当前位置:网站首页>A Closer Look at How Fine-tuning Changes BERT
A Closer Look at How Fine-tuning Changes BERT
2022-07-06 07:48:00 【be_humble】
A Closer Look at How Fine-tuning Changes BERT
ACL 2022, 作者来自每个Utah University
论文链接:[2102.12452] Probing Classifiers: Promises, Shortcomings, and Advances (arxiv.org)
看完题目觉得应该是使用可解释方法对比fine-tune前后的bert模型针对目标任务数据的效果情况分析,有可能会有一些理论分析,证明之类的。
Abstract
首先整体说到近年pretrain模型大火,一般都是在下游任务中fine-tune,表现更好,作者推理fine-tune增加了不同label数据representation的距离,然后设置5组实验证明,同时发现不是所有fine-tune都会让模型效果更好,最后提到fine-tune后的representation仍会保留原始空间结构。
看来我想多了,连可解释方法的对比都没有用,就是简单说不同label向量距离远了,这一看,不是废话,原来pretrain的模型直接在下游任务表现没有fine-tune好,模型应用都是representation后面接一个fc层softmax进行分类,当然fine-tune上不同label距离远了。然后一会看看例外情况是怎样的和作者如何是设置实验来比较两种空间结构的。
1. Introduction
首先介绍Bert论文,然后对fine-tune使用相关工作进行介绍,最后提出自己motivation:fine-tuning如何改变representation和为什么有效,提出了3个问题
- fine-tuning是否一直有效
- fine-tuning如何调整representation
- fine-tuning在bert不同laryers上改变程度如何
使用两种probing方法:
- 基于分类的probe
- Direct Probe
在5类不同任务(POS,依赖头预测,指代消歧,功能预测,文本分类)
结论如下:
fine-tune在train和test的分歧,一般对结果影响不大
fine-tune将representation不同label距离增加,不同label的cluster距离增加
fine-tune只是轻微改变了高层,representation保留了标签簇相对位置。
2. Preliminaries: Probing Methods
本文主要针对representation分析,下面主要介绍一下分析方法,探针方法
Classifier as Probes
简单来说,就是一个分类器,输入是我们bert模型顶层的embedding representation,输出就是分类结果,通过freeze embedding,仅训练分类器,然后对比实验结果,这里分类器使用两次fc,后面接relu激活等一些超参数设置
DirectProbe: Probing the Geometric Structure
由于直接用分类器探针无法体现representation的表现,使用类似聚类方法,按照embedding得到不同簇,计算簇之间距离,簇数目与label数目比较,通过计算簇间距离表示的Person系数来体现的空间相似度。来展示fine-tune前后representation的差异性。
探针方法,一个接分类器,一个聚类,用簇间聚类表示,都是很简单的方法,自认为这样得到结果,说明fine-tune对向量表现优化不够充分。
3. 实验设置
3.1 representations
使用bert模型不同层,不同hidden_size的向量表示,其中模型针对英文文本,不区分大小写(uncased),分词方式使用subwords,使用平均池化方式表示token representation,代码使用huggingface代码。
3.2 Tasks
针对bert常见任务,覆盖语法语义任务
POS 词形标注
DEP 依存句法分析
PS-role 指代消歧
Text -Classification 文本分类,使用CLS作为句子表示
3.3 微调设置
10个epoch,并且指出fine-tune和训练分类器探针两阶段训练过程,这不废话吗,,
4. 实验结果分析
4.1 fine-tune表现
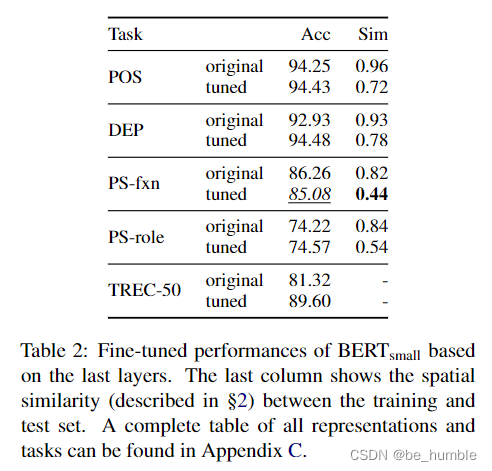
实验表明fine-tune使得训练集和测试集发散,并且发现在Bert-small模型下的PS-fxn任务fine-tune后效果更差,但是主要原因是训练集和测试集相似度较低,然后也没有查出具体原因(我觉得这不就废话吗,你fine-tune数据和测试数据差异很大,那fine-tune不仅往错误方向进行了吗,效果差是很有可能的,而且类似clip等模型fine-tune后效果差的也有许多呢)
4.2 向量表示的线性
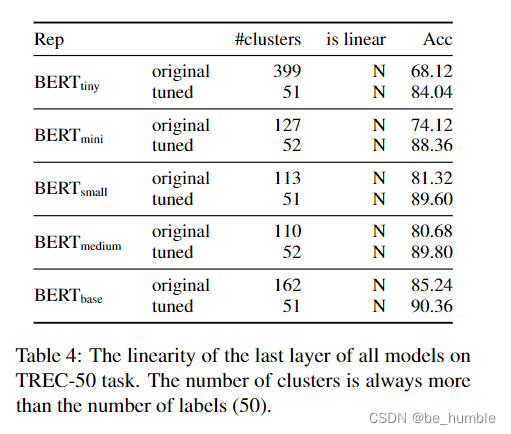
如结果图,表现了fine-tune后聚类簇数目降低,线性增强。微调使原来复杂的空间表示变得简单,微调后向量簇有目的向label汇聚移动。
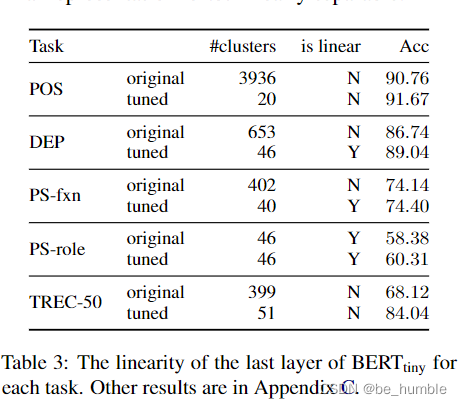
4.3 标签的空间结构
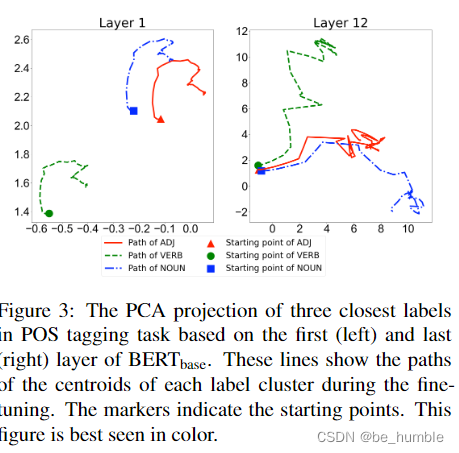
上图是bert-base在顶层和底层向量表示的PCA降维结果图,表明fine-tune可以使不同label簇之间增大距离(这fine-tune效果增加,向量表示距离增加不是明显的事情吗)
4.4 跨任务fine-tune
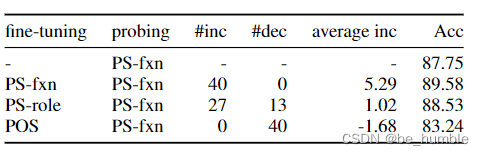
作者又考虑既然fine-tune一个task会增大对应label的距离,那么对其他task的label距离应该会相应缩小,通过上图实验查看效果,不同task任务进行fine-tune,然后再PS-fxn探针进行测试结果,结果显示任务相似度高的fine-tune有可能会再cross-task fine-tune效果表现好,相关度低的task进行fine-tune反而会降低效果。(这一部分的实验感觉也是显而易见的)
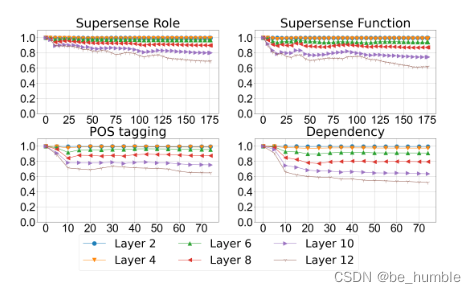
最后进行不同层向量表示的person系数,证明fine-tune几乎不会修改预训练模型的信息表示,high layer的改变很微小。
总结
总结一下本文,主要为了描述fine-tune为什么效果好,并且再向量表示上进行对比分析,最后分析fine-tune对bert不同层向量表示影响效果。使用方法探针(基于表示向量然后进行分类和聚类),实验思路很简单,证明的内容也是我们认为理所当然的结果,但文章叙述很好,实验充分,工作量足够,认为虽然看了之后没有什么方法上的借鉴价值,但是这种证明理所当然的事情,有时也是有必要的。
使用方法探针(基于表示向量然后进行分类和聚类),实验思路很简单,证明的内容也是我们认为理所当然的结果,但文章叙述很好,实验充分,工作量足够,认为虽然看了之后没有什么方法上的借鉴价值,但是这种证明理所当然的事情,有时也是有必要的。
最近假期回家办公,每天经常打篮球,健身,学习的时间减少了许多,更的较慢,最近一定加油。
边栏推荐
- TS类型体操 之 字符串的妙用
- Compliance and efficiency, accelerate the digital transformation of pharmaceutical enterprises, and create a new document resource center for pharmaceutical enterprises
- jmeter性能测试步骤实战教程
- P3047 [USACO12FEB]Nearby Cows G(树形dp)
- ROS learning (IX): referencing custom message types in header files
- Data governance: data quality
- [非线性控制理论]9_非线性控制理论串讲
- When the Jericho development board is powered on, you can open the NRF app with your mobile phone [article]
- leecode-C語言實現-15. 三數之和------思路待改進版
- [CF Gym101196-I] Waif Until Dark 网络最大流
猜你喜欢
Summary of Digital IC design written examination questions (I)
数据治理:主数据的3特征、4超越和3二八原则
Sharing of source code anti disclosure scheme under burning scenario
861. Score after flipping the matrix
Do you really think binary search is easy
解决方案:智慧工地智能巡检方案视频监控系统
Pre knowledge reserve of TS type gymnastics to become an excellent TS gymnastics master
Codeforces Global Round 19(A~D)
leecode-C語言實現-15. 三數之和------思路待改進版
Comparison of usage scenarios and implementations of extensions, equal, and like in TS type Gymnastics

随机推荐
Fundamentals of C language 9: Functions
When the Jericho development board is powered on, you can open the NRF app with your mobile phone [article]
Redis list detailed explanation of character types yyds dry goods inventory
JMeter performance test steps practical tutorial
leecode-C語言實現-15. 三數之和------思路待改進版
Force buckle day31
If Jerry needs to send a large package, he needs to modify the MTU on the mobile terminal [article]
What are the ways to download network pictures with PHP
[MySQL learning notes 29] trigger
Document 2 Feb 12 16:54
Summary of Digital IC design written examination questions (I)
HTTP cache, forced cache, negotiated cache
esRally国内安装使用避坑指南-全网最新
P3047 [USACO12FEB]Nearby Cows G(树形dp)
链表面试题(图文详解)
[MySQL learning notes 30] lock (non tutorial)
Ble of Jerry [chapter]
shu mei pai
C # display the list control, select the file to obtain the file path and filter the file extension, and RichTextBox displays the data
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower