当前位置:网站首页>深拷贝真难
深拷贝真难
2022-07-05 13:47:00 【wade3po】
深拷贝浅拷贝的原理我是已经懂了,之前也有分享过。只是深拷贝浅拷贝的方法却从来没有真的去了解过。
想想之前的面试,问到深拷贝浅拷贝的时候,都是说一下原理,问到方法,张口就来JSON.parse和JSON.stringify,如果有函数的话就递归循环拷贝。却从来没有写过递归或者循环拷贝的函数。
今天写了一下深拷贝数据的函数,发现深拷贝其实好难好难,单单一个数据的深拷贝就让我觉得脑壳都受不了了,更别说一些大佬们还提到了原型链、dom、RegExp、函数、浏览器内置函数之类的是否拷贝或者说怎么处理,再加上兼容,以后出去再也不敢说能写出深拷贝函数了。
今天也不是写个什么好的深拷贝函数,单纯的写一下数据处理的深拷贝,虽然对于json对象的深拷贝JSON.parse和JSON.stringify是最简单的,只是让自己稍微见见世面。
先上一个递归深拷贝的函数:
function clone(data) {
var target = data;
if(isObject(data)){
target = {};
for(var i in data) {
target[i] = clone(data[i])
}
}
if(isArray(data)){
target = [];
for (let i = 0; i < data.length; i++) {
target[i] = clone(data[i])
}
}
return target;
}
function isObject(x){
return Object.prototype.toString.call(x) === '[object Object]';
}
function isArray(x){
return Object.prototype.toString.call(x) === '[object Array]';
}
很简单,判断传进来的参数是否是数组或者对象,这边对数组或者对象的判断比较严格,如果是就分别循环递归拷贝子对象。这只是对对象和数组的深拷贝。for in我们都知道会遍历出自身和原型链上可枚举的属性,有时候我们是不想拷贝这些的。所以这边兼容就要在for in里面加上data.hasOwnProperty的判断。
基本上递归的拷贝都能理解,但是如果一个数据层级太多,会出现爆栈:
Maximum call stack size exceeded
包括JSON.parse和JSON.stringify也会。
这时候就要循环深拷贝了,直接上代码:
function cloneLoop(x) {
let target = '';
if(isObject(x)){
target = {};
};
if(isArray(x)){
target = [];
}
const loopList = [
{
parent: target,
key: undefined,
data: x,
}
];
while(loopList.length) {
const node = loopList.pop();
const parent = node.parent;
const key = node.key;
const data = node.data;
let res = parent;
if(typeof key !== 'undefined'){
if(isObject(data)) {
res = parent[key] = {};
};
if(isArray(data)) {
res = parent[key] = [];
}
}
if(isObject(data)){
for(let k in data) {
initLoopList(data[k], k, res);
}
}
if(isArray(data)){
for (let i = 0; i < data.length; i++) {
initLoopList(data[i], i, res);
}
}
}
function initLoopList(val, key, res) {
if (isObject(val) || isArray(val)) {
loopList.push({
parent: res,
key: key,
data: val,
});
} else {
res[key] = val;
}
}
return target;
}
function isObject(val){
return Object.prototype.toString.call(val) === '[object Object]'
}
function isArray(val){
return Object.prototype.toString.call(val) === '[object Array]'
}
我自己都不知道要这么去注释这个函数,精华就是这两个引用:
res = parent[key] = {};
res = parent[key] = [];
就是对引用稍微绕了一点,可以自己理解一下。
深拷贝暂时只能是了解到这种程度了,当然,一般来说数据不会有这么深的层级。这只是最简单的对数组对象的拷贝,没有涉及函数、dom或者原型链这些,连数据的引用都没考虑进去,比如:
let a = {};
let b = {b:b, c:c};
这种情况还得考虑是否保留引用还是创建新的。
最后提个序列化和反序列化的概念,今天分享的其实就是针对可以序列化和发序列化的数据。百度百科上面对序列化的定义:
序列化是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
不同语言有不同的方法,百度百科上面Java的序列化是转成二进制,反序列化是将二进制转成对象。而JavaScript我理解的序列化就是对象转成字符串,发序列化把字符串转成对象。

边栏推荐
- Summit review | baowanda - an integrated data security protection system driven by compliance and security
- ETCD数据库源码分析——rawnode简单封装
- Aikesheng sqle audit tool successfully completed the evaluation of "SQL quality management platform grading ability" of the Academy of communications and communications
- 搭建一个仪式感点满的网站,并内网穿透发布到公网 2/2
- Personal component - message prompt
- 53. 最大子数组和:给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
- Resttemplate details
- Operational research 68 | the latest impact factors in 2022 were officially released. Changes in journals in the field of rapid care
- 53. Maximum subarray sum: give you an integer array num, please find a continuous subarray with the maximum sum (the subarray contains at least one element) and return its maximum sum.
- Liar report query collection network PHP source code
猜你喜欢

那些考研后才知道的事
Jenkins installation

Laravel framework operation error: no application encryption key has been specified
The development of speech recognition app with uni app is simple and fast.

NFT value and white paper acquisition

【华南理工大学】考研初试复试资料分享
Idea设置方法注释和类注释

"Baidu Cup" CTF competition in September, web:upload

MySQL - database query - sort query, paging query
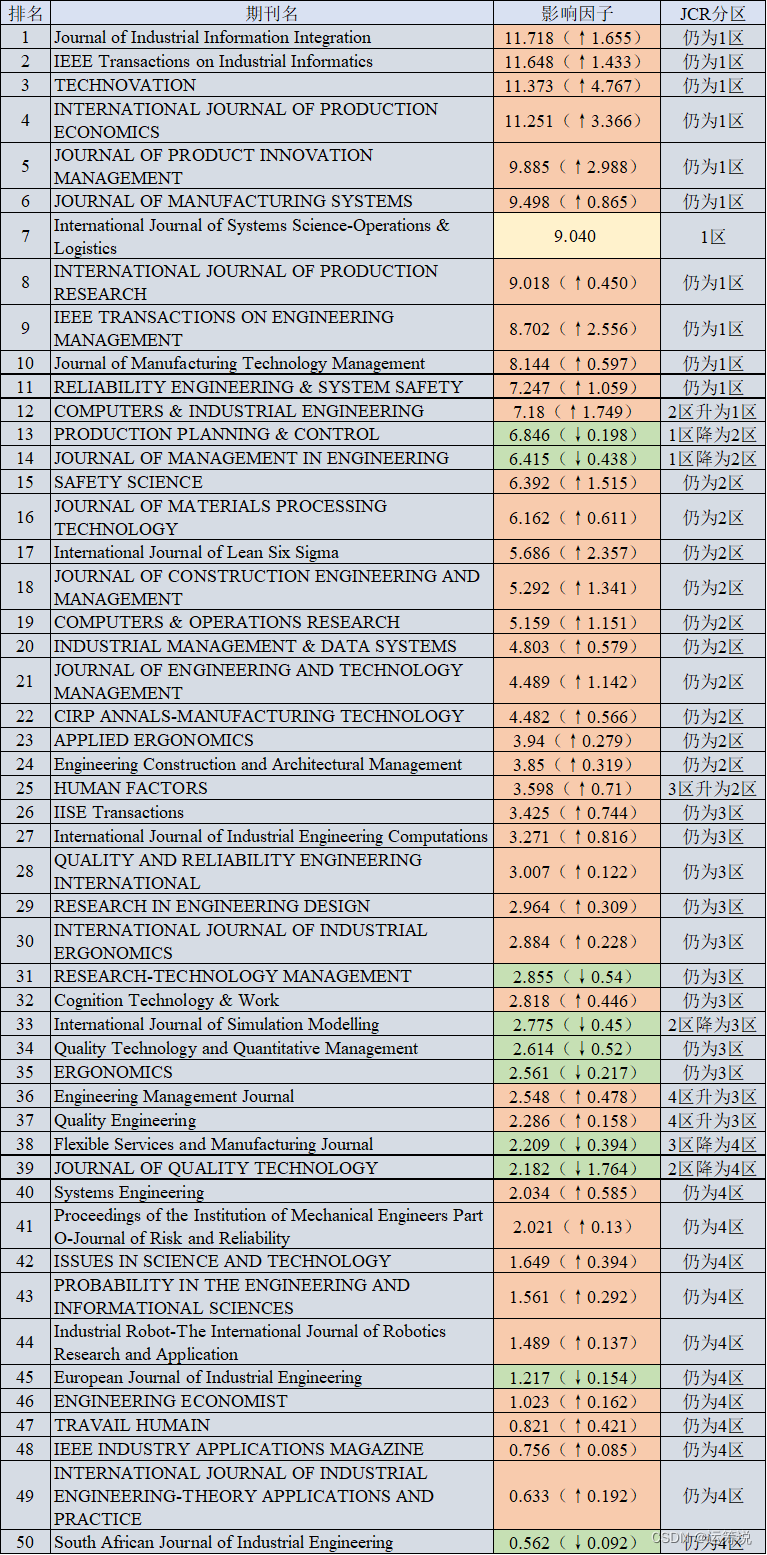
Operational research 68 | the latest impact factors in 2022 were officially released. Changes in journals in the field of rapid care
随机推荐
kafaka 日志收集
我为什么支持 BAT 拆掉「AI 研究院」
js 从一个数组对象中取key 和value组成一个新的对象
Network security - Novice introduction
不知道这4种缓存模式,敢说懂缓存吗?
私有地址有那些
Catch all asynchronous artifact completable future
Integer = = the comparison will unpack automatically. This variable cannot be assigned empty
Nantong online communication group
【MySQL 使用秘籍】一网打尽 MySQL 时间和日期类型与相关操作函数(三)
Summit review | baowanda - an integrated data security protection system driven by compliance and security
Internal JSON-RPC error. {"code":-32000, "message": "execution reverted"} solve the error
stm32逆向入门
Aikesheng sqle audit tool successfully completed the evaluation of "SQL quality management platform grading ability" of the Academy of communications and communications
Ordering system based on wechat applet
RK3566添加LED
Zhubo Huangyu: it's really bad not to understand these gold frying skills
TortoiseSVN使用情形、安装与使用
restTemplate详解
Primary code audit [no dolls (modification)] assessment