当前位置:网站首页>存储过程动态查询处理方法
存储过程动态查询处理方法
2020-11-08 19:03:00 【轻轻的走过】
查询存储过程动态匹配的问题时,看到了存储过程的参数动态匹配处理,发现自己就有这方面的错误,所以重新整理保存下。
方式一:
常见的写法:拼凑字符串,用EXEC的方式执行这个拼凑出来的字符串,不推荐
create proc pr_getOrederInfo_1
(
@p_OrderNumber int ,
@p_CustomerId varchar(20) ,
@p_OrderDateBegin datetime ,
@p_OrderDateEnd datetime
)
as
begin
set nocount on;
declare @strSql nvarchar(max);
set @strSql= 'SELECT [id]
,[OrderNumber]
,[CustomerId]
,[OrderDate]
,[Remark]
FROM [dbo].[SaleOrder] where 1=1 ';
/*
这种写法的特点在于将查询SQL拼凑成一个字符串,最后以EXEC的方式执行这个SQL字符串
*/
if(@p_OrderNumber is not null)
set @strSql = @strSql + ' and OrderNumber = ' + @p_OrderNumber
if(@p_CustomerId is not null)
set @strSql = @strSql + ' and CustomerId = '+ ''''+ @p_CustomerId + ''''
if(@p_OrderDateBegin is not null)
set @strSql = @strSql + ' and OrderDate >= ' + '''' + cast(@p_OrderDateBegin as varchar(10)) + ''''
if(@p_OrderDateEnd is not null)
set @strSql = @strSql + ' and OrderDate <= ' + '''' + cast(@p_OrderDateEnd as varchar(10)) + ''''
print @strSql
exec(@strSql);
end执行方法本身没有问题,结果也没有问题。但有缺点
1、绕不过转移符以及注入问题。
2、因为参数不同,会导致每次拼凑出来的sql不同,结果每次都需要编译,浪费CPU资源,量大就会有问题。
方式二:
对所有查询条件用OR的方式加在where条件中,非常不推荐
create proc pr_getOrederInfo_2
(
@p_OrderNumber int ,
@p_CustomerId varchar(20) ,
@p_OrderDateBegin datetime ,
@p_OrderDateEnd datetime
)
as
begin
set nocount on;
declare @strSql nvarchar(max);
SELECT [id]
,[OrderNumber]
,[CustomerId]
,[OrderDate]
,[Remark]
FROM [dbo].[SaleOrder]
where 1=1
and (@p_OrderNumber is null or OrderNumber = @p_OrderNumber)
and (@p_CustomerId is null or CustomerId = @p_CustomerId)
/*
这是另外一种类似的奇葩的写法,下面会重点关注
and OrderNumber = ISNULL( @p_OrderNumber,OrderNumber)
and CustomerId = ISNULL( @p_CustomerId,CustomerId)
*/
and (@p_OrderDateBegin is null or OrderDate >= @p_OrderDateBegin)
and (@p_OrderDateEnd is null or OrderDate <= @p_OrderDateEnd)
end执行方法本身没有问题,结果也没有问题。但有缺点
1、抑制索引。
2、参数也是null的时候就惨了。
方式三:
参数化SQL,推荐
create proc pr_getOrederInfo_3
(
@p_OrderNumber int ,
@p_CustomerId varchar(20) ,
@p_OrderDateBegin datetime ,
@p_OrderDateEnd datetime
)
as
begin
set nocount on;
DECLARE @Parm NVARCHAR(MAX) = N'',
@sqlcommand NVARCHAR(MAX) = N''
SET @sqlcommand = 'SELECT [id]
,[OrderNumber]
,[CustomerId]
,[OrderDate]
,[Remark]
FROM [dbo].[SaleOrder]
where 1=1 '
IF(@p_OrderNumber IS NOT NULL)
SET @sqlcommand = CONCAT(@sqlcommand,' AND OrderNumber= @p_OrderNumber')
IF(@p_CustomerId IS NOT NULL)
SET @sqlcommand = CONCAT(@sqlcommand,' AND CustomerId= @p_CustomerId')
IF(@p_OrderDateBegin IS NOT NULL)
SET @sqlcommand = CONCAT(@sqlcommand,' AND OrderDate>=@p_OrderDateBegin ')
IF(@p_OrderDateEnd IS NOT NULL)
SET @sqlcommand = CONCAT(@sqlcommand,' AND OrderDate<=@p_OrderDateEnd ')
SET @Parm= '@p_OrderNumber int,
@p_CustomerId varchar(20),
@p_OrderDateBegin datetime,
@p_OrderDateEnd datetime '
PRINT @sqlcommand
EXEC sp_executesql @sqlcommand,@Parm,
@p_OrderNumber = @p_OrderNumber,
@p_CustomerId = @p_CustomerId,
@p_OrderDateBegin = @p_OrderDateBegin,
@p_OrderDateEnd = @p_OrderDateEnd
end执行方法本身没有问题,结果也没有问题。
第一,既能避免第一种写法中的SQL注入问题(包括转移符的处理),
因为参数是运行时传递进去SQL的,而不是编译时传递进去的,传递的参数是什么就按照什么执行,参数本身不参与编译
第二,保证执行计划的重用,因为使用占位符来拼凑SQL的,SQL参数的值不同并导致最终执行的SQL文本不同
同上面,参数本身不参与编译,如果查询条件一样(SQL语句就一样),而参数不一样,并不会影响要编译的SQL文本信息
第三,还有就是避免了第二种情况(and (@p_CustomerId is null or CustomerId = @p_CustomerId)
或者 and OrderNumber = ISNULL( @p_OrderNumber,OrderNumber))
这种写法,查询条件有就是有,没有就是没有,不会丢给SQL查询引擎一个模棱两个的结果,
避免了对索引的抑制行为,是一种比较好的处理查询条件的方式。
看完这些,发现要把一些可能以后量大的存储过程做个调整。。。
归纳:
1、创建临时表。
2、用方式三将数据写入到临时表中。
3、遍历临时表拼接成JSON字符串返回
实测追加
declare
@data1 NVARCHAR(20),
@count int,
@sqlcommand NVARCHAR(MAX) = N'',
@Parm NVARCHAR(MAX) = N''
begin
set @sqlcommand=' '
set @data1=' 1 or 1=1'
set @sqlcommand=' select @a=COUNT(1) from tb_user where 1=1 '
exec sp_executesql @sqlcommand,N'@a int output ',@count output
print '数量='+convert(varchar(10),@count)
set @sqlcommand=' '
set @sqlcommand=N' select id,u_no,u_name from tb_user where 1=1 '
IF(@data1 IS NOT NULL) SET @sqlcommand += N' AND u_name like ''%'+@data1+'%'''
print @sqlcommand
exec sp_executesql @sqlcommand
end结果

就这样了先。。。。。。。。。。。。。
突然反应过来自己现在用的就是哎。
create PROCEDURE pro_demo
@action varchar(20)
AS
BEGIN
SET NOCOUNT ON;
-------------------------------------- 定义变量
declare
@method varchar(20),
@err varchar(20)
if @action='1'
begin
set @method='1'
goto res
end
if @action='2'
begin
set @method='2'
goto res
end
if @action='3'
begin
set @method='3'
goto res
end
set @err='方法没有匹配到'
-- 貌似就是 类似的 哎 骑驴找驴.......
-- switch(){
-- case '1':
-- 方法1 ;
-- break;
-- case '2':
-- 方法2 ;
-- break;
-- case '3':
-- 方法3 ;
-- break;
-- default:
-- 错误 ;
-- break;
-- }
res:
END
GO
版权声明
本文为[轻轻的走过]所创,转载请带上原文链接,感谢
https://my.oschina.net/qingqingdego/blog/4707974
边栏推荐
猜你喜欢
PAT_ Grade A_ 1056 Mice and Rice
线程池运用不当的一次线上事故
Liteos message queuing
![[elastic search technology sharing] - ten pictures to show you the principle of ES! Understand why to say: ES is quasi real time!](/img/4b/176185ba622b275404e2083df4f28a.jpg)
[elastic search technology sharing] - ten pictures to show you the principle of ES! Understand why to say: ES is quasi real time!
Travel notes of Suzhou
Implementation of warehouse management system with ABP (net core) + easyUI + efcore

函数分类大pk!sigmoid和softmax,到底分别怎么用?
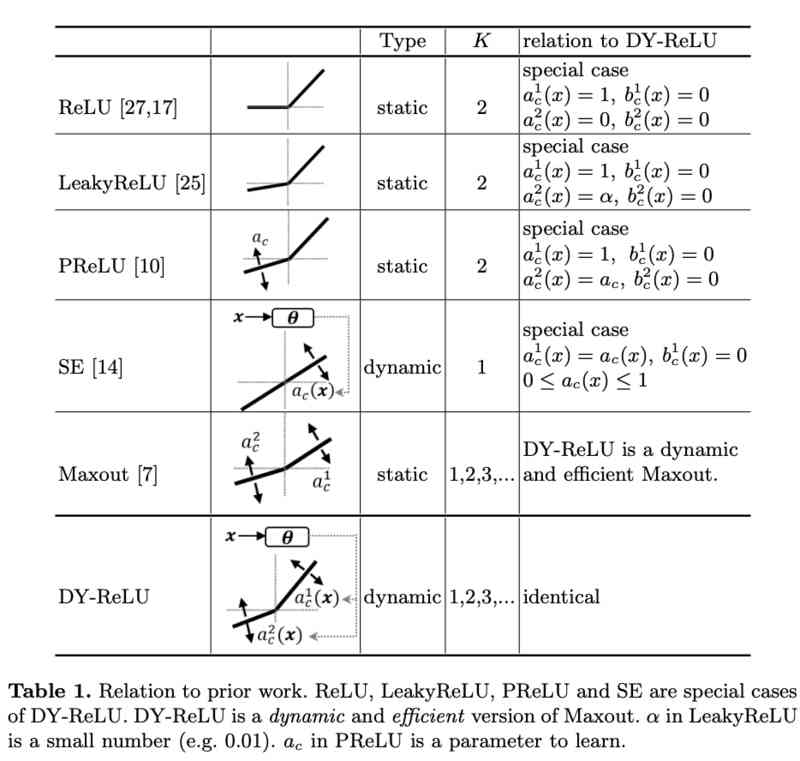
Dynamic relu: Microsoft's refreshing device may be the best relu improvement | ECCV 2020
趣文分享:C 语言和 C++、C# 的区别在什么地方?
Summary of interface test case ideas
随机推荐
C + + opencv4.3 sift matching
SQL quick query
Chapter 5 programming
Five phases of API life cycle
AI perfume is coming. Will you buy it?
搭载固态硬盘的服务器究竟比机械硬盘快多少
net.sf.json . jsonobject's format processing of time stamp
An online accident caused by improper use of thread pool
Django之简易用户系统(3)
Dynamic relu: Microsoft's refreshing device may be the best relu improvement | ECCV 2020
jsliang 求职系列 - 07 - Promise
Mongodb add delete modify query operation
Application of four ergodic square of binary tree
awk实现类sql的join操作
给大家介绍下,这是我的流程图软件 —— draw.io
write文件一个字节后何时发起写磁盘IO
11 important operations of Python list
Simulink中封装子系统
Suffix expression to infix expression
实验