当前位置:网站首页>Numpy -- data cleaning
Numpy -- data cleaning
2022-07-07 15:50:00 【madkeyboard】
List of articles
Data cleaning
Dirty data
Usually, the data we get cannot be 100% error free , There are usually some problems , For example, the data value is missing 、 The data value is abnormally large or small 、 Format error and dependent data error .
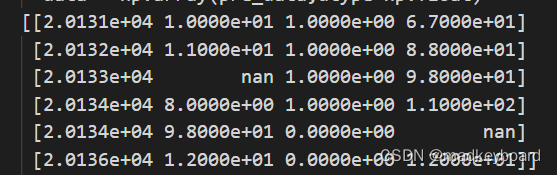
Generate a set of dirty data vividly through the following code , As shown in the figure, a dtype = object.( This dtype Namely numpy Type of data , Pay attention here , If dtype = object explain list Directly converted data cannot be directly involved in calculation , Only int and float Only such data types can participate in the calculation )
raw_data = [
["Name", "StudentID", "Age", "AttendClass", "Score"],
[" Xiao Ming ", 20131, 10, 1, 67],
[" floret ", 20132, 11, 1, 88],
[" Side dish ", 20133, None, 1, "98"],
[" Xiao Qi ", 20134, 8, 1, 110],
[" Cauliflower ", 20134, 98, 0, None],
[" Liu Xin ", 20136, 12, 0, 12]
]
data = np.array(raw_data)
print(data)

Data preprocessing
pre_data = []
for i in range(len(raw_data)):
if i == 0: # Remove the first line of string
continue
pre_data.append(raw_data[i][1:]) # Remove the first column of names
data = np.array(pre_data,dtype=np.float) # The reason it's used here float Because the data contains None, Only float To convert None
print(data)
Data cleaning
Clean out all illogical data , In the data entered before , The first column has obvious repetition of student numbers , This is illogical data .np.unique() Make the data unique , And in the process of using, you can also see how many times the duplicate data has been repeated . As shown in the figure below ,20134 It appears twice , Then we can clearly know 20135 Not recorded , Then you can correct the data .
fcow = data[:,0] # Take all student numbers in the first column
print(fcow)
unique, counts = np.unique(fcow,return_counts=True) # return_counts Show the number of repetitions of the data
print(" Data after cleaning :",unique)
print(" The number of times the data repeats :",counts)

Looking at the second column of data , First of all, you can intuitively see that there is a lack of data , So for this missing data , We can add by averaging the existing data
is_nan = np.isnan(data[:,1]) # Find the second column as none The data of
nan_idx = np.argwhere(is_nan)
print(" Subscript :",nan_idx," by none")
mean_age = data[~np.isnan(data[:,1]), 1].mean() # ~ Take the opposite ,isnan It returns a Boolean value , The Boolean value selected here is false( Not for None), Then average
print(" Average age :",mean_age)
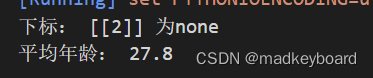
I was puzzled when I saw this , The average age of primary school students is 28? By observing the data , There is a data for 98, Obviously wrong , This is abnormal data . So we need to delete these two wrong data , Then replace them with the average of the remaining data .
normal_idx = ~np.isnan(data[:,1]) & (data[:,1] < 13) # Find the second column as none The data of
print("(flase) For the data that needs to be changed :",normal_idx)
mean_age = data[normal_idx,1].mean() # ~ Take the opposite ,isnan It returns a Boolean value , The Boolean value selected here is false( Not for None), Then average
print(" Average age :",mean_age)
data[~normal_idx,1] = mean_age
print(" Data after cleaning :",np.floor(data[:,1])) # Age has no decimal , Round down again

Finally, look at the data in the last two columns , here 0 and 1 Whether the representative is in class or not , There can be no grades when there is no class , There is a problem with the last line . And the total score of primary school is generally 100, There are beyond 100 The existence of indicates abnormal data .
data = np.array(pre_data,dtype=np.float64) # The reason it's used here float Because the data contains None, Only float To convert None
data[data[:,2] == 0,3] = np.nan # Those who don't have classes have no grades nan
data[:,3] = np.clip(data[:,3], 0, 100) # Cut the scores that are no longer within a reasonable range
print(data[:,2:]) # Output the last two columns
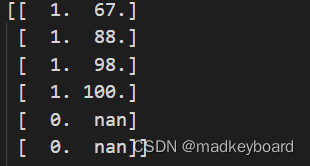
Finally, compare the data before and after cleaning , Although the amount of data this time is very small , But there are also many cleaning methods , Familiar with these ways , In the future, it is also easy to catch more huge data , Keep your data clean and hygienic .
边栏推荐
- 【數字IC驗證快速入門】26、SystemVerilog項目實踐之AHB-SRAMC(6)(APB協議基本要點)
- JS array foreach source code parsing
- It's different for rich people to buy a house
- webgl_ Enter the three-dimensional world (1)
- HW primary flow monitoring, what should we do
- 山东老博会,2022中国智慧养老展会,智能化养老、适老科技展
- unnamed prototyped parameters not allowed when body is present
- Gd32 F3 pin mapping problem SW interface cannot be burned
- 尤雨溪,来了!
- Getting started with webgl (1)
猜你喜欢
Three. JS introductory learning notes 15: threejs frame animation module
【数字IC验证快速入门】18、SystemVerilog学习之基本语法5(并发线程...内含实践练习)

Zhongang Mining: Fluorite continues to lead the growth of new energy market
【数字IC验证快速入门】22、SystemVerilog项目实践之AHB-SRAMC(2)(AMBA总线介绍)
【數字IC驗證快速入門】20、SystemVerilog學習之基本語法7(覆蓋率驅動...內含實踐練習)
Ida Pro reverse tool finds the IP and port of the socket server
使用cpolar建立一个商业网站(2)

航运船公司人工智能AI产品成熟化标准化规模应用,全球港航人工智能/集装箱人工智能领军者CIMC中集飞瞳,打造国际航运智能化标杆

2022第四届中国(济南)国际智慧养老产业展览会,山东老博会
numpy--数据清洗
随机推荐
Virtual memory, physical memory /ram what
使用cpolar建立一个商业网站(2)
Three. JS introductory learning notes 11:three JS group composite object
The difference between full-time graduate students and part-time graduate students!
Super signature principle (fully automated super signature) [Yun Xiaoduo]
15. Using the text editing tool VIM
Please supervise the 2022 plan
[quick start of Digital IC Verification] 25. AHB sramc of SystemVerilog project practice (5) (AHB key review, key points refining)
Android -- jetpack: the difference between livedata setValue and postvalue
【数字IC验证快速入门】20、SystemVerilog学习之基本语法7(覆盖率驱动...内含实践练习)
使用Scrapy框架爬取网页并保存到Mysql的实现
Getting started with webgl (3)
【數字IC驗證快速入門】20、SystemVerilog學習之基本語法7(覆蓋率驅動...內含實踐練習)
Shader Language
Streaming end, server end, player end
VS2005 strange breakpoint is invalid or member variable value cannot be viewed
10 schemes to ensure interface data security
讲师征集令 | Apache SeaTunnel(Incubating) Meetup 分享嘉宾火热招募中!
【数字IC验证快速入门】29、SystemVerilog项目实践之AHB-SRAMC(9)(AHB-SRAMC SVTB Overview)
Basic knowledge sorting of mongodb database