当前位置:网站首页>TiDB For PostgreSQL和YugabyteDB在Sysbench上的性能对比
TiDB For PostgreSQL和YugabyteDB在Sysbench上的性能对比
2022-07-07 13:53:00 【神州数码云基地】
目录
背景
PostgreSQL是一款知名的开源数据库产品,作为数字化的基础设施在大型企业级应用中扮演着重要的角色,它的许多高级特性被广泛应用在各种复杂场景中。
根据Stack Overflow 2022 开发者调查报告显示,PostgreSQL已经超越MySQL成为开发者最喜爱的数据库软件。

在近些年的数据库领域中分布式数据库是当下的发展趋势,基于PostgreSQL协议的分布式数据库国外诞生了诸如CockroachDB、YugabyteDB这样的优秀产品,而国内的热门分布式数据库TiDB官方只提供了MySQL协议的支持,神州数码技术团队基于开源TiDB研发了TiDB For PostgreSQL版本,目前已经实现了主流应用兼容,参考资料:
他们同属NewSQL范畴且实现了PG协议,但具体架构实现上还是有差异性,我们非常好奇两者性能对比之下表现如何。
测试方案
准备3台物理机用来搭建分布式数据库,分别搭建3节点的YugabyteDB集群和TiDB For PostgreSQL集群,全部使用默认参数部署,数据库之上使用Haproxy做负载均衡代理。这样能尽可能地保证两者的部署架构一致,减少实验误差。
部署环境:
| 机器名称 | 参数值 | 备注 |
|---|---|---|
| 数据库节点-1 | 物理机,NUC 10 x86,12c 64G 1Tssd | yugabytedb:1个master、1个 tserver tidb4pg:1个pd、1个tidb、1个tikv |
| 数据库节点-2 | 物理机,NUC 10 x86,12c 64G 1Tssd | 同上 |
| 数据库节点-3 | 物理机,NUC 10 x86,12c 64G 1Tssd | 同上 |
| Sysbench压测机 | 虚拟机,x86,16c 32G | |
| Haproxy负载均衡 | 虚拟机,x86,8c 16G |
Sysbench压测选择7个常用场景:
- select_random_points(随机点查)
- oltp_read_only(只读事务)
- oltp_write_only(只写事务)
- oltp_read_write(读写混合事务)
- oltp_update_index(带索引更新)
- oltp_update_non_index(不带索引更新)
- oltp_delete(事务删除)
针对以上每个场景,设置5种不同并发级别,分别是10、50、100、200、300个线程数,持续压测5分钟。
收集每次测试数据中的QPS和95%延时指标做两种数据库对比。
测试结果
1、select_random_points
| 线程数 | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 4044 | 3.49 | 2666 | 5.47 |
| 50 | 8398 | 10.09 | 5086 | 15.00 |
| 100 | 8754 | 20 | 5429 | 29.19 |
| 200 | 9441 | 36.89 | 5541 | 58.92 |
| 300 | 9785 | 52.89 | 5531 | 92.42 |

结果分析:
在点查场景上TIDB For PostgreSQL比YugabyteDB要稍微领先一些,而且随着并发量增大,这个差距被拉的越来越大。
2、oltp_read_only
| 线程数 | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 8954 | 20.74 | 0.13 | - |
| 50 | 24262 | 38.94 | 0.15 | - |
| 100 | 25136 | 78.60 | 0.15 | - |
| 200 | 25267 | 158.63 | 0.14 | - |
| 300 | 25436 | 240.02 | 0.14 | - |
结果分析:
这个场景测试结果差异非常大,YugabyteDB查询性能受到碾压,TiDB For PostgreSQL在正常水平。
通过分析Sysbench源码发现,只读场景主要是包含以下几条查询SQL:
SELECT c FROM sbtest1 WHERE id BETWEEN 1 AND 1000;
SELECT sum(k) FROM sbtest1 WHERE id BETWEEN 1 AND 1000;
SELECT c FROM sbtest1 WHERE id BETWEEN 1 AND 1000 order by c;
SELECT distinct c FROM sbtest1 WHERE id BETWEEN 1 AND 1000 order by c;
4条根据主键做范围查的SQL执行下来耗时总共在400秒以上,结果非常让人吃惊。以第一条SQL为例分析它的执行计划:
Seq Scan on sbtest1 (cost=0.00..105.00 rows=1000 width=484) (actual time=9.968..127393.155 rows=1000 loops=1)
Filter: ((id >= 1) AND (id <= 1000))
Rows Removed by Filter: 9999000
Planning Time: 0.048 ms
Execution Time: 127393.919 ms
按照以往经验来说应该直接走主键索引扫描,但实际上是用了全表扫描,令人迷惑。
为了验证是否查询范围大小的影响,我把id的查询范围限制在1到10,发现还是一样的执行计划,如果改用in查询的话就可以走主键索引。
相比而言,TiDB For PostgreSQL的执行计划是在预期内:
Projection_4 500.09 1000 root
└─IndexLookUp_13 500.09 1000 root
├─IndexRangeScan_11(Build) 500.09 1000 cop[tikv] table:sbtest1, index:PRIMARY(id)
└─TableRowIDScan_12(Probe) 500.09 1000 cop[tikv] table:sbtest1
到底是什么原因导致YugabyteDB的范围查询效率这么低还要进一步分析。
3、oltp_write_only
| 线程数 | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 790 | 90.78 | 4309 | 47.47 |
| 50 | 3540 | 104.84 | 8427 | 71.83 |
| 100 | 6486 | 114.72 | 8674 | 92.42 |
| 200 | 11414 | 132.49 | 11170 | 150.29 |
| 300 | 15133 | 155.80 | 12036 | 211.60 |
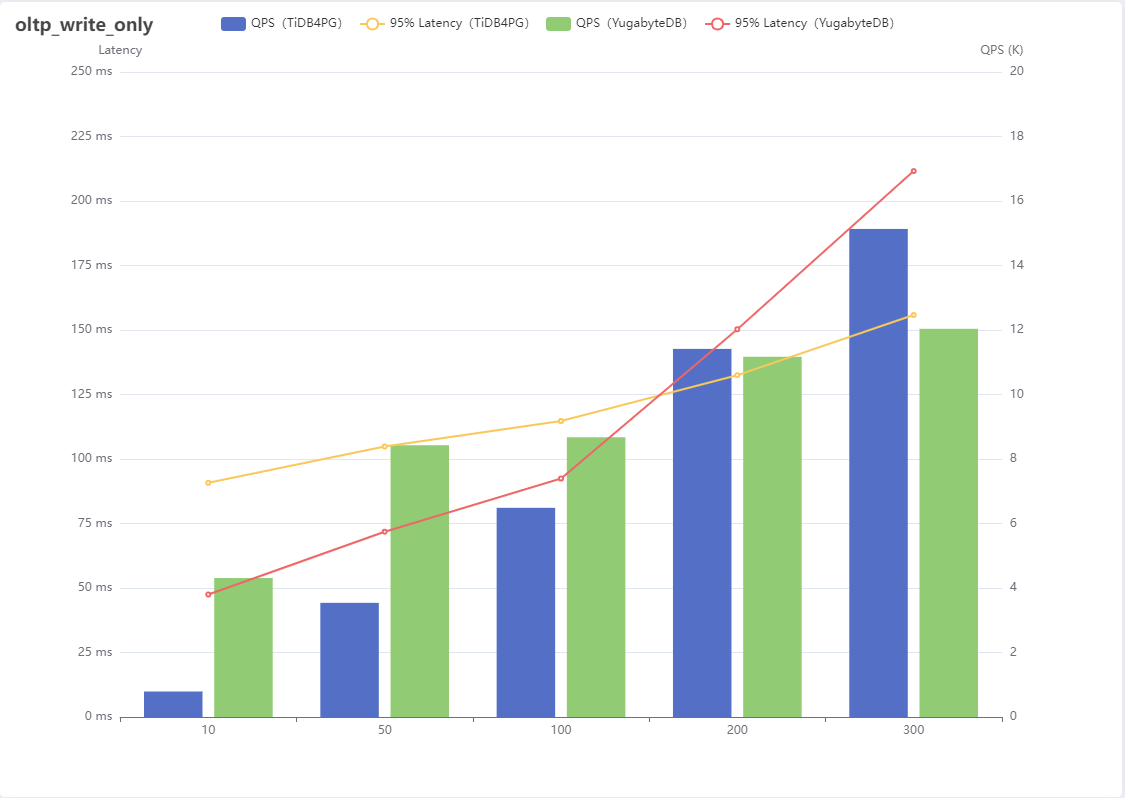
结果分析:
混合写入场景包含4类,也就是后面提到的索引更新、不带索引更新、删除、插入这4种情况,在并发量较小的时候YugabyteDB性能优势明显,但是从200并发开始TiDB For PostgreSQL性能开始反超,可以反映稳定性稍好一些。
4、oltp_read_write
| 线程数 | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 2238 | 104.84 | 556 | 3151.62 |
| 50 | 9790 | 123.28 | 1485 | 3326 |
| 100 | 17454 | 137.35 | 1494 | 6960 |
| 200 | 25119 | 189.93 | 1402 | 14302 |
| 300 | 25967 | 272.27 | 1835 | 22034 |
结果分析:
混合读写场景同样受到YugabyteDB范围查询的影响,整体性能比TiDB For PostgreSQL要差很多,在50并发量的时候已经达到瓶颈。
5、oltp_update_index
| 线程数 | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 374 | 36.24 | 2227 | 11.65 |
| 50 | 1630 | 41.85 | 3754 | 21.89 |
| 100 | 2980 | 45.79 | 4266 | 36.24 |
| 200 | 5375 | 50.11 | 4845 | 62.19 |
| 300 | 7298 | 55.82 | 4964 | 92.42 |
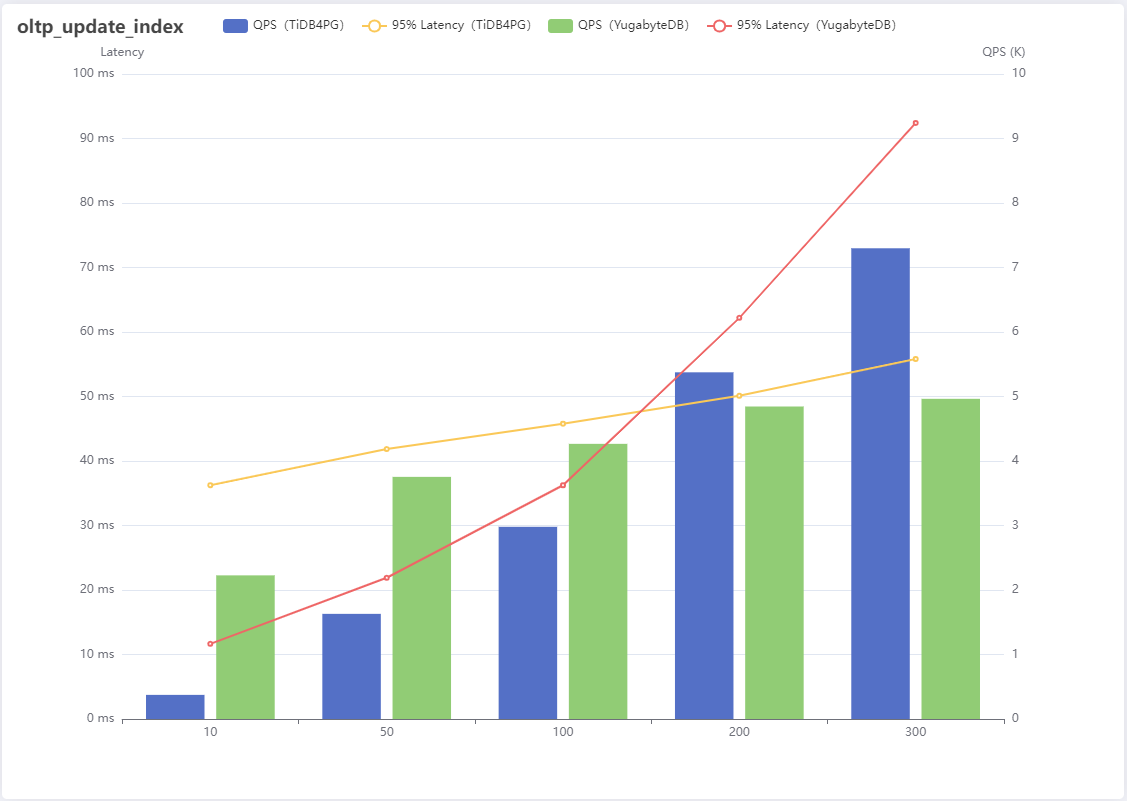
结果分析:
update_index是根据主键更新索引列,在这一场景中YugabyteDB在小并发量时性能更好,但是随着并发量上升会更快达到性能瓶颈,并且会越来越差,TiDB For PostgreSQL相对稳定。
6、oltp_update_non_index
| 线程数 | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 415 | 31.37 | 6847 | 2.03 |
| 50 | 1988 | 35.59 | 17123 | 4.65 |
| 100 | 3761 | 37.56 | 16246 | 9.91 |
| 200 | 6910 | 41.10 | 18928 | 20.37 |
| 300 | 9849 | 43.39 | 19896 | 29.72 |
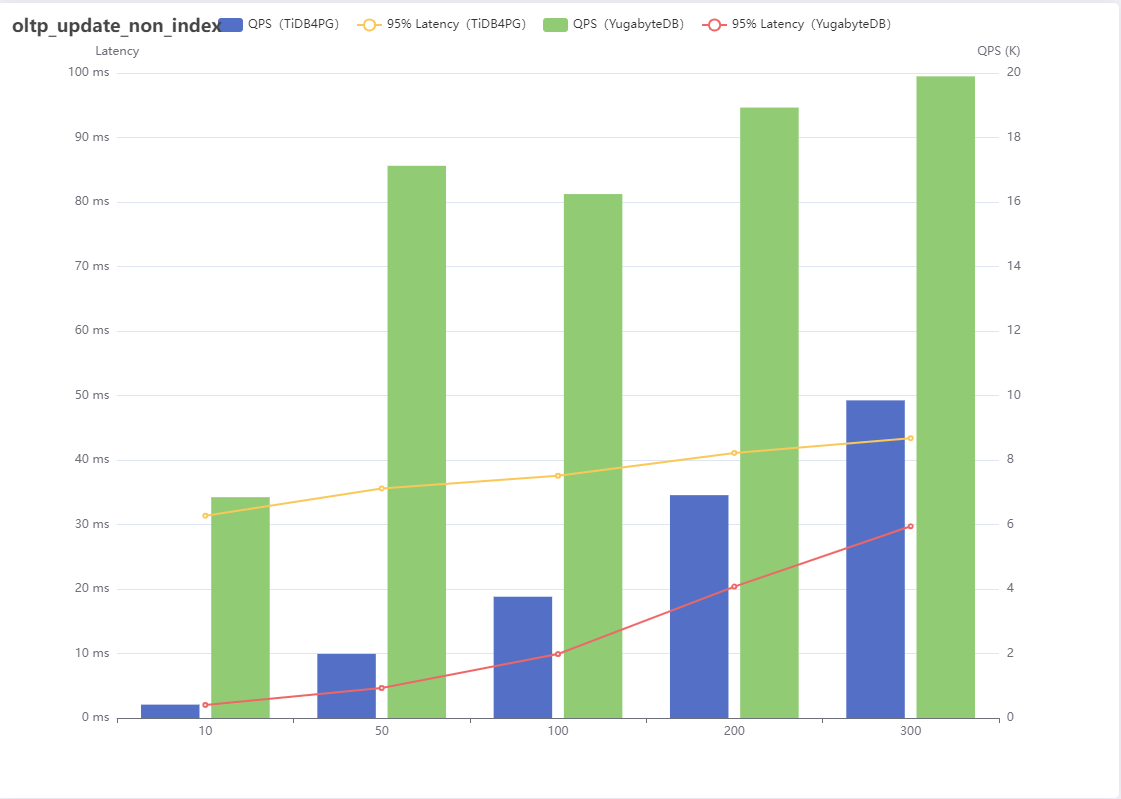
结果分析:
update_non_index是根据主键更新非索引列,在这一场景中YugabyteDB大幅领先TiDB For PostgreSQL并且持续保持。
7、oltp_delete
| 线程数 | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 364 | 37.56 | 2389 | 10.84 |
| 50 | 1568 | 43.39 | 4269 | 19.65 |
| 100 | 2899 | 46.63 | 4844 | 33.12 |
| 200 | 5380 | 50.11 | 5705 | 56.84 |
| 300 | 7622 | 54.83 | 6146 | 82.96 |
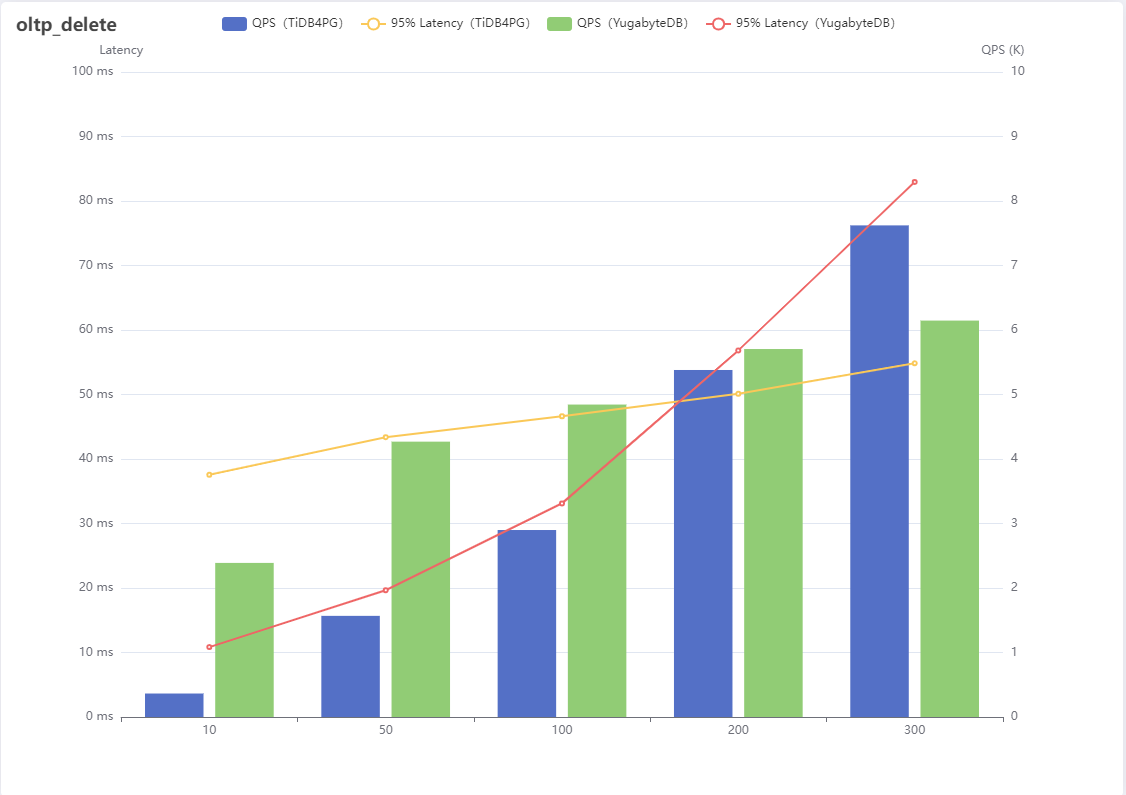
结果分析:
delete场景是根据主键删除一行记录,这个测试结果类似非索引更新,刚开始YugabyteDB性能较好,并发量上升以后慢慢落后于TiDB For PostgreSQL。
总结
经过以上7个场景的测试发现,两种数据库的性能各有优劣。
TiDB For PostgreSQL更擅长读操作,YugabyteDB更擅长写操作,但是随着数据库负载增加,YugabyteDB对大并发请求的处理能力和稳定性不如TiDB For PostgreSQL好。
这其中的差异我们会在后续对两者从架构和底层原理上做深度对比,看能否找出真实的原因。
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,后台回复TiDB,加入TiDB技术交流群。
边栏推荐
- A JS script can be directly put into the browser to perform operations
- Use moviepy Editor clips videos and intercepts video clips in batches
- Use of SVN
- JS array foreach source code parsing
- Strengthen real-time data management, and the British software helps the security construction of the medical insurance platform
- hellogolang
- Three. JS introductory learning notes 11:three JS group composite object
- Three. Introduction to JS learning notes 17: mouse control of 3D model rotation of JSON file
- leetcode 241. Different ways to add parentheses design priority for operational expressions (medium)
- Cocos creator collision and collision callback do not take effect
猜你喜欢

Spin animation of Cocos performance optimization
C4D learning notes 3- animation - animation rendering process case

2022第四届中国(济南)国际智慧养老产业展览会,山东老博会

JS array foreach source code parsing
numpy--数据清洗

Three. JS introductory learning notes 11:three JS group composite object
Step by step monitoring platform ZABBIX

Apache Doris刚“毕业”:为什么应关注这种SQL数据仓库?
After UE4 is packaged, mesh has no material problem
10 schemes to ensure interface data security
随机推荐
星瑞格数据库入围“2021年度福建省信息技术应用创新典型解决方案”
numpy---基础学习笔记
Eye of depth (VI) -- inverse of matrix (attachment: some ideas of logistic model)
Function: JS Click to copy content function
Shader basic UV operations, translation, rotation, scaling
There are many ways to realize the pause function in JS
Clang compile link ffmpeg FAQ
Annexb and avcc are two methods of data segmentation in decoding
讲师征集令 | Apache SeaTunnel(Incubating) Meetup 分享嘉宾火热招募中!
尤雨溪,来了!
航運船公司人工智能AI產品成熟化標准化規模應用,全球港航人工智能/集裝箱人工智能領軍者CIMC中集飛瞳,打造國際航運智能化標杆
PyTorch 中的乘法:mul()、multiply()、matmul()、mm()、mv()、dot()
Three. JS introductory learning notes 08:orbitcontrols JS plug-in - mouse control model rotation, zoom in, zoom out, translation, etc
Simple understanding and application of TS generics
2022第四届中国(济南)国际智慧养老产业展览会,山东老博会
Particle effect for ugui
webgl_ Enter the three-dimensional world (2)
无线传感器网络--ZigBee和6LoWPAN
Bidding announcement: Panjin people's Hospital Panjin hospital database maintenance project
Three. JS introduction learning notes 12: the model moves along any trajectory line