当前位置:网站首页>Spark cluster installation and deployment
Spark cluster installation and deployment
2022-07-03 09:25:00 【Did Xiao Hu get stronger today】
List of articles
Spark Cluster installation deployment
Cluster planning :
The names of the three hosts are :hadoop102, hadoop103, hadoop104. The cluster planning is as follows :
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| Master+Worker | Worker | Worker |
Upload and unzip
Spark Download address :
https://spark.apache.org/downloads.html
take spark-3.0.0-bin-hadoop3.2.tgz File upload to Linux And decompress it in the specified location
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark
Modify the configuration file
Enter the path after decompression conf Catalog , modify slaves.template The file named slaves
mv slaves.template slaves
modify slaves file , add to work node
hadoop102 hadoop103 hadoop104modify spark-env.sh.template The file named spark-env.sh
mv spark-env.sh.template spark-env.shmodify spark-env.sh file , add to JAVA_HOME The environment variable corresponds to the cluster master node
export JAVA_HOME=/opt/module/jdk1.8.0_144 // Change it to your own jdk route SPARK_MASTER_HOST=hadoop102 SPARK_MASTER_PORT=7077distribution spark Catalog
xsync sparkNote that it needs to be installed in advance xsync Password free login , If not configured, you can refer to :https://blog.csdn.net/hshudoudou/article/details/123101151?spm=1001.2014.3001.5501
Start cluster
Execute script command :
sbin/start-all.sh![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-8w8JeNL9-1654759026708)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220609143834238.png)]](/img/e8/e1e53eee730483302151edf6945deb.png)
- Check the progress of three servers
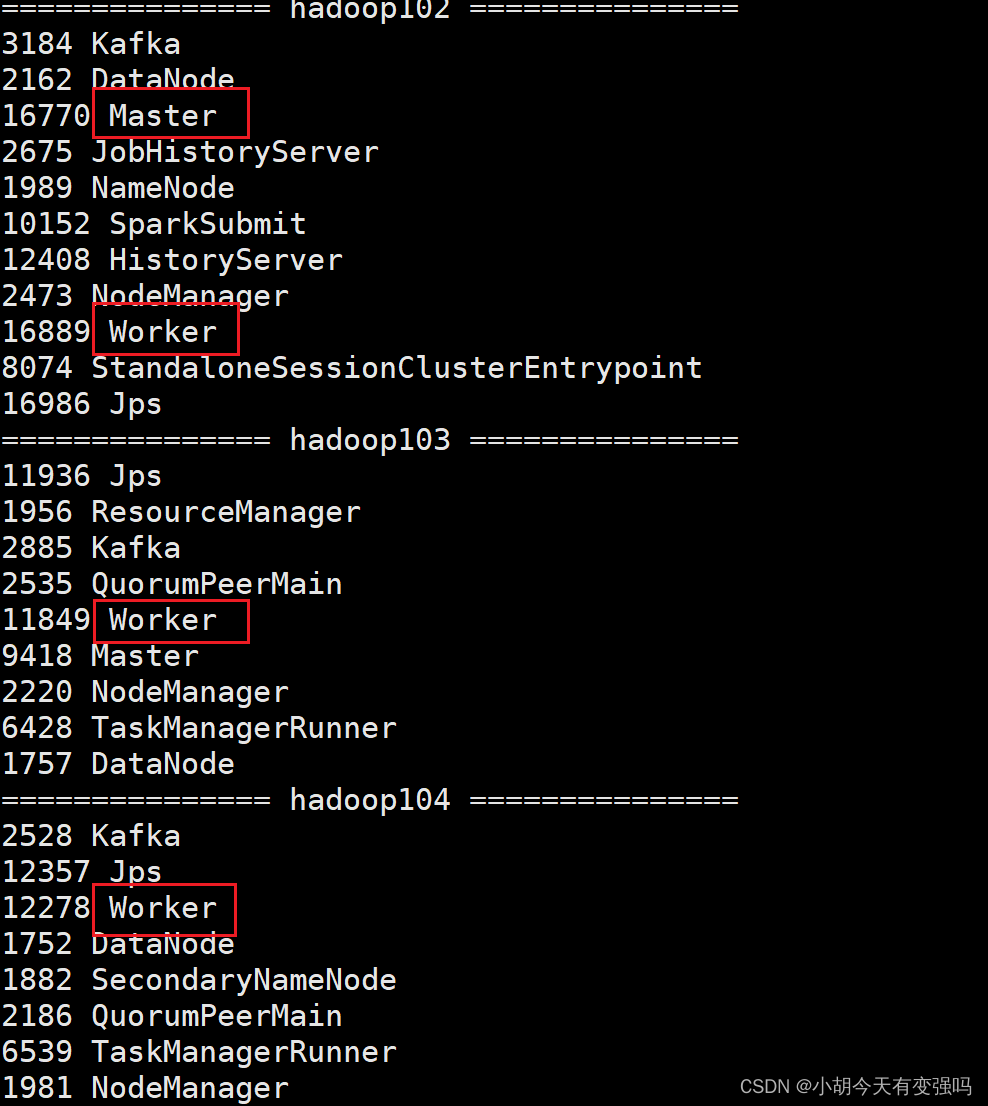
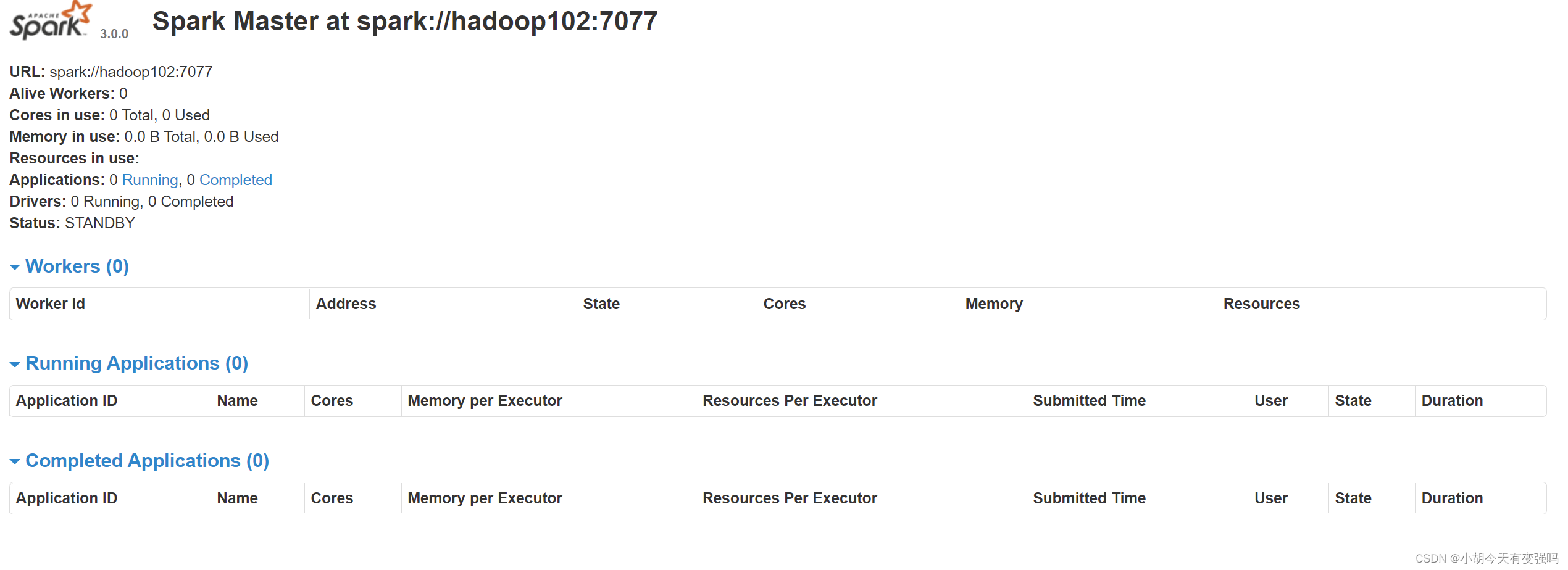
- see Master Resource monitoring Web UI Interface : http://hadoop102:8080
Submit app
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
–class Represents the main class of the program to execute
–master spark://hadoop102:7077 Independent deployment mode , Connect to Spark colony
spark-examples_2.12-3.0.0.jar Where the running class is located jar package
Numbers 10 Represents the entry parameter of the program , Used to set the number of tasks in the current application
Submit parameter description : In submitting applications , Generally, some parameters will be submitted at the same time
| Parameters | explain | Examples of optional values |
|---|---|---|
| –class | Spark The class containing the main function in the program | |
| –master | spark The mode in which the program runs ( Environmental Science ) | Pattern :local[*]、spark://linux1:7077、 Yarn |
| –executor-memory 1G | Specify each executor Available memory is 1G | Other configurations can be set according to the situation |
| –total-executor-cores 2 | Specify all executor The use of cpu Auditing for 2 individual | |
| –executor-cores | Specify each executor The use of cpu Check the number | |
| application-jar | Packaged applications jar, Include dependencies . | |
| application-arguments | Pass to main() Method parameters | |
Configure history server
modify spark-defaults.conf.template The file named spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
modify spark-default.conf file , Configure log storage path
spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop102:8020/directory
Need to start the hadoop colony ,HDFS Upper directory The directory needs to exist in advance .
If it doesn't exist , You need to create :
sbin/start-dfs.sh
hadoop fs -mkdir /director
modify spark-env.sh file , Add log configuration
export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory -Dspark.history.retainedApplications=30"Distribution profile
xsync conf
Restart the cluster and history service
sbin/start-all.sh sbin/start-history-server.shReexecute the task
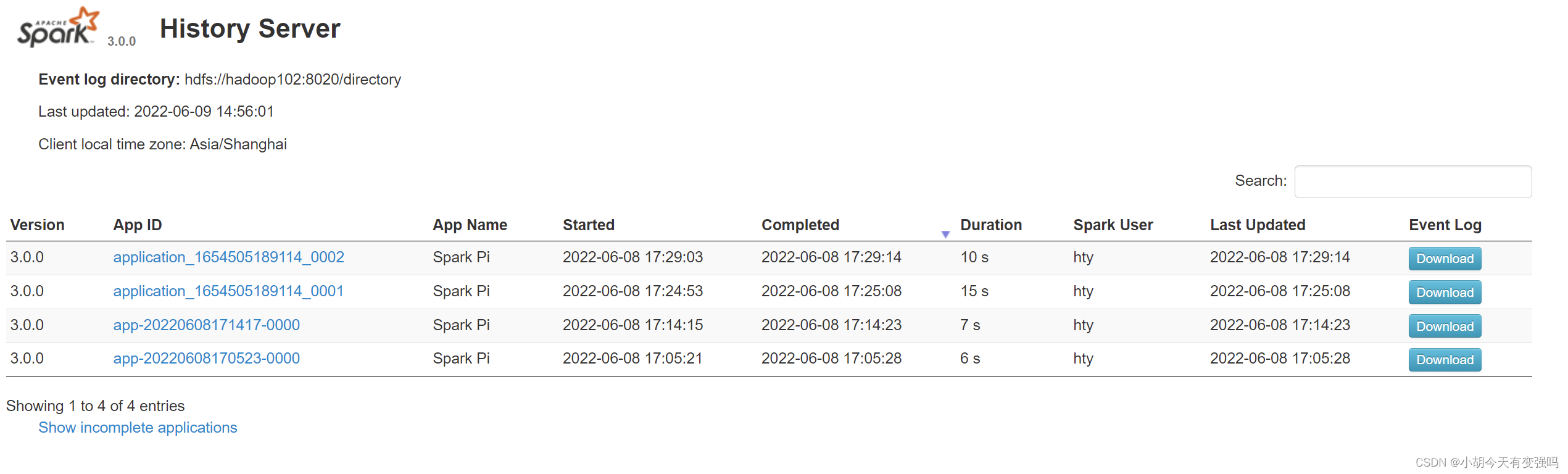
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop102:7077 \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10View history Services :http://hadoop102:18080
Configuration high availability (HA)
The so-called high availability is due to Master There is only one node , So there will be a single point of failure . therefore To solve the single point of failure problem , Multiple nodes need to be configured in the cluster Master node , Once active Master In case of failure , By standby Master Provide services , Ensure that the job can continue . The high availability here generally adopts Zookeeper Set up .
Cluster planning :
| hadoop02 | hadoop103 | hadoop04 |
|---|---|---|
| Master Zookeeper Worker | Master Zookeeper Worker | Zookeeper Worker |
Stop the cluster
sbin/stop-all.sh
start-up zookeeper
zk.sh start // Here is the use of script commands to start , If there is no script , Can be in zookeeper Under the directory, use the following command xstart zkmodify spark-env.sh Add the following configuration to the file
Note as follows :
#SPARK_MASTER_HOST=hadoop102
#SPARK_MASTER_PORT=7077
Add the following :
#Master The default access port of the monitoring page is 8080, But it could be with Zookeeper Conflict , So to 8989, It can also be from
Definition , visit UI Please note when monitoring the page
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104 -Dspark.deploy.zookeeper.dir=/spark"
Distribution profile
xsync conf/
Yarn Pattern
The above deployment mode is independent deployment (Standalone) Pattern , Independent deployment mode is provided by Spark Provide its own computing resources , No other framework is required to provide resources . this This method reduces the coupling with other third-party resource frameworks , Very independent .Spark Mainly the calculation framework , Instead of a resource scheduling framework , Therefore, the resource scheduling provided by itself is not its strength , Therefore, we should make more use of Yarn Pattern .
- modify hadoop The configuration file /opt/module/hadoop/etc/hadoop/yarn-site.xml, And distribute
<!-- Whether to start a thread to check the amount of physical memory that each task is using , If the task exceeds the assigned value , Kill it directly , Default yes true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- Whether to start a thread to check the amount of virtual memory that each task is using , If the task exceeds the assigned value , Kill it directly , Default yes true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
modify conf/spark-env.sh, add to JAVA_HOME and YARN_CONF_DIR To configure
export JAVA_HOME=/opt/module/jdk1.8.0_144 // Replace with your own jdk Catalog YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop // Instead, pack it yourself hadoop Catalog
- start-up HDFS as well as YARN colony
边栏推荐
- C language programming specification
- Flink学习笔记(十)Flink容错机制
- [kotlin learning] operator overloading and other conventions -- overloading the conventions of arithmetic operators, comparison operators, sets and intervals
- Tag paste operator (#)
- Bert install no package metadata was found for the 'sacraments' distribution
- Spark structured stream writing Hudi practice
- Flink-CDC实践(含实操步骤与截图)
- Logstash+jdbc data synchronization +head display problems
- Simple use of MATLAB
- Move anaconda, pycharm and jupyter notebook to mobile hard disk
猜你喜欢
【点云处理之论文狂读经典版13】—— Adaptive Graph Convolutional Neural Networks
![[kotlin learning] classes, objects and interfaces - define class inheritance structure](/img/66/34396e51c59504ebbc6b6eb9831209.png)
[kotlin learning] classes, objects and interfaces - define class inheritance structure
Vscode编辑器右键没有Open In Default Browser选项

【Kotlin学习】类、对象和接口——带非默认构造方法或属性的类、数据类和类委托、object关键字

【点云处理之论文狂读经典版9】—— Pointwise Convolutional Neural Networks
[graduation season | advanced technology Er] another graduation season, I change my career as soon as I graduate, from animal science to programmer. Programmers have something to say in 10 years
![[point cloud processing paper crazy reading frontier version 8] - pointview gcn: 3D shape classification with multi view point clouds](/img/ee/3286e76797a75c0f999c728fd2b555.png)
[point cloud processing paper crazy reading frontier version 8] - pointview gcn: 3D shape classification with multi view point clouds
![[kotlin puzzle] what happens if you overload an arithmetic operator in the kotlin class and declare the operator as an extension function?](/img/fc/5c71e6457b836be04583365edbe08d.png)
[kotlin puzzle] what happens if you overload an arithmetic operator in the kotlin class and declare the operator as an extension function?

State compression DP acwing 91 Shortest Hamilton path
MySQL installation and configuration (command line version)
![[graduation season | advanced technology Er] another graduation season, I change my career as soon as I graduate, from animal science to programmer. Programmers have something to say in 10 years](/img/7d/f69ef6805c38fcef6fef2df9ed0d70)
随机推荐
LeetCode 871. Minimum refueling times
LeetCode每日一题(1162. As Far from Land as Possible)
CSDN markdown editor help document
【点云处理之论文狂读前沿版9】—Advanced Feature Learning on Point Clouds using Multi-resolution Features and Learni
【点云处理之论文狂读前沿版12】—— Adaptive Graph Convolution for Point Cloud Analysis
Powerdesign reverse wizard such as SQL and generates name and comment
Redis learning (I)
The "booster" of traditional office mode, Building OA office system, was so simple!
[untitled] use of cmake
Move anaconda, pycharm and jupyter notebook to mobile hard disk
MySQL installation and configuration (command line version)
LeetCode 513. Find the value in the lower left corner of the tree
AcWing 786. Number k
[point cloud processing paper crazy reading frontier version 10] - mvtn: multi view transformation network for 3D shape recognition
CATIA automation object architecture - detailed explanation of application objects (I) document/settingcontrollers
Beego learning - JWT realizes user login and registration
Hudi 集成 Spark 数据分析示例(含代码流程与测试结果)
【点云处理之论文狂读经典版9】—— Pointwise Convolutional Neural Networks
Hudi 快速体验使用(含操作详细步骤及截图)
【点云处理之论文狂读经典版12】—— FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation