当前位置:网站首页>Flink-CDC实践(含实操步骤与截图)
Flink-CDC实践(含实操步骤与截图)
2022-07-03 09:00:00 【小胡今天有变强吗】
文章目录
前言
本文主要对B站的Flink视频进行学习并实操,将相关重点进行记录,当做自己的学习笔记,以便快速上手进行开发。
Flink CDC
1. CDC简介
1.1 什么是 CDC
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库 的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录 下来,写入到消息中间件中以供其他服务进行订阅及消费。
1.2 CDC 的种类
CDC 主要分为基于查询和基于 Binlog 两种方式。

1.3 Flink-CDC
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。
开源地址:https://github.com/ververica/flink-cdc-connectors
2. Flink CDC 案例实操
2.1 DataStream 方式的应用
2.1.1 导入依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<!-- 可以将依赖打到jar包中 -->
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.1.2 编写代码
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/** * FlinkCDC * * @author hutianyi * @date 2022/5/30 **/
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.获取Flink执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//通过FlinkCDC构建SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("123456")
.databaseList("cdc_test") //监控的数据库
.tableList("cdc_test.user_info") //监控的数据库下的表
.deserializer(new StringDebeziumDeserializationSchema())//反序列化
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
//3.数据打印
dataStreamSource.print();
//4.启动任务
env.execute("FlinkCDC");
}
}
开启MysqlBinlog:
sudo vim /etc/my.cnf

log-bin=mysql-bin
binlog_format=row
binlog-do-db=cdc_test
重启mysql:
sudo systemctl restart mysqld
切换至root用户,检查是否成功开启:
cd /var/lib/mysql
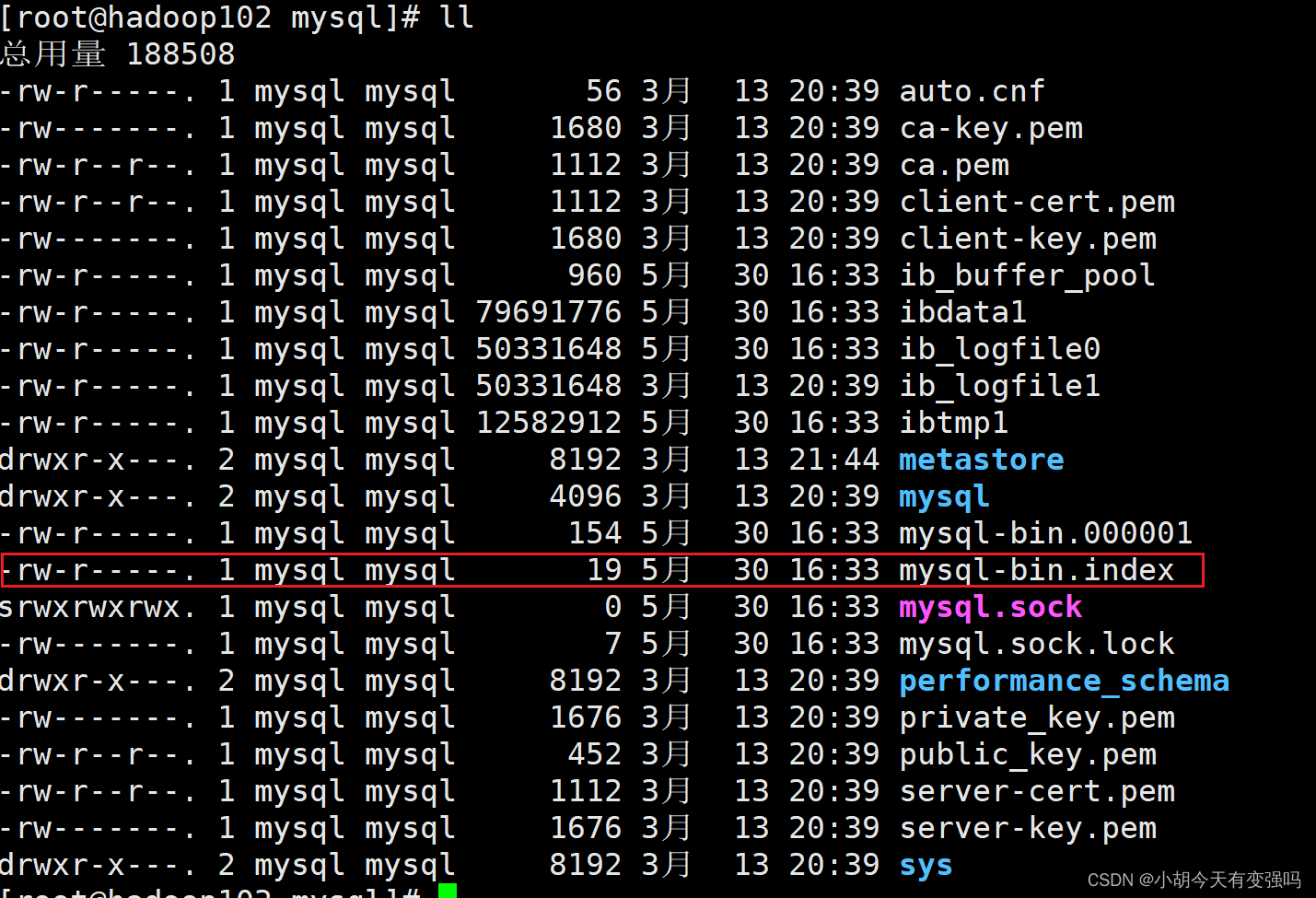

新建数据库和表,并写入数据:

重新查看binlog文件:
已经由154变成了926,说明binlog开启没有问题。

启动项目:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yC2i0SHQ-1653917022942)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220530165404280.png)]](/img/95/9697b76982666f6816d826e51d6318.png)
新增一条数据:

可以看到控制台已经捕获到新增的数据:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j18lJXWF-1653917022942)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220530165609574.png)]](/img/f6/a842bd246d40e96d14a55565a8c299.png)
修改第二条数据:
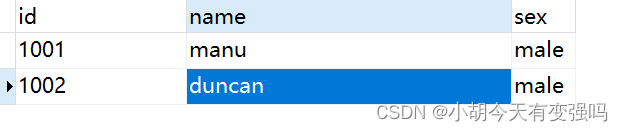
在控制台可以看到捕获到变化的数据:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AGsAXj2R-1653917022942)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220530170038793.png)]](/img/52/76729d2fabd0db35705ffaefa23a86.png)
删除第二条数据:

只有before的数据。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fngPkuaA-1653917022942)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220530170609441.png)]](/img/36/21bb8e2be0612234de8000e5845e17.png)
注意到op有不同的值:
r:查询读取 c:新增 u:更新 d:删除
2.2.3 提交到集群运行
代码中开启checkpoint:
//1.1开启checkpoint
env.enableCheckpointing(5000);//5秒钟
env.getCheckpointConfig().setCheckpointTimeout(10000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/cdc-test/ck"));
打包:

启动flink集群:
./start-cluster.sh

将打好的jar包上传至集群:
启动:
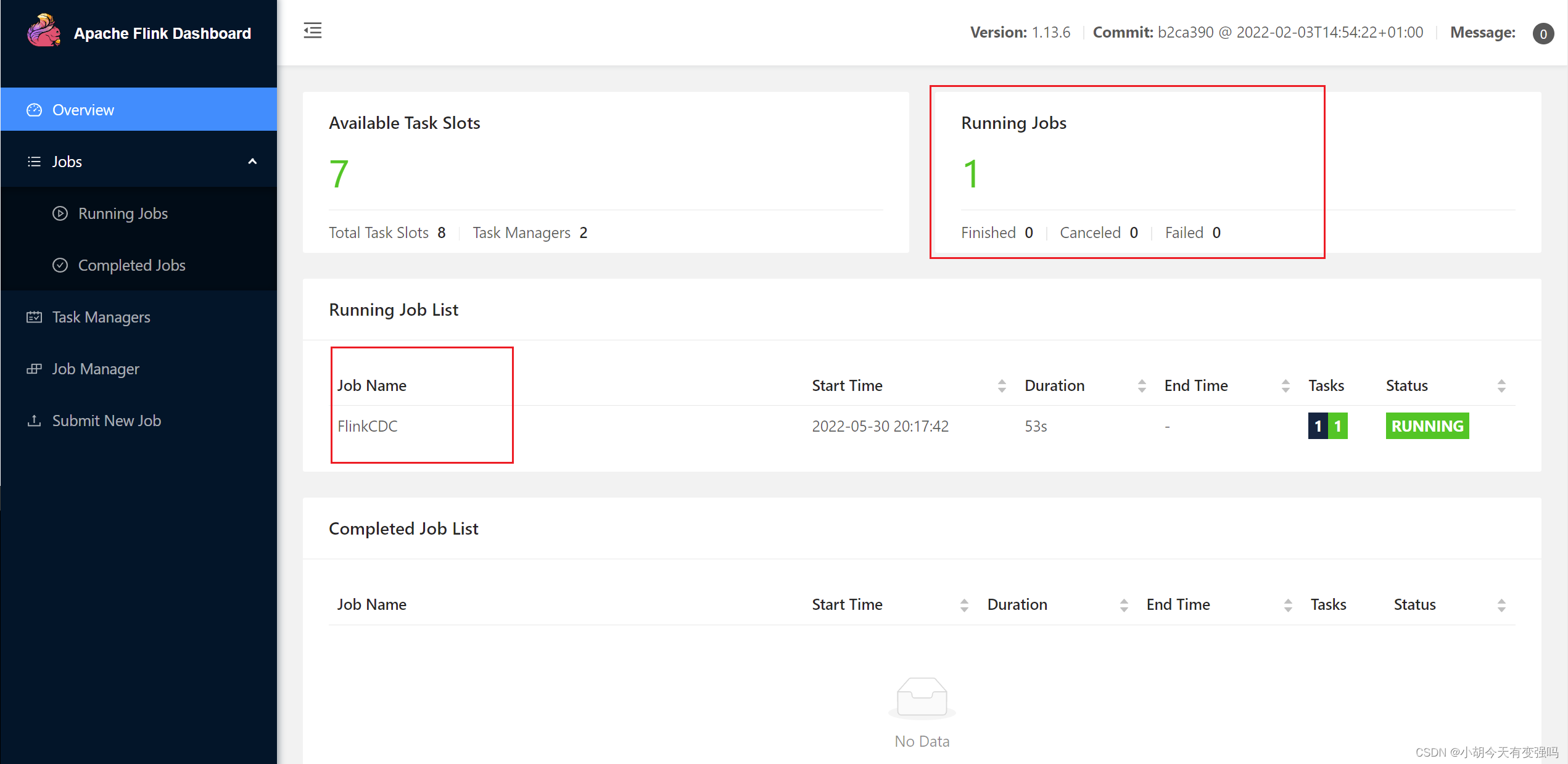
bin/flink run -m hadoop102:8081 -c com.tianyi.FlinkCDC ./flink-cdc-1.0-SNAPSHOT-jar-with-dependencies.jar
在Flink webui进行查看:8081端口
查看日志:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fJazqQrJ-1653917022943)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220530202319139.png)]](/img/21/f4af706df39f55fa28af1027d82329.png)
2.1.4 断点续传savepoint
给当前的 Flink 程序创建 Savepoint:
bin/flink savepoint JobId hdfs://hadoop102:8020/flink/save
关闭程序以后从 Savepoint 重启程序:
bin/flink run -s hdfs://hadoop102:8020/flink/save/... -c 全类名 flink-1.0-SNAPSHOT-jar-with-dependencies.jar
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FOiRSioM-1653917022943)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220530202737681.png)]](/img/d5/729cdcaf8c2f39d6d4e8c59e8b5b01.png)
2.2 FlinkSQL 方式的应用
2.2.1 代码实现
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQLCDC {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.创建 Flink-MySQL-CDC 的 Source
tableEnv.executeSql("CREATE TABLE user_info (" +
" id STRING primary key," +
" name STRING," +
" sex STRING" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'hostname' = 'hadoop102'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '123456'," +
" 'database-name' = 'cdc_test'," +
" 'table-name' = 'user_info'" +
")");
//3. 查询数据并转换为流输出
Table table = tableEnv.sqlQuery("select * from user_info");
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnv.toRetractStream(table, Row.class);
retractStream.print();
//4. 启动
env.execute("FlinkSQLCDC");
}
}
启动项目:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P1poK4jf-1653917022944)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220530210204715.png)]](/img/9d/ce07eae2f29deaf38c47926c2c6fb8.png)
2.2.2 测试
增添数据:
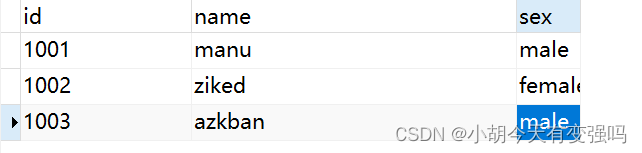
控制台捕获到变更:

2.3 自定义反序列化器
代码实现:
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
public class CustomerDeserializationSchema implements DebeziumDeserializationSchema<String> {
/** * { * "db":"", * "tableName":"", * "before":{"id":"1001","name":""...}, * "after":{"id":"1001","name":""...}, * "op":"" * } */
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
//创建JSON对象用于封装结果数据
JSONObject result = new JSONObject();
//获取库名&表名
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
result.put("db", fields[1]);
result.put("tableName", fields[2]);
//获取before数据
Struct value = (Struct) sourceRecord.value();
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
//获取列信息
Schema schema = before.schema();
List<Field> fieldList = schema.fields();
for (Field field : fieldList) {
beforeJson.put(field.name(), before.get(field));
}
}
result.put("before", beforeJson);
//获取after数据
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
//获取列信息
Schema schema = after.schema();
List<Field> fieldList = schema.fields();
for (Field field : fieldList) {
afterJson.put(field.name(), after.get(field));
}
}
result.put("after", afterJson);
//获取操作类型
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
result.put("op", operation);
//输出数据
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
创建自定义序列化对象处理:
import com.tianyi.func.CustomerDeserializationSchema;
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC2 {
public static void main(String[] args) throws Exception {
//1.获取Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 开启CK
// env.enableCheckpointing(5000);
// env.getCheckpointConfig().setCheckpointTimeout(10000);
// env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/cdc-test/ck"));
//2.通过FlinkCDC构建SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("123456")
.databaseList("cdc_test")
// .tableList("cdc_test.user_info")
//使用自定义的反序列化器
.deserializer(new CustomerDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
//3.数据打印
dataStreamSource.print();
//4.启动任务
env.execute("FlinkCDC");
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zhW6ie9e-1653917022944)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220530211450198.png)]](/img/83/591baee8be3dd75c21c71f79465ada.png)
2.4 DataStream 和 FlinkSQL 方式的对比
DataStream 在 Flink1.12 和 1.13 都可以用,而 FlinkSQL 只能在 Flink1.13 使用。
DataStream 可以同时监控多库多表,而 FlinkSQL 只能监控单表。
总结
本文主要介绍了Flink CDC的概念,以及对于DataStream 和 FlinkSQL两种方式进行实操,可以直观得感受FlinkCDC的强大功能,并对两种方式进行了对比。
参考资料
边栏推荐
- On February 14, 2022, learn the imitation Niuke project - develop the registration function
- We have a common name, XX Gong
- Temper cattle ranking problem
- Instant messaging IM is the countercurrent of the progress of the times? See what jnpf says
- Use the interface colmap interface of openmvs to generate the pose file required by openmvs mvs
- Computing level network notes
- dried food! What problems will the intelligent management of retail industry encounter? It is enough to understand this article
- Beego learning - JWT realizes user login and registration
- Internet Protocol learning record
- 【Kotlin学习】类、对象和接口——定义类继承结构
猜你喜欢

数字化管理中台+低代码,JNPF开启企业数字化转型的新引擎
Build a solo blog from scratch
Spark 集群安装与部署

LeetCode 532. K-diff number pairs in array

2022-2-13 learning xiangniuke project - version control

How to check whether the disk is in guid format (GPT) or MBR format? Judge whether UEFI mode starts or legacy mode starts?
【点云处理之论文狂读前沿版11】—— Unsupervised Point Cloud Pre-training via Occlusion Completion
Crawler career from scratch (3): crawl the photos of my little sister ③ (the website has been disabled)

Data mining 2021-4-27 class notes

Liteide is easy to use
随机推荐
How to check whether the disk is in guid format (GPT) or MBR format? Judge whether UEFI mode starts or legacy mode starts?
What is an excellent fast development framework like?
The server denied password root remote connection access
IDEA 中使用 Hudi
Notes on numerical analysis (II): numerical solution of linear equations
Jenkins learning (II) -- setting up Chinese
[graduation season | advanced technology Er] another graduation season, I change my career as soon as I graduate, from animal science to programmer. Programmers have something to say in 10 years
【毕业季|进击的技术er】又到一年毕业季,一毕业就转行,从动物科学到程序员,10年程序员有话说
Logstash+jdbc data synchronization +head display problems
MySQL installation and configuration (command line version)
The less successful implementation and lessons of RESNET
【点云处理之论文狂读前沿版8】—— Pointview-GCN: 3D Shape Classification With Multi-View Point Clouds
Vscode编辑器右键没有Open In Default Browser选项
图像修复方法研究综述----论文笔记
Excel is not as good as jnpf form for 3 minutes in an hour. Leaders must praise it when making reports like this!
[kotlin puzzle] what happens if you overload an arithmetic operator in the kotlin class and declare the operator as an extension function?
[point cloud processing paper crazy reading frontier version 10] - mvtn: multi view transformation network for 3D shape recognition
Hudi学习笔记(三) 核心概念剖析
【Kotlin学习】高阶函数的控制流——lambda的返回语句和匿名函数
Crawler career from scratch (II): crawl the photos of my little sister ② (the website has been disabled)