当前位置:网站首页>Deep learning network regularization
Deep learning network regularization
2022-07-04 14:56:00 【Falling flowers and rain】
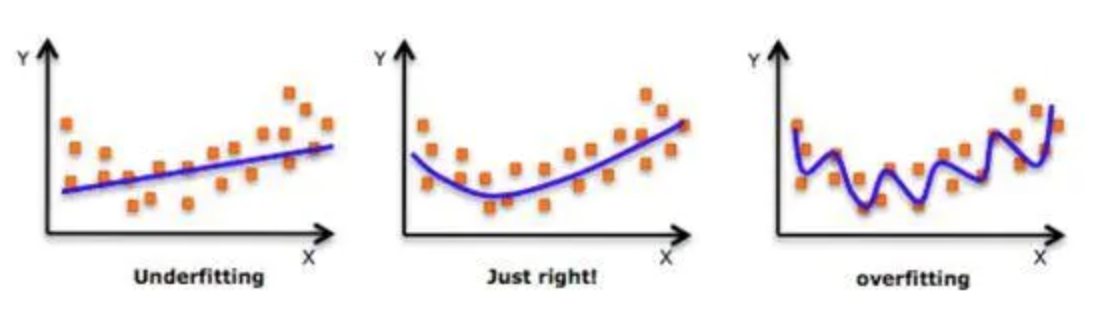
When designing machine learning algorithm, it is not only required to have small error in the training set , And hope to have strong generalization ability on new samples . Many machine learning algorithms use relevant strategies to reduce the test error , These strategies are collectively referred to as regularization . Because of the strong representation ability of neural network, fitting is often encountered , Therefore, different forms of regularization strategies need to be used .
Regularization reduces generalization error by modifying the algorithm , At present, the most commonly used strategies in deep learning are parameter norm punishment , Early termination ,DropOut etc. , Next, we will introduce it in detail .
1. L1 And L2 Regularization ( review )
L1 and L2 Is the most common regularization method . They are in the loss function (cost function) Add a regular item to , Due to the addition of this regularization term , The value of the weight matrix decreases , Because it assumes that a neural network with a smaller weight matrix leads to a simpler model . therefore , It also reduces overfitting to some extent . However , This regularization term is in L1 and L2 It's different .
L2 Regularization
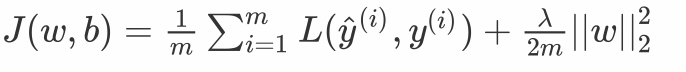
there λ It's a regularization parameter , It is a super parameter that needs to be optimized .L2 Regularization is also called weight attenuation , Because it causes the weight to tend to 0( But not all 0)L1 Regularization
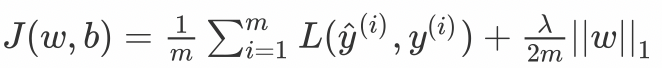
here , We punish the absolute value of the weight matrix . among ,λ Is the regularization parameter , It's a super parameter. , differ L2, The weight value may be reduced to 0. therefore ,L1 Useful for compression models . In other cases , General preference L2 Regularization .
stay tf.keras The method used in the implementation is :
- L1 Regularization
tf.keras.regularizers.L1(l1=0.01)
- L2 Regularization
tf.keras.regularizers.L2(l2=0.01)
- L1L2 Regularization
tf.keras.regularizers.L1L2(
l1=0.0, l2=0.0
)
We're directly on a certain floor layers Specify the regularization type and hyperparameters in :
# Import the corresponding toolkit
import tensorflow as tf
from tensorflow.keras import regularizers
# Creating models
model = tf.keras.models.Sequential()
# L2 Regularization ,lambda by 0.01
model.add(tf.keras.layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu', input_shape=(10,)))
# L1 Regularization ,lambda by 0.01
model.add(tf.keras.layers.Dense(16, kernel_regularizer=regularizers.l1(0.001),
activation='relu'))
# L1L2 Regularization ,lambda1 by 0.01,lambda2 by 0.01
model.add(tf.keras.layers.Dense(16, kernel_regularizer=regularizers.L1L2(0.001, 0.01),
activation='relu'))
2. Dropout Regularization
dropout It is the most commonly used regularization technology in the field of deep learning .Dropout It's very simple : Suppose our neural network structure is as follows , During each iteration , Select some nodes randomly , And delete forward and backward connections .
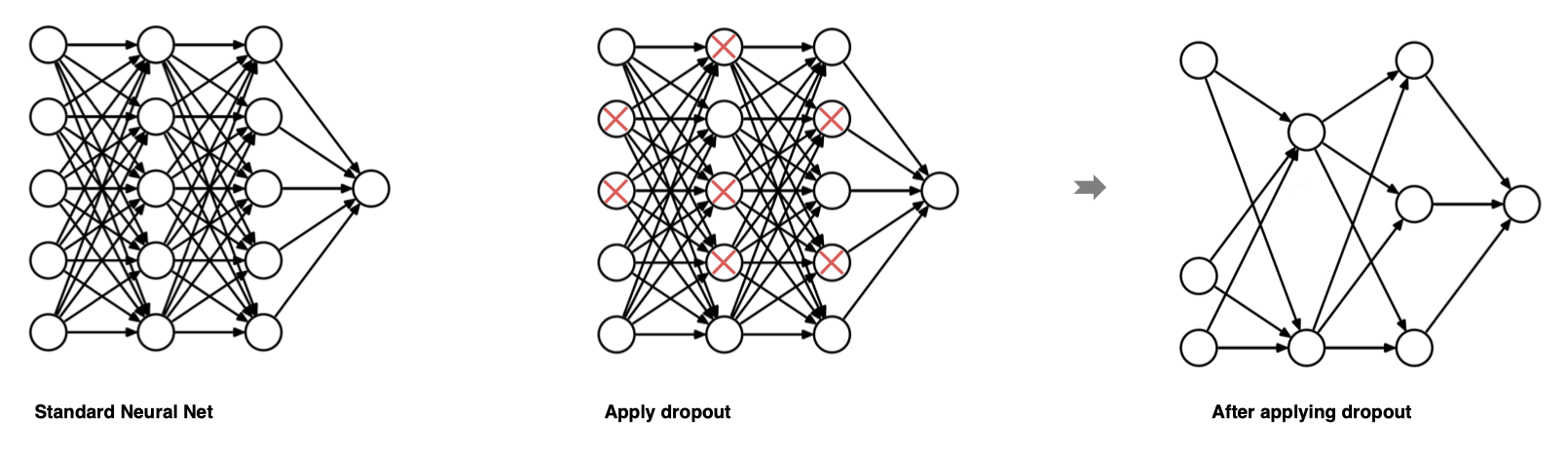
therefore , Each iteration process will have different node combinations , This leads to different outputs , This can be seen as an integration method in machine learning (ensemble technique). Integration model is the first mock exam. , Because they can capture more randomness . Similarly ,dropout Make the neural network model better than the normal model .
stay tf.keras The method used in the implementation is dropout:
tf.keras.layers.Dropout(rate)
Parameters :
rate: The probability that each neuron is discarded
Example :
# Import the corresponding library
import numpy as np
import tensorflow as tf
# Definition dropout layer , Every neuron has 0.2 The probability of being inactivated , The input that is not deactivated will be pressed 1 /(1-rate) Zoom in
layer = tf.keras.layers.Dropout(0.2,input_shape=(2,))
# Define data for five batches
data = np.arange(1,11).reshape(5, 2).astype(np.float32)
# Print raw data
print(data)
# Perform random deactivation : stay training In the pattern , Back to app dropout Output after ; Or in Africa training In mode , Normal return output ( No, dropout)
outputs = layer(data,training=True)
# Print the results after deactivation
print(outputs)
The result is :
[[ 1. 2.]
[ 3. 4.]
[ 5. 6.]
[ 7. 8.]
[ 9. 10.]]
tf.Tensor(
[[ 1.25 2.5 ]
[ 0. 5. ]
[ 6.25 7.5 ]
[ 8.75 10. ]
[ 0. 12.5 ]], shape=(5, 2), dtype=float32)
3. Early stop
Early stop (early stopping) Is to take part of the training set as the verification set (validation set). When the performance of the verification set becomes worse and worse, or the performance is no longer improved , Stop training the model immediately . This is called an early stop .
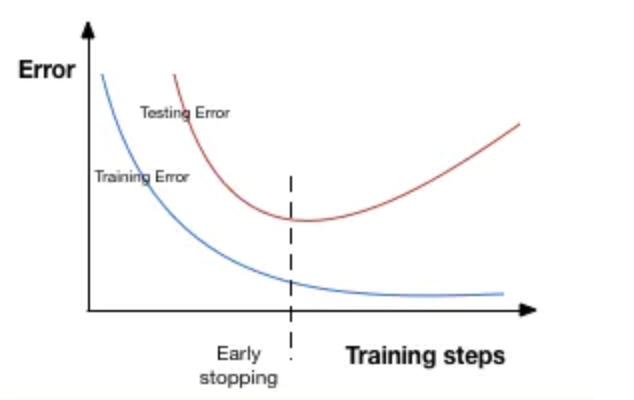
In the diagram above , Stop the training of the model at the dotted line , At this time, the model begins to over fit the training data .
stay tf.keras in , We can use callbacks Function implementation early stop :
tf.keras.callbacks.EarlyStopping(
monitor='val_loss', patience=5
)
above ,monitor The parameter indicates the monitored quantity , here val_loss Indicates the loss of validation set . and patience Parameters epochs Number , When there is no improvement in performance during this process, the training will be stopped . Just to understand , Let's take another look at the picture above . After the dotted line , Every epoch Will lead to higher verification set errors . therefore , After the dotted line patience individual epoch, The model will stop training , Because there is no further improvement .
# Import the corresponding toolkit
import tensorflow as tf
import numpy as np
# As the continuous 3 individual epoch loss Stop training if you don't descend
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)
# Define a neural network with only one layer
model = tf.keras.models.Sequential([tf.keras.layers.Dense(10)])
# Set the loss function and gradient descent algorithm
model.compile(tf.keras.optimizers.SGD(), loss='mse')
# model training
history = model.fit(np.arange(100).reshape(5, 20), np.array([0,1,2,1,2]),
epochs=10, batch_size=1, callbacks=[callback],
verbose=1)
# Print running epoch
len(history.history['loss'])
Output :
Epoch 1/10
5/5 [==============================] - 0s 600us/step - loss: 145774557280600064.0000
Epoch 2/10
5/5 [==============================] - 0s 522us/step - loss: 10077891596456623723194184833695744.0000
Epoch 3/10
5/5 [==============================] - 0s 1ms/step - loss: inf
Epoch 4/10
5/5 [==============================] - 0s 1ms/step - loss: inf
# Just run 4 Time
4
4. Batch of standardized
Batch of standardized (BN layer ,Batch Normalization) yes 2015 A method proposed in , During in-depth network training , Most of them will adopt this algorithm , Same as full connection layer ,BN Layer is also a layer in the network .
BN Layer is for a single neuron , When using the Internet to train mini-batch To calculate the neuron xi The mean and variance of , Normalized and reconstructed , So it's called Batch Normalization. Before each layer input , Take the data BN, Then send it to the follow-up network for learning :
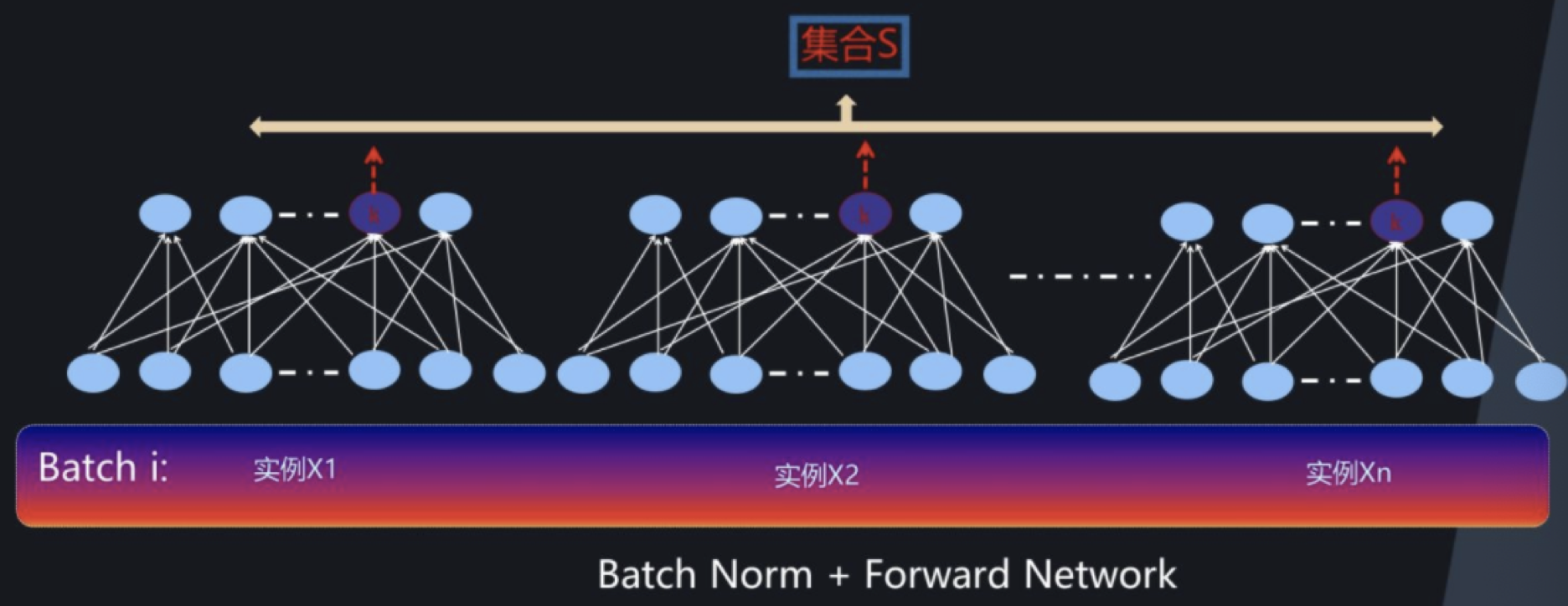
First, we standardize the output of neurons in a batch of data ,
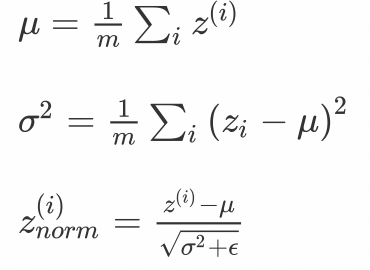
Then use transform reconstruction , The learnable parameter is introduced γ、β, If the input mean of each hidden layer is close to 0 Region , That is, in the linear region of the activation function , It is not conducive to the training of nonlinear neural networks , So as to obtain the model with poor effect . therefore , Need to use γ and β Further processing of the standardized results :
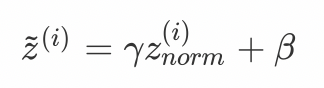
This is it. BN The final result of the layer . The overall process is shown in the figure below :

stay tf.keras Implementation and use in :
# It can be directly put into the structure of neural network
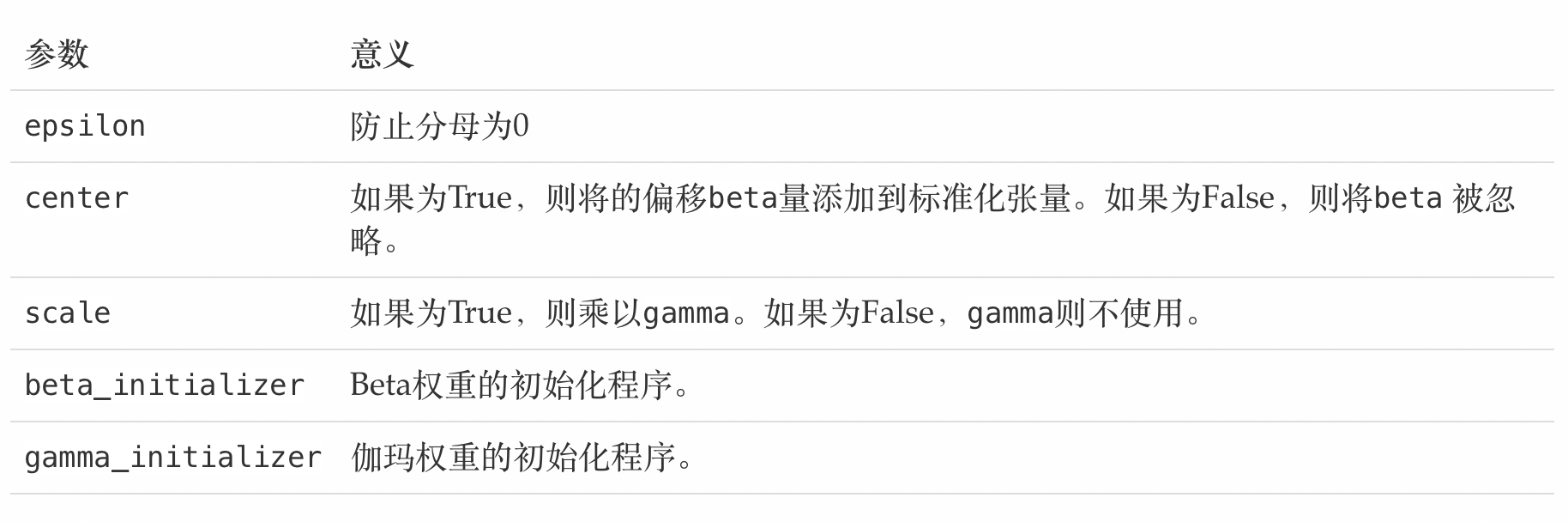
tf.keras.layers.BatchNormalization(
epsilon=0.001, center=True, scale=True,
beta_initializer='zeros', gamma_initializer='ones',
)
summary
know L2 Regularization and L1 The method of regularization
In loss function (cost function) Add a regular item to , Due to the addition of this regularization term , The value of the weight matrix decreases , Because it assumes that a neural network with a smaller weight matrix leads to a simpler modelKnow random deactivation droupout Application
During each iteration , Select some nodes randomly , And delete forward and backward connectionsKnow how to stop early
When you see that the performance of the verification set is getting worse and worse, or the performance is no longer improved , Stop training the model immediatelyknow BN How to use layers
When using the Internet to train mini-batch To calculate the neuron xi The mean and variance of , Normalized and reconstructed , So it's called Batch Normalization
边栏推荐
- C language set operation
- LVGL 8.2 Draw label with gradient color
- Ranking list of databases in July: mongodb and Oracle scores fell the most
- 阿里被裁员工,找工作第N天,猎头又传来噩耗...
- UFO: Microsoft scholars have proposed a unified transformer for visual language representation learning to achieve SOTA performance on multiple multimodal tasks
- 如何配和弦
- C language personal address book management system
- 10. (map data) offline terrain data processing (for cesium)
- LVGL 8.2 Line wrap, recoloring and scrolling
- Introduction to modern control theory + understanding
猜你喜欢

Transplant tinyplay for imx6q development board QT system

Xcode abnormal pictures cause IPA packet size problems
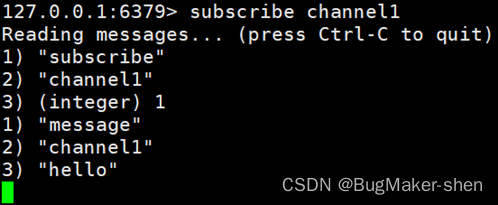
Redis publish and subscribe
Programmers exposed that they took private jobs: they took more than 30 orders in 10 months, with a net income of 400000
如何搭建一支搞垮公司的技术团队?

Free, easy-to-use, powerful lightweight note taking software evaluation: drafts, apple memo, flomo, keep, flowus, agenda, sidenote, workflow
Details of FPGA underlying resources

深度学习 神经网络案例(手写数字识别)
Guitar Pro 8win10最新版吉他学习 / 打谱 / 创作
UFO:微软学者提出视觉语言表征学习的统一Transformer,在多个多模态任务上达到SOTA性能!...
随机推荐
LVGL 8.2 Line
openresty 限流
[C language] Pointer written test questions
关于FPGA底层资源的细节问题
LVGL 8.2 Line
03 storage system
[local differential privacy and random response code implementation] differential privacy code implementation series (13)
Ffprobe common commands
IO流:节点流和处理流详细归纳。
Redis publier et s'abonner
Why do domestic mobile phone users choose iPhone when changing a mobile phone?
Memory management summary
MP3是如何诞生的?
10. (map data) offline terrain data processing (for cesium)
Detailed explanation of visual studio debugging methods
毕业季-个人总结
ES6 modularization
局部修改-渐进型开发
Red envelope activity design in e-commerce system
都在说DevOps,你真正了解它吗?