当前位置:网站首页>Drop out (pytoch)
Drop out (pytoch)
2022-07-03 10:34:00 【-Plain heart to warm】
List of articles
The law of abandonment
motivation
- A good model needs to be robust to the disturbance of input data
- Using noisy data is equivalent to Tikhonov Regular
- The law of abandonment : Add noise between layers
Add noise without deviation
- Yes x Add noise to get x’, We hope
E [ x ′ ] = x E[x']=x E[x′]=x - The discarding method perturbs each element as follows
x i ′ = { 0 w i t h p r o b a b l i t y p w i 1 − p o t h e r w i s e x_i'= \begin{cases} 0&with\;probablity\;p\\ {w_i \over 1-p}&otherwise \end{cases} xi′={ 01−pwiwithprobablitypotherwise
E [ x i ′ ] = p ⋅ 0 + ( 1 − p ) x i 1 − p = x i E[x_i']=p·0+(1-p){x_i \over 1-p}=x_i E[xi′]=p⋅0+(1−p)1−pxi=xi
Use discard method
- The discard method is usually used to hide the output of the full connection layer
h = σ ( W 1 x + b 1 ) h ′ = d r o p o u t ( h ) o = W 2 h ′ + b 2 y = s o f t m a x ( o ) h=\sigma (W_1x+b_1)\\ h'=dropout(h)\\ o=W_2h'+b_2\\ y=softmax(o) h=σ(W1x+b1)h′=dropout(h)o=W2h′+b2y=softmax(o)

Add a probability function , Kill some connections
Discarding method in reasoning
- Regular terms are only used in training : They affect the updating of model parameters
- In the process of reasoning , The discard method returns the input directly
h = d r o p o u t ( h ) h=dropout(h) h=dropout(h)- This also ensures deterministic output
summary
- The discard method randomly places some output items 0 To control the complexity of the model
- It often acts on the hidden layer output of multi-layer perceptron
- Discarding probability is a super parameter that controls the complexity of the model
Discard rate P Usually take 0.5、0.9、0.1
Start from scratch
To realize the single-layer fallback function , We take samples from the uniform distribution , The number of samples is consistent with the dimension of this neural network . Then we keep those nodes whose corresponding samples are larger than , Throw away the rest .
In the following code , We implement dropout_layer function , The function dropout Probabilistic discarding tensor input X The elements in , Rescale the rest as described above : Divide the rest by 1.0-dropout.
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# In this case , All elements are discarded
if dropout == 1:
return torch.zeros_like(X)
# In this case , All elements are preserved
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float() # The front is bool,float Convert to floating point 0. or 1.
return mask * X / (1.0 - dropout)
- Multiplication is much faster than choosing a data
- rand produce 0-1 A uniform distribution between
- randn The average production is 0, The variance of 1 Gaussian distribution of
We can test through the following examples dropout_layer function . We're going to enter X Operate through the temporary withdrawal method , The probabilities of retirement are 0、0.5 and 1.
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 0., 0., 0., 8., 10., 0., 14.],
[16., 18., 0., 22., 0., 0., 28., 30.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
Define model parameters
Define a multi-layer perceptron with two hidden layers , Each hidden layer contains 256 A unit .
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
Defining models
We can apply the fallback method to the output of each hidden layer ( After activating the function ), And the temporary retirement probability can be set for each layer : A common technique is to set a low probability of retirement close to the input layer . The following model sets the retirement probability of the first and second hidden layers to 0.2 and 0.5, And the suspension method is only valid during training .
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# Use only when training the model dropout
if self.training == True:
# Add one after the first fully connected layer dropout layer
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# Add a... After the second fully connected layer dropout layer
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
Instantiation Net After the class , Automatically call forward
Training and testing
This is similar to the multi-layer perceptron training and testing described above .
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
Concise implementation
Advanced for deep learning framework API, We just need to add one after each fully connected layer Dropout layer , Pass the fallback probability as a unique parameter to its constructor . During the training ,Dropout The layer will randomly discard the output of the previous layer according to the specified fallback probability ( Equivalent to the input of the next layer ). At testing time ,Dropout The layer only passes data .
net = nn.Sequential(nn.Flatten(), # Flatten the input , Pull into two dimensions
nn.Linear(784, 256),
nn.ReLU(),
# Add one after the first fully connected layer dropout layer
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# Add a... After the second fully connected layer dropout layer
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
Model test
Next , We train and test the model .
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
summary
The retreat method is in the process of forward propagation , Discard some neurons while calculating each internal layer .
The regression method can avoid over fitting , It is usually used in combination with controlling the dimension and size of the weight vector .
The regression method replaces the activity value with a random variable with an expected value .
The respite method is only used during training .
QA
dropout Random setting 0 What is the effect on finding gradient and direction propagation ?
dropout Set up 0, The gradient will also become 0, The corresponding weight will not be updated
It can be understood that each time a small network is randomly taken out from it for updatingIn the use of BN When , It is necessary to use dropout Well ?
BN It's for convolution layer ,dropout It's for the whole connection layerdropout Function return value expression return mask * X / (1.0 - dropout) The value of the input part that is not discarded will be changed because of the denominator of the expression (1-P) Change with the existence of , The label of training data is still the original value .
Or turn the output into 0, Otherwise, divide by (1-P). Guarantee expectations ( mean value ) Don't change , But the label doesn't change .dropout The only change is the output of the hidden layer .
You can change the label , It is also a kind of regularization .
边栏推荐
- Leetcode刷题---704
- Leetcode刷题---35
- Hands on deep learning pytorch version exercise solution - 2.5 automatic differentiation
- Leetcode刷题---202
- Tensorflow—Neural Style Transfer
- [LZY learning notes -dive into deep learning] math preparation 2.5-2.7
- Tensorflow—Image segmentation
- Yolov5 creates and trains its own data set to realize mask wearing detection
- 20220608其他:逆波兰表达式求值
- Julia1.0
猜你喜欢

Configure opencv in QT Creator

High imitation Netease cloud music

Leetcode - 5 longest palindrome substring

Opencv+dlib to change the face of Mona Lisa
GAOFAN Weibo app
![[C question set] of Ⅵ](/img/49/eb31cd26f7efbc4d57f17dc1321092.jpg)
[C question set] of Ⅵ

EFFICIENT PROBABILISTIC LOGIC REASONING WITH GRAPH NEURAL NETWORKS
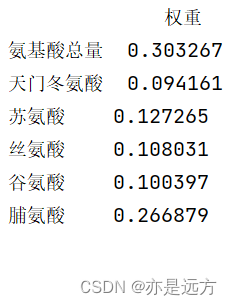
熵值法求权重
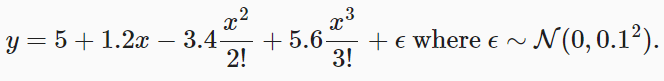
神经网络入门之模型选择(PyTorch)
ECMAScript--》 ES6语法规范 ## Day1
随机推荐
Configure opencv in QT Creator
Knowledge map reasoning -- hybrid neural network and distributed representation reasoning
Ind yff first week
[LZY learning notes -dive into deep learning] math preparation 2.5-2.7
20220603 Mathematics: pow (x, n)
Ut2015 learning notes
八、MySQL之事务控制语言
神经网络入门之预备知识(PyTorch)
Realize an online examination system from zero
2018 y7000 upgrade hard disk + migrate and upgrade black apple
Ind wks first week
What did I read in order to understand the to do list
Hands on deep learning pytorch version exercise solution - 2.6 probability
Inverse code of string (Jilin University postgraduate entrance examination question)
Leetcode刷题---217
Raspberry pie 4B installs yolov5 to achieve real-time target detection
Leetcode刷题---75
Step 1: teach you to trace the IP address of [phishing email]
侯捷——STL源码剖析 笔记
Synchronous vs asynchronous