当前位置:网站首页>Spark structured stream writing Hudi practice
Spark structured stream writing Hudi practice
2022-07-03 09:21:00 【Did Xiao Hu get stronger today】
summary
Integrate Spark StructuredStreaming And Hudi, Write streaming data in real time Hudi In the table , For each batch of data batch DataFrame, use
Spark DataSource Write data in a way .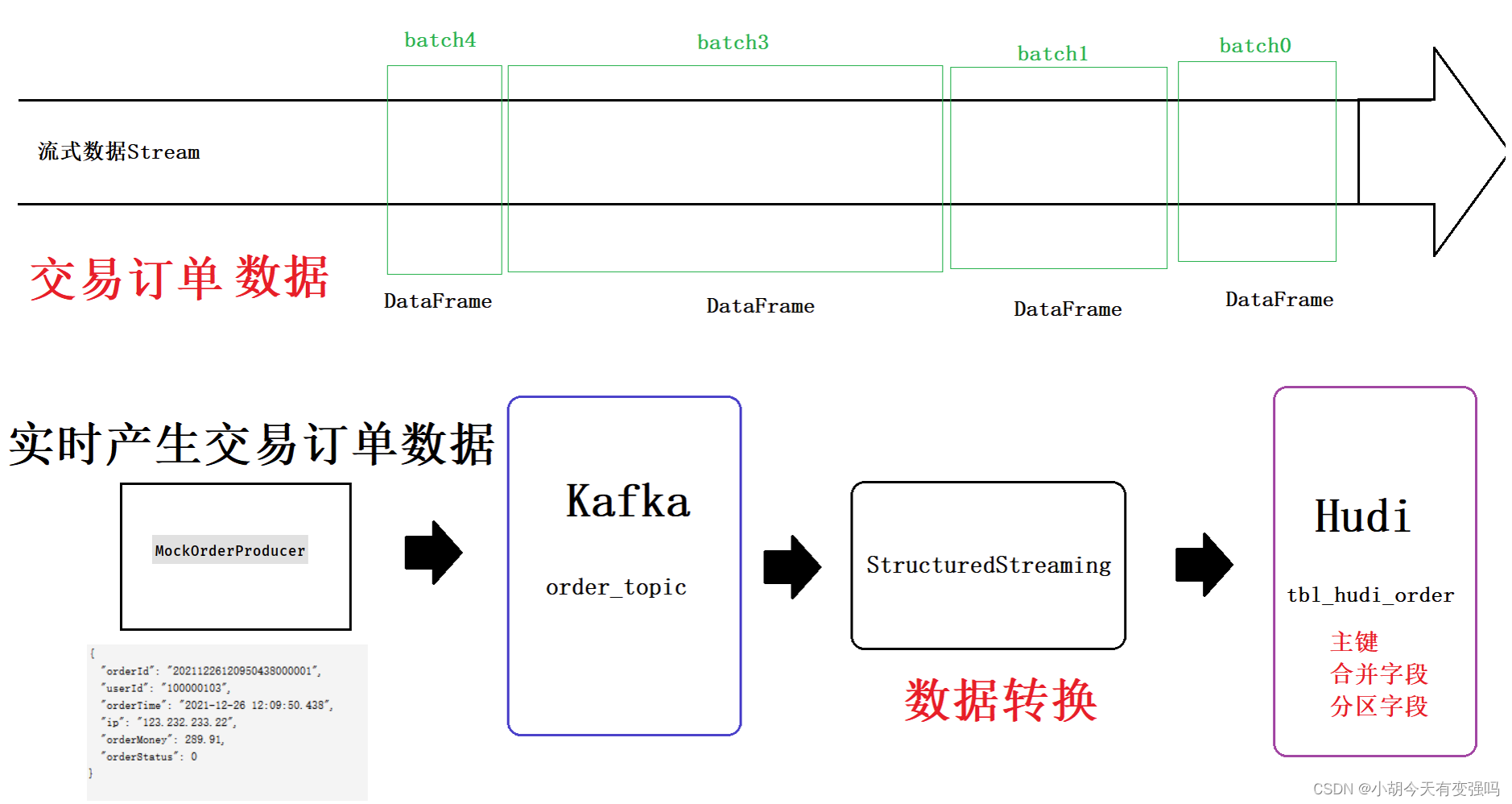
The process is the same as the previous blog https://blog.csdn.net/hshudoudou/article/details/125303310?spm=1001.2014.3001.5501 The configuration file of is consistent .
The project structure is shown in the figure below :
Mainly stream Two under the bag spark Code .
Code
- MockOrderProducer.scala
Simulate order generation to generate transaction order data in real time , Use Json4J Convert data to JSON character , send out Kafka Topic in .
import java.util.Properties
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.producer.{
KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import org.json4s.jackson.Json
import scala.util.Random
/** * Order entity class (Case Class) * * @param orderId Order ID * @param userId user ID * @param orderTime Order date time * @param ip Place an order IP Address * @param orderMoney Order amount * @param orderStatus The order status */
case class OrderRecord(
orderId: String,
userId: String,
orderTime: String,
ip: String,
orderMoney: Double,
orderStatus: Int
)
/** * Simulate production order data , Send to Kafka Topic in * Topic Every data in the database Message The type is String, With JSON Format data sending * Data conversion : * take Order Class instance object is converted to JSON Format string data ( have access to json4s Class library ) */
object MockOrderProducer {
def main(args: Array[String]): Unit = {
var producer: KafkaProducer[String, String] = null
try {
// 1. Kafka Client Producer Configuration information
val props = new Properties()
props.put("bootstrap.servers", "hadoop102:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
// 2. establish KafkaProducer object , Pass in configuration information
producer = new KafkaProducer[String, String](props)
// Random number instance object
val random: Random = new Random()
// The order status : Order opening 0, Order cancellation 1, Order closed 2, Order complete 3
val allStatus = Array(0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
while (true) {
// Each cycle Number of orders generated by simulation
val batchNumber: Int = random.nextInt(1) + 20
(1 to batchNumber).foreach {
number =>
val currentTime: Long = System.currentTimeMillis()
val orderId: String = s"${
getDate(currentTime)}%06d".format(number)
val userId: String = s"${
1 + random.nextInt(5)}%08d".format(random.nextInt(1000))
val orderTime: String = getDate(currentTime, format = "yyyy-MM-dd HH:mm:ss.SSS")
val orderMoney: String = s"${
5 + random.nextInt(500)}.%02d".format(random.nextInt(100))
val orderStatus: Int = allStatus(random.nextInt(allStatus.length))
// 3. Order record data
val orderRecord: OrderRecord = OrderRecord(
orderId, userId, orderTime, getRandomIp, orderMoney.toDouble, orderStatus
)
// Convert to JSON Format data
val orderJson = new Json(org.json4s.DefaultFormats).write(orderRecord)
println(orderJson)
// 4. structure ProducerRecord object
val record = new ProducerRecord[String, String]("order-topic", orderId, orderJson)
// 5. send data :def send(messages: KeyedMessage[K,V]*), Send data to Topic
producer.send(record)
}
// Thread.sleep(random.nextInt(500) + 5000)
Thread.sleep(random.nextInt(500))
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (null != producer) producer.close()
}
}
/** ================= Get the current time ================= */
def getDate(time: Long, format: String = "yyyyMMddHHmmssSSS"): String = {
val fastFormat: FastDateFormat = FastDateFormat.getInstance(format)
val formatDate: String = fastFormat.format(time) // Format date
formatDate
}
/** ================= Get random IP Address ================= */
def getRandomIp: String = {
// ip Range
val range: Array[(Int, Int)] = Array(
(607649792, 608174079), //36.56.0.0-36.63.255.255
(1038614528, 1039007743), //61.232.0.0-61.237.255.255
(1783627776, 1784676351), //106.80.0.0-106.95.255.255
(2035023872, 2035154943), //121.76.0.0-121.77.255.255
(2078801920, 2079064063), //123.232.0.0-123.235.255.255
(-1950089216, -1948778497), //139.196.0.0-139.215.255.255
(-1425539072, -1425014785), //171.8.0.0-171.15.255.255
(-1236271104, -1235419137), //182.80.0.0-182.92.255.255
(-770113536, -768606209), //210.25.0.0-210.47.255.255
(-569376768, -564133889) //222.16.0.0-222.95.255.255
)
// random number :IP Address range subscript
val random = new Random()
val index = random.nextInt(10)
val ipNumber: Int = range(index)._1 + random.nextInt(range(index)._2 - range(index)._1)
// transformation Int type IP The address is IPv4 Format
number2IpString(ipNumber)
}
/** ================= take Int type IPv4 Address conversion to string type ================= */
def number2IpString(ip: Int): String = {
val buffer: Array[Int] = new Array[Int](4)
buffer(0) = (ip >> 24) & 0xff
buffer(1) = (ip >> 16) & 0xff
buffer(2) = (ip >> 8) & 0xff
buffer(3) = ip & 0xff
// return IPv4 Address
buffer.mkString(".")
}
}
Pay attention to revision Kafka Client Producer Server configuration information in .
- HudiStructuredDemo.scala
Structured Streaming Application application , Real time slave Kafka Of 【order-topic】 consumption JSON Format data , after ETL After the transformation , Store in Hudi In the table .
import com.tianyi.hudi.didi.SparkUtils
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{
DataFrame, Dataset, Row, SaveMode, SparkSession}
/** * be based on StructuredStreaming Structured streams flow in real time from Kafka Consumption data , after ETL After the transformation , Store in Hudi surface */
object HudiStructuredDemo {
/** * Appoint Kafka Topic name , Real time consumption data */
def readFromKafka(spark: SparkSession, topicName: String): DataFrame = {
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "hadoop102:9092")
.option("subscribe", topicName)
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger", 100000)
.option("failOnDataLoss", "false")
.load()
}
def process(streamDF: DataFrame): DataFrame = {
streamDF
// Selection field
.selectExpr(
"CAST(key AS STRING) order_id",
"CAST(value AS STRING) AS message",
"topic", "partition", "offset", "timestamp"
)
// analysis Message data , Extract field values
.withColumn("user_id", get_json_object(col("message"), "$.userId"))
.withColumn("order_time", get_json_object(col("message"), "$.orderTime"))
.withColumn("ip", get_json_object(col("message"), "$.ip"))
.withColumn("order_money", get_json_object(col("message"), "$.orderMoney"))
.withColumn("order_status", get_json_object(col("message"), "$.orderStatus"))
// Delete message Field
.drop(col("message"))
// The format of conversion order date and time is Long type , As hudi Merge data fields in the table
.withColumn("ts", to_timestamp(col("order_time"), "yyyy-MM-dd HH:mm:ss.SSS"))
// Order date and time extraction partition log :yyyyMMdd
.withColumn("day", substring(col("order_time"), 0, 10))
}
/** * Stream data DataFrame Save to Hudi In the table */
def saveToHudi(streamDF: DataFrame) = {
streamDF.writeStream
.outputMode(OutputMode.Append())
.queryName("query-hudi-streaming")
.foreachBatch((batchDF: Dataset[Row], batchId: Long) => {
println(s"============== BatchId: ${
batchId} start ==============")
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.keygen.constant.KeyGeneratorOptions._
batchDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi Set the attribute value of the table
.option(RECORDKEY_FIELD.key(), "order_id")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(PARTITIONPATH_FIELD.key(), "day")
.option(TBL_NAME.key(), "tbl_hudi_order")
.option(TABLE_TYPE.key(), "MERGE_ON_READ")
// The partition value corresponds to the directory format , And Hive The partition policy is consistent
.option(HIVE_STYLE_PARTITIONING_ENABLE.key(), "true")
.save("/hudi-warehouse/tbl_hudi_order")
})
.option("checkpointLocation", "/datas/hudi-spark/struct-ckpt-1001")
.start()
}
def main(args: Array[String]): Unit = {
// Set the server user name
System.setProperty("HADOOP_USER_NAME","hty")
// step1、 structure SparkSession Instance object
val spark: SparkSession = SparkUtils.createSpakSession(this.getClass)
//step2、 from Kafka Real time consumption data
val kafkaStreamDF: DataFrame = readFromKafka(spark, "order-topic")
// step3、 Extract the data , Convert data type
val streamDF: DataFrame = process(kafkaStreamDF)
// step4、 Save data to Hudi In the table :MOR Type table , Read the table data merge file
saveToHudi(streamDF)
// step5、 After the streaming application starts , Waiting for termination
spark.streams.active.foreach(query => println(s"Query: ${
query.name} is Running .........."))
spark.streams.awaitAnyTermination()
}
}
Pay attention to modifying the relevant configuration of the server in the code .
test
- Test of simulated data generation
start-up MockOrderProducer.scala Code , Generate simulated order data .
- Create a consistent topic: order_topic
The software shown in the figure below is kafka The connector Offset , For creating and managing Topic Very convenient , You can download and connect the test from the Internet by yourself .
You can see Kafka Data has been received in .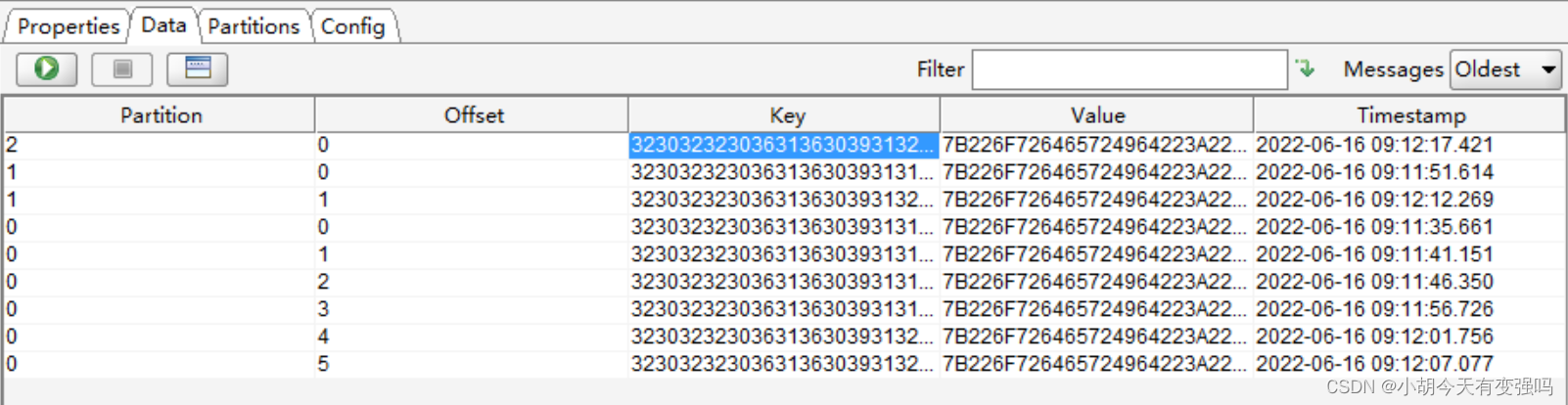
- HudiStructuredDemo.scala test , Start the main method , from Kafka Of order_topic China consumption data , And Hudi In the form of table HDFS in .
Check HDFS Storage under , The data consumed has been successfully written .
Many parquet file , That's exactly what it is. Hudi Storage form of . and parquet Files will not continue to grow after they have grown to a certain number , But maintain in a specific range , This is a Hudi You can merge the embodiment of the small file mechanism by yourself .
Spark Shell Inquire about
- start-up Spark-shell
./spark-shell --master local[2] \
--jars /opt/module/jars/hudi-jars/hudi-spark3-bundle_2.12-0.9.0.jar,\
--jars /opt/module/jars/hudi-jars/spark-avro_2.12-3.0.1.jar,\
--jars /opt/module/jars/hudi-jars/spark_unused-1.0.0.jar \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
- establish orderDF
val orderDF = spark.read.format("hudi").load("/hudi-warehouse/tbl_hudi_order")
- View table structure
orderDF.printSchema()
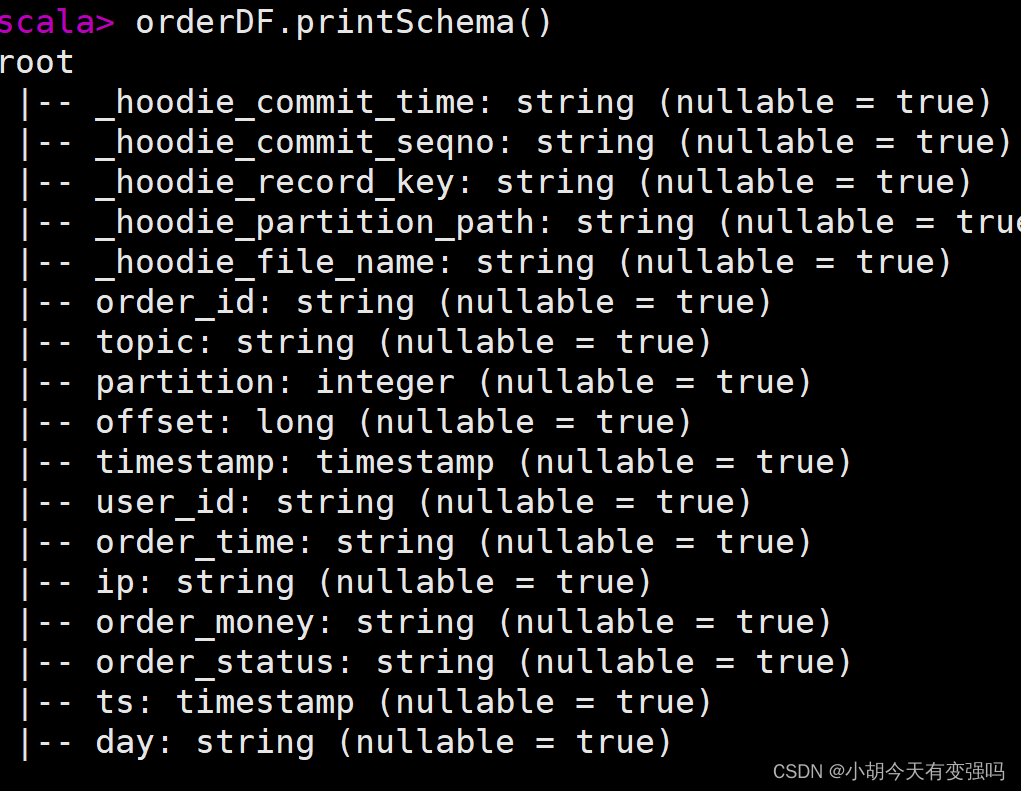
- Before the exhibition 10 Data
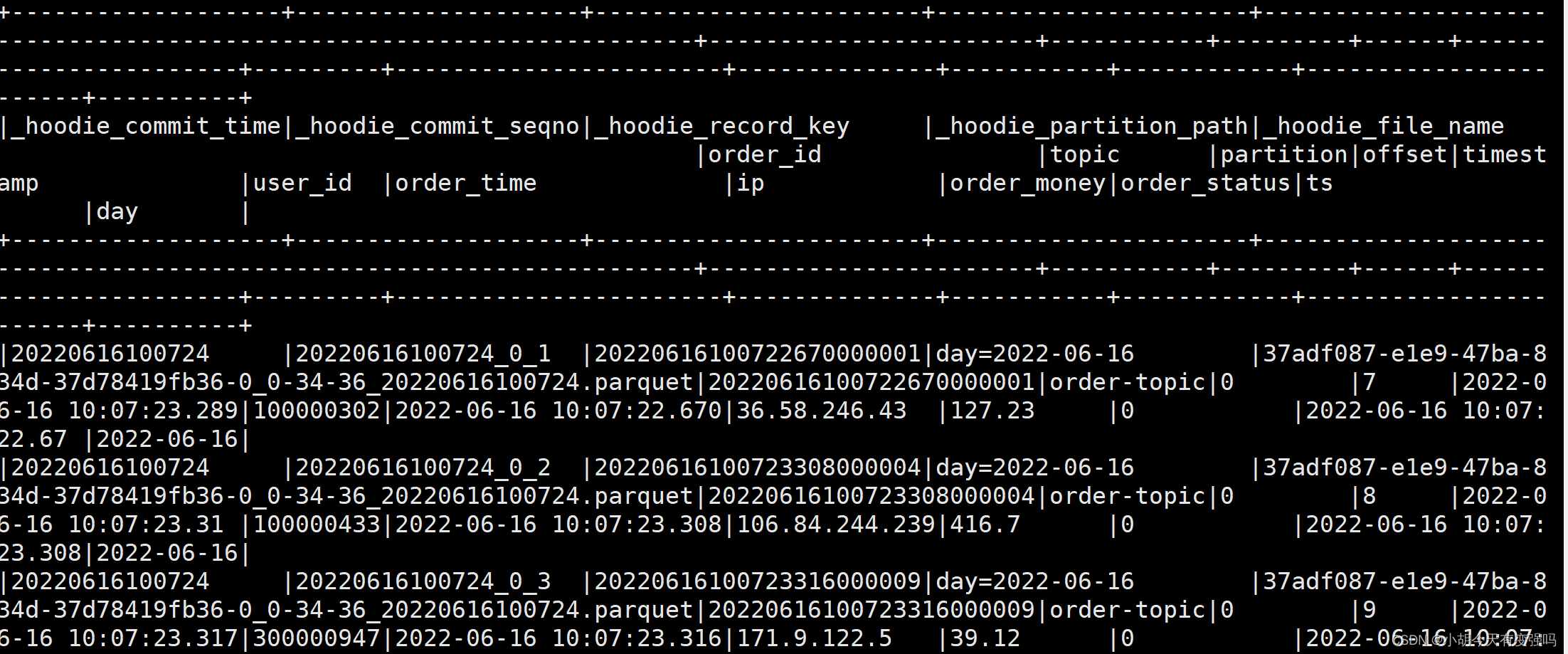
orderDF.show(10, false)
- Select a specific field
orderDF.select("order_id", "user_id", "order_time", "ip", "order_money", "order_status", "day").show(false)

- Aggregate statistics using functions
// Register as a temporary view
orderDF.createOrReplaceTempView("view_tmp_orders")
// perform SQL Make statistics
spark.sql(""" with tmp AS ( select CAST(order_money AS DOUBLE) from view_tmp_orders where order_status = '0' ) select max(order_money) as max_money, min(order_money) as min_money, round(avg(order_money), 2) as avg_money from tmp """).show

So far the whole process is over .
summary
This example uses spark The program generates simulated order transaction data , Real time by Spark Consumption , Again by Spark Consumption , Write to Hudi In the table .
边栏推荐
- 图像修复方法研究综述----论文笔记
- Go language - JSON processing
- Introduction to the usage of getopts in shell
- 拯救剧荒,程序员最爱看的高分美剧TOP10
- 数字化转型中,企业设备管理会出现什么问题?JNPF或将是“最优解”
- AcWing 788. 逆序对的数量
- excel一小时不如JNPF表单3分钟,这样做报表,领导都得点赞!
- 2022-2-13 learning the imitation Niuke project - home page of the development community
- Numerical analysis notes (I): equation root
- Wonderful review | i/o extended 2022 activity dry goods sharing
猜你喜欢
![[point cloud processing paper crazy reading frontier version 11] - unsupervised point cloud pre training via occlusion completion](/img/76/b92fe4549cacba15c113993a07abb8.png)
[point cloud processing paper crazy reading frontier version 11] - unsupervised point cloud pre training via occlusion completion
![[point cloud processing paper crazy reading classic version 14] - dynamic graph CNN for learning on point clouds](/img/7d/b66545284d6baea2763fd8d8555e1d.png)
[point cloud processing paper crazy reading classic version 14] - dynamic graph CNN for learning on point clouds
【点云处理之论文狂读经典版14】—— Dynamic Graph CNN for Learning on Point Clouds

2022-2-13 learning xiangniuke project - version control

Jenkins learning (III) -- setting scheduled tasks
![[point cloud processing paper crazy reading classic version 10] - pointcnn: revolution on x-transformed points](/img/c1/045ca010b212376dc3e5532d25c654.png)
[point cloud processing paper crazy reading classic version 10] - pointcnn: revolution on x-transformed points

Excel is not as good as jnpf form for 3 minutes in an hour. Leaders must praise it when making reports like this!
推荐一个 yyds 的低代码开源项目
Move anaconda, pycharm and jupyter notebook to mobile hard disk

LeetCode 57. 插入区间
随机推荐
Just graduate student reading thesis
[set theory] order relation (chain | anti chain | chain and anti chain example | chain and anti chain theorem | chain and anti chain inference | good order relation)
低代码起势,这款信息管理系统开发神器,你值得拥有!
拯救剧荒,程序员最爱看的高分美剧TOP10
[point cloud processing paper crazy reading classic version 12] - foldingnet: point cloud auto encoder via deep grid deformation
2022-2-14 learning xiangniuke project - generate verification code
What is the difference between sudo apt install and sudo apt -get install?
LeetCode 241. Design priorities for operational expressions
[point cloud processing paper crazy reading classic version 9] - pointwise revolutionary neural networks
Digital management medium + low code, jnpf opens a new engine for enterprise digital transformation
Spark 结构化流写入Hudi 实践
Recommend a low code open source project of yyds
Wonderful review | i/o extended 2022 activity dry goods sharing
剑指 Offer II 029. 排序的循环链表
Vscode编辑器右键没有Open In Default Browser选项
【Kotlin学习】类、对象和接口——定义类继承结构
Instant messaging IM is the countercurrent of the progress of the times? See what jnpf says
【点云处理之论文狂读经典版9】—— Pointwise Convolutional Neural Networks
LeetCode 515. 在每个树行中找最大值
LeetCode 715. Range 模块