当前位置:网站首页>Statistical learning method -- perceptron
Statistical learning method -- perceptron
2022-07-07 16:14:00 【_ Spring_】
Catalog
Perceptron is one of the most basic models of machine learning , It's the basis of neural networks and support vector machines .
Keywords of perceptron
- Two classification
- Discriminant model 、 Linear model
- Data sets are linearly separable , There are infinitely many solutions
- Unable to resolve XOR problem
The principle of perceptron
The perceptron is based on the feature vector of the data instance x A linear classification model for its second class classification , Output is +1 or -1. The function of the perceptron is :
f ( x ) = s i g n ( w ⋅ x + b ) f(x)=sign(w·x+b) f(x)=sign(w⋅x+b)
among w w w Is the weight , b b b It's bias , w ⋅ x w·x w⋅x yes w w w and x x x Inner product , s i g n sign sign It's a symbolic function , namely ,
s i g n ( x ) = { + 1 x ≥ 0 − 1 x < 0 sign(x) = \begin{cases} +1 & x\ge 0\\ -1 & x <0 \end{cases} sign(x)={ +1−1x≥0x<0When wx+b Greater than 0 when , according to sign function , Output is 1, Corresponding to positive class ; When wx+b Less than 0, Output is -1, Corresponding negative class .Geometric interpretation of perceptron : linear equation w ⋅ x + b = 0 w·x+b=0 w⋅x+b=0 Corresponding to a hyperplane in the feature space S S S, This hyperplane divides the feature space into two parts , The point in both parts ( Eigenvector ) They're divided into positive 、 Negative two types of . hyperplane S S S It is also called separating hyperplane .
A linear equation divides the feature space into two parts . In the two-dimensional feature space ,wx+b=0 That is, between one , Divide the plane into two parts , The point above the line is brought in wx+b The calculated value is greater than 0, Is a positive class , Corresponding y The value is +1, The point below the line is less than 0, Is a negative class , Corresponding y The value is -1.The strategy of perceptron learning is to minimize the loss function Count :
m i n w , b L ( w , b ) = − ∑ y i ( w ⋅ x i + b ) , x i ∈ M min_w, _bL(w,b)=-\sum y_i(w·x_i+b), x_i \in M minw,bL(w,b)=−∑yi(w⋅xi+b),xi∈M
The loss function corresponds to the total distance from the misclassification point to the separation hyperplane .The loss function here focuses on misclassification points , Not all points . The minimum loss function is zero , That is, all points are classified correctly . Therefore, there are infinite solutions .Perceptron learning algorithm is an optimization algorithm of loss function based on random gradient descent method . In the original form , First select a hyperplane , Then the gradient descent method is used to continuously minimize the objective function , In the process , Randomly select one misclassification point at a time to make its gradient drop .
When the training data set is linearly separable [ Add 1], The perceptron learning algorithm is convergent , But there are infinite solutions , These solutions depend on the choice of local values , It also depends on the selection order of misclassification points in the iterative process .
If you want to get a unique hyperplane , We need to add constraints to the separation hyperplane . Refer to support vector machine
Why can't we solve XOR (XOR) problem
XOR problem is in binary operation , The same value is 0, The difference is 1.
Map the XOR problem to two-dimensional space , Can be expressed as :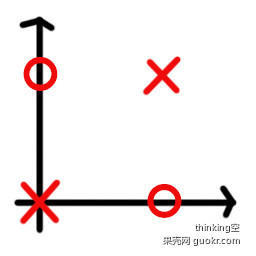
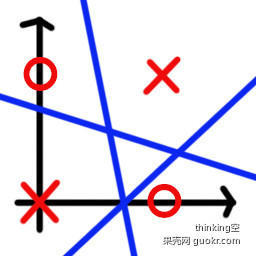
picture source : https://www.jianshu.com/p/853ebc9e69f6
In this two-dimensional space , We can't find a straight line to divide it into two categories . That is to say, it is impossible to use the perceptron model to X To the side of the straight line , At the same time O To the other side of the line . So the perceptron can't solve the XOR problem .
Supplementary knowledge
- Add 1: Linear separability of data sets
Given a dataset
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) } T=\{(x_1, y_1), (x_2, y_2),…, (x_N, y_N)\} T={ (x1,y1),(x2,y2),…,(xN,yN)}
among , x i ∈ X = R n x_i \in X = R^n xi∈X=Rn, y i ∈ Y = { + 1 , − 1 } y_i \in Y=\{+1,-1\} yi∈Y={ +1,−1}, i = 1 , 2 , … , N i=1,2,…,N i=1,2,…,N, If I have some hyperplane S S S
w ⋅ x + b = 0 w·x+b=0 w⋅x+b=0 The ability to partition the positive and negative instance points of a data set exactly to either side of a hyperplane , For all y i = + 1 y_i=+1 yi=+1 Example i i i, Yes w ⋅ x i + b > 0 w·x_i+b>0 w⋅xi+b>0, For all y i = − 1 y_i=-1 yi=−1 Example i i i, Yes w ⋅ x i + b < 0 w·x_i+b<0 w⋅xi+b<0, Is called a data set T T T Is a linear fractional data set (Linearly separable data set); otherwise , According to the data set T T T The line shape is inseparable .
Recommended reading :
边栏推荐
- 神经网络c语言中的指针是怎么回事
- MySQL中, 如何查询某一天, 某一月, 某一年的数据
- Logback logging framework third-party jar package is available for free
- Three. JS introduction learning notes 12: the model moves along any trajectory line
- [excelexport], Excel to Lua, JSON, XML development tool
- Migration and reprint
- Sysom case analysis: where is the missing memory| Dragon lizard Technology
- Plate - forme de surveillance par étapes zabbix
- Three. JS introductory learning notes 05: external model import -c4d into JSON file for web pages
- Markdown formula editing tutorial
猜你喜欢
Numpy -- epidemic data analysis case
numpy--数据清洗
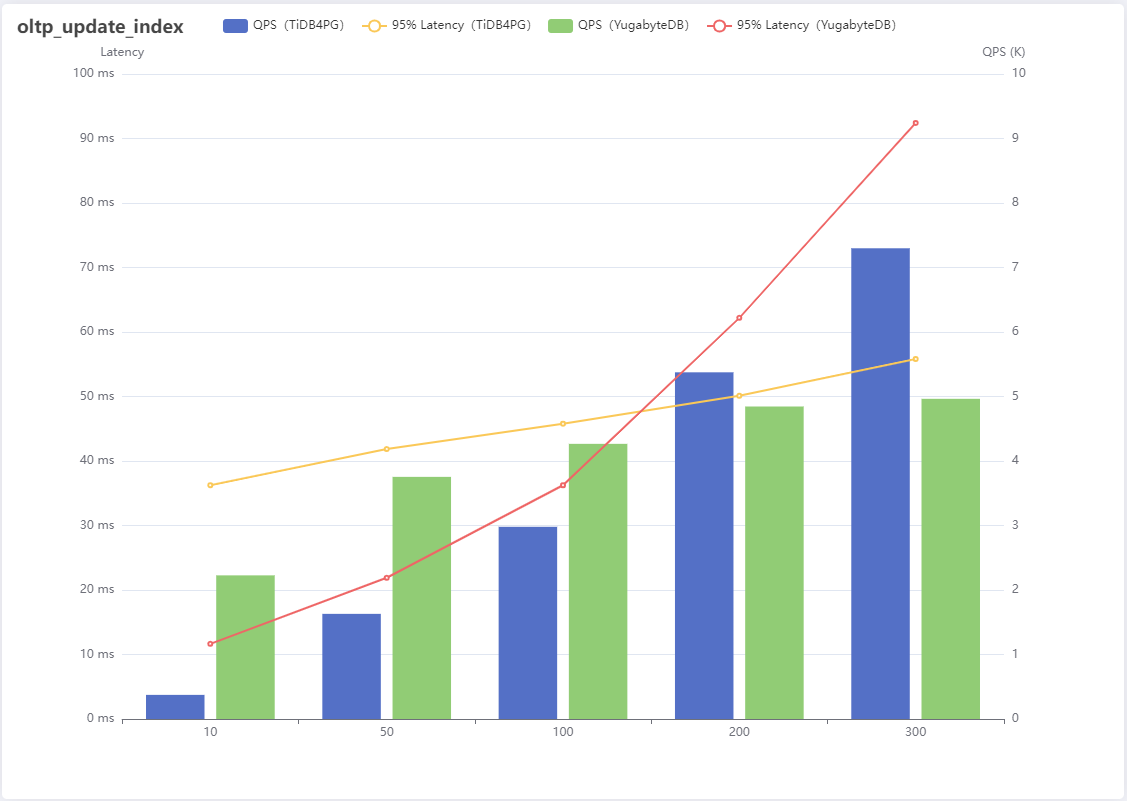
Performance comparison of tidb for PostgreSQL and yugabytedb on sysbench
Notification uses full resolution
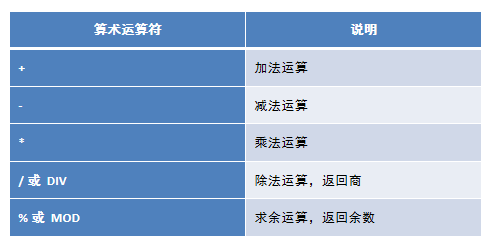
Mysql database basic operation DQL basic query
C4D learning notes 1- animation - animation key frames
AE learning 02: timeline
MySQL数据库基本操作-DQL-基本查询
C4D learning notes 2- animation - timeline and time function

神经网络c语言中的指针是怎么回事
随机推荐
Unity3D_ Class fishing project, bullet rebound effect is achieved
山东老博会,2022中国智慧养老展会,智能化养老、适老科技展
numpy--数据清洗
TS typescript type declaration special declaration field number is handled when the key key
Talk about the cloud deployment of local projects created by SAP IRPA studio
Logback日志框架第三方jar包 免费获取
通知Notification使用全解析
航天宏图信息中标乌鲁木齐某单位数据库系统研发项目
C4D learning notes 2- animation - timeline and time function
121. The best time to buy and sell stocks
Three. JS introductory learning notes 04: external model import - no material obj model
AE learning 02: timeline
torch. Numel action
如何在shell中实现 backspace
Migration and reprint
神经网络c语言中的指针是怎么回事
hellogolang
Bidding announcement: 2022 Yunnan Unicom gbase database maintenance public comparison and selection project (second) comparison and selection announcement
SPI master rx time out中断
2022第四届中国(济南)国际智慧养老产业展览会,山东老博会