[ Paper reading notes ] Large-Scale Heterogeneous Feature Embedding
The structure of this paper
- solve the problem
- Main contributions
- Algorithm principle
- reference
(1) solve the problem
- Consider all kinds of information sources of nodes in the network , So we learn that a unified node representation can improve the accuracy of downstream tasks . However , Heterogeneous feature information limits the scalability of existing attribute network representation algorithms .( For example, the type of feature 、 The numbers and dimensions are huge )
(2) Main contributions
Contribution 1: The problem of large-scale heterogeneous feature representation is defined .( Heterogeneous features should refer to different types of features )
Contribution 2: Put forward an effective framework FeatWalk To integrate the high-dimensional and multi-type features of nodes into the node representation .
Contribution 3:
An effective algorithm is designed to avoid computing node similarity , It also provides an alternative way to simulate the random walk based on similarity to model the local similarity of nodes ( In this paper, we prove that this alternative method is equivalent to random walk based on the similarity of node attributes ).
(3) Algorithm principle
FeatWalk It can be applied to the case that a network has multiple network topologies and multiple heterogeneous characteristic matrices ( That is, multiple heterogeneous information sources can be combined ).
The following is an example of a single network topology and a single characteristic matrix .
FeatWalk The main framework of the algorithm is shown in the figure below :
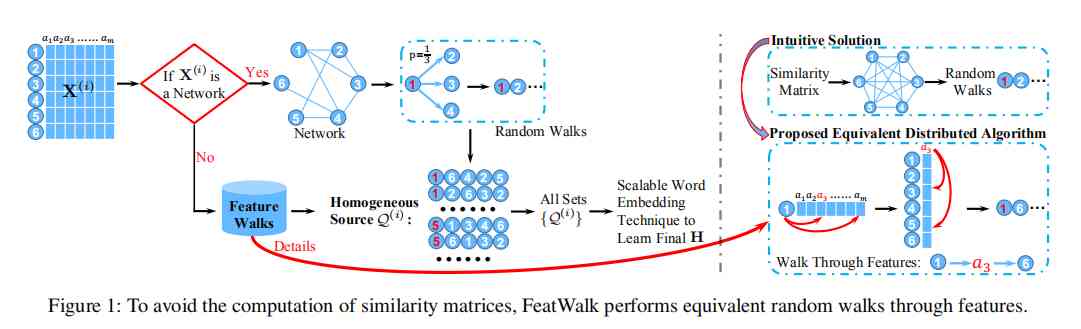
As can be seen from the picture FeatWalk The algorithm consists of three parts :
-
First step , Topology Random Walk sampling network topology information : Be similar to DeepWalk The random walk of , Completely random , I won't repeat .
-
The second step , Feature random walk sampling network feature information : Traditional random walk based on attribute similarity , We need to calculate the attribute similarity between each pair of nodes to construct the attribute graph , So we can walk randomly on the attribute graph . However, there are several problems with this intuitive approach . First of all , With the scale of the network N The increase of , Attribute similarity matrix S The size of the exponential growth . Yes S The computational storage and operation overhead of the . second , The newly constructed attribute graph S It's quite dense , Random walk does not work well on this graph and it costs a lot . Therefore, this paper proposes a random walk based on node features, which can get similar results to random walk based on attribute similarity without calculating attribute similarity , It is also suitable for many different types of eigenmatrices . From the picture above, we can easily summarize the main idea of feature wandering : That is, each time the feature matrix selects the attribute with larger value in the current node according to probability , In the attribute column corresponding to the attribute, the node with larger value on the attribute is selected as the next hop node according to probability . This is the characteristic walk proposed in this paper . It is proved that the output of the design feature walk is equivalent to the output of random walk based on attribute similarity matrix ( I won't go over it here ). Besides , This paper also proposes to calculate the walk length of each node as the starting point according to the complexity of the node itself , As shown in the following formula .
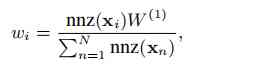
W(1) It's for this eigenmatrix X The total number of trips allocated ( The topological structure graph takes the adjacency matrix as the characteristic matrix ). How to allocate the total expectation to each node . As shown in the above formula , If there are more non-zero elements in the eigenvector of a node , Indicates that the more complex the node is , The more times it takes to swim, the more information can be captured . The design of the formula is based on the following two assumptions , First of all , The more non-zero elements of a node's eigenvector , It indicates that there are more edges in the graph , Assuming that m strip , So at least traverse m Only then can he capture his relationship with all his neighbors . second , Nodes with more edges in the network are more important . In order to keep the local similarity of these nodes better , We sample more sequences for them . -
The third step , Training Skip-Gram Learning nodes represent vectors ( I won't repeat ).
(4) reference
Huang X, Song Q, Yang F, et al. Large-scale heterogeneous feature embedding[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 3878-3885.