当前位置:网站首页>Machine learning practice: is Mermaid a love movie or an action movie? KNN announces the answer
Machine learning practice: is Mermaid a love movie or an action movie? KNN announces the answer
2022-07-02 09:12:00 【Qigui】
Author's brief introduction : The most important part of the whole building is the foundation , The foundation is unstable , The earth trembled and the mountains swayed . And to learn technology, we should lay a solid foundation , Pay attention to me , Take you to firm the foundation of the neighborhood of each plate .
Blog home page : Qigui's blog
Included column :《 Statistical learning method 》 The second edition —— Personal notes
From the south to the North , Don't miss it , Miss this article ,“ wonderful ” May miss you la
Triple attack( Three strikes in a row ):Comment,Like and Collect—>Attention
List of articles
problem :
It is known that 《 Warwolf 》《 The red sea action 》《 Mission: impossible 6》 Action movie. , and 《 The former 3》《 Chunjiao saves Zhiming 》《 Titanic Number 》 It's romance. . But if ⼀ Dan now has ⼀ A new movie 《 Mermaid 》, Is there any ⼀ There are two ways for the machine to master ⼀ Rules of classification , Automatically classify new movies ?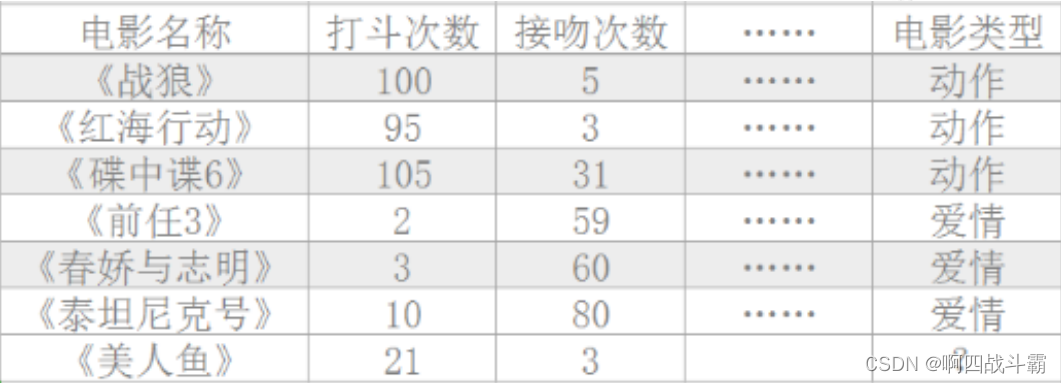
Visualize the data
Because the data in the above table does not look intuitive , So visualize .
The code is as follows :
# Data visualization , Visually observe the classification of movie data
import matplotlib.pyplot as plt
# matplotlin Chinese display is not supported by default —— adopt rcParams Configuration parameters
plt.rcParams['font.sans-serif'] = ['SimHei'] # Step one ( Replace sans-serif typeface )
plt.rcParams['axes.unicode_minus'] = False # Step two ( Solve the problem of negative sign display of coordinate axis negative numbers )
# 1. get data
# 2. Basic data processing
# 3. Data visualization
x = [5,3,31,59,60,80] # x The axis represents the number of kisses
y = [100,95,105,2,3,10] # y The axis represents the number of fights
labels = ["《 Warwolf 》","《 The red sea action 》","《 Mission: impossible 6》","《 The former 3》","《 love in a puff 》","《 Titanic 》"]
# Set scales and labels
plt.scatter(x,y,s=120)
plt.xlabel(" Number of kisses ")
plt.ylabel(" Number of fights ")
plt.xticks(range(0,150,10))
plt.yticks(range(0,150,10))
# Add annotation text to each point
count = 0
for x_i,y_i in list(zip(x,y)): # use zip take x,y package , Then turn to the list
plt.annotate(f"{
labels[count]}",xy=(x_i,y_i),xytext=(x_i,y_i))
count+=1
plt.show()
The output result is shown below :
thus , The data in the table is clear at a glance .
But we don't know 《 Mermaid 》 Which point is closer to this point , How to calculate 《 Mermaid 》 The distance between this point and other points ?—— Two point distance
The distance between two points is also called Euclidean distance : d = ( x 1 − y 1 ) 2 + ( x 2 − y 2 ) 2 d=\sqrt{\left ( x_{1} -y_{1}\right )^2+\left ( x_{2}-y_{2} \right )^2} d=(x1−y1)2+(x2−y2)2
Know the article in detail :
Concept to method , great 《 Statistical learning method 》—— The third chapter 、k Nearest neighbor method
current demand It's calculation 《 Mermaid 》 Distance from each movie . We may all think , Only look for ⼀ The nearest neighbor to judge 《 Mermaid 》 Isn't it just the type of ? In fact, this approach is not feasible .
Here's a chestnut :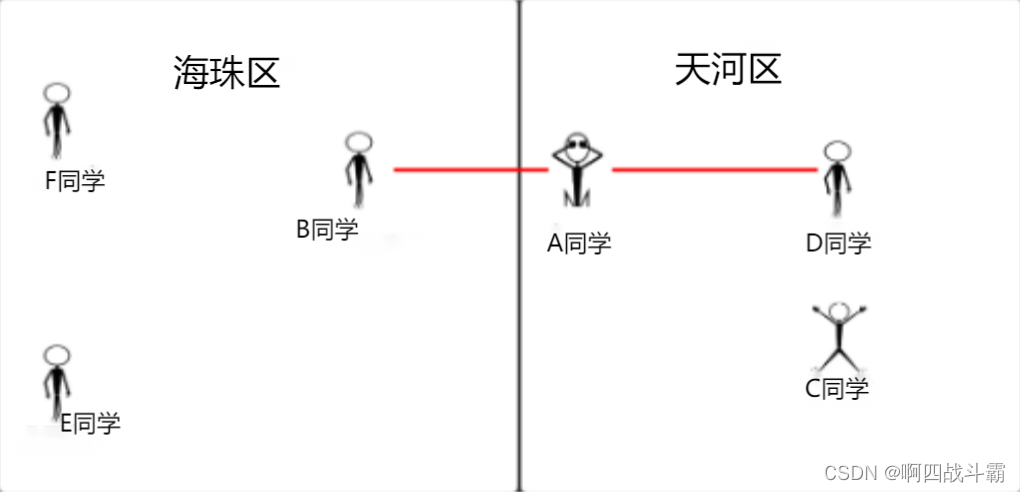
In the figure A Classmates and B、D The distance between the two students is equal , These two students are in different districts , Then you can't judge A Which district does the student belong to . in other words , We should find more neighbors , In order to determine its classification more accurately . Compare this movie classification to determine the selection 3 A close neighbor , in other words k=3.
In the last article ( Concept to method , great 《 Statistical learning method 》—— The third chapter 、k Nearest neighbor method ) As detailed in KNN Workflow , Here is a brief memory .
summary KNN Workflow :
- 1. Calculate the distance between the object to be classified and other objects ;
- 2. Count the nearest K A neighbor ;
- 3. about K The nearest neighbor , Which category do they belong to the most , Where the object to be classified belongs ⼀ class .
There are two implementations :
1、Numpy Realization
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # Step one ( Replace sans-serif typeface )
plt.rcParams['axes.unicode_minus'] = False # Step two ( Solve the problem of negative sign display of coordinate axis negative numbers )
# 1. Prepare the data
# Training data characteristics and objectives
# Test data characteristics and objectives
# 2. Calculate the Euclidean distance between unknown data features and training data features
# 3. Count the nearest K A neighbor
# 4. Make category statistics
class Myknn(object):
def __init__(self, train_df, k):
""" :param train_df: Training data :param k: Number of nearest neighbors """
self.train_df = train_df
self.k = k
# Calculate forecast data And Training data distance
# Select minimum distance k It's worth
# Calculation k Of the values Categories Proportion
def predict(self, test_df):
""" Prediction function """
# Calculate the Euclidean distance —— Use nupy Calculated distance
self.train_df[' distance '] = np.sqrt(
(test_df[' Number of fights '] - self.train_df[' Number of fights ']) ** 2 + (test_df[' Number of kisses '] - self.train_df[' Number of kisses ']) ** 2)
# Sort by distance Get the one with the smallest distance front K Categories of data
my_types = self.train_df.sort_values(by=' distance ').iloc[:self.k][' Film type ']
print(my_types)
# Yes k Classification of points for statistics , See who accounts for more , The predicted value belongs to which category
new_my_type = my_types.value_counts().index[0]
print(new_my_type)
# 1. Reading data
my_df = pd.read_excel(' Movie data .xlsx', sheet_name=0)
# print(my_df)
# 2. Basic data processing
# 3. Feature Engineering
# 4. Data visualization ( Omit )
# 2. Training data Characterized features : The number of fights and kisses Initialize tags ( Category ): Film type
train_df = my_df.loc[:5, [" Number of fights ", " Number of kisses ", " Film type "]]
# 3. Forecast data
test_df = my_df.loc[6, [" Number of fights ", " Number of kisses ", ]]
# 4. Algorithm implementation —— Instantiate the class
mk = Myknn(train_df, 3) # k=3
mk.predict(test_df)
Output results :
3 love
4 love
5 love
Name: Film type , dtype: object
love
2、Sklearn Realization
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=‘uniform’, algorithm=‘auto’)
- n_neighbors: By default kneighbors Number of neighbors used by query . Namely k-NN Of k Value , Pick the nearest k A little bit . Number of adjacent points , namely k The number of .( The default is 5)
- weights: The default is “uniform” It means that each nearest neighbor is assigned the same weight , That is to determine the weight of the nearest neighbor ; Can be specified as “distance” It indicates that the distribution weight is inversely proportional to the distance of the query point ; At the same time, you can also customize the weight .
- algorithm: Nearest neighbor algorithm , Optional {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}. Optional fast k Nearest neighbor search algorithm , The default parameter is auto, It can be understood that the algorithm decides the appropriate search algorithm by itself ; You can also specify your own search algorithm ball_tree、kd_tree、brute Method to search ,brute It's brute force search , That's linear scanning .
step :
- 1、 Build feature data and target data
- 2、 structure k A nearest neighbor classifier
- 3、 send ⽤fit Training
- 4、 Forecast data
from sklearn.neighbors import KNeighborsClassifier
# 1. Reading data
mv_df = pd.read_excel(" Movie data .xlsx",sheet_name=0)
# 2. Build the characteristic data of the training set —— Be careful : Two dimensional arrays
x = mv_df.loc[:5," Number of fights ":" Number of kisses "].values
# 3. Build the target data of the training set —— Be careful : One dimensional array
y = mv_df.loc[:5," Film type "].values
# 4. Instantiation KNN Algorithm ( classifier )
knn = KNeighborsClassifier(n_neighbors=4)
# 5. Training —— Characteristic data of training set Target data of training set
knn.fit(x,y)
# 6. Forecast data
knn.predict([[5,29]])
Output results :
[' love ']
therefore , Through training KNN Model , Finally it is concluded that 《 Mermaid 》 It's a love movie .
The learning :
Bloggers are determined to understand every knowledge point . Why? ? I've read an article about the learning experience shared by a big man , One of them is very good :【 Basic knowledge is like the foundation of a building , It determines the height of our technology , And to do something quickly , The precondition must be that the basic ability is excellent ,“ Internal skill ” In place 】. therefore , Since then, I have focused on a solid foundation , And I know , Learning technology can't be learned overnight , Not for half a year 、 A year , Or two years , Even longer ; But I believe , Persistence is never wrong . Last , I want to say : Focus on the basics , Establish your own knowledge system .
Okay , This learning sharing is over . Mix a —— How many of the above seven movies have you seen ? Which one do you like best ? Tell me in the comment area ! Hey ,, I can't help but hurry to see it before studying .
Knowledge review :
Concept to method , great 《 Statistical learning method 》—— The third chapter 、k Nearest neighbor method
边栏推荐
- 微服务实战|声明式服务调用OpenFeign实践
- 概念到方法,绝了《统计学习方法》——第三章、k近邻法
- 将一串数字顺序后移
- C4D quick start tutorial - C4d mapping
- Matplotlib剑客行——容纳百川的艺术家教程
- Matplotlib剑客行——布局指南与多图实现(更新)
- Win10 uses docker to pull the redis image and reports an error read only file system: unknown
- 机器学习实战:《美人鱼》属于爱情片还是动作片?KNN揭晓答案
- 微服务实战|原生态实现服务的发现与调用
- Gocv split color channel
猜你喜欢

【Go实战基础】gin 如何自定义和使用一个中间件
Redis安装部署(Windows/Linux)
![[go practical basis] gin efficient artifact, how to bind parameters to structures](/img/c4/44b3bda826bd20757cc5afcc5d26a9.png)
[go practical basis] gin efficient artifact, how to bind parameters to structures
![[go practical basis] how to install and use gin](/img/0d/3e899bf69abf4e8cb7e6a0afa075a9.png)
[go practical basis] how to install and use gin

十年開發經驗的程序員告訴你,你還缺少哪些核心競爭力?
Cloudrev self built cloud disk practice, I said that no one can limit my capacity and speed
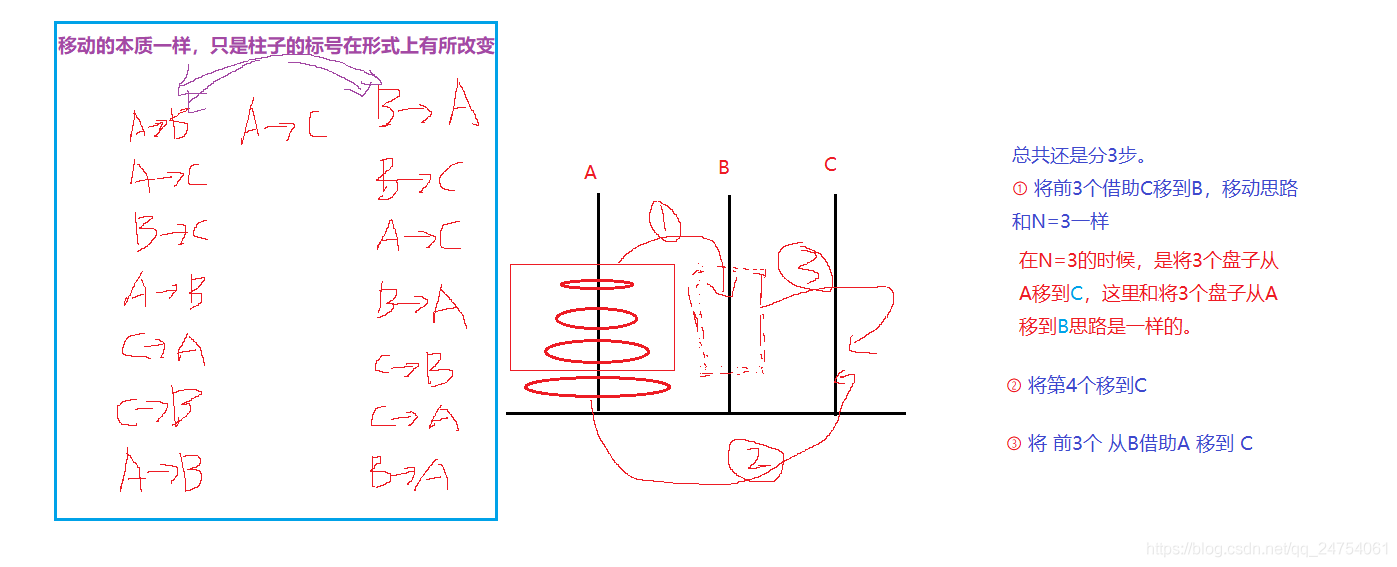
汉诺塔问题的求解与分析
Programmers with ten years of development experience tell you, what core competitiveness do you lack?
Microservice practice | declarative service invocation openfeign practice
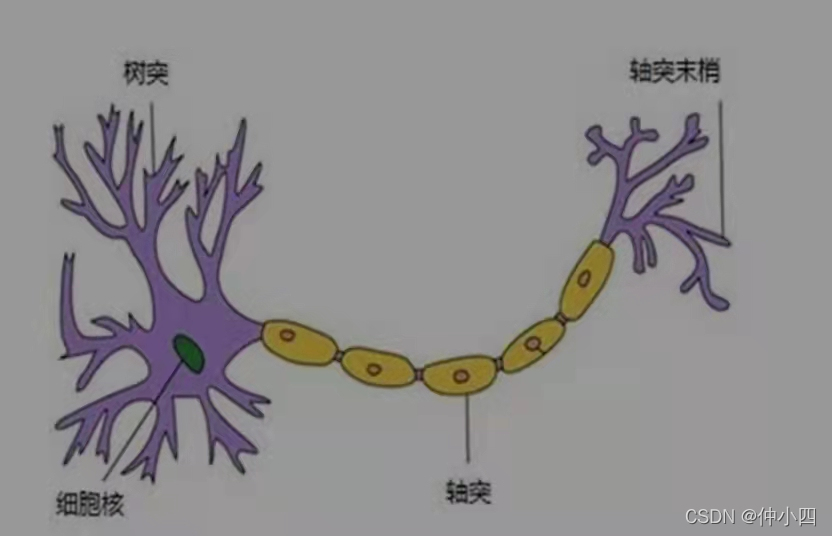
Watermelon book -- Chapter 5 neural network
随机推荐
[go practical basis] how to set the route in gin
win10使用docker拉取redis镜像报错read-only file system: unknown
Minecraft module service opening
Watermelon book -- Chapter 5 neural network
[staff] time sign and note duration (full note | half note | quarter note | eighth note | sixteenth note | thirty second note)
「面试高频题」难度大 1.5/5,经典「前缀和 + 二分」运用题
C#钉钉开发:取得所有员工通讯录和发送工作通知
Minecraft install resource pack
Installing Oracle database 19C for Linux
以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
1、 QT's core class QObject
Redis安装部署(Windows/Linux)
Microservice practice | load balancing component and source code analysis
Minecraft air Island service
微服务实战|微服务网关Zuul入门与实战
【Go实战基础】gin 如何设置路由
微服务实战|Eureka注册中心及集群搭建
Chrome用户脚本管理器-Tampermonkey 油猴
Redis zadd导致的一次线上问题排查和处理
数构(C语言--代码有注释)——第二章、线性表(更新版)