当前位置:网站首页>【爬虫】数据提取之xpath
【爬虫】数据提取之xpath
2022-07-04 22:46:00 【语音不识别】
安装
pip install lxml
导包
from lxml import etree
使用
将html字符串 转换为element对象
# 将html字符串 转换为element对象
from lxml import etree
element = etree.HTML(html_str)
以下是通过element对象.xpath('匹配规则')来提取内容
获取标签
使用 / 表示根节点,路径和路径之间的过渡
/html/xx/xx/xxx
使用 // 跨节点选取,直接到想要的标签或者文本
//xxx # 获取所有xxx标签
使用.
./ 当前节点
使用 ..
../ # 当前节点的上一级节点
.// 当不是完整的html时,使用 ,获取相对路径
获取属性
@属性名 获取当前标签 这个属性对应的属性值
//img/@src # 所有img 的scr属性
获取文本
/text() 获取标签里面的文本内容//标签名[contains( text() , ' 文字 ' ) ] 获取包含 文字的 标签
//ol/li//span[contains(text(),'可播放')]
获取特定条件标签
//标签名[@属性名=值] 根据标签的属性值去定位具体的标签
//span[@class='title'] # 可以通过类名进行获取了
//标签名[索引] 索引从1开始
从前边获取//上一级标签/标签名[position()>3] 从第4个开始
从后边获取//上一级标签/标签名[last()] 获取最后一个//上一级标签/标签名[last() - 2] 倒数第3个
结合//ol/li[position()>1][position()<last()-2]
//标签名[text()='值'] 根据标签中具体的文本内容定位具体的标签,需要一字不差进行匹配
//ol/li//span[text()='[可播放]'] # 匹配标签内容是[可播放]的标签
边栏推荐
- Network namespace
- vim编辑器知识总结
- Set up a website with a sense of ceremony, and post it to 1/2 of the public network through the intranet
- The difference between Max and greatest in SQL
- Google Earth engine (GEE) - globfire daily fire data set based on mcd64a1
- Unity vscode emmylua configuration error resolution
- 【图论】拓扑排序
- 【剑指offer】1-5题
- 数据库基础知识
- C语言快速解决反转链表
猜你喜欢
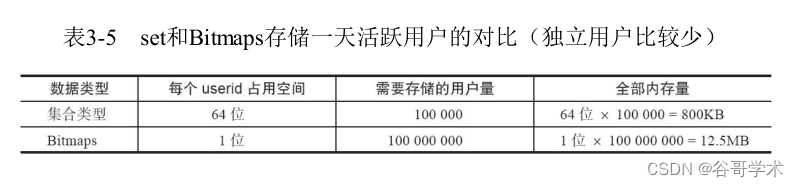
Complete tutorial for getting started with redis: bitmaps
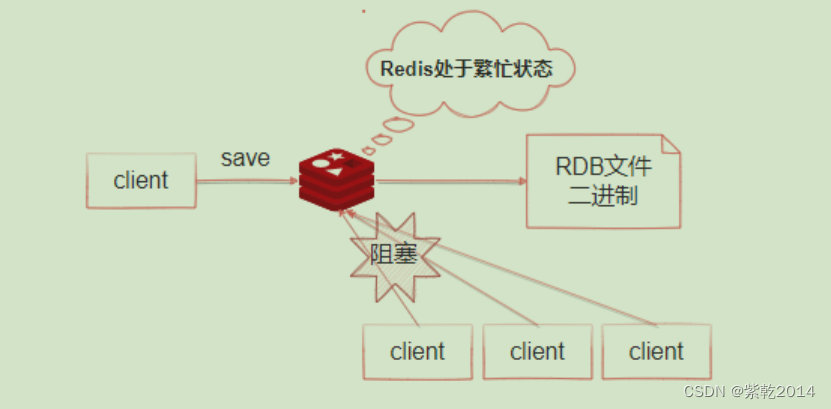
Persistence mechanism of redis
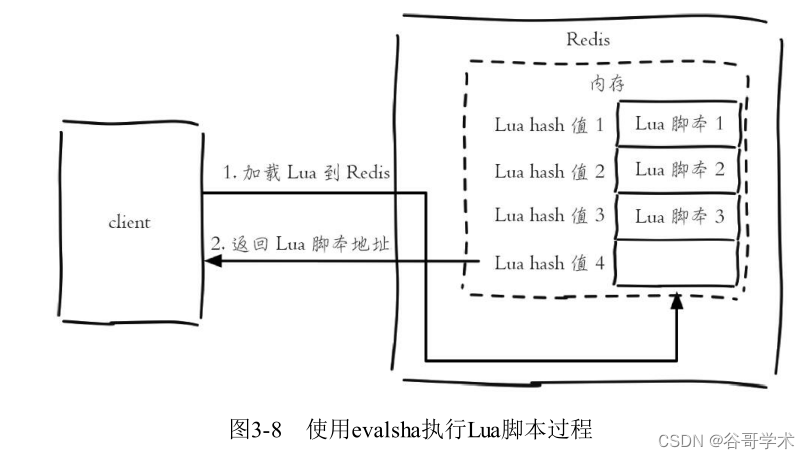
Redis入门完整教程:事务与Lua

Unity vscode emmylua configuration error resolution
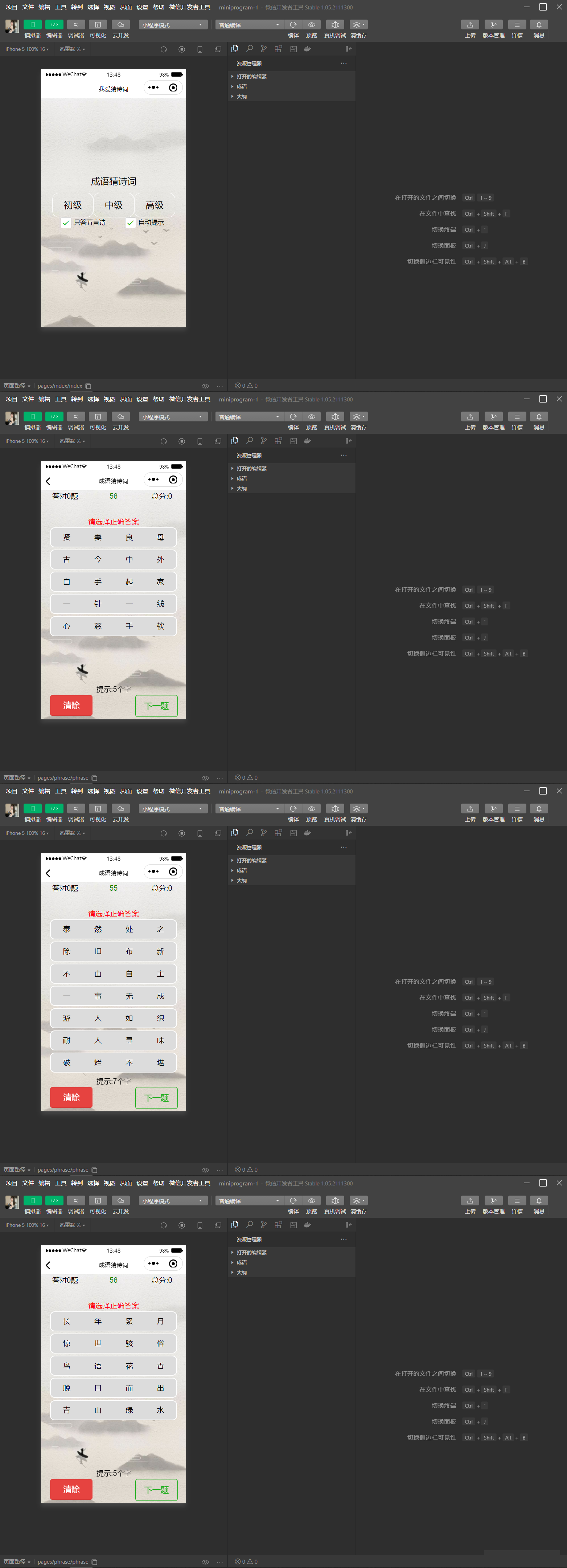
智力考验看成语猜古诗句微信小程序源码
D3.js+Three. JS data visualization 3D Earth JS special effect
Set up a website with a sense of ceremony, and post it to 1/2 of the public network through the intranet

Tweenmax emoticon button JS special effect
Redis入门完整教程:初识Redis
Redis introduction complete tutorial: detailed explanation of ordered collection
随机推荐
[try to hack] wide byte injection
debug和release的区别
为什么信息图会帮助你的SEO
ETCD数据库源码分析——处理Entry记录简要流程
Sword finger offer 68 - I. nearest common ancestor of binary search tree
Photoshop batch adds different numbers to different pictures
qt绘制网络拓补图(连接数据库,递归函数,无限绘制,可拖动节点)
UML图记忆技巧
JS card style countdown days
Redis introduction complete tutorial: slow query analysis
[roommate learned to use Bi report data processing in the time of King glory in one game]
Redis入门完整教程:哈希说明
ECS settings SSH key login
Feature scaling normalization
Advanced area of attack and defense world misc 3-11
[Lua] Int64 support
Gnawing down the big bone - sorting (II)
Redis introduction complete tutorial: client communication protocol
PS style JS webpage graffiti board plug-in
[machine learning] handwritten digit recognition