当前位置:网站首页>使用 Dumpling 备份 TiDB 集群数据到兼容 S3 的存储
使用 Dumpling 备份 TiDB 集群数据到兼容 S3 的存储
2022-07-06 07:58:00 【添香小铺】
本文档介绍如何将 Kubernetes 上 TiDB 集群的数据备份到兼容 S3 的存储上。本文档中的“备份”,均是指全量备份(即 Ad-hoc 全量备份和定时全量备份)。
本文档介绍的备份方法基于 TiDB Operator(v1.1 及以上)的 CustomResourceDefinition (CRD) 实现,底层使用 Dumpling 工具获取集群的逻辑备份,然后在将备份数据上传到兼容 S3 的存储上。
Dumpling 是一款数据导出工具,该工具可以把存储在 TiDB/MySQL 中的数据导出为 SQL 或者 CSV 格式,可以用于完成逻辑上的全量备份或者导出。
使用场景
如果你需要将 TiDB 集群数据以 Ad-hoc 全量备份或定时全量备份的方式备份至兼容 S3 的存储上,并且对数据备份有以下要求,可考虑本文介绍的备份方案:
- 导出 SQL 或 CSV 格式的数据
- 对单条 SQL 语句的内存进行限制
- 导出 TiDB 的历史数据快照
Ad-hoc 全量备份
Ad-hoc 全量备份通过创建一个自定义的 Backup custom resource (CR) 对象来描述一次备份。TiDB Operator 根据这个 Backup 对象来完成具体的备份过程。如果备份过程中出现错误,程序不会自动重试,此时需要手动处理。
目前兼容 S3 的存储中,Ceph 和 Amazon S3 经测试可正常工作。下文提供了如何将 TiDB 集群的数据备份到 Ceph 和 Amazon S3 这两种存储的示例。示例假设对部署在 Kubernetes tidb-cluster 这个 namespace 中的 TiDB 集群 demo1 进行数据备份,以下是具体的操作过程。
前置条件
使用 Dumpling 备份 TiDB 集群数据到 S3 前,确保你拥有备份数据库的以下权限:
mysql.tidb表的SELECT和UPDATE权限:备份前后,Backup CR 需要一个拥有该权限的数据库账户,用于调整 GC 时间。- 全局权限:
SELECT、RELOAD、LOCK TABLES、和REPLICATION CLIENT。
以下是如何创建一个备份用户的示例:
CREATE USER 'backup'@'%' IDENTIFIED BY '...'; GRANT SELECT, RELOAD, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'backup'@'%'; GRANT UPDATE, SELECT ON mysql.tidb TO 'backup'@'%';
第 1 步:Ad-hoc 全量备份环境准备
执行以下命令,根据 backup-rbac.yaml 在
tidb-cluster命名空间创建基于角色的访问控制 (RBAC) 资源。kubectl apply -f https://raw.githubusercontent.com/pingcap/tidb-operator/v1.3.6/manifests/backup/backup-rbac.yaml -n tidb-cluster远程存储访问授权。
如果使用 Amazon S3 来备份集群,可以使用三种权限授予方式授予权限,参考 AWS 账号授权授权访问兼容 S3 的远程存储;使用 Ceph 作为后端存储测试备份时,是通过 AccessKey 和 SecretKey 模式授权,设置方式可参考通过 AccessKey 和 SecretKey 授权。
创建
backup-demo1-tidb-secretsecret。该 secret 存放用于访问 TiDB 集群的 root 账号和密钥。kubectl create secret generic backup-demo1-tidb-secret --from-literal=password=${password} --namespace=tidb-cluster
第 2 步:备份数据到兼容 S3 的存储
注意
由于
rclone存在问题,如果使用 Amazon S3 存储备份,并且 Amazon S3 开启了AWS-KMS加密,需要在本节示例中的 yaml 文件里添加如下spec.s3.options配置以保证备份成功:spec: ... s3: ... options: - --ignore-checksum
本节提供了存储访问的多种方法。只需使用符合你情况的方法即可。
- 通过导入 AccessKey 和 SecretKey 备份到 Amazon S3 的方法
- 通过导入 AccessKey 和 SecretKey 备份到 Ceph 的方法
- 通过绑定 IAM 与 Pod 的方式备份到 Amazon S3 的方法
- 通过绑定 IAM 与 ServiceAccount 的方式备份到 Amazon S3 的方法
方法 1:创建
BackupCR,通过 AccessKey 和 SecretKey 授权的方式将数据备份到 Amazon S3。kubectl apply -f backup-s3.yamlbackup-s3.yaml文件内容如下:--- apiVersion: pingcap.com/v1alpha1 kind: Backup metadata: name: demo1-backup-s3 namespace: tidb-cluster spec: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws secretName: s3-secret region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10Gi方法 2:创建
BackupCR,通过 AccessKey 和 SecretKey 授权的方式将数据备份到 Ceph。kubectl apply -f backup-s3.yamlbackup-s3.yaml文件内容如下:--- apiVersion: pingcap.com/v1alpha1 kind: Backup metadata: name: demo1-backup-s3 namespace: tidb-cluster spec: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: ceph secretName: s3-secret endpoint: ${endpoint} # prefix: ${prefix} bucket: ${bucket} # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10Gi方法 3:创建
BackupCR,通过 IAM 绑定 Pod 授权的方式将数据备份到 Amazon S3。kubectl apply -f backup-s3.yamlbackup-s3.yaml文件内容如下:--- apiVersion: pingcap.com/v1alpha1 kind: Backup metadata: name: demo1-backup-s3 namespace: tidb-cluster annotations: iam.amazonaws.com/role: arn:aws:iam::123456789012:role/user spec: backupType: full from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10Gi方法 4:创建
BackupCR,通过 IAM 绑定 ServiceAccount 授权的方式将数据备份到 Amazon S3。kubectl apply -f backup-s3.yamlbackup-s3.yaml文件内容如下:--- apiVersion: pingcap.com/v1alpha1 kind: Backup metadata: name: demo1-backup-s3 namespace: tidb-cluster spec: backupType: full serviceAccount: tidb-backup-manager from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10Gi
上述示例将 TiDB 集群的数据全量导出备份到 Amazon S3 和 Ceph 上。Amazon S3 的 acl、endpoint、storageClass 配置项均可以省略。其余非 Amazon S3 的但是兼容 S3 的存储均可使用和 Amazon S3 类似的配置。可参考上面例子中 Ceph 的配置,省略不需要配置的字段。更多兼容 S3 的存储相关配置参考 S3 存储字段介绍。
以上示例中,.spec.dumpling 表示 Dumpling 相关的配置,可以在 options 字段指定 Dumpling 的运行参数,详情见 Dumpling 使用文档;默认情况下该字段可以不用配置。当不指定 Dumpling 的配置时,options 字段的默认值如下:
options: - --threads=16 - --rows=10000
更多 Backup CR 字段的详细解释参考 Backup CR 字段介绍。
创建好 Backup CR 后,可通过如下命令查看备份状态:
kubectl get bk -n tidb-cluster -owide
要获取一个 Backup job 的详细信息,请使用以下命令。对于此命令中的 $backup_job_name,请使用上一条命令输出中的名称。
kubectl describe bk -n tidb-cluster $backup_job_name
如果要再次运行 Ad-hoc 备份,你需要删除备份的 Backup CR 并重新创建。
定时全量备份
用户通过设置备份策略来对 TiDB 集群进行定时备份,同时设置备份的保留策略以避免产生过多的备份。定时全量备份通过自定义的 BackupSchedule CR 对象来描述。每到备份时间点会触发一次全量备份,定时全量备份底层通过 Ad-hoc 全量备份来实现。下面是创建定时全量备份的具体步骤:
第 1 步:定时全量备份环境准备
第 2 步:定时全量备份数据到 S3 兼容存储
注意
由于 rclone 存在问题,如果使用 Amazon S3 存储备份,并且 Amazon S3 开启了 AWS-KMS 加密,需要在本节示例中的 yaml 文件里添加如下 spec.backupTemplate.s3.options 配置以保证备份成功:
spec: ... backupTemplate: ... s3: ... options: - --ignore-checksum
方法 1:创建
BackupScheduleCR 开启 TiDB 集群的定时全量备份,通过 AccessKey 和 SecretKey 授权的方式将数据备份到 Amazon S3:kubectl apply -f backup-schedule-s3.yamlbackup-schedule-s3.yaml文件内容如下:--- apiVersion: pingcap.com/v1alpha1 kind: BackupSchedule metadata: name: demo1-backup-schedule-s3 namespace: tidb-cluster spec: #maxBackups: 5 #pause: true maxReservedTime: "3h" schedule: "*/2 * * * *" backupTemplate: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws secretName: s3-secret region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10Gi方法 2:创建
BackupScheduleCR 开启 TiDB 集群的定时全量备份,通过 AccessKey 和 SecretKey 授权的方式将数据备份到 Ceph:kubectl apply -f backup-schedule-s3.yamlbackup-schedule-s3.yaml文件内容如下:--- apiVersion: pingcap.com/v1alpha1 kind: BackupSchedule metadata: name: demo1-backup-schedule-ceph namespace: tidb-cluster spec: #maxBackups: 5 #pause: true maxReservedTime: "3h" schedule: "*/2 * * * *" backupTemplate: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: ceph secretName: s3-secret endpoint: ${endpoint} bucket: ${bucket} # prefix: ${prefix} # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10Gi方法 3:创建
BackupScheduleCR 开启 TiDB 集群的定时全量备份,通过 IAM 绑定 Pod 授权的方式将数据备份到 Amazon S3:kubectl apply -f backup-schedule-s3.yamlbackup-schedule-s3.yaml文件内容如下:--- apiVersion: pingcap.com/v1alpha1 kind: BackupSchedule metadata: name: demo1-backup-schedule-s3 namespace: tidb-cluster annotations: iam.amazonaws.com/role: arn:aws:iam::123456789012:role/user spec: #maxBackups: 5 #pause: true maxReservedTime: "3h" schedule: "*/2 * * * *" backupTemplate: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10Gi方法 4:创建
BackupScheduleCR 开启 TiDB 集群的定时全量备份,通过 IAM 绑定 ServiceAccount 授权的方式将数据备份到 Amazon S3:kubectl apply -f backup-schedule-s3.yamlbackup-schedule-s3.yaml文件内容如下:--- apiVersion: pingcap.com/v1alpha1 kind: BackupSchedule metadata: name: demo1-backup-schedule-s3 namespace: tidb-cluster spec: #maxBackups: 5 #pause: true maxReservedTime: "3h" schedule: "*/2 * * * *" serviceAccount: tidb-backup-manager backupTemplate: from: host: ${tidb_host} port: ${tidb_port} user: ${tidb_user} secretName: backup-demo1-tidb-secret s3: provider: aws region: ${region} bucket: ${bucket} # prefix: ${prefix} # storageClass: STANDARD_IA # acl: private # endpoint: # dumpling: # options: # - --threads=16 # - --rows=10000 # tableFilter: # - "test.*" # storageClassName: local-storage storageSize: 10Gi
定时全量备份创建完成后,可以通过以下命令查看定时全量备份的状态:
kubectl get bks -n tidb-cluster -owide
查看定时全量备份下面所有的备份条目:
kubectl get bk -l tidb.pingcap.com/backup-schedule=demo1-backup-schedule-s3 -n tidb-cluster
从以上示例可知,backupSchedule 的配置由两部分组成。一部分是 backupSchedule 独有的配置,另一部分是 backupTemplate。backupTemplate 指定集群及远程存储相关的配置,字段和 Backup CR 中的 spec 一样,详细介绍可参考 Backup CR 字段介绍。backupSchedule 独有配置项介绍可参考 BackupSchedule CR 字段介绍。
注意
TiDB Operator 会创建一个 PVC,这个 PVC 同时用于 Ad-hoc 全量备份和定时全量备份,备份数据会先存储到 PV,然后再上传到远端存储。如果备份完成后想要删掉这个 PVC,可以参考删除资源先把备份 Pod 删掉,然后再把 PVC 删掉。
假如备份并上传到远端存储成功,TiDB Operator 会自动删除本地的备份文件。如果上传失败,则本地备份文件将被保留。
删除备份的 Backup CR
备份完成后,你可能需要删除备份的 Backup CR。删除方法可参考删除备份的 Backup CR。
边栏推荐
- Get the path of edge browser
- Position() function in XPath uses
- Qualitative risk analysis of Oracle project management system
- http缓存,强制缓存,协商缓存
- [redis] Introduction to NoSQL database and redis
- datax自检报错 /datax/plugin/reader/._drdsreader/plugin.json]不存在
- How to estimate the number of threads
- Nft智能合约发行,盲盒,公开发售技术实战--拼图篇
- CAD ARX gets the current viewport settings
- [KMP] template
猜你喜欢
![[count] [combined number] value series](/img/f5/6fadb8f1c8b75ddf5994c2c43feaa6.jpg)
[count] [combined number] value series
Apache middleware vulnerability recurrence
wincc7.5下载安装教程(Win10系统)
861. Score after flipping the matrix

In the era of digital economy, how to ensure security?
Key value judgment in the cycle of TS type gymnastics, as keyword use
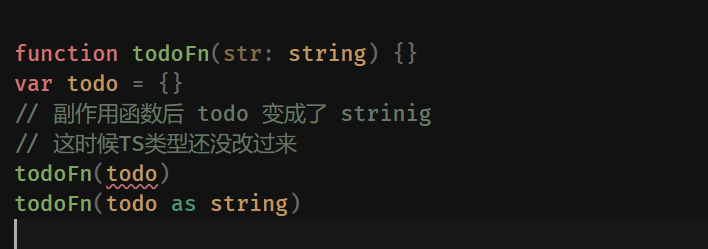
成为优秀的TS体操高手 之 TS 类型体操前置知识储备

珠海金山面试复盘

Opencv learning notes 8 -- answer sheet recognition
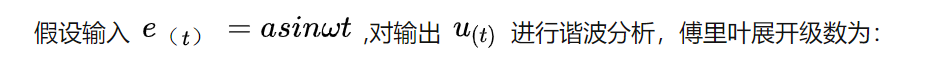
Parameter self-tuning of relay feedback PID controller
随机推荐
数据治理:主数据的3特征、4超越和3二八原则
MES, APS and ERP are essential to realize fine production
Pangolin Library: control panel, control components, shortcut key settings
Common functions for PHP to process strings
好用的TCP-UDP_debug工具下载和使用
Luogu p4127 [ahoi2009] similar distribution problem solution
二叉树创建 & 遍历
49. Sound card driven article collection
edge瀏覽器 路徑獲得
"Designer universe" APEC design +: the list of winners of the Paris Design Award in France was recently announced. The winners of "Changsha world center Damei mansion" were awarded by the national eco
[1. Delphi foundation] 1 Introduction to Delphi Programming
Le chemin du navigateur Edge obtient
数据治理:误区梳理篇
珠海金山面试复盘
Learn Arduino with examples
(lightoj - 1410) consistent verbs (thinking)
Notes on software development
MFC 给列表控件发送左键单击、双击、以及右键单击消息
Flash return file download
Artcube information of "designer universe": Guangzhou implements the community designer system to achieve "great improvement" of urban quality | national economic and Information Center