当前位置:网站首页>Flink CDC practice (including practical steps and screenshots)
Flink CDC practice (including practical steps and screenshots)
2022-07-03 09:35:00 【Did Xiao Hu get stronger today】
List of articles
Preface
This paper mainly focuses on B Stations Flink Video for learning and Practice , Record the relevant key points , As your study notes , In order to get started quickly .
Flink CDC
1. CDC brief introduction
1.1 What is? CDC
CDC yes Change Data Capture( Change data acquisition ) For short . The core idea is , Monitor and capture the database The change of ( Includes the insertion of data or data tables 、 Update and delete, etc ), Keep a complete record of these changes in the order they occur Come down , Write to message middleware for other services to subscribe and consume .
1.2 CDC The type of
CDC It is mainly divided into query based and Binlog Two ways .

1.3 Flink-CDC
Flink The community has developed flink-cdc-connectors Components , This is one that can be directly from MySQL、PostgreSQL The database directly reads the total data and incremental change data source Components .
Open source address :https://github.com/ververica/flink-cdc-connectors
2. Flink CDC Case practice
2.1 DataStream Application of method
2.1.1 Import dependence
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<!-- You can hit dependency to jar In bag -->
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.1.2 Write code
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/** * FlinkCDC * * @author hutianyi * @date 2022/5/30 **/
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1. obtain Flink execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// adopt FlinkCDC structure SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("123456")
.databaseList("cdc_test") // Monitored database
.tableList("cdc_test.user_info") // The table under the monitored database
.deserializer(new StringDebeziumDeserializationSchema())// Deserialization
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
//3. The data to print
dataStreamSource.print();
//4. Start the task
env.execute("FlinkCDC");
}
}
Turn on MysqlBinlog:
sudo vim /etc/my.cnf

log-bin=mysql-bin
binlog_format=row
binlog-do-db=cdc_test
restart mysql:
sudo systemctl restart mysqld
Switch to root user , Check whether it is successfully opened :
cd /var/lib/mysql

Create new databases and tables , And write data :

Review binlog file :
Already by 154 Turned into 926, explain binlog There is no problem opening .

Start project :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-yC2i0SHQ-1653917022942)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220530165404280.png)]](/img/95/9697b76982666f6816d826e51d6318.png)
Add a piece of data :

You can see that the console has captured the new data :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-j18lJXWF-1653917022942)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220530165609574.png)]](/img/f6/a842bd246d40e96d14a55565a8c299.png)
Modify the second data :
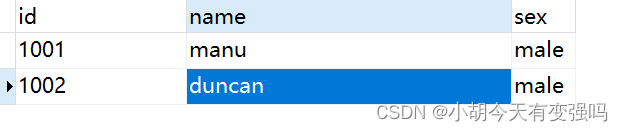
You can see the data captured in the console :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-AGsAXj2R-1653917022942)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220530170038793.png)]](/img/52/76729d2fabd0db35705ffaefa23a86.png)
Delete the second data :

Only before The data of .![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-fngPkuaA-1653917022942)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220530170609441.png)]](/img/36/21bb8e2be0612234de8000e5845e17.png)
be aware op There are different values :
r: Query read c: newly added u: to update d: Delete
2.2.3 Submit to the cluster to run
Open in code checkpoint:
//1.1 Turn on checkpoint
env.enableCheckpointing(5000);//5 Second
env.getCheckpointConfig().setCheckpointTimeout(10000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/cdc-test/ck"));
pack :

start-up flink colony :
./start-cluster.sh

Will play well jar Upload the package to the cluster :
start-up :
bin/flink run -m hadoop102:8081 -c com.tianyi.FlinkCDC ./flink-cdc-1.0-SNAPSHOT-jar-with-dependencies.jar
stay Flink webui To view the :8081 port
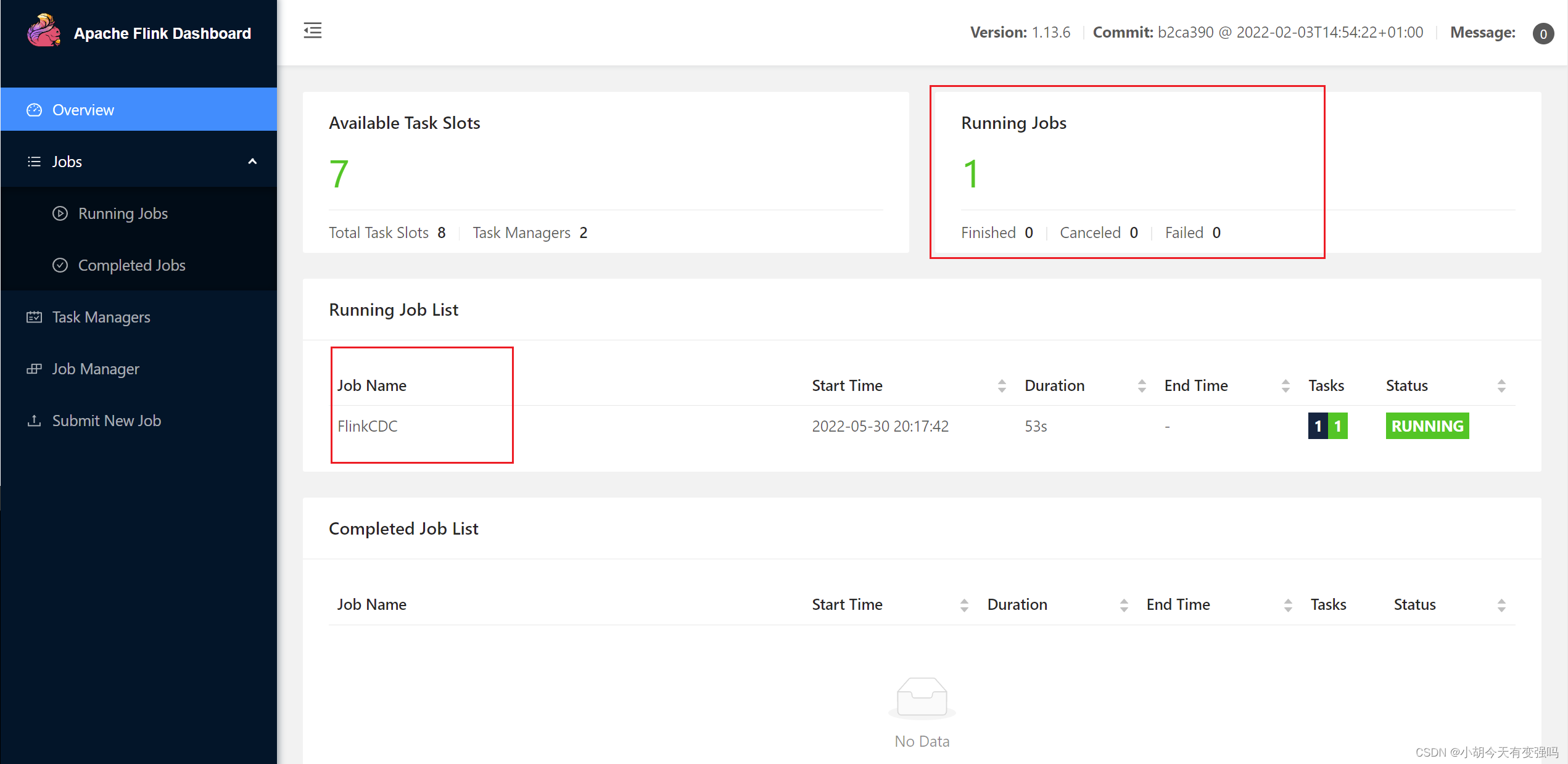
Check the log :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-fJazqQrJ-1653917022943)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220530202319139.png)]](/img/21/f4af706df39f55fa28af1027d82329.png)
2.1.4 Breakpoint continuation savepoint
To the present Flink Program creation Savepoint:
bin/flink savepoint JobId hdfs://hadoop102:8020/flink/save
After closing the program Savepoint Restart the program :
bin/flink run -s hdfs://hadoop102:8020/flink/save/... -c Full class name flink-1.0-SNAPSHOT-jar-with-dependencies.jar
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-FOiRSioM-1653917022943)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220530202737681.png)]](/img/d5/729cdcaf8c2f39d6d4e8c59e8b5b01.png)
2.2 FlinkSQL Application of method
2.2.1 Code implementation
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQLCDC {
public static void main(String[] args) throws Exception {
//1. Create an execution environment
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2. establish Flink-MySQL-CDC Of Source
tableEnv.executeSql("CREATE TABLE user_info (" +
" id STRING primary key," +
" name STRING," +
" sex STRING" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'hostname' = 'hadoop102'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '123456'," +
" 'database-name' = 'cdc_test'," +
" 'table-name' = 'user_info'" +
")");
//3. Query the data and convert it into stream output
Table table = tableEnv.sqlQuery("select * from user_info");
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnv.toRetractStream(table, Row.class);
retractStream.print();
//4. start-up
env.execute("FlinkSQLCDC");
}
}
Start project :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-P1poK4jf-1653917022944)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220530210204715.png)]](/img/9d/ce07eae2f29deaf38c47926c2c6fb8.png)
2.2.2 test
Add data :
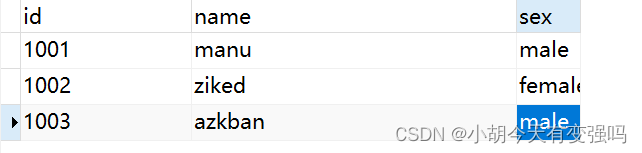
The console captures the changes :

2.3 Custom deserializer
Code implementation :
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
public class CustomerDeserializationSchema implements DebeziumDeserializationSchema<String> {
/** * { * "db":"", * "tableName":"", * "before":{"id":"1001","name":""...}, * "after":{"id":"1001","name":""...}, * "op":"" * } */
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
// establish JSON Object is used to encapsulate the result data
JSONObject result = new JSONObject();
// Get library name & Table name
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
result.put("db", fields[1]);
result.put("tableName", fields[2]);
// obtain before data
Struct value = (Struct) sourceRecord.value();
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
// Get column information
Schema schema = before.schema();
List<Field> fieldList = schema.fields();
for (Field field : fieldList) {
beforeJson.put(field.name(), before.get(field));
}
}
result.put("before", beforeJson);
// obtain after data
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
// Get column information
Schema schema = after.schema();
List<Field> fieldList = schema.fields();
for (Field field : fieldList) {
afterJson.put(field.name(), after.get(field));
}
}
result.put("after", afterJson);
// Get operation type
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
result.put("op", operation);
// Output data
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
Create custom serialized object processing :
import com.tianyi.func.CustomerDeserializationSchema;
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC2 {
public static void main(String[] args) throws Exception {
//1. obtain Flink execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 Turn on CK
// env.enableCheckpointing(5000);
// env.getCheckpointConfig().setCheckpointTimeout(10000);
// env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/cdc-test/ck"));
//2. adopt FlinkCDC structure SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("123456")
.databaseList("cdc_test")
// .tableList("cdc_test.user_info")
// Use a custom deserializer
.deserializer(new CustomerDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
//3. The data to print
dataStreamSource.print();
//4. Start the task
env.execute("FlinkCDC");
}
}
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-zhW6ie9e-1653917022944)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220530211450198.png)]](/img/83/591baee8be3dd75c21c71f79465ada.png)
2.4 DataStream and FlinkSQL A comparison of ways
DataStream stay Flink1.12 and 1.13 Both can be used. , and FlinkSQL Only in Flink1.13 Use .
DataStream It can monitor multiple databases and tables at the same time , and FlinkSQL Only a single table can be monitored .
summary
This paper mainly introduces Flink CDC The concept of , And for DataStream and FlinkSQL Practice in two ways , You can feel it intuitively FlinkCDC The power of , The two methods are compared .
Reference material
边栏推荐
- Redis learning (I)
- [kotlin learning] control flow of higher-order functions -- lambda return statements and anonymous functions
- Hudi quick experience (including detailed operation steps and screenshots)
- [set theory] order relation (chain | anti chain | chain and anti chain example | chain and anti chain theorem | chain and anti chain inference | good order relation)
- Jetson nano custom boot icon kernel logo CBOOT logo
- 一款开源的Markdown转富文本编辑器的实现原理剖析
- LeetCode每日一题(745. Prefix and Suffix Search)
- Apply for domain name binding IP to open port 80 record
- Crawler career from scratch (3): crawl the photos of my little sister ③ (the website has been disabled)
- Install database -linux-5.7
猜你喜欢

LeetCode每日一题(1162. As Far from Land as Possible)

Crawler career from scratch (II): crawl the photos of my little sister ② (the website has been disabled)

Solve the problem of disordered code in vscode development, output Chinese and open source code
![[kotlin puzzle] what happens if you overload an arithmetic operator in the kotlin class and declare the operator as an extension function?](/img/fc/5c71e6457b836be04583365edbe08d.png)
[kotlin puzzle] what happens if you overload an arithmetic operator in the kotlin class and declare the operator as an extension function?
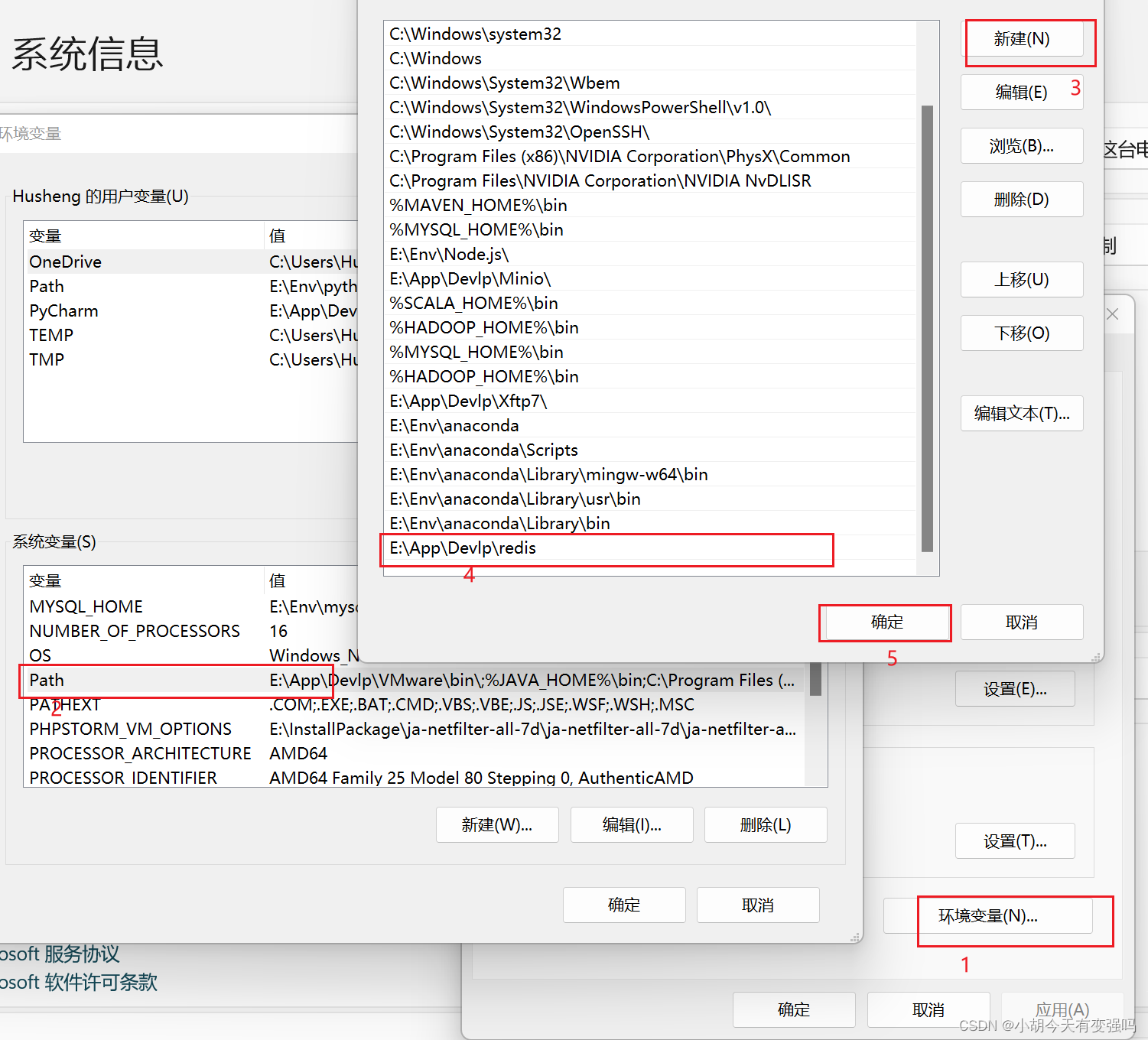
Detailed steps of windows installation redis
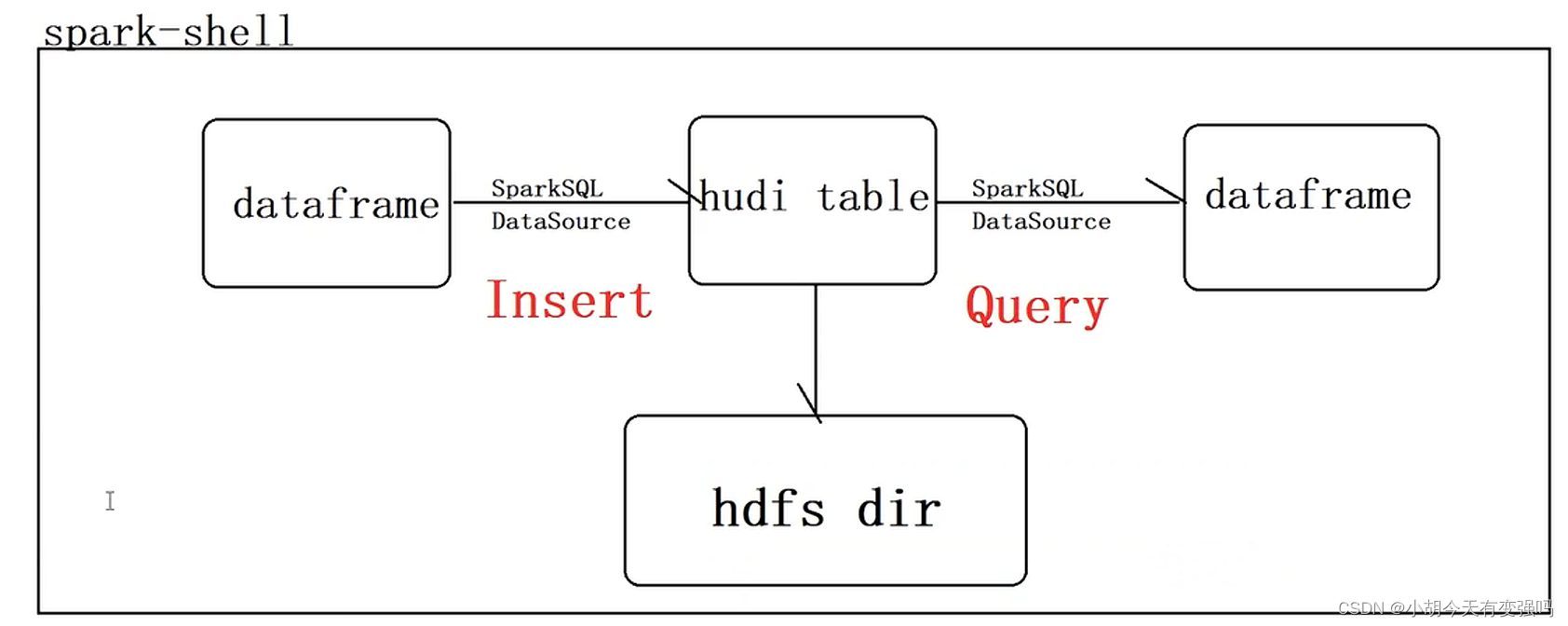
Hudi quick experience (including detailed operation steps and screenshots)

Global KYC service provider advance AI in vivo detection products have passed ISO international safety certification, and the product capability has reached a new level

软件测试工程师是做什么的 通过技术测试软件程序中是否有漏洞

CATIA automation object architecture - detailed explanation of application objects (I) document/settingcontrollers

About the configuration of vs2008+rade CATIA v5r22
随机推荐
Jestson Nano 从tftp服务器下载更新kernel和dtb
The server denied password root remote connection access
【Kotlin学习】类、对象和接口——带非默认构造方法或属性的类、数据类和类委托、object关键字
LeetCode每日一题(1162. As Far from Land as Possible)
Leetcode daily question (968. binary tree cameras)
Powerdesign reverse wizard such as SQL and generates name and comment
Django operates Excel files through openpyxl to import data into the database in batches.
Please tell me how to set vscode
LeetCode每日一题(1362. Closest Divisors)
Solve editor MD uploads pictures and cannot get the picture address
Common formulas of probability theory
LeetCode每日一题(2090. K Radius Subarray Averages)
Apply for domain name binding IP to open port 80 record
Hudi data management and storage overview
【Kotlin学习】高阶函数的控制流——lambda的返回语句和匿名函数
软件测试工程师是做什么的 通过技术测试软件程序中是否有漏洞
Overview of database system
Hudi learning notes (III) analysis of core concepts
IDEA 中使用 Hudi
Temper cattle ranking problem