In our previous article , We talked about Multimodal index The design of the , It's a way to Lakehouse Server free and high-performance indexing subsystem , To improve query and write performance . In this blog , We discussed the mechanisms needed to build such a powerful index , Design of asynchronous indexing mechanism , Be similar to PostgreSQL and MySQL And other popular database systems , It supports index building without blocking writes .
background
Apache Hudi Transactions and updates / Delete / Change streams are added to tables on top of elastic cloud storage and open file formats . Hudi A key internal component is the transaction database kernel , It coordinates the right Hudi Reading and writing of tables . The index is the latest subsystem of the kernel . All indexes are stored internally Hudi Merge-On-Read (MOR) In the table , namely The metadata table Keep synchronized with the data table on transactions , Even in case of failure . Metadata tables are also built as Hudi The table service manages itself , Just like the data sheet .
motivation
and Hudi Currently, three indexes are supported ; file 、column_stats and bloom_filter, The number and variety of big data make adding more indexes to further reduce I/O Cost and query latency are imperative . One way to build a new index is to stop all writers , Then create a new index partition in the metadata table , Then recover the writer . As we add more indexes , This may not be ideal , because ,a) It needs to be shut down ,b) It will not expand with more indexes . therefore , You need to dynamically add and delete indexes on tables that are concurrent with writes . Asynchronous indexing has two benefits , Improve write latency and decoupling faults . For those who are familiar with the database system “CREATE INDEX” People will understand how easy it is to create an index , Don't worry about continuous writing . Add an asynchronous index to Hudi A rich set of table services is attempted for Lakehouse Bring the ease of use of similar databases 、 Reliability and performance .
Design
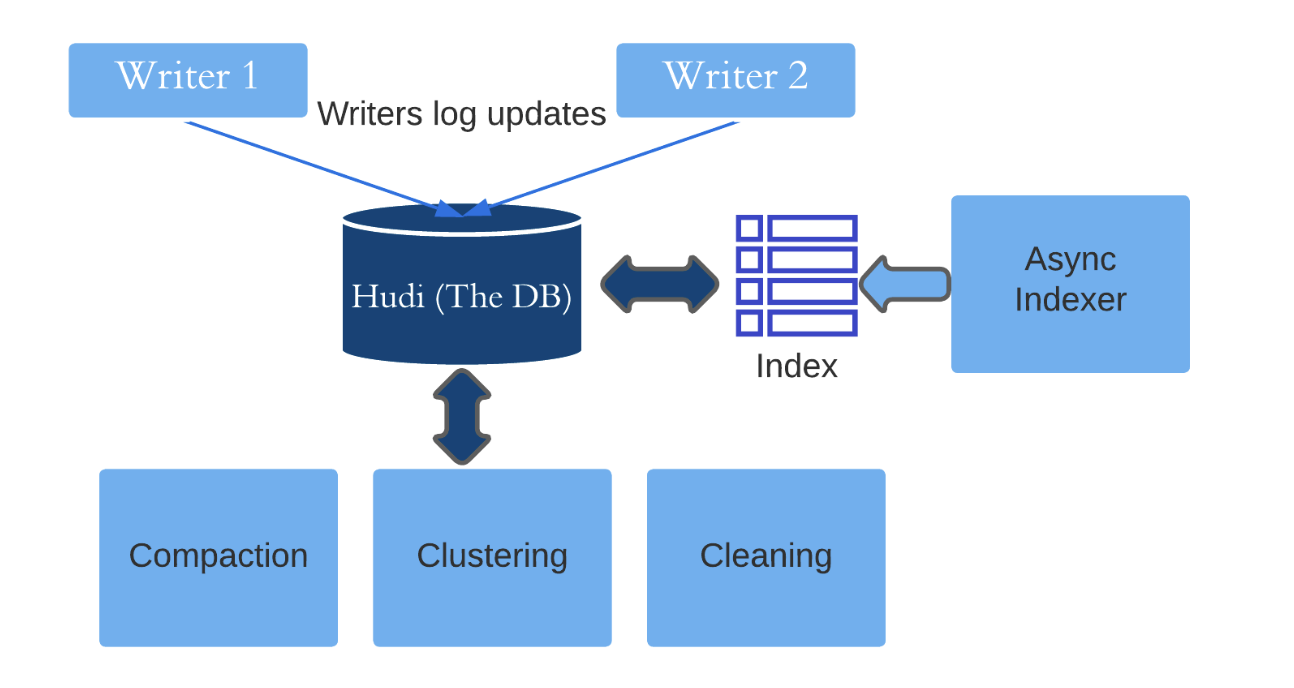
The core of asynchronous indexing with ongoing writes is to ensure that these writes can perform consistent updates to the index , Even if historical data is being indexed in the background . One way to deal with this problem is to lock the index partition completely , Until the historical data is indexed and then catch up . However , The possibility of conflict will only increase with the locking of long-running transactions . The solution of this problem depends on Hudi The three pillars of transaction kernel design :
Hudi File layout
Hudi The data files in the table are organized into file groups , Each filegroup contains multiple file slices . Each slice contains a basic file generated at a particular commit , And a set of log files containing updates to the basic files . This makes it possible to see fine-grained concurrency control in the next section . After initializing the filegroup and writing the basic file , Another writer can record updates to the same filegroup , And a new slice will be created .
Hybrid concurrency control
Asynchronous indexing uses a mixture of optimistic concurrency control and log based concurrency control models . Indexing is divided into two stages : Scheduling and execution .
In the scheduling process , Indexer ( The external process responsible for creating the new index ) Get a short lock , And generate an index plan for the data file , Until the last submission time t. It initializes the metadata partition corresponding to the requested index , And release the lock after this stage . This should take a few seconds , And no index file will be written at this stage .
During execution , Indexer execution plan , The base file will be indexed ( Corresponds to the moment t Data files for ) Write metadata partition . meanwhile , Regular ongoing writes continue to record updates to log files in the same filegroup as the base files in the metadata partition . After writing the basic document , The indexer will check t All subsequent submissions have been completed instant, To ensure that each of them adds entries according to its index plan , Otherwise just stop gracefully . This is when optimistic concurrency control starts , Use the metadata table lock to check whether the writer has affected the overlapping files , If there is a conflict , Then stop , Graceful abort ensures that indexing can be retried idempotent .
Hudi Timeline
Hudi Maintains a schedule of all operations performed on the table at different times . Think of it as an event log , As a core part of inter process coordination . Hudi A fine-grained log based concurrency protocol is implemented on the timeline . To distinguish the index from other write operations , We have introduced a time line called “ Indexes ” New actions for . The state transition of this operation is handled by the indexer . The scheduling index will add a “indexing.requested” instant. The execution phase converts the plan into “inflight” state , Then it is finally converted to “completed” state . The indexer locks only when adding events to the timeline , Instead of locking when writing index files .
The advantages of this design are as follows :
- Data writing and indexing are separate , But they know each other .
- It can be extended to other types of indexes .
- It is suitable for batch and streaming workloads .
Use the timeline as the event log , The mixture of the two concurrency models provides excellent scalability and asynchrony , So that the indexing process and writers and other table Services ( Such as compaction and clustering) Running at the same time .
file
More details about the design and implementation of indexer , Please check out RFC-45. To set up and view the running indexer , Please follow Asynchronous index guide .
Future work
The asynchronous indexing function is Lakehouse First in architecture , It's still evolving . Although the index can be created at the same time as the writer , But deleting indexes requires table level locking , Because tables are usually read by other readers / Writer threads use . therefore , One task is to overcome the current limitation by delaying the deletion of indexes and increasing the amount of asynchrony , So that multiple indexes can be created or deleted at the same time . Another task is to enhance the availability of indexers ; And SQL Integrate with other types of indexes , For example, the second bond Bloom Indexes , be based on Lucene Secondary index of (RFC-52) etc. . We welcome more ideas and contributions from the community .
Conclusion
Hudi The multimodal index and asynchronous index functions of show , Transaction data lake is more than table format and metadata . The basic principle of distributed storage system also applies to Lakehouse framework , And the challenges appear on different scales . Asynchronous indexing on this scale will soon become a necessity . We discussed a method that can be extended to other index types 、 Scalable and non blocking design , And will continue to add more functions to the indexing subsystem based on this framework .
![[daiy5] jz77 print binary tree in zigzag order](/img/ba/b2dfbf121798757c7b9fba4811221b.png)