当前位置:网站首页>Crawler_crawl wasde monthly supply and demand balance table (example)
Crawler_crawl wasde monthly supply and demand balance table (example)
2022-08-02 05:44:00 【Programmers and Finance and Technology】
注:This instance requires a ladder.
The monthly balance of supply and demand of world agricultural products released by the United States is an indispensable material for the study of agricultural products,This chapter is a complete example,Crawling released over the yearswasde报告.USDAThe website provides historical database query and download,But after checking, it is found that some categories existwasde报告中有,And the data downloaded in the database does not have it,In order to be closer to the research needs,直接获取所有的wasde报告.
目录
写在前面
1. wasdeReports are availablexls、txt、xml和pdf下载,But not all four methods are available at all time points,Early onlypdf,Some time points offer only a few of these four methods,In this example operation,优先xls,其次txt,最次pdf
2. 获取xls或txt或pdf文件后,A certain item of data needs to be extracted from the file,xls和txteasy to extract,pdf不方便,obtained from the websitepdf需要经过ocr转成txt,比较费劲
3. From crawling to final data acquisition,There are many steps before and after,有点复杂,需要耐心
步骤一:获取目录
the directory where the html文件下载
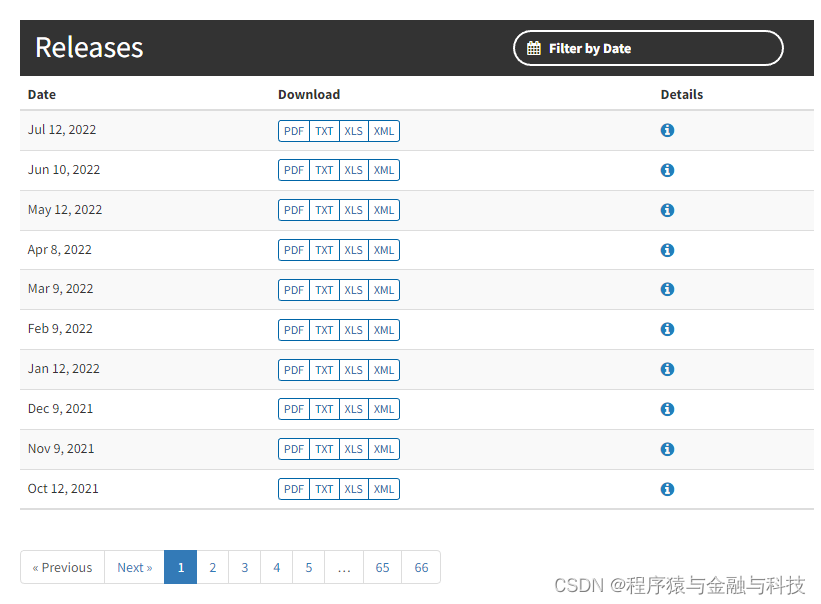
Total directory66页,改变url中的页码,下载这66页目录的html文件
import os,json,requests,urllib3
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
from tools import mongodb_utils,date_tools,string_tools
import xlrd
def wasde_step_one():
pre_dir = r'D:/temp006/'
driver = webdriver.Chrome('../driver/chromedriver.exe')
# 设置超时时间 10s
driver.set_page_load_timeout(10)
for i in range(1, 67):
print(i)
url_str = f"https://usda.library.cornell.edu/concern/publications/3t945q76s?locale=en&page={i}#release-items"
driver.get(url_str)
page_source = driver.page_source
file_path = pre_dir + str(i) + '.html'
with open(file_path, 'w', encoding='utf-8') as fw:
fw.write(page_source)
sleep(2)
driver.close()
driver.quit()
pass步骤二:获取xls链接地址
将存在xlsGet the link address
def wasde_step_three():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
proxies = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
urllib3.disable_warnings()
pre_dir = r'D:/temp005/'
pic_save_dir = r'D:/temp003/'
for i in range(6, 67):
print(i)
json_file_name = f"{i}.json"
json_file_path = pre_dir + json_file_name
with open(json_file_path, 'r', encoding='utf-8') as fr:
node_list = json.load(fr)
for node in node_list:
date_str = node['date']
url_str = node['url']
xls_save_name = f"{date_str}.xls"
pre_save_dir_00 = pic_save_dir + str(i)
if os.path.exists(pre_save_dir_00):
pass
else:
os.mkdir(pre_save_dir_00)
r = requests.get(url_str, headers=headers,proxies=proxies,verify=False)
xls_save_path = pre_save_dir_00 + os.path.sep + xls_save_name
with open(xls_save_path, 'wb') as fw:
fw.write(r.content)
pass
pass分析节点,提取存在xls的目录,并存储到json文件中,并将jsonThe file is stored in the specified directory
步骤三:下载xls文件
obtained in step 2xls的下载地址,Download according to these download addressesxls文件
def wasde_step_three():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
proxies = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
urllib3.disable_warnings()
pre_dir = r'D:/temp005/'
pic_save_dir = r'D:/temp003/'
for i in range(1, 67):
print(i)
json_file_name = f"{i}.json"
json_file_path = pre_dir + json_file_name
with open(json_file_path, 'r', encoding='utf-8') as fr:
node_list = json.load(fr)
for node in node_list:
date_str = node['date']
url_str = node['url']
xls_save_name = f"{date_str}.xls"
pre_save_dir_00 = pic_save_dir + str(i)
if os.path.exists(pre_save_dir_00):
pass
else:
os.mkdir(pre_save_dir_00)
r = requests.get(url_str, headers=headers,proxies=proxies,verify=False)
xls_save_path = pre_save_dir_00 + os.path.sep + xls_save_name
with open(xls_save_path, 'wb') as fw:
fw.write(r.content)
pass
pass步骤四:获取txt链接地址
对于没有提供xls文件的目录,获取txt链接地址
def wasde_step_four():
pic_dir = r'D:/temp005/'
pre_dir = r'D:/temp006/html/'
for file_no in range(1, 67):
# print(file_no)
final_list = []
file_name = f"{file_no}.html"
file_path = pre_dir + file_name
with open(file_path, 'r', encoding='utf-8') as fr:
html_content = fr.read()
soup = BeautifulSoup(html_content, 'lxml')
tbody_node = soup.find('tbody', {'id': 'release-items'})
tr_list = tbody_node.find_all('tr')
for tr_node in tr_list:
td_list = tr_node.find_all('td')
td_one = td_list[0]
date_str = td_one.string
res_date_str = date_tools.wasde_trans_date_str(date_str)
td_two = td_list[1]
a_list = td_two.find_all('a')
txt_url = None
has_xls_yeah = False
for a_node in a_list:
if a_node.get('data-label') is None:
continue
data_label = a_node['data-label']
if 'xls' in data_label:
has_xls_yeah = True
break
if 'txt' in data_label:
txt_url = a_node['href']
if has_xls_yeah:
continue
if txt_url is None:
print(f"{file_no}::{date_str}")
continue
final_list.append({
'date': res_date_str,
'url': txt_url
})
save_file_name = f"{file_no}.json"
save_file_path = pic_dir + save_file_name
with open(save_file_path, 'w', encoding='utf-8') as fw:
json.dump(final_list, fw, ensure_ascii=False)
passProceed to step two,没有提供xls的目录,Check for availabilitytxt,If there is, get it and store itjson文件中,并将jsonThe file is stored in the specified directory
步骤五:下载txt文件
Obtained in step fourtxt下载地址,According to these download addresses,下载txt文件
def wasde_step_five():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
proxies = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
urllib3.disable_warnings()
pre_dir = r'D:/temp005/'
pic_save_dir = r'D:/temp003/'
for i in range(1, 67):
print(i)
json_file_name = f"{i}.json"
json_file_path = pre_dir + json_file_name
with open(json_file_path, 'r', encoding='utf-8') as fr:
node_list = json.load(fr)
for node in node_list:
date_str = node['date']
url_str = node['url']
xls_save_name = f"{date_str}.txt"
pre_save_dir_00 = pic_save_dir + str(i)
if os.path.exists(pre_save_dir_00):
pass
else:
os.mkdir(pre_save_dir_00)
r = requests.get(url_str, headers=headers, proxies=proxies, verify=False)
xls_save_path = pre_save_dir_00 + os.path.sep + xls_save_name
with open(xls_save_path, 'w',encoding='utf-8') as fw:
fw.write(r.text)
pass步骤六:获取pdf链接地址
对于没有提供xls文件也没有txt文件的目录,获取pdf链接地址
def wasde_step_six():
pic_dir = r'D:/temp005/'
pre_dir = r'D:/temp006/html/'
for file_no in range(1, 67):
# print(file_no)
final_list = []
file_name = f"{file_no}.html"
file_path = pre_dir + file_name
with open(file_path, 'r', encoding='utf-8') as fr:
html_content = fr.read()
soup = BeautifulSoup(html_content, 'lxml')
tbody_node = soup.find('tbody', {'id': 'release-items'})
tr_list = tbody_node.find_all('tr')
for tr_node in tr_list:
td_list = tr_node.find_all('td')
td_one = td_list[0]
date_str = td_one.string
res_date_str = date_tools.wasde_trans_date_str(date_str)
td_two = td_list[1]
a_list = td_two.find_all('a')
pdf_url = None
has_xls_yeah = False
has_txt_yeah = False
for a_node in a_list:
if a_node.get('data-label') is None:
pdf_url = a_node['href']
else:
data_label = a_node['data-label']
if 'xls' in data_label:
has_xls_yeah = True
break
if 'txt' in data_label:
has_txt_yeah = True
break
if 'pdf' in data_label:
pdf_url = a_node['href']
if has_xls_yeah:
continue
if has_txt_yeah:
continue
if pdf_url is None:
print(f"{file_no}::{date_str}")
continue
final_list.append({
'date': res_date_str,
'url': pdf_url
})
save_file_name = f"{file_no}.json"
save_file_path = pic_dir + save_file_name
with open(save_file_path, 'w', encoding='utf-8') as fw:
json.dump(final_list, fw, ensure_ascii=False)
passProceed to step two,没有提供xls和txt的目录,则获取pdf并存储到json文件中,并将jsonThe file is stored in the specified directory
步骤七:下载pdf文件
def wasde_step_seven():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
proxies = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
urllib3.disable_warnings()
pre_dir = r'D:/temp005/'
pic_save_dir = r'D:/temp003/'
for i in range(1, 67):
print(i)
json_file_name = f"{i}.json"
json_file_path = pre_dir + json_file_name
with open(json_file_path, 'r', encoding='utf-8') as fr:
node_list = json.load(fr)
for node in node_list:
date_str = node['date']
url_str = node['url']
if 'pdf' not in url_str:
continue
xls_save_name = f"{date_str}.pdf"
pre_save_dir_00 = pic_save_dir + str(i)
if os.path.exists(pre_save_dir_00):
pass
else:
os.mkdir(pre_save_dir_00)
r = requests.get(url_str, headers=headers, proxies=proxies, verify=False)
xls_save_path = pre_save_dir_00 + os.path.sep + xls_save_name
with open(xls_save_path, 'wb') as fw:
fw.write(r.content)
pass步骤八: 将pdf转成txt文件
该网站下载的pdf文件需要使用ocr识别文本,The content to be recognized is English and numbers,识别效果很好,pdf转换得来的txtfiles and direct downloadstxtFiles need to be differentiated when extracting data,Both cannot be extracted in the same way
8.1 下载 tesseract-ocr-w64-setup-v5.0.1.20220118.exe 并安装
1). 下载地址:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v5.0.1.20220118.exe
2)Remember to tick the install language pack when installing

3). 选择安装路径,Remember to choose the installation path,The code will be used later
4). The installation process takes a long time,大概要半个小时,And there will be multiple pop-ups during the process, When you encounter a pop-up window, click OK.
8.2 安装Poppler, Poppler主要是协助pdf2image在windows操作系统中操作pdf
1). 下载地址https://blog.alivate.com.au/wp-content/uploads/2018/10/poppler-0.68.0_x86.7z
2). 下载后直接解压,Remember the unzipped address,Will need to use it in the code later
8.3 安装python需要用到的包
pip install Pillow
pip install pdf2image
pip install pytesseract
8.4 写一个小demo验证tesseractIdentify whether the file is feasible
from PIL import Image
import pytesseract
from pdf2image import convert_from_path
def temp_tesseract_demo():
poppler_path = r'D:/python_package/poppler-0.68.0_x86/poppler-0.68.0/bin/'
pytesseract.pytesseract.tesseract_cmd = r'D:\\soft\\ocr\\tesseract.exe'
pdf_file_path = r'E:/temp000/1994_9_12.pdf'
images = convert_from_path(pdf_path=pdf_file_path,poppler_path=poppler_path)
print('Start saving as a picture')
pic_pre_dir = r'E:/temp000/pic/'
pic_file_list = []
for count,img in enumerate(images):
img_path = f"{pic_pre_dir}page_{count}.png"
img.save(img_path,'PNG')
pic_file_list.append(img_path)
print('Start converting to text')
txt_pre_dir = r'E:/temp000/txt/'
for file_count,file_item in enumerate(pic_file_list):
print(file_count,file_item)
extracted_text = pytesseract.image_to_string(Image.open(file_item),lang='eng')
txt_file_path = f"{txt_pre_dir}txt_{file_count}.txt"
with open(txt_file_path,'w',encoding='utf-8') as fw:
fw.write(extracted_text)
pass图片文件夹 :

text folder:
 Image versus text content:
Image versus text content:
 8.5 将pdf文件转png
8.5 将pdf文件转png
def wasde_step_eight_02_00():
poppler_path = r'D:/python_package/poppler-0.68.0_x86/poppler-0.68.0/bin/'
pre_dir = r'E:/temp003/'
save_dir = r'E:/temp002/'
dir_two_list = os.listdir(pre_dir)
for two_dir in dir_two_list:
save_dir_two = save_dir + two_dir
if os.path.exists(save_dir_two):
pass
else:
os.mkdir(save_dir_two)
pre_dir_two = pre_dir + two_dir
pdf_file_list = os.listdir(pre_dir_two)
for pdf_item in pdf_file_list:
print(two_dir,pdf_item)
pdf_name = pdf_item.split('.')[0]
pdf_item_path = pre_dir_two + os.path.sep + pdf_item
pdf_pic_dir = save_dir_two + os.path.sep + pdf_name
if os.path.exists(pdf_pic_dir):
pass
else:
os.mkdir(pdf_pic_dir)
images = convert_from_path(pdf_path=pdf_item_path, poppler_path=poppler_path)
for count, img in enumerate(images):
img_path = f"{pdf_pic_dir}{os.path.sep}page_{count}.png"
img.save(img_path, 'PNG')
pass8.6 将png转txt文本
def wasde_step_eight_02_01():
pytesseract.pytesseract.tesseract_cmd = r'D:\\soft\\ocr\\tesseract.exe'
png_one_dir = r'E:/temp002/'
txt_one_dir = r'E:/temp001/'
png_two_dir_list = os.listdir(png_one_dir)
for two_dir in png_two_dir_list:
txt_two_dir = txt_one_dir + two_dir
if not os.path.exists(txt_two_dir):
os.mkdir(txt_two_dir)
png_two_dir = png_one_dir + two_dir
png_three_dir_list = os.listdir(png_two_dir)
for three_dir in png_three_dir_list:
print(two_dir,three_dir)
txt_three_dir = txt_two_dir + os.path.sep + three_dir + os.path.sep
if not os.path.exists(txt_three_dir):
os.mkdir(txt_three_dir)
png_three_dir = png_two_dir + os.path.sep + three_dir + os.path.sep
png_file_list = os.listdir(png_three_dir)
png_count = len(png_file_list)
for i in range(0,png_count):
png_file_path = f"{png_three_dir}page_{i}.png"
extracted_text = pytesseract.image_to_string(Image.open(png_file_path), lang='eng')
txt_file_path = f"{txt_three_dir}txt_{i}.txt"
with open(txt_file_path, 'w', encoding='utf-8') as fw:
fw.write(extracted_text)
pass至此,The entire project is complete,The specific required value to the specifiedxls、txt或txt(pdf)中提取.
边栏推荐
猜你喜欢
如何评价最近爆红的FastAPI?

Go 语言是如何实现切片扩容的?【slice】
轮询和长轮询的区别

【STM32】 ADC模数转换
The line chart with square PyQt5_pyqtgraph mouse
PDF文件转换格式
批量--09---批量读文件入表
爬虫_爬取wasde月度供需平衡表(实例)

Visual SLAM Lecture Fourteen - Lecture 13 Practice: Designing a SLAM system (the most detailed code debugging and running steps)
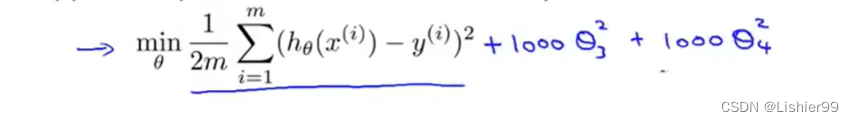
吴恩达机器学习系列课程笔记——第七章:正则化(Regularization)
随机推荐
吴恩达机器学习系列课程笔记——第九章:神经网络的学习(Neural Networks: Learning)
UI自动化测试框架搭建——标记性能较差用例
Platts Analysis-MATLAB Toolbox Function
How to save a section of pages in a PDF as a new PDF file
How to decrypt worksheet protection in Excel
Camtasia 2022简体中文版屏幕录像和视频编辑软件
Line generation 005
【FreeRTOS】12 任务通知——更省资源的同步方式
Arduino框架下ESP32重启原因串口信息输出示例
捷信将ESG理念注入企业DNA致力于提供“负责任的消费金融服务”
(一)代码输出题 —— reverse
被大厂强制毕业,两个月空窗期死背八股文,幸好上岸,不然房贷都还不上了
无主复制系统(3)-Quorum一致性的局限性
Jetson Nano 2GB Developer Kit Installation Instructions
RuoYi-App启动教程
6个月测试经验,面试跳槽狮子大开口要18K,只会点点点,给我整无语了。。
1318_将ST link刷成jlink
LeetCode 23: 合并K个升序链表
Minecraft 1.18.1, 1.18.2 module development 23.3D animation armor production
热爱责任担当