当前位置:网站首页>ECCV 2022 | 腾讯优图提出DisCo:拯救小模型在自监督学习中的效果
ECCV 2022 | 腾讯优图提出DisCo:拯救小模型在自监督学习中的效果
2022-07-04 22:59:00 【智源社区】

DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning
论文:https://arxiv.org/abs/2104.09124代码(已开源):https://github.com/Yuting-Gao/DisCo-pytorch
Motivation
自监督学习通常指的模型在大规模无标注数据上学习通用的表征,迁移到下游相关任务。因为学习到的通用表征能显著提升下游任务的性能,自监督学习被广泛用于各种场景。通常来讲,模型容量越大,自监督学习的效果越好 [1,2]。反之,轻量化的模型(EfficientNet-B0, MobileNet-V3, EfficientNet-B1) 在自监督学习上效果就远不如容量相对大的模型 (ResNet50/101/152/50*2)。
目前提升轻量化模型在自监督学习上性能的做法主要是通过蒸馏的方式,将容量更大的模型的知识迁移给学生模型。SEED [2]基于MoCo-V2框架 [3,4],容量大的模型作为Teacher,轻量化模型作为Student,共享MoCo-V2框架中负样本空间(Queue),通过交叉熵迫使正样本与相同的负样本在Student与Teacher空间中的分布尽可能相同。CompRess [1]还尝试了Teacher和Student维护各自的负样本空间,同时使用KL散度来拉近分布。以上方法可以有效的将Teacher的知识迁移给Student,从而提升轻量化模型Student的效果(本文会交替使用Student与轻量化模型)。
本文提出了 Distilled Contrastive Learning (DisCo),一种简单有效的基于蒸馏的轻量化模型的自监督学习方法,该方法可以显著提升Student的效果并且部分轻量化模型可以非常接近Teacher的性能。该方法有以下几个观察:
- 基于自监督的蒸馏学习,因为最后一层的表征包含了不同样本的在整个表征空间中的全局的绝对位置和局部的相对位置信息,而Teacher中的这类信息比Student更加的好,所以直接拉近Teacher与Student最后一层的表征可能是效果最好。
- 在CompRess [1] 中,Teacher 与 Student 模型共享负样本队列(1q) 与拥有各自负样本队列(2q) 差距在1%内。该方法迁移到下游任务数据集CUB200, Car192,该方法拥有各自的负样本队列甚至可以显著超过共享负样本队列。这说明,Student并没有从Teacher共享的负样本空间学习中获得足够有效的知识。Student不需要依赖来自Teacher的负样本空间。
- 放弃共享队列的好处之一,是整个框架不依赖于MoCo-V2,整个框架更加简洁。Teacher/Student 模型可以与其他比MoCo-V2更加有效的自监督/无监督表征学习方法结合,进一步提升轻量化模型蒸馏完的最终性能。
目前的自监督方法中,MLP的隐藏层维度较低可能是蒸馏性能的瓶颈。在自监督学习与蒸馏阶段增加这个结构的隐藏层的维度可以进一步提升蒸馏之后最终轻量化模型的效果,而部署阶段不会有任何额外的开销。将隐藏层维度从512->2048,ResNet-18可以显著提升3.5%。
Method
本文提出一个简单却很有效的框架 Distilled Contrastive Learning (DisCo) 。Student 会同时进行自监督学习和学习相同的样本在Teacher的表征空间中分布。

DisCo的框架
如上图所示,通过数据增广 (Data Augmentation) 操作将图像生成为两个视图 (View)。除了自监督学习,还引入一个自监督学习获得的Teacher模型。要求相同样本的相同视图,经过Student和固定参数的Teacehr的最终表征保持一致。在本文的主要实验中,自监督学习基于MoCo-V2 (Contrastive Learning),而保持相同样本通过Teacher与Student的输出表征的表征相似是通过一致性正则化(Consistency Regularization)。本文采用均方误差来使Student学习到样本在对应Teacher空间中的分布。
边栏推荐
- Qt加法计算器(简单案例)
- Duplicate ADMAS part name
- 【图论】拓扑排序
- Redis入门完整教程:发布订阅
- Pagoda 7.9.2 pagoda control panel bypasses mobile phone binding authentication bypasses official authentication
- Redis introduction complete tutorial: slow query analysis
- Redis: redis transactions
- Redis入门完整教程:列表讲解
- The initial arrangement of particles in SPH (solved by two pictures)
- 法国学者:最优传输理论下对抗攻击可解释性探讨
猜你喜欢
一次edu证书站的挖掘
![P2181 diagonal and p1030 [noip2001 popularization group] arrange in order](/img/79/36c46421bce08284838f68f11cda29.png)
P2181 diagonal and p1030 [noip2001 popularization group] arrange in order
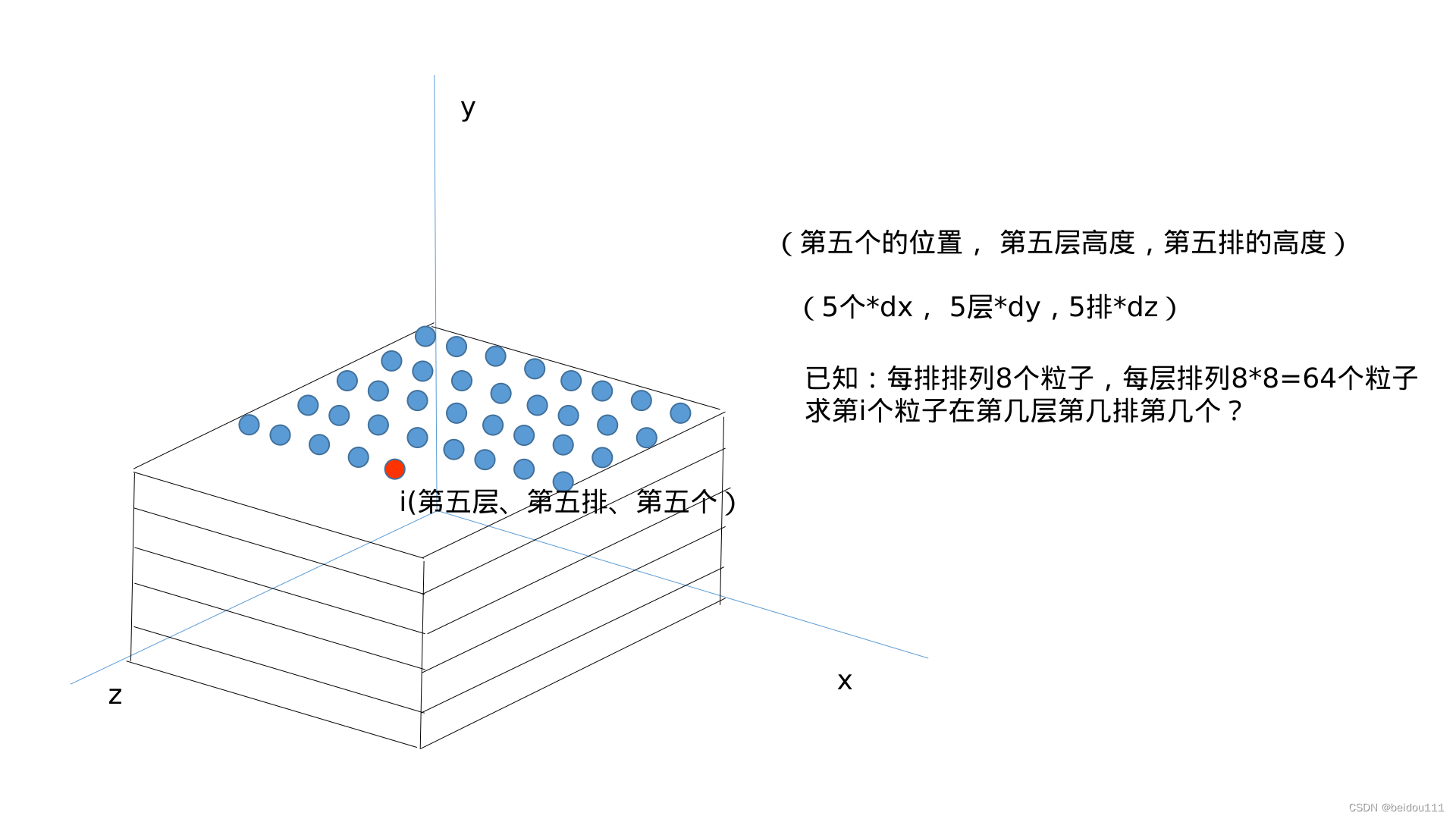
The initial arrangement of particles in SPH (solved by two pictures)

Redis introduction complete tutorial: slow query analysis
Talk about Middleware
字体设计符号组合多功能微信小程序源码

法国学者:最优传输理论下对抗攻击可解释性探讨
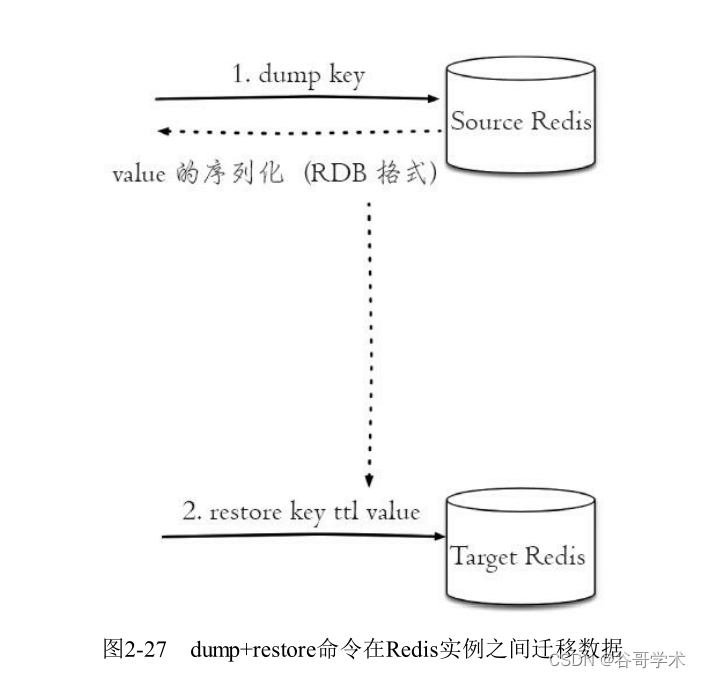
Redis入门完整教程:键管理
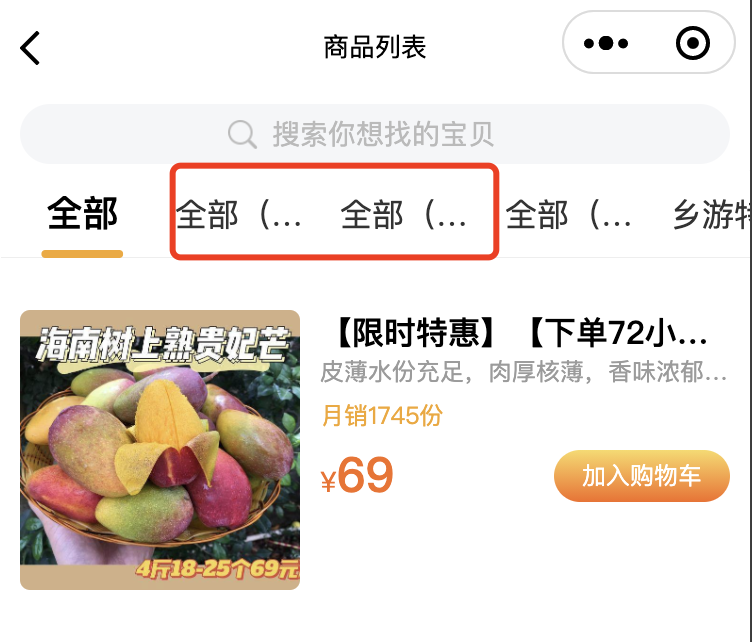
The small program vant tab component solves the problem of too much text and incomplete display
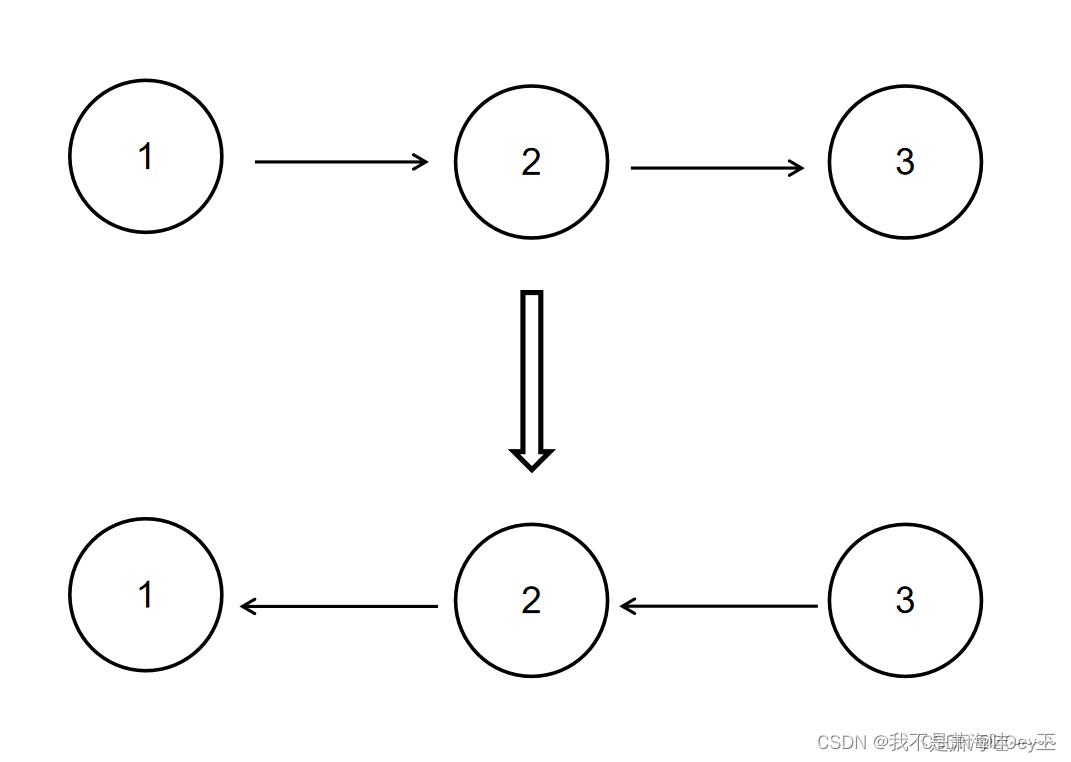
C语言快速解决反转链表
随机推荐
A complete tutorial for getting started with redis: understanding and using APIs
Redis入门完整教程:HyperLogLog
[graph theory] topological sorting
Excel shortcut keys - always add
C语言快速解决反转链表
初试为锐捷交换机跨设备型号升级版本(以RG-S2952G-E为例)
Redis: redis message publishing and subscription (understand)
EditPlus--用法--快捷键/配置/背景色/字体大小
【js】-【动态规划】-笔记
How can enterprises cross the digital divide? In cloud native 2.0
UML图记忆技巧
Redis: redis transactions
Redis入门完整教程:键管理
Redis入门完整教程:事务与Lua
【js】-【排序-相关】-笔记
ScriptableObject
Talk about Middleware
Observable time series data downsampling practice in Prometheus
CTF竞赛题解之stm32逆向入门
List related knowledge points to be sorted out