当前位置:网站首页>mysql进阶(二十七)数据库索引原理
mysql进阶(二十七)数据库索引原理
2022-08-05 09:14:00 【InfoQ】
一、前言
MySQLInnodbMySQLMySQLInnoDBMySQL二、数据结构及算法理论
InnodbB+B+2.1 B+树
B+B+Balance
InnodbPage DirectoryPage Directory2.2 二叉查找树
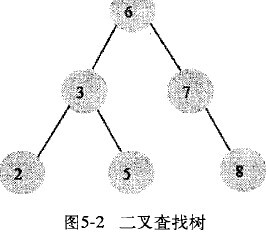
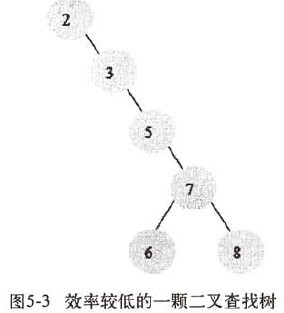
2.3 AVL树
2.4 B+树的特性
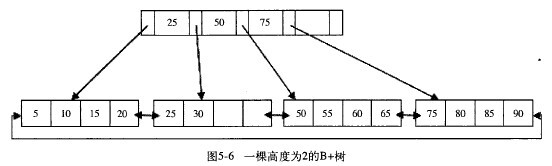
B+
B+三、聚集索引、非聚集索引
3.1 聚集索引
3.2 非聚集索引
InnoDBInnoDBInnoDB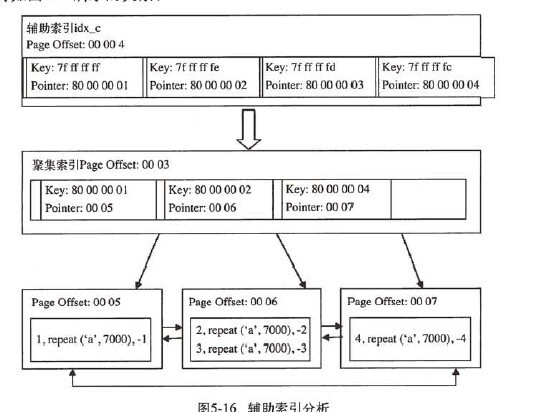
边栏推荐
猜你喜欢

随机推荐
CVPR 2022 | 将X光图片用于垃圾分割,港中大(深圳)探索大规模智能垃圾分类
使用稀疏 4D 卷积对 3D LiDAR 数据中的运动对象进行后退分割(IROS 2022)
21 Days of Deep Learning - Convolutional Neural Networks (CNN): Clothing Image Classification (Day 3)
无题十三
汇编语言(8)x86内联汇编
The Secrets of the Six-Year Team Leader | The Eight Most Important Soft Skills of Programmers
放大器OPA855的噪声计算实例
施一公:科学需要想象,想象来自阅读
seata源码解析:TM RM 客户端的初始化过程
ECCV 2022 Oral Video Instance Segmentation New SOTA: SeqFormer & IDOL and CVPR 2022 Video Instance Segmentation Competition Champion Scheme...
DPU — 功能特性 — 存储系统的硬件卸载
express hot-reload
代码审计—PHP
只有一台交换机,如何实现主从自动切换之nqa
在colab里怎样读取google drive数据
基因数据平台
动态内存开辟(C语言)
嵌入式实操----基于RT1170 移植memtester做SDRAM测试(二十五)
Comprehensively explain what is the essential difference between GET and POST requests?Turns out I always misunderstood
轩辕实验室丨欧盟EVITA项目预研 第一章(四)