当前位置:网站首页>Performance comparison of tidb for PostgreSQL and yugabytedb on sysbench
Performance comparison of tidb for PostgreSQL and yugabytedb on sysbench
2022-07-07 16:11:00 【Digital China cloud base】
Catalog
background
PostgreSQL Is a well-known open source database product , As a digital infrastructure, it plays an important role in large enterprise applications , Many of its advanced features are widely used in various complex scenes .
according to Stack Overflow 2022 Developer survey report Show ,PostgreSQL beyond MySQL Become developers' favorite database software .

In the field of database in recent years, distributed database is the current development trend , be based on PostgreSQL The distributed database of the protocol was born abroad, such as CockroachDB、YugabyteDB Such an excellent product , And domestic popular distributed databases TiDB The official only offers MySQL Protocol support , Digital China technology team based on open source TiDB Research and development TiDB For PostgreSQL edition , At present, it has achieved compatibility with mainstream applications , Reference material :
- TiDB for PostgreSQL— a master hand 's first small display
- TiDB for PostgreSQL Learning Guide
- TiDB for PostgreSQL Compatible with GitLab
They belong to NewSQL Category and realize PG agreement , But there are still differences in the implementation of the specific architecture , We are very curious about the performance comparison between the two .
Test plan
Get ready 3 Physical machines are used to build distributed databases , Build separately 3 Node YugabyteDB Clusters and TiDB For PostgreSQL colony , Deploy all with default parameters , Use on the database Haproxy Acting as a load balancing agent . In this way, the deployment architecture of the two can be consistent as much as possible , Reduce the experimental error .
Deployment environment :
| Machine name | Parameter values | remarks |
|---|---|---|
| Database nodes -1 | The physical machine ,NUC 10 x86,12c 64G 1Tssd | yugabytedb:1 individual master、1 individual tserver tidb4pg:1 individual pd、1 individual tidb、1 individual tikv |
| Database nodes -2 | The physical machine ,NUC 10 x86,12c 64G 1Tssd | ditto |
| Database nodes -3 | The physical machine ,NUC 10 x86,12c 64G 1Tssd | ditto |
| Sysbench Piezometer | virtual machine ,x86,16c 32G | |
| Haproxy Load balancing | virtual machine ,x86,8c 16G |
Sysbench Pressure measurement selection 7 A common scenario :
- select_random_points( Random spot check )
- oltp_read_only( Read only transactions )
- oltp_write_only( Just write business )
- oltp_read_write( Read write hybrid transactions )
- oltp_update_index( Update with index )
- oltp_update_non_index( Update without index )
- oltp_delete( Transaction deletion )
For each of the above scenarios , Set up 5 Different concurrency levels , Namely 10、50、100、200、300 Number of threads , Continuous pressure test 5 minute .
Collect QPS and 95% The delay index is compared with two databases .
test result
1、select_random_points
| Number of threads | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 4044 | 3.49 | 2666 | 5.47 |
| 50 | 8398 | 10.09 | 5086 | 15.00 |
| 100 | 8754 | 20 | 5429 | 29.19 |
| 200 | 9441 | 36.89 | 5541 | 58.92 |
| 300 | 9785 | 52.89 | 5531 | 92.42 |

Result analysis :
Check the scene TIDB For PostgreSQL Than YugabyteDB Be a little ahead , And as the concurrency increases , This gap is getting bigger and bigger .
2、oltp_read_only
| Number of threads | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 8954 | 20.74 | 0.13 | - |
| 50 | 24262 | 38.94 | 0.15 | - |
| 100 | 25136 | 78.60 | 0.15 | - |
| 200 | 25267 | 158.63 | 0.14 | - |
| 300 | 25436 | 240.02 | 0.14 | - |
Result analysis :
The test results of this scenario are very different ,YugabyteDB Query performance is crushed ,TiDB For PostgreSQL At normal level .
Through analysis Sysbench Source code discovery , The read-only scenario mainly contains the following queries SQL:
SELECT c FROM sbtest1 WHERE id BETWEEN 1 AND 1000;
SELECT sum(k) FROM sbtest1 WHERE id BETWEEN 1 AND 1000;
SELECT c FROM sbtest1 WHERE id BETWEEN 1 AND 1000 order by c;
SELECT distinct c FROM sbtest1 WHERE id BETWEEN 1 AND 1000 order by c;
4 Check the range according to the primary key SQL It takes a total of 400 More than seconds , The result is very surprising . With the first article SQL As an example, analyze its implementation plan :
Seq Scan on sbtest1 (cost=0.00..105.00 rows=1000 width=484) (actual time=9.968..127393.155 rows=1000 loops=1)
Filter: ((id >= 1) AND (id <= 1000))
Rows Removed by Filter: 9999000
Planning Time: 0.048 ms
Execution Time: 127393.919 ms
According to past experience, you should directly scan the primary key index , But in fact, it uses full table scanning , It's confusing .
To verify whether the size of the query range affects , I put id The query scope of is limited to 1 To 10, Found that the same implementation plan , If you switch to in If you query, you can use the primary key index .
Compared with ,TiDB For PostgreSQL The implementation plan is expected :
Projection_4 500.09 1000 root
└─IndexLookUp_13 500.09 1000 root
├─IndexRangeScan_11(Build) 500.09 1000 cop[tikv] table:sbtest1, index:PRIMARY(id)
└─TableRowIDScan_12(Probe) 500.09 1000 cop[tikv] table:sbtest1
What is the cause of YugabyteDB The efficiency of range query is so low that further analysis is needed .
3、oltp_write_only
| Number of threads | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 790 | 90.78 | 4309 | 47.47 |
| 50 | 3540 | 104.84 | 8427 | 71.83 |
| 100 | 6486 | 114.72 | 8674 | 92.42 |
| 200 | 11414 | 132.49 | 11170 | 150.29 |
| 300 | 15133 | 155.80 | 12036 | 211.60 |
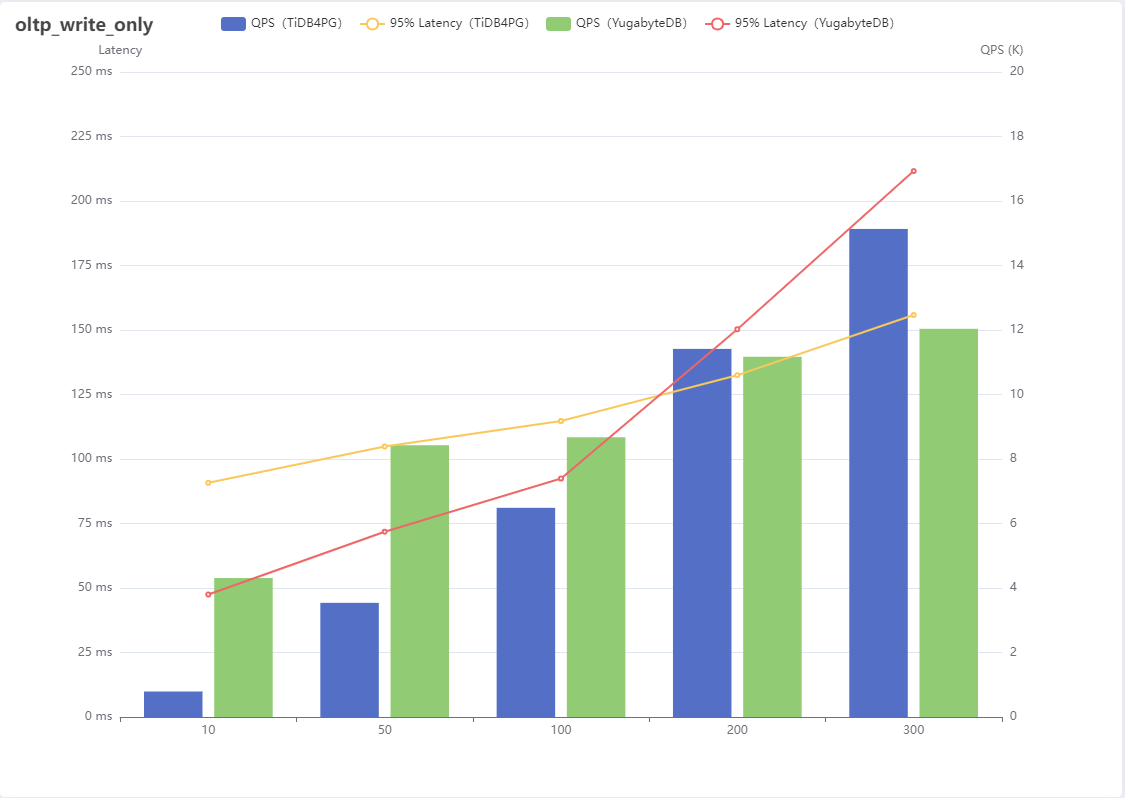
Result analysis :
The mixed write scenario contains 4 class , That is, the index update mentioned later 、 Update without index 、 Delete 、 Insert this 4 In this case , When the concurrency is small YugabyteDB Obvious performance advantages , But from 200 Concurrency starts TiDB For PostgreSQL Performance starts to exceed , It can reflect that the stability is slightly better .
4、oltp_read_write
| Number of threads | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 2238 | 104.84 | 556 | 3151.62 |
| 50 | 9790 | 123.28 | 1485 | 3326 |
| 100 | 17454 | 137.35 | 1494 | 6960 |
| 200 | 25119 | 189.93 | 1402 | 14302 |
| 300 | 25967 | 272.27 | 1835 | 22034 |
Result analysis :
Mixed reading and writing scenarios are also affected YugabyteDB The impact of range queries , Overall performance ratio TiDB For PostgreSQL It's a lot worse , stay 50 The concurrency has reached the bottleneck .
5、oltp_update_index
| Number of threads | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 374 | 36.24 | 2227 | 11.65 |
| 50 | 1630 | 41.85 | 3754 | 21.89 |
| 100 | 2980 | 45.79 | 4266 | 36.24 |
| 200 | 5375 | 50.11 | 4845 | 62.19 |
| 300 | 7298 | 55.82 | 4964 | 92.42 |
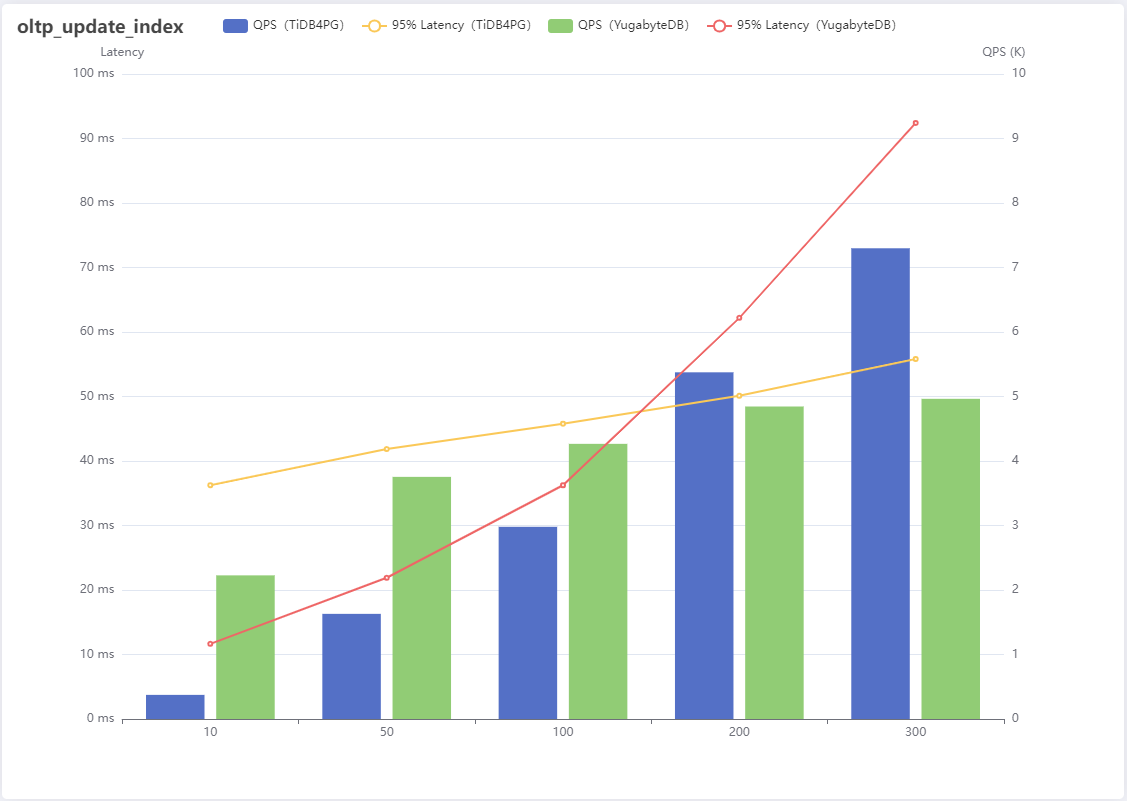
Result analysis :
update_index Is to update the index column according to the primary key , In this scene YugabyteDB The performance is better when the concurrency is small , But as the concurrency increases, it will reach the performance bottleneck faster , And it will get worse ,TiDB For PostgreSQL Relatively stable .
6、oltp_update_non_index
| Number of threads | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 415 | 31.37 | 6847 | 2.03 |
| 50 | 1988 | 35.59 | 17123 | 4.65 |
| 100 | 3761 | 37.56 | 16246 | 9.91 |
| 200 | 6910 | 41.10 | 18928 | 20.37 |
| 300 | 9849 | 43.39 | 19896 | 29.72 |
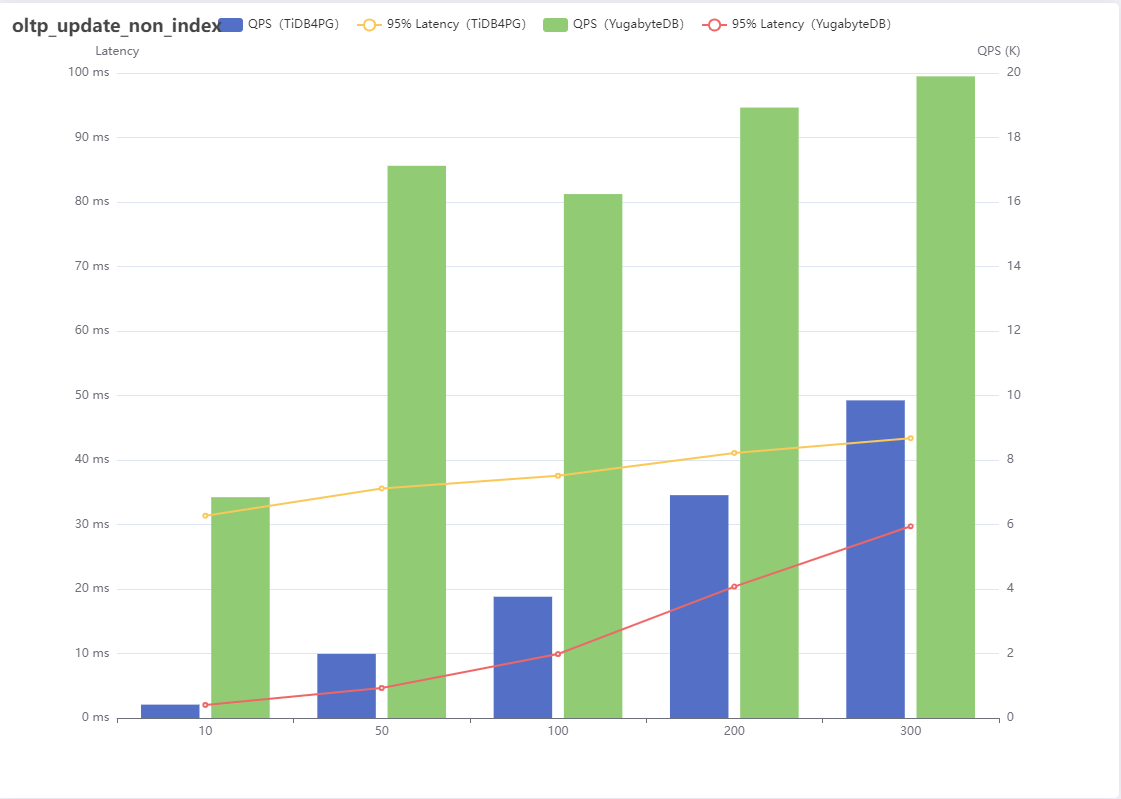
Result analysis :
update_non_index Update non indexed columns according to the primary key , In this scene YugabyteDB Take a big lead TiDB For PostgreSQL And keep .
7、oltp_delete
| Number of threads | QPS(TiDB4PG) | 95% Latency(TiDB4PG) | QPS(YugabyteDB) | 95% Latency(YugabyteDB) |
|---|---|---|---|---|
| 10 | 364 | 37.56 | 2389 | 10.84 |
| 50 | 1568 | 43.39 | 4269 | 19.65 |
| 100 | 2899 | 46.63 | 4844 | 33.12 |
| 200 | 5380 | 50.11 | 5705 | 56.84 |
| 300 | 7622 | 54.83 | 6146 | 82.96 |
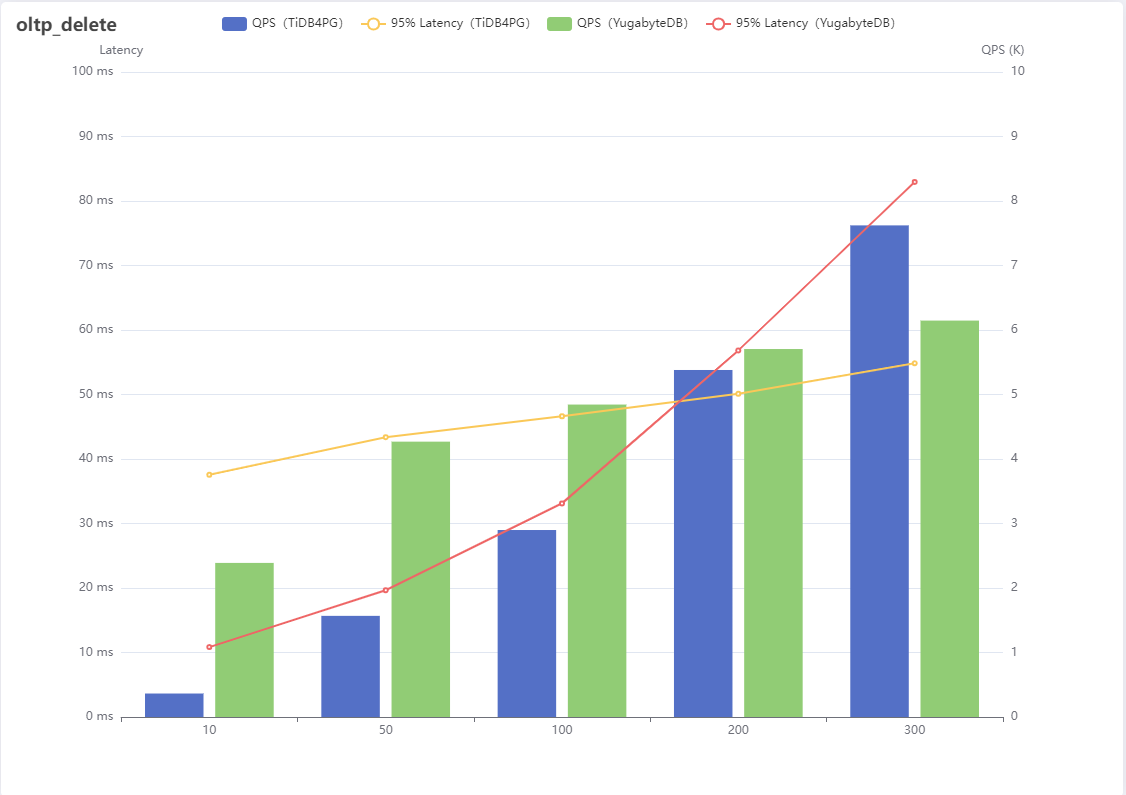
Result analysis :
delete The scenario is to delete a row of records according to the primary key , This test result is similar to non index update , At first YugabyteDB Good performance , After the concurrency increases, it slowly lags behind TiDB For PostgreSQL.
summary
After the above 7 Test findings of scenarios , The performance of the two databases has its own advantages and disadvantages .
TiDB For PostgreSQL Better at reading operation ,YugabyteDB Better at writing , But as the database load increases ,YugabyteDB The processing power and stability of large concurrent requests are not as good as TiDB For PostgreSQL good .
We will make an in-depth comparison between the two in terms of architecture and underlying principles in the future , See if you can find out the real reason .
Copyright notice : This article is organized and written by the team of Digital China cloud base , If reproduced, please indicate the source .
Official account search for digital cloud base in China , The background to reply TiDB, Join in TiDB Technology exchange group .
边栏推荐
- 2022山东智慧养老展,适老穿戴设备展,养老展,山东老博会
- Apache Doris刚“毕业”:为什么应关注这种SQL数据仓库?
- LeetCode3_ Longest substring without duplicate characters
- AE learning 01: AE complete project summary
- Three. JS introductory learning notes 04: external model import - no material obj model
- 分步式监控平台zabbix
- TCP framework___ Unity
- MySQL数据库基本操作-DQL-基本查询
- Limit of total fields [1000] in index has been exceeded
- Three. JS introductory learning notes 03: perspective projection camera
猜你喜欢
After UE4 is packaged, mesh has no material problem

强化实时数据管理,英方软件助力医保平台安全建设
Strengthen real-time data management, and the British software helps the security construction of the medical insurance platform
torch.numel作用

Shandong old age Expo, 2022 China smart elderly care exhibition, smart elderly care and aging technology exhibition

You Yuxi, coming!

【花雕体验】15 尝试搭建Beetle ESP32 C3之Arduino开发环境
Numpy -- data cleaning
无线传感器网络--ZigBee和6LoWPAN

Use of SVN
随机推荐
PyTorch 中的乘法:mul()、multiply()、matmul()、mm()、mv()、dot()
[flower carving experience] 15 try to build the Arduino development environment of beetle esp32 C3
Lecturer solicitation order | Apache seatunnel (cultivating) meetup sharing guests are in hot Recruitment!
Talk about the cloud deployment of local projects created by SAP IRPA studio
分步式监控平台zabbix
Learn good-looking custom scroll bars in 1 minute
融云斩获 2022 中国信创数字化办公门户卓越产品奖!
Leetcode-231-2的幂
Unity3D_ Class fishing project, bullet rebound effect is achieved
When opening the system window under UE4 shipping, the problem of crash is attached with the plug-in download address
Three. JS introductory learning notes 11:three JS group composite object
C Alibaba cloud OSS file upload, download and other operations (unity is available)
企业级日志分析系统ELK
A wave of open source notebooks is coming
Multiplication in pytorch: mul (), multiply (), matmul (), mm (), MV (), dot ()
Sysom case analysis: where is the missing memory| Dragon lizard Technology
Unity3D_ Class fishing project, control the distance between collision walls to adapt to different models
Step by step monitoring platform ZABBIX
numpy--数据清洗
Shipping companies' AI products are mature, standardized and applied on a large scale. CIMC, the global leader in port and shipping AI / container AI, has built a benchmark for international shipping