same time, this strategy will try to cache data in memory as much as possible , Write to disk if memory cache is not available .
- It is generally not recommended to use DISK_ONLY And suffixes are _2 The level of : Because the data is read and write based on the disk file , Can cause a dramatic performance degradation , Sometimes it's better to recalculate all RDD. The suffix is _2 The level of , All data must be copied in one copy , And send it to other nodes , Data replication and network transmission will lead to large performance overhead , Unless high availability of the job is required , Otherwise, it is not recommended to use .
Conclusion
边栏推荐
- laravel中将session由文件保存改为数据库保存
- "The" "PIP" "entry cannot be recognized as the name of a cmdlet, function, script file, or runnable program."
- Bidding announcement: Fujian Rural Credit Union database audit system procurement project (re bidding)
- laravel 是怎么做到运行 composer dump-autoload 不清空 classmap 映射关系的呢?
- The inevitable trend of the intelligent development of ankerui power grid is that microcomputer protection devices are used in power systems
- The differences between exit, exit (0), exit (1), exit ('0 '), exit ('1'), die and return in PHP
- 分步式监控平台zabbix
- 无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称
- logback.xml配置不同级别日志,设置彩色输出
- Unity3d click events added to 3D objects in the scene
猜你喜欢
Logback日志框架第三方jar包 免费获取

1亿单身男女“在线相亲”,撑起130亿IPO

You Yuxi, coming!
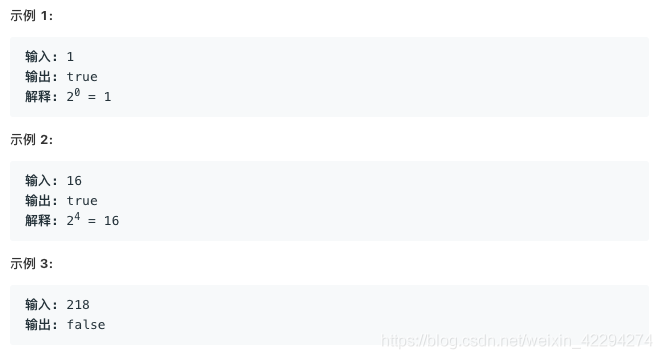
Power of leetcode-231-2
![[flower carving experience] 15 try to build the Arduino development environment of beetle esp32 C3](/img/8f/ca9ab042916f68de7994d9f2124da9.jpg)
[flower carving experience] 15 try to build the Arduino development environment of beetle esp32 C3

企业级日志分析系统ELK
Mysql database basic operation DQL basic query

无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称

Apache Doris just "graduated": why should we pay attention to this kind of SQL data warehouse?
平衡二叉树(AVL)
随机推荐
121. The best time to buy and sell stocks
01tire+ chain forward star +dfs+ greedy exercise one
PHP has its own filtering and escape functions
Limit of total fields [1000] in index has been exceeded
php 自带过滤和转义函数
Laravel changed the session from file saving to database saving
深度之眼(六)——矩阵的逆(附:logistic模型一些想法)
深度之眼(七)——矩阵的初等变换(附:数模一些模型的解释)
hellogolang
记录Servlet学习时的一次乱码
Good news! Kelan sundb database and Hongshu technology privacy data protection management software complete compatibility adaptation
leetcode 241. Different Ways to Add Parentheses 为运算表达式设计优先级(中等)
1亿单身男女“在线相亲”,撑起130亿IPO
Power of leetcode-231-2
Plate - forme de surveillance par étapes zabbix
Unity的三种单例模式(饿汉,懒汉,MonoBehaviour)
Laravel post shows an exception when submitting data
SPI master rx time out中断
[hcsd celebrity live broadcast] teach the interview tips of big companies in person - brief notes
Balanced binary tree (AVL)