当前位置:网站首页>MySQL Index Optimization Practice II
MySQL Index Optimization Practice II
2022-07-07 23:24:00 【Which floor do you rate, moto】
Catalog
Detailed explanation of paging query optimization
Common paging scene optimization techniques
Paged query sorted by auto increasing and continuous primary key
Paging queries sorted by non primary key fields
surface JOIN Detailed explanation and optimization of correlation principle
mysql There are two common algorithms for table Association
Nested loop connection Nested-Loop Join Algorithm
Block based nested loop connections Block Nested-Loop Join Algorithm
For Association sql The optimization of the
surface COUNT Query optimization
Inquire about mysql The total number of rows maintained by yourself
Maintain the total to Redis in
Alibaba MYSQL Normative interpretation
MYSQL Data type selection analysis
Detailed explanation of paging query optimization
Many times, the paging function of our business system may be used as follows sql Realization
mysql> select * from employees limit 10000, 10;
From the table empoyes To remove from 10001 The line 10 rows . It seems that only query 10 Bar record , Actually this one SQL Is to take first 1010 Bar record , And then before I leave 1000 Bar record , Then read back 10 Data you want . Therefore, you need to query the data behind a large table , Execution efficiency is very low .
Common paging scene optimization techniques
Paged query sorted by auto increasing and continuous primary key
An example of a paged query sorted by a self increasing and continuous primary key
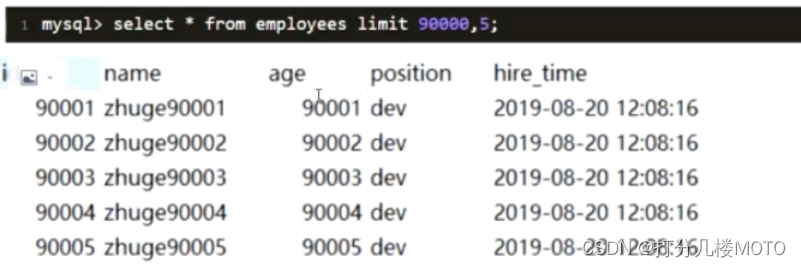
The SQL Indicates that the query starts from 90001 The first five lines of data , Indicates sorting by primary key . Because the primary key is self increasing and continuous , So it can be rewritten to query from 90001 The first five lines of data
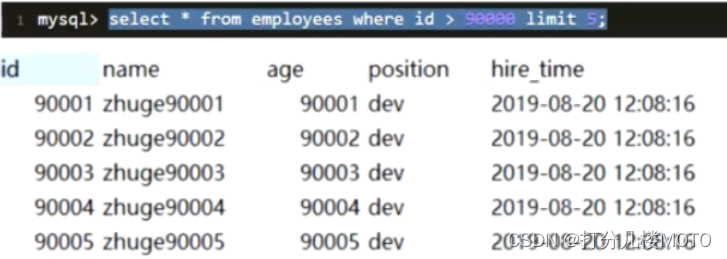
Paging queries sorted by non primary key fields
Use explain

Found no use name Index of field (key The corresponding value of the field is null), reason : Scan the entire index tree and find the index rows ( You may have to traverse multiple index trees ) The cost of is higher than that of scanning the whole table , So the optimizer abandons the use of indexes
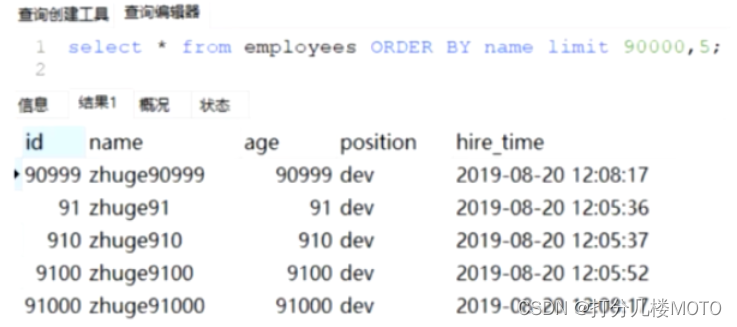
How to optimize : The key is to return as few fields as possible , therefore You can let sorting and paging operations find out the primary key first , Then find the corresponding record according to the primary key ,SQL Rewrite as follows :

from sql Execution shows :id by 2 First of all , The overlay index is used and the sort field is the first of the union index , So as to use the sorting of index tree
Yes id by 1 Of sql Scan the whole table for the temporary table
because id by 1 Of sql The connection field of is the primary key , Only one-to-one can be returned, so the execution type is eq_ref
The efficiency is half less than that of paging directly
surface JOIN Detailed explanation and optimization of correlation principle
mysql There are two common algorithms for table Association
Nested-Loop Join Algorithm
Block Nested-Loop Join Algorithm
Nested loop connection Nested-Loop Join Algorithm
Loop one row at a time from the first table ( Called drive table ) Read lines in , Get the associated field in this row of data , According to the associated fields in another table ( Was the driver table ) Take out the line that meets the conditions , Then take out the result set of the two tables

As can be seen from the implementation plan
The drive table is t2, The driven table is t1, The first thing to execute is the drive table ( The results of the implementation plan id If the same, execute from top to bottom sql); The optimizer usually preferentially selects small tables as the driving tables , So use inner join when , The top table is not necessarily the driving table
Use left join when , The left table is the driver table , The right table is the driven table ; Use right join when , The right table is the drive table , The left table is the driven table ; When using join when ,mysql Will choose the one with a small amount of data as the driving table , Big watch as driven watch
Used Nested-Loop Join Algorithm , commonly join In the sentence , If you execute the plan Extra There is no Using join buffer Is the use of join The algorithm is NLJ
sql General implementation process of
from t2 Read a row of data in the ( If t2 There are query filter conditions in the table , A row of data will be taken from the filtering result )
From the data in the first step , Remove associated fields a, To table t1 Search for
Take out t1 Rows in the table that meet the conditions , Follow t2 The results returned in the table are merged , Return to the client as a result
Repeat the above steps
The whole process will read t2 All the data in the table (100 That's ok ), Then traverse the fields in each row of data a Value , according to t2 In the table a Value index scan t1 The corresponding row in the table ( scanning 100 Time t1 Index of tables ,1 One scan can only scan the task in the end t1 One row of complete data in the table , That's all t1 The watch was also scanned 100 That's ok , So the whole process scans 200 That's ok ); If the associated field of the driven table has no index , Use Nested-Loop Join The performance of the algorithm will be low ,mysql Will choose Block Nested-Loop Join Algorithm
Block based nested loop connections Block Nested-Loop Join Algorithm
Be careful b Field is not a primary key field
Read the data of the driving table into join_buffer in , Then scan the driven table , Take out each row of the driven table and follow join_buffer Compare the data in
Extra Medium Using join buffer(Block Nested Loop) This indicates that the association query uses Block Nested-Loop Join Algorithm

above sql The general process is as follows
hold t2 All data of is added to join_buffer in
Keep watch t1 Take out every line in the , Follow join_buffer Compare the data in
Return to satisfaction join Conditional data
The whole process is on the table t1 and t2 We did a full scan , Therefore, the total number of rows scanned is 10000(t1 Row number )+100(t2 Row number )=10100. also join_buffer The data in the is out of order , So watch t1 Each line , Do it all 100 This judgment , So the number of judgments in memory is 100*10000=100 Ten thousand times , In this case t2 only 100 That's ok , If t2 It's also a big watch ,join_buffer What can I do if I can't put it down
join_buffer The size of is determined by join_buffer_buffer Set , The default value is 256k, If you can't put it down t2 Of all the data , Meeting Put... In sections
for instance t2 Yes 1000 Row data , You can only put... At a time 800 Row data , Then the execution process is to go first join_buffer discharge 800 rows , And then from t1 Take data from the table and follow join_buffer Some results are obtained by comparing the data in , And then empty join_buffer, And then put in t2 Table remaining 200 rows , Again from t1 The table fetches data with join_buffer Data comparison in , So I scanned it once more t1 surface
The associated field of the driven table has no index. Why do you choose to use BNL Algorithm without using Nested-Loop Join Well ?
If the second above sql Use Nested-Loop Join, Then the number of scanning lines is 100*10000 = 100 Ten thousand times , This is ScanDisk . Obviously , use BNL The number of disk scans is much less , Compared to disk scanning ,BNL Memory computing will be much faster .
therefore MySQL For an associated query with no index for the associated field of the driven table , Generally used BNL Algorithm . If there is an index, generally choose NLJ Algorithm , With an index NJ Algorithm ratio BNL The algorithm has higher performance
For Association sql The optimization of the
The associated fields are , Give Way mysq| do join Try to choose NLJ Algorithm
Small tables drive large tables , Write multi table join sq If you know which table is small, you can use it straight join Fixed connection drive mode , Omit mysq| The optimizer's own time
straight join explain : straight join Same function join similar , But let the left watch drive the right watch , It can change the execution order of the table optimizer for the associated table query . such as : select * from t2 straight join t1 on t2.a = t1.a; The representative designates mysql Choose the t2 Table as drive table .
straight join Only applicable to inner join, It doesn't apply to left join, right join.( because left join, right join The execution order of the table has been specified on behalf of )
Let the optimizer judge as much as possible , Because most of the time mysql The optimizer is smarter than people . Use straight join- Be careful , Because in some cases, the artificially specified execution order is not necessarily more reliable than the optimization engine .
The definition of small tables is clear
When deciding which watch to drive , Two tables should be filtered according to their own conditions , After filtering , Calculate participation join The total amount of data in each field of , The table with small amount of data , Namely “ Watch ”, It should be used as a driving table .
in and exsits Optimize
principle : Small tables drive large tables , That is, small datasets drive large datasets
in: When B The data set of the table is less than A When the data set of the table ,in be better than exists
select * from A where id in (select id from B)
# Equivalent to :
for(select id from B){
select from A where A.id = B.id
}exists: When A The data set of the table is less than B When the data set of the table ,exists be better than in, Put the main query A The data of , Put it in subquery B Do conditional verification , According to the verification results (true or false) To determine whether the data of the main query is retained
select * from A where exists (select 1 from B where B.id = A.id)
# Equivalent to :
for(select * from A){
select * from B where B.id = A.id
}
#A Table and B Tabular ID Fields should be indexed EXISTS (subquery) Only return TRUE or FALSE, So in the subquery SELECT * It can also be used. SELECT 1 Replace , The official saying is that the actual implementation will be ignored SELECT detailed list , So there's no difference
EXISTS The actual execution process of the subquery may have been optimized, rather than the item by item comparison in our understanding
EXISTS Subqueries can also JOIN To replace what is the optimal need Specific analysis of specific problems
surface COUNT Query optimization
EXPLAIN select count(1) from employees ;| EXPLAIN select count(id) from employees; EXPLAIN select count(name) from employees ; EXPLAIN select count(*) from employees;
Be careful : above 4 strip sql Only according to a certain field count The statistics field will not be null Data line of value
Why for count(id), mysql Finally, select the secondary index instead of the primary key clustered index ? Because the secondary index stores less data than the primary key index , Retrieval performance should be higher , mysql Inside did Point optimization ( It should be 5.7 The version is optimized ).
four sqI Implementation plan of - sample , Explain these four sq The execution efficiency should be about the same
The field has an index : count(*)≈count(1)>count( Field )>count( Primary key id) // The field has an index , count( Field ) Statistics go through secondary index , Secondary indexes store less data than primary indexes , therefore count( Field )>count( Primary key id)
Field has no index : count(*)≈count(1)>count( Primary key id)>count( Field ) // Field has no index count( Field ) Statistics can't be indexed , count( Primary key id) You can also go through the primary key index , therefore count( Primary key id)>count( Field )
count(1) Follow count( Field ) The execution process is similar to , however count(1) There is no need to take out the field statistics , Just use constants 1 Do statistics , count( Field ) You also need to take out the fields and put them into memory for statistics name The number of , So theoretically count(1) Than count( Field ) Soon - spot .
count(*) It's an exception , mysql It doesn't take all the fields out , It's optimized , No value , Add by line , It's very efficient , So you don't need to use count( Name ) or count( Constant ) To replace count( * )
Common optimization methods
Inquire about mysql The total number of rows maintained by yourself
about myisam The table of the storage engine does not have where Conditions of the count Query performance is very high , because myisam The total number of rows in the table of the storage engine will be mysql Stored on disk , The query does not need to calculate

about innodb The table that stores the engine mysq| The total number of record rows of the table will not be stored ( Because there is MVCC Mechanism , The back can speak ), Inquire about count Real time computing is required
show table status
If you only need to know the total number of rows in the table Estimated value It can be used as follows sql Inquire about , A high performance

Maintain the total to Redis in
When inserting or deleting table data rows, maintain redis The total number of rows in the table key The count of ( use incr or decr command ), But this way may not be right , It is difficult to guarantee table operation and redis The transaction of the operation - Sexual nature
Add database count table
Maintain the count table while inserting or deleting table data rows , Let them operate in the same transaction
Alibaba MYSQL Normative interpretation
Index specifications
[ mandatory ] Fields with unique characteristics on the business , Even the combined fields , We must also build a unique Indexes .
explain : Don't think the only index affects insert Speed , This speed loss can be ignored , But it's obvious to improve the speed of searching ; in addition , Even in the application layer to do a very perfect verification control , As long as there is no unique index , According to Murphy's law , There must be dirty data .
[ mandatory ] More than three tables prohibited join. need join Field of , Data types are absolutely consistent ; When multi table associated query , Ensure that the associated field needs to have an index .
explain : Even if the double meter join Also pay attention to table indexes 、SQL performance .
[ mandatory ] stay varchar When indexing on a field , Index length must be specified , There's no need to index all fields , Determine the index length according to the actual text differentiation .
explain : Indexes | The length and differentiation of are a pair of contradictions , - For string type data , The length is 20 The index of , The distinction will be as high as 90% above , have access to count(distinct left( Name , Index length ))/count( *) To determine .
[ mandatory ] Page search must not be left blurred or full blurred , If you need to go to search engine to solve
explain : Index file has B-Tree The leftmost prefix matching property of , If the value on the left is not determined , Then you can't use this index .
[ recommend ] If there is order by Scene , Note the use of index order .order by The last field is part of the composite index , And put it at the end of the index combination order , Avoid file_ sort The situation of , Affect query performance .
Example : where a=? and b=? order by c; Indexes :a_ b. _C
Counter example : Index if there is range query , Then index order cannot be utilized , Such as : WHERE a> 10 order by b; Indexes a_b nothing Sort by .
[ recommend ] Use overlay index to query , Avoid returning to your watch
explain : If a book needs to know the 11 What is the title of the chapter , Will open the 11 Does the chapter correspond to that page ? Just have a look at the catalogue , this A directory serves as an index overlay .
Example : The types of indexes can be divided into primary key indexes 、 unique index 、 Three kinds of common indexes , And overlay index is just an effect of query fruit , use explain Result , extra Columns appear : using index.
[ recommend ] Use delay association or subquery to optimize the super multi page scenario
explain : MySQL It's not about skipping offset That's ok , It's about taking offset+N That's ok , And then back before giving up offset That's ok , return N That's ok , That's right offset When I was very old , It's very inefficient , Or control the total number of pages returned , Or for the number of pages over a specific threshold SQL rewrite .
Example : First, quickly locate what needs to be acquired id paragraph , And then relate : SELECT a.* FROM surface 1 a, (select id from surface 1 where Conditions LIMIT 100000,20 ) b where a.id=b.id
[ recommend ] SQL Objectives of performance optimization ? At the very least range Level , The requirement is ref Level , If it can be the best .
explain :
consts There is at most one matching row in a single table ( Primary key or unique Indexes ) , Data can be read in the optimization phase .
ref It refers to the use of ordinary indexes ( normal index ).
range Scope index .
Counter example : explain Table results , type=index , Index physical file full scan , Very slow , This index This level is higher than range Still low , With a full scan is a wizard .
[ recommend ] When building a composite index , The highest discrimination is on the left .
Example : If wherea=?a and b=? , a The value of the column is close to the unique value , Then you only need to create one idx_ _a Index is enough .
explain : When there is a mixed judgment condition of non equal sign and equal sign , While indexing , Please precede the equal sign condition . Such as : where c>? and d=? So even C More differentiated , We must also put d At the top of the index , That is to build a composite index idx_ d_ C.
[ recommend ] Prevent implicit conversion due to different field types , Cause index to fail .
[ Reference resources ] Avoid the following extreme misunderstandings when creating indexes :
It is better to have an index than to lack it . Think that a query needs to build an index .
Stingy index creation . Think indexes consume space 、 It slows down the updating of records and the adding speed of rows .
Resist the only Indexes . Think only Indexes - - Laws need to be passed at the application layer " Check first and insert later ” How to solve .
SQL sentence
[ mandatory ] Do not use count( Name ) or count( Constant ) To replace count( * ) , count(*) yes SQL92 The syntax for defining the number of standard statistics lines , It's not about the database , Follow NULL He Fei NULL irrelevant .
explain : count(*) The statistical value is NULL The line of , and count( Name ) This column is not counted NULL Row of values .
[ mandatory ] count(distinct col) Calculation This column is divided by NULL Number of non repeating lines outside Be careful count(distinct col1,col2) If one - All are listed as NULL , So even if the other column has different values , Also returned as 0.
[ mandatory ] When the values of a column are all NULL when , count(col) The return result of is 0 , but sum(col) The return result of is NULL , Therefore use sum() Pay attention to NPE problem .
Example : You can use the following methods to avoid sum Of NPE problem : SELECT IFNULL(SUM(column), 0) FROM table;
[ mandatory ] Use ISNULL() To determine whether it is NULL value .
explain : NULL A direct comparison with any value is NULL.
NULL<> NULL The return result is NULL , instead of false.
NULL=NULL The return result is NULL , instead of true.
NULL<>1 The return result is NULL , instead of true.
Counter example : stay SQL In the sentence , If in null Wrap before , Affect readability .select * from table where column1 is null and column3 is not null; and ISNULL(column) It's a whole , Simple and easy to understand . From the performance data analysis ,ISNULL(column) Faster execution .
[ mandatory ] When writing paging query logic in the code , if count by 0 Should return directly , Avoid executing subsequent paging statements .
[ mandatory ] Do not use foreign keys and cascades , All foreign key concepts must be solved in the application layer .
explain : ( Conceptual explanation ) In the student list student id It's the primary key , So the student_ id Foreign key . If you update the student id , Also trigger the student id to update , That's cascading updates . Foreign key and cascade update are suitable for single machine low concurrency , Not suitable for distributed 、 High concurrency cluster ; Cascading updates are strong blocking , There is a risk of a database update storm ; Foreign keys affect the insertion speed of the database .
[ mandatory ] Stored procedures are not allowed , Stored procedures are difficult to debug and extend , There is no portability .
[ mandatory ] Data revision ( In particular, deleting or modifying records ) when , First select , Avoid false deletion , The update statement can only be executed after confirmation .
[ mandatory ] For queries and changes to table records in the database , As long as multiple tables are involved , You need to add the alias of the table before the column name ( Or watch name ) To limit .
explain : Query records for multiple tables 、 Update record 、 When deleting records , If there is no alias of the qualified table for the operation column ( Or watch name ) , And when the operation column exists in multiple tables , I'm going to throw an exception .
Example : select t1.name from table_ first as t1 , table second as t2 where t1 .id=t2.id;
Counter example : In a business , Because the multi table associated query statement does not add the alias of the table ( Or watch name ) The limitation of , Two years after normal operation , Recently Add a field with the same name to a table , After making database changes in the pre release environment , The online query statement appears 1052 abnormal : Column 'name' in field list is ambiguous.
[ recommend ] SQL Add... Before the alias of the table in the statement as , And take t1、t2、 t3... The order of names is .
explain :
An alias can be the abbreviation of a table , Or according to the order in which the tables appear , With t1. t2、 t3 How to name .
Add... Before the alias as Make aliases easier to identify . Example : select t1.name from table_ first as t1, table_ second as t2 where t1.id=t2.id;
[ recommend ] in Avoid if operation can be avoided , If it can't be avoided , Need to be evaluated carefully in Number of set elements behind , Control in 1000 Within .
in If there are too many or too few elements in the back, you don't have to go to the index
[ Reference resources ] Due to the need of internationalization , All character storage and representation , All adopt utf8 Character set , So the character counting method needs to pay attention to .
explain :
SELECT LENGTH(" Easy work "); Return to 12
SELECT CHARACTER_ LENGTH(" Easy work "); Return to 4.
if necessary Store expressions , So choose utf8mb4 To store , Pay attention to it and utf8 Coding differences .
[ Reference resources ] TRUNCATE TABLE Than DELETE Fast , It also uses less system and transaction log resources , but TRUNCATE No transaction and no trigger trigger , Possible accidents , It is not recommended to use this statement in development code .
explain : TRUNCATE TABLE In function and without WHERE Clause DELETE Same statement .
MYSQL Data type selection analysis
stay MySQL in , Choose the right data type , Critical to performance . Generally, the following two steps should be followed :
Identify the appropriate large type : Numbers 、 character string 、 Time 、 Binary system ;
Determine the specific type : With or without symbols 、 Value range 、 Variable length, fixed length, etc .
stay MySQL Data type setting , Try to use smaller data types , Because they usually have better performance , Spend less hardware resources . also , Try to define the field as NOT NULL, Avoid using NULL.
value type
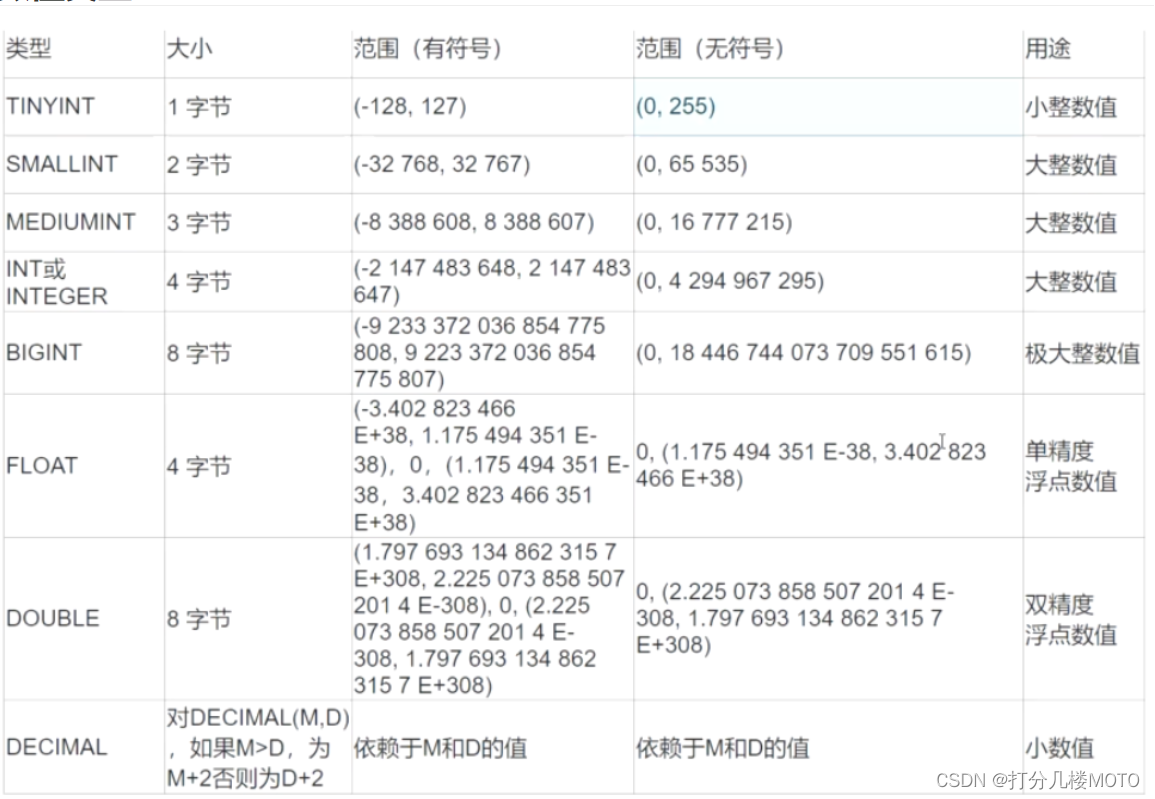
Optimization Suggestions
If the shaping data has no negative number , Such as ID Number , It is suggested that it should be designated as UNSIGNED Unsigned type , Capacity can be expanded - - times .
It is recommended to use TINYINT Instead of ENUM、BITENUM、 SET.
Avoid using integer display widths ( See the end of the document ), in other words , Do not use INT(10) Specify the field display width in a similar way , Direct use INT.
DECIMAL It is most suitable for storage with high accuracy , And the data used for calculation , Like the price . But in use DECIMAL When it comes to type , Note the length setting .
It is recommended to use integer types to operate and store real numbers , The method is , Multiply the real number by the corresponding multiple .
Integers are usually the best data type , Because it's fast , And can use AUTO_ INCREMENT.
Date and time
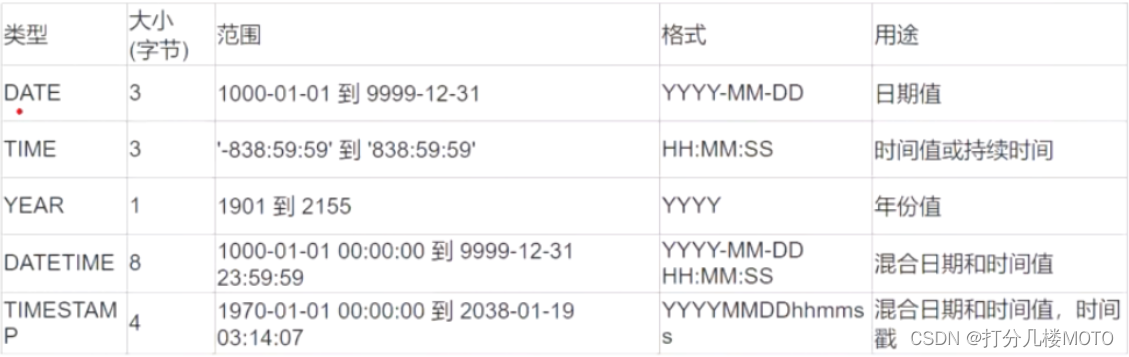
Optimization Suggestions
MySQL The minimum time granularity that can be stored is seconds .
Suggest using DATE Data type to save date .MySQL The default date format in is yyy-mm-dd.
use MySQL Built in type of DATE、TIME、 DATETIME To store time , Instead of using strings .
When the data format is TIMESTAMP and DATETIME when , It can be used CURRENT_TIMES TAMP As default (MySQL5.6 in the future )MySQL It will automatically return the exact time of record insertion
TIMESTAMP yes UTC Time stamp , Related to time zone .|
DATETIME The storage format of is YYYYMMDD HH:MM:SS The integer of , It's not about time zone , What did you save , Just read it out .
Unless there is a special need , General companies recommend using TIMESTAMP, It is better than DATETIME Save more space , But companies like Ali usually use DATETIME, Because you don't have to think about TIMESTAMP Future time , The upper limit problem .
Sometimes people call Unix The timestamp of is saved as an integer value , But it usually doesn't do any good , This format is inconvenient to handle , We don't recommend it .
character string
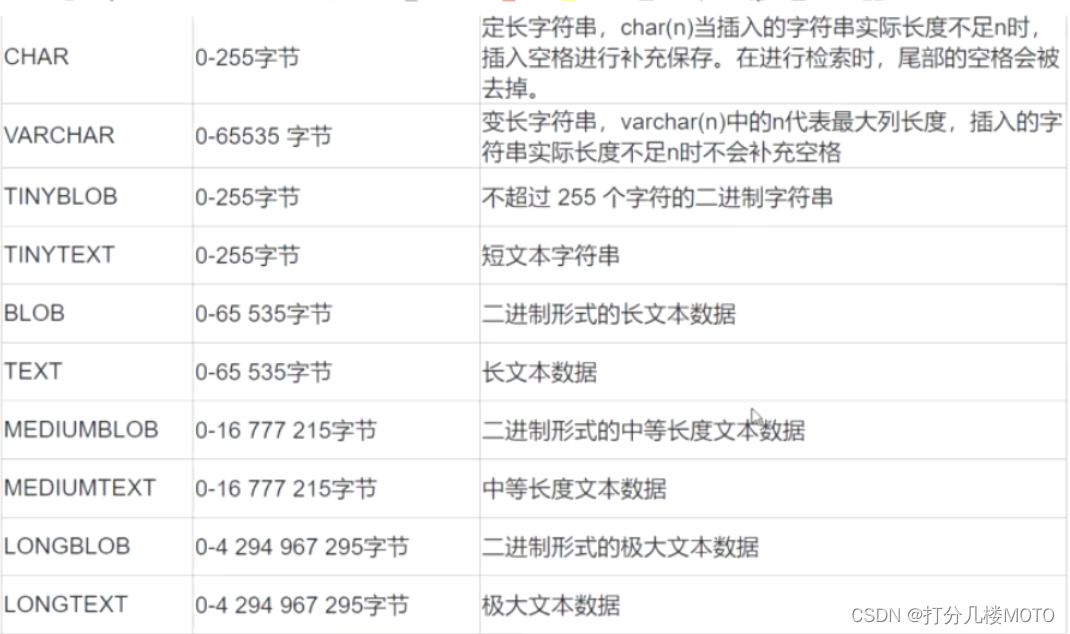
Optimization Suggestions
The length of the string varies greatly. Use VARCHAR; The string is short , And all values are close to a length, using CHAR.
CHAR and VARCHAR Applicable to include person's name 、 Postal Code 、 Telephone number and no more than 255 Any alphanumeric combination of characters . Don't use the numbers you want to calculate VARCHAR class Type save , Because it may lead to some calculation related problems . let me put it another way , May affect the accuracy and completeness of the calculation .
Use less as far as possible BLOB and TEXT, If you really want to use it, you can consider BLOB and TEXT Fields are saved in a separate table , use id relation .
BLOB Series stores binary strings , Character set independent .TEXT Series stores non binary strings , Related to character set .
BLOB and TEXT Can't have default values .
ps:INT Show width
We often use commands to create data tables , And a length will be specified at the same time , as follows . however , The length here is not TINYINT Maximum length of type storage , It's the maximum length displayed .
CREATE TABLE user ( id TINYINT(2) UNSIGNED )
It means user Tabular id The type of field is TINYINT, The maximum value that can be stored is 255. therefore , When storing data , If the stored value is less than or equal to 255, Such as 200, Although more than 2 position , But not beyond TINYINT Type length , So it can be saved normally ; If the stored value is greater than 255, Such as 500, that MySQL Meeting Automatically save as TINYINT Maximum of type 255. When querying data , No matter what the query result is , According to the actual output . here TINYINT(2) in 2 Is that , When you need to fill in before the query results 0 when , Add... To the order ZEROFILL Can be realized , Such as :
id TINYINT(2) UNSIGNED ZEROFILL
such , If the query result is 5, Then the output is 05. If specified TINYINT(5), Then the output is 00005, In fact, the actual stored value is still 5, And the stored data will not exceed 255, It's just MySQL When outputting data, it is filled with 0.
let me put it another way , stay MySQL In command , The type and length of the field TINYINT(2)、INT(11) It will not affect the insertion of data , Only use ZEROFILL Useful when , Let the query result be filled with 0.
边栏推荐
- 2021icpc Shanghai h.life is a game Kruskal reconstruction tree
- Vs extension tool notes
- USB(十五)2022-04-14
- Network security - joint query injection
- 智慧社區和智慧城市之間有什麼异同
- Wechat forum exchange applet system graduation design (3) background function
- Unity3D学习笔记6——GPU实例化(1)
- 聊聊支付流程的设计与实现逻辑
- FreeLink开源呼叫中心设计思想
- Byte hexadecimal binary understanding
猜你喜欢
高级程序员必知必会,一文详解MySQL主从同步原理,推荐收藏

Mysql索引优化实战一
经纬度PLT文件格式说明

Technology at home and abroad people "see" the future of audio and video technology
USB(十五)2022-04-14
Matlab SEIR infectious disease model prediction
PCI-Express接口的PCB布线规则
【微服务|SCG】gateway整合sentinel

Explain

Wechat forum exchange applet system graduation design completion (1) development outline
随机推荐
Network security - joint query injection
Dynamic agent explanation (July 16, 2020)
Wechat forum exchange applet system graduation design completion (7) Interim inspection report
二叉树(Binary Tree)
Byte hexadecimal binary understanding
leetcode-520. Detect capital letters -js
leetcode-520. 检测大写字母-js
Experience sharing of system architecture designers in preparing for the exam: the direction of paper writing
Network security -beef
Solve the problem of duplicate request resource paths /o2o/shopadmin/o2o/shopadmin/getproductbyid
Gee (III): calculate the correlation coefficient between two bands and the corresponding p value
LDO voltage stabilizing chip - internal block diagram and selection parameters
VS扩展工具笔记
谷歌浏览器怎么登录及开启同步功能
Gee (IV): calculate the correlation between two variables (images) and draw a scatter diagram
v-for遍历对象
网络安全-联合查询注入
聊聊支付流程的设计与实现逻辑
PMP project management exam pass Formula-1
USB (十七)2022-04-15