当前位置:网站首页>Crawler career from scratch (3): crawl the photos of my little sister ③ (the website has been disabled)
Crawler career from scratch (3): crawl the photos of my little sister ③ (the website has been disabled)
2022-07-03 09:18:00 【fishfuck】
List of articles
Preface
Start with this article , We will crawl through several articles in a row (url :https://imoemei.com/) All the pictures of my little sister . With this example, let's learn simple python Reptiles .
Please read the previous article
A reptilian career from scratch ( One ): Crawling for a picture of my little sister ①
A reptilian career from scratch ( Two ): Crawling for a picture of my little sister ②
Thought analysis
1. Page source analysis
After the first two crawls , We have got the photo of our little sister under the self photo item
But now our reptiles still have two problems :
First , The website has more than one sub item of selfie ,
thirdly , In the last article, we only got the first 30 Page url, This is a little far from our goal of crawling to take photos of the whole station
For the first question , We just need to crawl through the sub items on the homepage url You can solve it 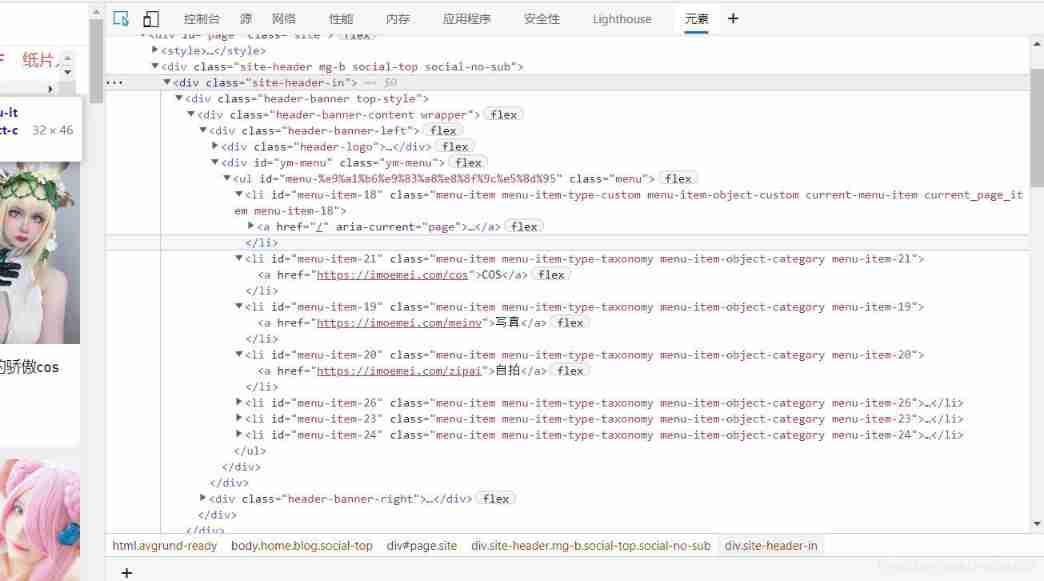
Just take each of the above a Labeled herf It's done
For the second question , After turning a few pages, we found that he turned pages ( Such as :https://imoemei.com/meinv/page/2) By page The following figures are used to determine
So as long as we modify this number, we can control page turning
Here comes the question , The total page of each sub item is different , Then how should we control ?
Or use crawlers to get the number of pages 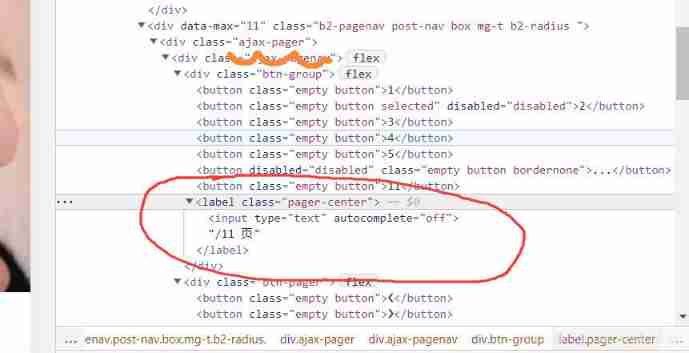
Just climb to label label , There are pages ?
But that's not the case 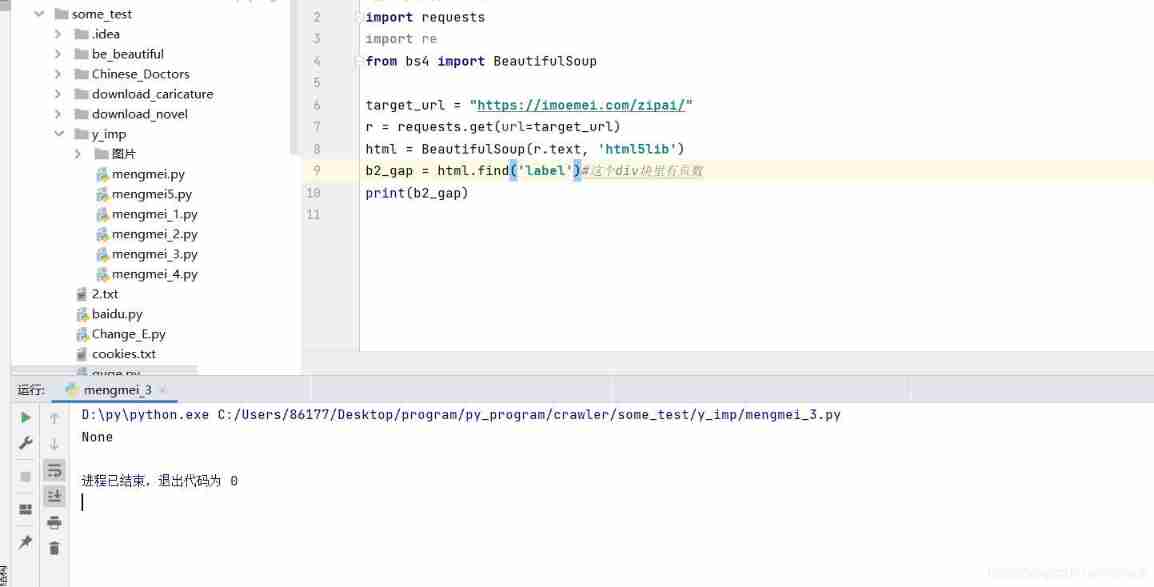
Crawling label, Found nothing to climb , And then I tried to climb label The parent label of the label , As a result, nothing can climb out
After consulting data , I find request Will only return html Original web page , And the target website label The label is through ajax To dynamically load
Fortunately, I found another div There are pages hidden in the block
But the number of pages is stored in the attribute 
What should I do ?
So I thought of using regular expressions to get the number of pages , At last it worked
2. Reptilian thinking
For question 1 , Directly follow the idea of the previous article to crawl the sub items url
For question 2 , Take out div The block is first converted into a string , Then use regular expression to get the number of pages
The crawler code
1. development environment
development environment :win10 python3.6.8
Using tools :pycharm
Using third party libraries :requests、os、BeatutifulSoup、re
2. Code decomposition
(1) Crawl each item url
import requests
from bs4 import BeautifulSoup
ind = []
target_url = "https://imoemei.com"
r = requests.get(url=target_url)
html = BeautifulSoup(r.text, 'html5lib')
menu = html.find('ul', class_='menu')
indexs = menu.find_all('a')
#print(indexs)
for index in indexs:
temp = index.get('href')
ind.append(temp)
del ind[0]
print(ind)
(2) Crawl pages
import requests
import re
from bs4 import BeautifulSoup
target_url = "https://imoemei.com/zipai/"
r = requests.get(url=target_url)
html = BeautifulSoup(r.text, 'html5lib')
b2_gap = html.find('div', class_='b2-pagenav post-nav box mg-t b2-radius')# This div There are pages in the block
b2_gap = str(b2_gap)# Convert to a string first
regex = '(?<=pages=").[0-9_]*'#re Match the page book
str_select = re.findall(regex,b2_gap)
print(str_select[0])
3. The overall code
import requests
import os
import re
from bs4 import BeautifulSoup
ind = []
target_url = "https://imoemei.com"
r = requests.get(url=target_url)
html = BeautifulSoup(r.text, 'html5lib')
menu = html.find('ul', class_='menu')
indexs = menu.find_all('a')
#print(indexs)
for index in indexs:
temp = index.get('href')
ind.append(temp)
del ind[0]
l = 0
for l in range(len(ind)+1):
target_url = ind[l]
r = requests.get(url=target_url)
html = BeautifulSoup(r.text, 'html5lib')
b2_gap = html.find('div', class_='b2-pagenav post-nav box mg-t b2-radius') # This div There are pages in the block
b2_gap = str(b2_gap) # Convert to a string first
regex = '(?<=pages=").[0-9_]*' # re Match the page book
str_select = re.findall(regex, b2_gap)
v = 0
for v in range(int(str_select[0]) + 1):
target_url = ind[l] + "//page//" + str(v)
r = requests.get(url=target_url)
html = BeautifulSoup(r.text, 'html5lib')
b2_gap = html.find('ul', class_='b2_gap')
print(str(1) + "page is OK")
img_main = b2_gap.find_all('a', class_='thumb-link')
img_main_urls = []
for img in img_main:
img_main_url = img.get('href')
img_main_urls.append(img_main_url)
for j in range(len(img_main_urls) + 1):
print(img_main_urls[j])
r = requests.get(url=img_main_urls[j])
html = BeautifulSoup(r.text, 'html5lib')
entry_content = html.find('div', class_='entry-content')
img_list = entry_content.find_all('img')
img_urls = []
num = 0
name = html.find('h1').text
print(name)
for img in img_list:
img_url = img.get('src')
result = requests.get(img_url).content
path = ' picture '
if not os.path.exists(path):
os.mkdir(path)
f = open(path + '/' + name + str(num) + '.jpg', 'wb')
f.write(result)
num += 1
print(' Downloading {} The first {} A picture '.format(name, num))
Crawling results


边栏推荐
- LeetCode 324. 摆动排序 II
- [point cloud processing paper crazy reading frontier edition 13] - gapnet: graph attention based point neural network for exploring local feature
- Sword finger offer II 029 Sorted circular linked list
- State compression DP acwing 91 Shortest Hamilton path
- How to check whether the disk is in guid format (GPT) or MBR format? Judge whether UEFI mode starts or legacy mode starts?
- AcWing 785. 快速排序(模板)
- 2022-2-13 learning the imitation Niuke project - home page of the development community
- [point cloud processing paper crazy reading classic version 10] - pointcnn: revolution on x-transformed points
- LeetCode 241. 为运算表达式设计优先级
- Problems in the implementation of lenet
猜你喜欢
Build a solo blog from scratch

With low code prospect, jnpf is flexible and easy to use, and uses intelligence to define a new office mode
LeetCode 1089. 复写零

【点云处理之论文狂读前沿版9】—Advanced Feature Learning on Point Clouds using Multi-resolution Features and Learni

LeetCode 30. Concatenate substrings of all words
![[point cloud processing paper crazy reading frontier version 10] - mvtn: multi view transformation network for 3D shape recognition](/img/94/2ab1feb252dc84c2b4fcad50a0803f.png)
[point cloud processing paper crazy reading frontier version 10] - mvtn: multi view transformation network for 3D shape recognition
【点云处理之论文狂读前沿版13】—— GAPNet: Graph Attention based Point Neural Network for Exploiting Local Feature

AcWing 785. 快速排序(模板)

dried food! What problems will the intelligent management of retail industry encounter? It is enough to understand this article
浅谈企业信息化建设
随机推荐
Data mining 2021-4-27 class notes
Save the drama shortage, programmers' favorite high-score American drama TOP10
Use of sort command in shell
Excel is not as good as jnpf form for 3 minutes in an hour. Leaders must praise it when making reports like this!
[point cloud processing paper crazy reading classic version 9] - pointwise revolutionary neural networks
[advanced feature learning on point clouds using multi resolution features and learning]
拯救剧荒,程序员最爱看的高分美剧TOP10
Overview of database system
Go language - Reflection
LeetCode 513. 找树左下角的值
Go language - IO project
We have a common name, XX Gong
Use the interface colmap interface of openmvs to generate the pose file required by openmvs mvs
LeetCode 532. K-diff number pairs in array
LeetCode 75. 颜色分类
【点云处理之论文狂读经典版10】—— PointCNN: Convolution On X-Transformed Points
LeetCode 1089. 复写零
【Kotlin学习】运算符重载及其他约定——重载算术运算符、比较运算符、集合与区间的约定
教育信息化步入2.0,看看JNPF如何帮助教师减负,提高效率?
The method of replacing the newline character '\n' of a file with a space in the shell