当前位置:网站首页>数据库设计:范式与反范式
数据库设计:范式与反范式
2020-11-08 21:14:00 【讓丄帝愛伱】
- 三范式
第一范式(1NF):数据表中的每一列(每个字段)必须是不可拆分的最小单元,也就是确保每一列的原子性;
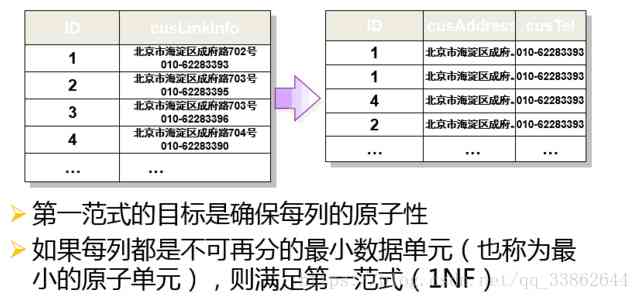
第二范式(2NF):满足1NF后,要求表中的所有列,都必须依赖于主键,而不能有任何一列与主键没有关系,也就是说一个表只描述一件事情;

第三范式(3NF):必须先满足第二范式(2NF),要求:表中的每一列只与主键直接相关而不是间接相关,(表中的每一列只能依赖于主键);
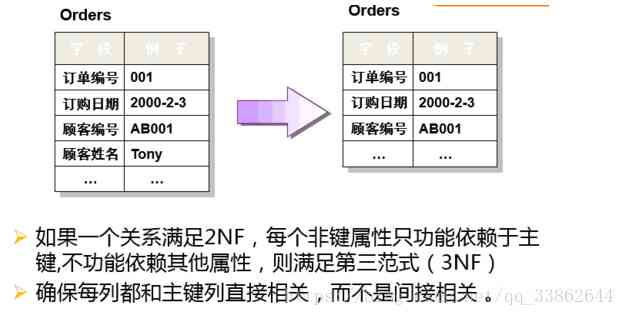
第 一范式和第二范式在于有没有分出两张表,
第二范式是说一张表中包含了多种不同的实体属性,那么要必须分成多张表,
第三范式是要求已经分成了多张表,那么一张表中只能有另一张表中的id(主键),而不能有其他的任何信息(其他的信息一律用主键在另一表查询)。
总结:
第1范式:每个表中都有1列,并且该列是不可拆分的最小单元 无重复的列
第2范式:1张表只描述一件事情 属性完全依赖于主键
第3范式:用外键做表的关联 直接依赖而不是间接(传递)依赖
要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
简而言之,第三范式就是属性不依赖于其它非主属性。 也就是说, 如果存在非主属性对于码的传递函数依赖,则不符合3NF的要求
- 反范式
反范式允许表中存在传递函数依赖
范式与反范式的比较:
查询记录时,范式模式往往要进行多表连接,而反范式只需在同一张表中查询,当数据量很大的时候,显然反范式的效率会更好。
反范式有很多重复的数据,会占用更多的内存,查询时可能会较多地使用DROUP BY或DISTINCT等耗时耗性能的关键字。
当要修改更新数据时(例如修改Accounting部门的领导为Russell),范式更灵活,而反范式要修改全部的数据,且易出错。
…
总结:关于范式与反范式的比较还有很多很多,二者各有各的好处,在实际开发中应该根据需要合理地混用不同的模式,最大程度地结合发挥各自的优点。
版权声明
本文为[讓丄帝愛伱]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/2425659/blog/4708340
边栏推荐
- Infix expression to suffix expression
- 存储过程动态查询处理方法
- 动态规划之子序列问题解题模板
- 选择API管理平台之前要考虑的5个因素
- Problem solving templates for subsequence problems in dynamic programming
- What courses will AI programming learn?
- Implementation of warehouse management system with ABP (net core) + easyUI + efcore
- Decorator (2)
- 接口测试工具Eolinker进行post请求
- Django's simple user system (3)
猜你喜欢

选择排序
Looking for better dynamic getter and setter solutions
Implementation of warehouse management system with ABP (net core) + easyUI + efcore
Select sort
微信小程序相关
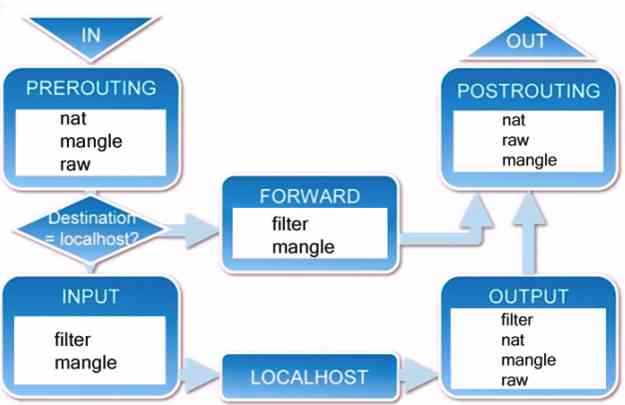
iptables从入门到掌握
Using fastai to develop and deploy image classifier application
Why need to use API management platform
![[200 interview experience], programmer interview, common interview questions analysis](/img/fb/625e17f83f6be064f7387e78ec082a.jpg)
[200 interview experience], programmer interview, common interview questions analysis
存储过程动态查询处理方法
随机推荐
C/C++学习日记:原码、反码和补码
寻找性能更优秀的动态 Getter 和 Setter 方案
API生命周期的5个阶段
动态规划答疑篇
第一部分——第2章指针操作
CountDownLatch 瞬间炸裂!同基于 AQS,凭什么 CyclicBarrier 可以这么秀?
云计算之路-出海记-小目标:Hello World from .NET 5.0 on AWS
Creating a text cloud or label cloud in Python
MongoDB数据库
构造回文的最小插入次数
Development and deployment of image classifier application with fastai
PAT_ Grade A_ 1056 Mice and Rice
Python应用场景多不多?
Looking for a small immutable dictionary with better performance
装饰器(一)
Aprelu: cross border application, adaptive relu | IEEE tie 2020 for machine fault detection
Classical dynamic programming: longest common subsequence
接口测试工具Eolinker进行post请求
VirtualBox install centos7
Solve the failure of go get download package