当前位置:网站首页>numpy--数据清洗
numpy--数据清洗
2022-07-07 13:26:00 【madkeyboard】
数据清洗
脏数据
通常我们获得的数据不可能都是百分百无错误的,一般都会存在一些问题,比如数据值缺失、数据值异常大或小、格式错误和非独立数据错误。
通过下面代码生动生成一组脏数据,如图所示在最后一行输出了一个dtype = object。(这个dtype就是numpy数据的类型,这里要注意,如果dtype = object说明list直接转换过来的数据是无法直接参与计算的,只有int和float这样的数据类型才能参与计算)
raw_data = [
["Name", "StudentID", "Age", "AttendClass", "Score"],
["小明", 20131, 10, 1, 67],
["小花", 20132, 11, 1, 88],
["小菜", 20133, None, 1, "98"],
["小七", 20134, 8, 1, 110],
["花菜", 20134, 98, 0, None],
["刘欣", 20136, 12, 0, 12]
]
data = np.array(raw_data)
print(data)

数据预处理
pre_data = []
for i in range(len(raw_data)):
if i == 0: # 去掉第一行字符串
continue
pre_data.append(raw_data[i][1:]) # 去掉第一列名字
data = np.array(pre_data,dtype=np.float) # 这里之所以用float是因为数据中含有None,只有float才能转换None
print(data)
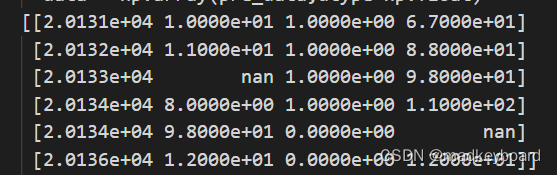
清洗数据
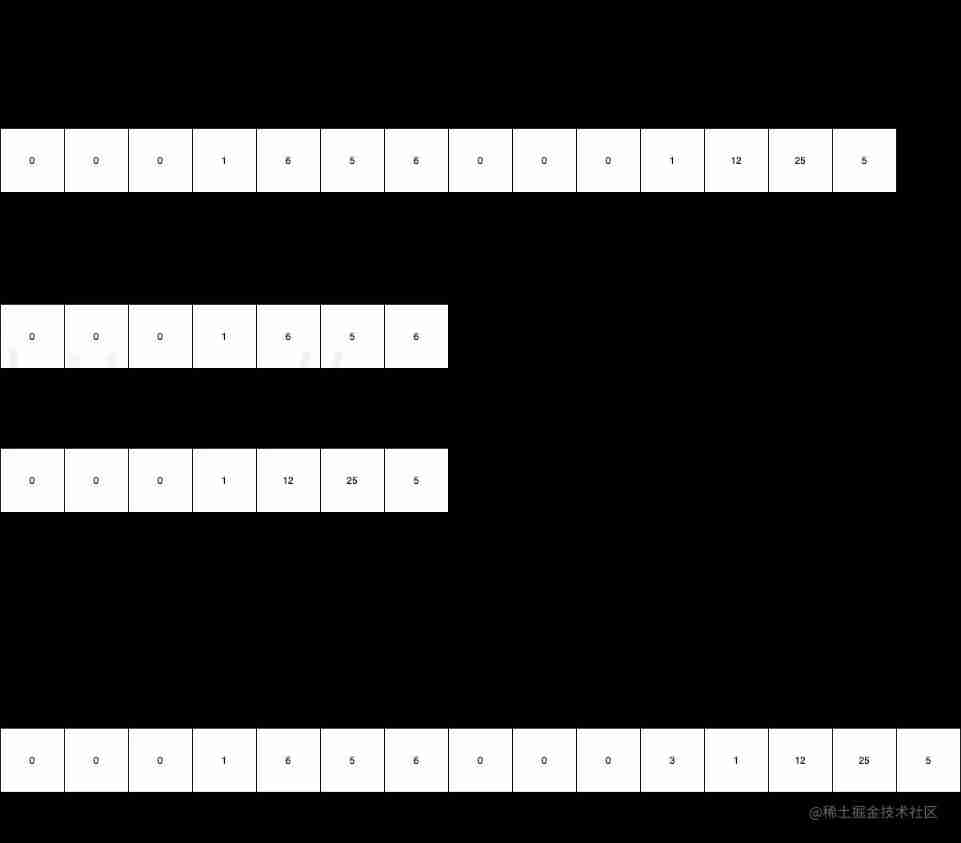
把不合逻辑的数据都清洗掉,在之前输入的数据中,第一列有明显的学号重复,这就不合逻辑的数据。np.unique()让数据具有唯一性,并且在使用过程中还可以看到重复的数据到底重复了多少次。如下图所示,20134出现了两次,那么我们就可以清楚的知道20135没有录上,之后就可以对数据进行更正。
fcow = data[:,0] # 取第一列的所有学号
print(fcow)
unique, counts = np.unique(fcow,return_counts=True) # return_counts展示数据的重复次数
print("清洗后的数据:",unique)
print("数据重复的次数:",counts)

在看第二列数据,首先能直观的看到有数据缺失,那么对于这个缺失的数据,我们可以通过求已有数据的平均值来进行补充
is_nan = np.isnan(data[:,1]) # 找到第二列为none的数据
nan_idx = np.argwhere(is_nan)
print("下标:",nan_idx,"为none")
mean_age = data[~np.isnan(data[:,1]), 1].mean() # ~取反,isnan返回的是一个布尔值,这里选择的是布尔值为false(不为None),然后求平均
print("平均年龄:",mean_age)
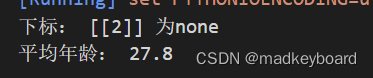
看到这里就疑惑了,小学生的平均年龄有28?通过观察数据,有一个数据为98,明显就错了,这就是异常数据。所以我们需要删除这两个错误数据,然后用剩下数据的平均来代替它们。
normal_idx = ~np.isnan(data[:,1]) & (data[:,1] < 13) # 找到第二列为none的数据
print("(flase)为需要更改的数据:",normal_idx)
mean_age = data[normal_idx,1].mean() # ~取反,isnan返回的是一个布尔值,这里选择的是布尔值为false(不为None),然后求平均
print("平均年龄:",mean_age)
data[~normal_idx,1] = mean_age
print("清洗后的数据:",np.floor(data[:,1])) # 年龄没有小数,向下再取整

最后再看后两列的数据,这里0和1代表上课与否,当没有上课时不可能有成绩,最后一行存在问题。还有小学总分一般都是100,有超出100的存在说明是异常数据。
data = np.array(pre_data,dtype=np.float64) # 这里之所以用float是因为数据中含有None,只有float才能转换None
data[data[:,2] == 0,3] = np.nan # 没上课的通通没有成绩nan
data[:,3] = np.clip(data[:,3], 0, 100) # 把不再合理范围内的分数裁剪掉
print(data[:,2:]) # 输出后两列
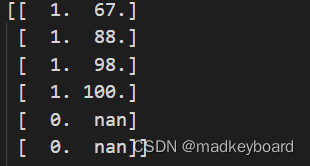
最后再对比一下数据清洗前清洗后,虽然本次数据量很小,但是也有非常多种的清洗方式,熟悉了这些方式,以后对于更加庞大的数据也是手到擒来,让自己的数据干净又卫生。
边栏推荐
- Share the technical details of super signature system construction
- LeetCode1_ Sum of two numbers
- The "go to definition" in VS2010 does not respond or prompts the solution of "symbol not found"
- LeetCode3_ Longest substring without duplicate characters
- Jacobo code coverage
- Whether runnable can be interrupted
- Ue4/ue5 multi thread development attachment plug-in download address
- 【OBS】RTMPSockBuf_ Fill, remote host closed connection.
- 最安全的证券交易app都有哪些
- Unity's ASE achieves full screen sand blowing effect
猜你喜欢
![[server data recovery] a case of RAID data recovery of a brand StorageWorks server](/img/aa/6d820d97e82df1d908dc7aa78fc8bf.png)
[server data recovery] a case of RAID data recovery of a brand StorageWorks server
Cocos creator collision and collision callback do not take effect
![[deep learning] image hyperspectral experiment: srcnn/fsrcnn](/img/84/114fc8f0875b82cc824e6400bcb06f.png)
[deep learning] image hyperspectral experiment: srcnn/fsrcnn

20th anniversary of agile: a failed uprising

Tkinter after how to refresh data and cancel refreshing
![[server data recovery] data recovery case of raid failure of a Dell server](/img/5d/03bc8dcc6e554273b34a78c49a9eaf.jpg)
[server data recovery] data recovery case of raid failure of a Dell server
Annexb and avcc are two methods of data segmentation in decoding
Implementation of crawling web pages and saving them to MySQL using the scrapy framework
Unity's ASE realizes cartoon flame

LeetCode3_ Longest substring without duplicate characters
随机推荐
Virtual memory, physical memory /ram what
【微信小程序】Chapter(5):微信小程序基础API接口
2. 堆排序『较难理解的排序』
2022 all open source enterprise card issuing network repair short website and other bugs_ 2022 enterprise level multi merchant card issuing platform source code
unnamed prototyped parameters not allowed when body is present
HW初级流量监控,到底该怎么做
[quick start of Digital IC Verification] 26. Ahb-sramc of SystemVerilog project practice (6) (basic points of APB protocol)
【原创】一切不谈考核的管理都是扯淡!
最安全的证券交易app都有哪些
XMIND frame drawing tool
Jacobo code coverage
有一头母牛,它每年年初生一头小母牛。每头小母牛从第四个年头开始,每年年初也生一头小母牛。请编程实现在第n年的时候,共有多少头母牛?
Gd32 F3 pin mapping problem SW interface cannot be burned
【数字IC验证快速入门】25、SystemVerilog项目实践之AHB-SRAMC(5)(AHB 重点回顾,要点提炼)
Yunxiaoduo software internal test distribution test platform description document
Cocos makes Scrollview to realize the effect of zooming in the middle and zooming out on both sides
[quickstart to Digital IC Validation] 20. Basic syntax for system verilog Learning 7 (Coverage Driven... Including practical exercises)
【搞船日记】【Shapr3D的STL格式转Gcode】
【數字IC驗證快速入門】26、SystemVerilog項目實踐之AHB-SRAMC(6)(APB協議基本要點)
Share the technical details of super signature system construction