当前位置:网站首页>The first TOF related data set available for deep learning: deep learning for confidence information in stereo and TOF data fusion (iccv 2017)
The first TOF related data set available for deep learning: deep learning for confidence information in stereo and TOF data fusion (iccv 2017)
2022-06-11 09:36:00 【F_ L_ O_ W】
List of articles
summary
Title of thesis : Deep Learning for Confidence Information in Stereo and ToF Data Fusion
Cited : 29
Thesis link : https://openaccess.thecvf.com/content_ICCV_2017_workshops/papers/w13/Agresti_Deep_Learning_for_ICCV_2017_paper.pdf
Data links : https://lttm.dei.unipd.it//paper_data/deepfusion/
Author's unit : University of Padua, Italy
Journal or conference : ICCV 2017
This article presents a method for stereo camera and ToF Camera depth map fusion framework . The key is to get ToF Confidence between depth and solid depth . In the fusion process between two depth maps , The constraint of local consistency is imposed based on the confidence information .
Besides , One of the great contributions of this article is , This paper provides a set of synthetic data sets that can be used for deep learning network training . Network training and testing , On this dataset .
Experimental results show that , The fusion framework can effectively improve the accuracy of depth map .
ps: After this article , The team published another article dedicated to removing MPI The article , The address of thesis translation and interpretation is :https://blog.csdn.net/flow_specter/article/details/123073483
Method and network structure
Under the assumption of stereo acquisition system and ToF When the systems have been calibrated , The algorithm consists of the following four steps :
- from ToF sensor The obtained depth information is first projected onto the reference stereo camera angle ;
- A high resolution depth map is calculated by stereo matching algorithm . In particular , In this paper SGM Algorithm ;
- Use CNN The network estimates the stereoscopic parallax and ToF Confidence of depth map ;
- Take the sample from ToF Output results and stereo parallax for fusion , The way of integration is LC(Mattoccia etc. ,2009) An extended version of the technique .

Use e-learning confidence
For a certain scene i i i for , First of all, there are the following definitions :
- D T , i D_{T,i} DT,i: Projected onto a stereoscopic system ToF Parallax map ;
- A T , i A_{T,i} AT,i: Amplitude diagram projected onto the stereoscopic system ;
- D S , i D_{S,i} DS,i: Parallax map obtained by stereoscopic system ;
- I R , i I_{R,i} IR,i: The right image of the stereoscopic system that has been converted to gray
- I L ′ , i I_{L',i} IL′,i:warp To the left from the perspective of the right ( Has been converted to grayscale )
- Δ L R . i ′ \Delta '_{LR.i} ΔLR.i′: Based on a two-step process warp The difference between the left graph and the right graph of , First of all, there is :
Δ L R , i = ∣ I L , i μ L , i − I R , i μ R , i ∣ \Delta_{L R, i}=\left|\frac{I_{L, i}}{\mu_{L, i}}-\frac{I_{R, i}}{\mu_{R, i}}\right| ΔLR,i=∣∣∣∣μL,iIL,i−μR,iIR,i∣∣∣∣
among , Zoom factor μ L , i \mu_{L,i} μL,i as well as μ R , i \mu_{R,i} μR,i Calculated from the left and right images respectively . This result is then divided by a σ Δ L R \sigma_{\Delta_{LR}} σΔLR, That is to say, in all scenarios in the training data set Δ L R , j \Delta_{LR,j} ΔLR,j The mean of the standard deviation of :
Δ L R , i ′ = Δ L R , i / σ Δ L R \Delta_{L R, i}^{\prime}=\Delta_{L R, i} / \sigma_{\Delta_{L R}} ΔLR,i′=ΔLR,i/σΔLR
Besides , also :
D T , i ′ = D T , i / σ D T D S , i ′ = D S , i / σ D S A T , i ′ = A T , i / σ A T \begin{aligned} D_{T, i}^{\prime} &=D_{T, i} / \sigma_{D_{T}} \\ D_{S, i}^{\prime} &=D_{S, i} / \sigma_{D_{S}} \\ A_{T, i}^{\prime} &=A_{T, i} / \sigma_{A_{T}} \end{aligned} DT,i′DS,i′AT,i′=DT,i/σDT=DS,i/σDS=AT,i/σAT
Among them σ D T \sigma_{D_T} σDT, σ D S \sigma_{D_S} σDS, σ A T \sigma_{A_T} σAT Are the average values of the standard deviations of multiple scenes in the training set .
Final , Δ L R , i ′ \Delta'_{LR,i} ΔLR,i′, D T , i ′ D'_{T,i} DT,i′, D S , i ′ D'_{S,i} DS,i′, A T , i ′ A'_{T,i} AT,i′concat together , Form a four channel input , Feed CNN, The outputs correspond to ToF Data and Stereo Confidence graph of data P T P_T PT and P S P_S PS.
The schematic diagram of the network reasoning structure is as follows :
Input CNN Of the training image block shape by 142 ∗ 142 142 * 142 142∗142 The size of 4 Access map .
The network in the middle stack is 6 One with ReLU The convolution of layer , Except for the last convolution, there is no convolution . front 5 Convolution layers , Every floor has 128 A green filter , The window size of the first layer is 5 ∗ 5 5 * 5 5∗5, Others are 3 ∗ 3 3 * 3 3∗3. The last layer of convolution has only two filters , Thus, the output has only two channels , These two channels contain estimated ToF And the confidence of stereogram . be aware , In order to make the output and input have the same resolution , No pooling layer is used .
meanwhile , In order to deal with the size reduction caused by convolution , Turn each image outward in advance pad 7 Pixel .
Training details
The image block is obtained by randomly clipping from the complete image (pad after 142 * 142), A considerable amount of training data can be obtained .
In training , Some standard data enhancement methods can be used , For example, rotate the positive and negative 5°, Horizontal and vertical flipping, etc .
In the experiment , Extract... From each graph 30 individual patch, Consider the enhanced version , A total of 6000 individual patch.
Whether it's ToF data , Or binocular data , Its confidence is GT There are estimated parallax values and GT The absolute difference between parallax . More specifically , The confidence level is calculated as : First, give a threshold , Will be greater than the threshold value clip fall , Then divide by the threshold , So that all confidence levels fall to [ 0 , 1 ] [0,1] [0,1] Between .
Loss function for training , Then the confidence degree and confidence degree of network estimation are calculated GT Between MSE.
The optimizer uses SGD, The momentum is 0.9.bs=16. The weight initialization method is Xavier initialization . The initial learning rate is 1 0 − 7 10^{-7} 10−7, The attenuation coefficient of learning rate is 0.9, every other 10 The wheel decays once . The concrete implementation of the network adopts MatConvNet Structure . stay i7-4790CPU as well as NVIDIA Titan X GPU Configured PC On , Network training takes about three hours .
Eyes and ToF Parallax fusion
LC Refer to Local Cosistent, Is a method for optimizing stereo matching data . The idea behind this approach is , Every effective depth estimation should be a function of data color representation and spatial consistency .
And this rationality , It will further spread to the adjacent pixels . In the end , Every point will gather rationality from all directions , And through WTA To get the final parallax value .
The parameters used in the network are : γ s = 8 \gamma_s =8 γs=8, γ c = γ t = 4 \gamma_c = \gamma_t = 4 γc=γt=4.
LC One of the extension methods of is : The depth estimation of multiple sources is weighted according to the confidence , Formula for :
Ω f ′ ( d ) = ∑ g ∈ A ( P T ( g ) P f , g , T ( d ) + P S ( g ) P f , g , S ( d ) ) \Omega_{f}^{\prime}(d)=\sum_{g \in \mathcal{A}}\left(P_{T}(g) \mathcal{P}_{f, g, T}(d)+P_{S}(g) \mathcal{P}_{f, g, S}(d)\right) Ωf′(d)=g∈A∑(PT(g)Pf,g,T(d)+PS(g)Pf,g,S(d))
among , P T ( g ) P_T(g) PT(g) as well as P S ( g ) P_S(g) PS(g) Namely ToF System and Stereo The system is in pixels g g g The confidence level on . in an article , The confidence is estimated by the network .
Synthetic data
Another major contribution of this paper is , A file named SYNTH3 Synthetic data set , This synthetic data set can be directly used for the training of deep learning networks , Which includes 40 A scenario (20 Each scene is unique and different , in addition 20 One for the front 20 Rendering results from different angles of three scenes ).
Although the number of scenes is not large , But compared with all the data sets at that time , Is already the biggest stereo-ToF The data set , It can also maintain different characteristics of different scenes , It's not easy .
The test set includes the following items: 15 Data collected in a unique scene .
Each synthetic data is passed through Blender Of 3D Rendering function implementation , Specifically, the scene is rendered by using a virtual camera .
Different scenes include furniture and other objects of different shapes , It also includes different indoor environments , For example, speaking of living room 、 Kitchen or office . Besides , The data also includes some outdoor scenes with irregular geometric structure . in general , The data looks relatively real , And more suitable for Stereo-ToF Simulation of acquisition . The depth distance in the scene is 50cm To 10m Between , It provides a wide measurement range .
In the simulation scenario , A virtual place with ZED Stereo camera with the same parameters , And an imitation Kinect v2 Camera parameters ToF The camera . The baseline length of the stereoscopic imaging system is 12cm. The relevant parameters of the two are :
Stereo-ToF Schematic diagram of the system :
For each scenario , The dataset includes :
(1) Left and right pictures collected by stereo system 1920 * 1080 Large and small color images ;
(2) ToF Depth map estimated by the system ;
(3) ToF The correlation amplitude diagram obtained by the system .
Color images can be directly generated by Blender Medium 3D Renderers LuxRender obtain ,
ToF The camera uses Sony EuTEC Developed ToF-Explorer The simulator gets .
ToF The simulator is used by Blender as well as LuxBlender The generated scene information is used as input .
Besides , The dataset also contains the depth truth of the scene ( Align with the right image of the stereo camera ).SYNTH3 It should be the first one that can be used for deep learning ToF Composite datasets .
experimental result
The training and testing of the fusion algorithm proposed in this paper are SYNTH3 On dataset .
Test set scenarios

Confidence estimation results

Qualitative and quantitative results of parallax estimation


reference
[1] S. Mattoccia. A locally global approach to stereo correspondence. In Proc. of 3D Digital Imaging and Modeling (3DIM), October 2009. 2, 3, 5
appendix : Data description
What is provided in this article SYNTH3 The download address of the data is :https://lttm.dei.unipd.it//paper_data/deepfusion/.
For each scenario in the dataset , There are :
- 512 ∗ 424 512 * 424 512∗424 Of ToF Depth map ;
- Projected into the perspective of a stereoscopic system ToF Depth map , A resolution of 960 ∗ 540 960*540 960∗540;
- They are different from 16、80、120MHz Frequency acquisition ToF amplitude chart , A resolution of 512 ∗ 424 512 * 424 512∗424;
- stay 120 MHz Obtained in frequency 、 And has been projected to the perspective of the stereo camera ToF amplitude chart ;
- stay 16、80、120 MHZ Separately obtained in frequency 512 ∗ 424 512 * 424 512∗424 Resolution ToF Intensity diagram ;
- ToF Perspective GT Depth map ;
- Left and right angle color images obtained by stereo system , The resolution is 1920 ∗ 1080 1920 * 1080 1920∗1080;
- Disparity map and depth map estimated by stereo camera , A resolution of 960 ∗ 540 960 * 540 960∗540, Right view ;
- On the right view of the stereo camera GT Depth and GT Parallax map .
边栏推荐
- Detailed explanation of this and static
- Device = depthai Device(““, False) TypeError: _init_(): incompatible constructor arguments.
- Talk about reading the source code
- 【ROS】noedic-moveit安装与UR5模型导入
- Success and failure of ERP software from the perspective of enterprise evaluation
- How to deal with these problems in the factory production process?
- Award winning survey streamnational sponsored 2022 Apache pulsar user questionnaire
- Interview question 17.10 Main elements
- Flask (VI) - template
- MSF adds back door to normal program
猜你喜欢

Zhiyun health submitted the statement to HKEx again: the loss in 2021 exceeded 4billion yuan, an increase of 43% year-on-year

Simulation of map and set

Before applying data warehouse ODBC, you need to understand these problems first
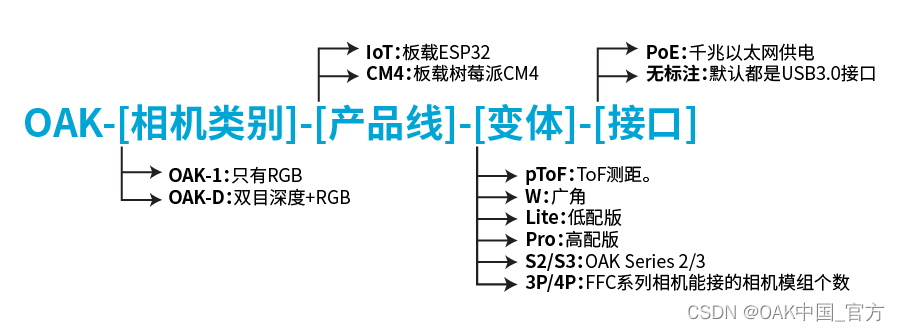
Comparison and introduction of OpenCV oak cameras

Package details

机器学习笔记 - 使用TensorFlow的Spatial Transformer网络

Openstack explanation (24) -- registration of neutron service

报错RuntimeError: BlobReader error: The version of imported blob doesn‘t match graph_transformer

Day41 process pool and thread pool
机器学习笔记 - 深度学习技巧备忘清单
随机推荐
Augmented reality experiment IV of Shandong University
[intelligent development] scheme design and hardware development of sphygmomanometer
Machine learning notes - in depth Learning Skills Checklist
keyboard entry.
Opencv CEO teaches you to use oak (V): anti deception face recognition system based on oak-d and depthai
Detailed explanation of the difference between construction method and method
Where is it safer to open an account for soda ash futures? How much do you need to buy at least?
Set up redis highly available cluster environment
Analysis of high frequency interview questions in massive data processing
js中关键字this的理解
【软件】大企业ERP选型的方法
Day39 process object and other method mutexes
Openstack explanation (22) -- neutron plug-in configuration
Do you know these advantages of ERP system?
【ERP体系】专业技术层面的评估,你了解多少?
Comparison and introduction of OpenCV oak cameras
Package details
Technical practice of dolphin dispatching in kubernetes system
affair
Machine learning notes - convolutional neural network memo list