当前位置:网站首页>Intensive learning notes: Sutton book Chapter III exercise explanation (ex17~ex29)
Intensive learning notes: Sutton book Chapter III exercise explanation (ex17~ex29)
2022-07-06 15:17:00 【Slow ploughing of stupid cattle】
Catalog
Exercise 3.17
What is the Bellman equation for action values, that is, for  ? It must give the action value
? It must give the action value  in terms of the action values,
in terms of the action values,  , of possible successors to the state–action pair (s, a). Hint: The backup diagram to the right corresponds to this equation. Show the sequence of equations analogous to (3.14), but for action values.
, of possible successors to the state–action pair (s, a). Hint: The backup diagram to the right corresponds to this equation. Show the sequence of equations analogous to (3.14), but for action values.
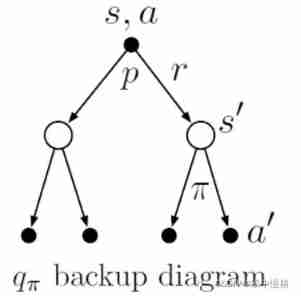
Explain :
As above backup diagram Shown , from (s,a) Go to every possible s' The probability of is determined by p decision , The total return of each branch includes two parts , One is immediate return r, The second is the state s' State value function of ( Of course, there should be a discount ), It can be obtained. ( stay Exercise 3.13[https://blog.csdn.net/chenxy_bwave/article/details/122522897] We have got this relationship ):

further , Same basis backup diagram You can get ( You can refer to Exercise 3.12) The expression of state value function expressed by action value function is as follows :

take (2) Plug in (1) Formula to get :

This is the Behrman equation about the action value function !
By the way , Because the state value function and the action value function can express each other , So from the mutual expression of the two , By substituting the elimination method to eliminate one, we can get another Behrman equation . For the derivation of Behrman equation of state value function, see Strengthen learning notes : Strategy 、 Value function and Behrman equation
Exercise 3.18
The value of a state depends on the values of the actions possible in that state and on how likely each action is to be taken under the current policy. We can think of this in terms of a small backup diagram rooted at the state and considering each possible action:

Give the equation corresponding to this intuition and diagram for the value at the root node,  , in terms of the value at the expected leaf node, , given
, in terms of the value at the expected leaf node, , given  . This equation should include an expectation conditioned on following the policy
. This equation should include an expectation conditioned on following the policy  . Then give a second equation in which the expected value is written out explicitly in terms of
. Then give a second equation in which the expected value is written out explicitly in terms of  such that no expected value notation appears in the equation.
such that no expected value notation appears in the equation.
Explain : As shown in the figure above , From the State s You can start by The determined probability reaches each action node . The action function value of each action node is  . state s The status value of is The expectations of the .
. state s The status value of is The expectations of the .
![\begin{align} \mathbb{E}[X] &= \sum\limits_x x\cdot p(x) \\ Y &= g(X),\\ \mathbb{E}[Y] &= \sum\limits_x g(x)\cdot p(x) \end{align}](http://img.inotgo.com/imagesLocal/202202/13/202202131320305149_29.gif)
 , So we can get the expectation that the state value function is the action value function :
, So we can get the expectation that the state value function is the action value function :
![v_{\pi}(s) = \mathbb{E}_a[q_{\pi}(a,s)] = \sum\limits_{a}\pi(a|s)q_{\pi}(a,s)](http://img.inotgo.com/imagesLocal/202201/17/202201170129520876_19.gif%28s%29%20%3D%20%5Cmathbb%7BE%7D_a%5Bq_%7B%5Cpi%7D%28a%2Cs%29%5D%20%3D%20%5Csum%5Climits_%7Ba%7D%5Cpi%28a%7Cs%29q_%7B%5Cpi%7D%28a%2Cs%29)
Exercise 3.19
The value of an action , depends on the expected next reward and the expected sum of the remaining rewards. Again we can think of this in terms of a small backup diagram, this one rooted at an action (state–action pair) and branching to the possible next states:
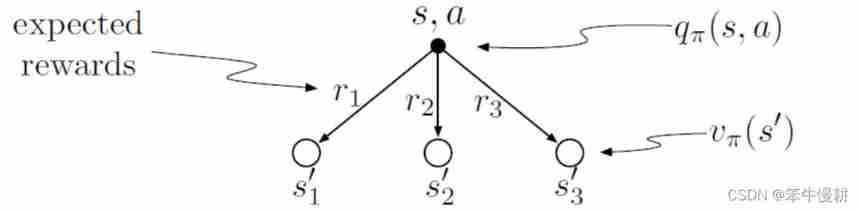
Give the equation corresponding to this intuition and diagram for the action value, , in terms of the expected next reward,  , and the expected next state value,
, and the expected next state value,  , given that St=s and At=a. This equation should include an expectation but not one conditioned on following the policy. Then give a second equation, writing out the expected value explicitly in terms of
, given that St=s and At=a. This equation should include an expectation but not one conditioned on following the policy. Then give a second equation, writing out the expected value explicitly in terms of  defined by (3.2), such that no expected value notation appears in the equation.
defined by (3.2), such that no expected value notation appears in the equation.
Explain :
from (s,a) Departure depends on probability Arrive at the branches as shown in the figure above . Access Rd k The total return includes  , And the state value function of the next state
, And the state value function of the next state  , It belongs to the next moment t+1 Of , Equivalent to the moment t Multiply by the discount factor . Therefore, we can get the expectation that the total return of branches is the return of each branch ( Probability weighted mean ):
, It belongs to the next moment t+1 Of , Equivalent to the moment t Multiply by the discount factor . Therefore, we can get the expectation that the total return of branches is the return of each branch ( Probability weighted mean ):
![\begin{align} G_{t+1}[k] &= R_{t+1} + \gamma v_{\pi}(S_{t+1}) \\ q_{\pi}(a,s) &= \mathbb{E}[G_{t+1}] \\ &= \sum\limits_{s',r}p(s',r|s,a)(r + \gamma v_{\pi}(s')) \end{align}](http://img.inotgo.com/imagesLocal/202202/13/202202131320305149_11.gif)
Exercise 3.20
Draw or describe the optimal state-value function for the golf example.
Exercise 3.21
Draw or describe the contours of the optimal action-value function for putting,  , for the golf example.
, for the golf example.
Exercise 3.22
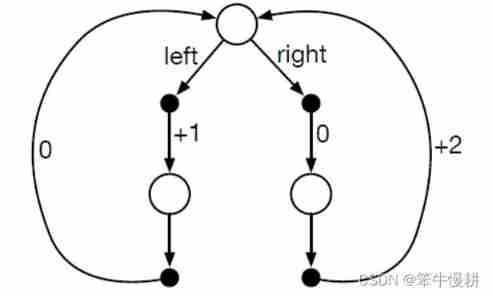
Consider the continuing MDP shown to the right. The only decision to be made is that in the top state,where two actions are available, left and right. The numbers show the rewards that are received deterministically after each action. There are exactly two deterministic policies,  and
and . What policy is optimal if
 = 0? If = 0.9? If = 0.5?
= 0? If = 0.9? If = 0.5?
Exercise 3.23
Give the Bellman equation for  for the recycling robot.
for the recycling robot.
Exercise 3.24
Figure 3.5 gives the optimal value of the best state of the gridworld as
24.4, to one decimal place. Use your knowledge of the optimal policy and (3.8) to express
this value symbolically, and then to compute it to three decimal places.
Exercise 3.25
Give an equation for  in terms of .
in terms of .
Explain : Is the optimal value function , By definition, it must be equal to in state s Take a certain action a, Then follow the optimal strategy to get the largest of the optimal action value functions , It can be obtained. :

Exercise 3.26
Give an equation for in terms of and the four-argument p.
Explain : Reference resources Exercise 3.19.
The optimal action value function must correspond to each next state s' The optimal state value function of , So there is :

Exercise 3.27
Give an equation for  in terms of .
in terms of .
Explain : Policy is used to change from a certain state s Set out to choose the action , Optimal strategy means from any state s Choose the corresponding optimal action when starting , Write it down as  , That is said , choice The probability of is 1, The probability of non optimal action is 0. Of course , It should be noted that , In a certain state s Next , There may be more than one optimal action . under these circumstances , Choose one of them . however , The action value function of multiple optimal actions must be equal .
, That is said , choice The probability of is 1, The probability of non optimal action is 0. Of course , It should be noted that , In a certain state s Next , There may be more than one optimal action . under these circumstances , Choose one of them . however , The action value function of multiple optimal actions must be equal .
First , state s The optimal action under satisfies the following equation :

secondly , The optimal strategy can be expressed as ( Here, for simplicity , Suppose there is only one optimal action in each state ):

Exercise 3.28
Give an equation for in terms of and the four-argument p.
Explain : combination 3.26 and 3.27( take 3.26 The solution of is substituted into 3.27 Solution ) You can get :

Exercise 3.29
Rewrite the four Bellman equations for the four value functions ( , , ,and ) in terms of the three argument function p (3.4) and the two-argument function r (3.5).
, , ,and ) in terms of the three argument function p (3.4) and the two-argument function r (3.5).
Explain :

And so on , A little .
Go back to the general catalogue : General catalogue of reinforcement learning notes  https://chenxiaoyuan.blog.csdn.net/article/details/121715424
https://chenxiaoyuan.blog.csdn.net/article/details/121715424
Sutton-RLbook( The first 2 edition ) The first 3 For the first half of this chapter, see : Strengthen learning notes :Sutton-Book Chapter III problem solving (Ex1~Ex16)https://blog.csdn.net/chenxy_bwave/article/details/122522897
边栏推荐
- 自动化测试中敏捷测试怎么做?
- Brief introduction to libevent
- CSAPP homework answers chapter 789
- ucore lab8 文件系统 实验报告
- What are the commonly used SQL statements in software testing?
- Global and Chinese market of portable and handheld TVs 2022-2028: Research Report on technology, participants, trends, market size and share
- Introduction to safety testing
- Sleep quality today 81 points
- 软件测试需求分析之什么是“试纸测试”
- Rearrange spaces between words in leetcode simple questions
猜你喜欢
![[Ogg III] daily operation and maintenance: clean up archive logs, register Ogg process services, and regularly back up databases](/img/31/875b08d752ecd914f4e727e561adbd.jpg)
[Ogg III] daily operation and maintenance: clean up archive logs, register Ogg process services, and regularly back up databases
Nest and merge new videos, and preset new video titles

接口测试面试题及参考答案,轻松拿捏面试官
Interview answering skills for software testing
Automated testing problems you must understand, boutique summary
几款开源自动化测试框架优缺点对比你知道吗?
ucore lab5用户进程管理 实验报告
Future trend and planning of software testing industry
软件测试工作太忙没时间学习怎么办?
软件测试面试要问的性能测试术语你知道吗?





随机推荐
遇到程序员不修改bug时怎么办?我教你
C4D quick start tutorial - Introduction to software interface
CSAPP家庭作業答案7 8 9章
Don't you even look at such a detailed and comprehensive written software test question?
软件测试方法有哪些?带你看点不一样的东西
What are the software testing methods? Show you something different
JDBC介绍
Express
Global and Chinese market of goat milk powder 2022-2028: Research Report on technology, participants, trends, market size and share
DVWA exercise 05 file upload file upload
線程及線程池
CSAPP homework answers chapter 789
Capitalize the title of leetcode simple question
Global and Chinese market of barrier thin film flexible electronics 2022-2028: Research Report on technology, participants, trends, market size and share
Install and run tensorflow object detection API video object recognition system of Google open source
如何成为一个好的软件测试员?绝大多数人都不知道的秘密
Brief description of compiler optimization level
Investment should be calm
Sorting odd and even subscripts respectively for leetcode simple problem
How to transform functional testing into automated testing?