当前位置:网站首页>Lex & yacc of Pisa proxy SQL parsing
Lex & yacc of Pisa proxy SQL parsing
2022-07-07 20:56:00 【SphereEx】
One 、 Preface
1.1 The authors introduce
Wang Bo ,SphereEx MeshLab R & D Engineer , Focus on Database Mesh,Cloud Native The development of .Linux,llvm,yacc,ebpf user. Gopher & Rustacean and c bug hunter.
GitHub: github.com/wbtlb
1.2 background
In the last article 《Pisa-Proxy And SQL Analytical practice )》 This paper introduces the in Pisa-Proxy One of the core modules of SQL Parser related content . stay MySQL and PostgreSQL in SQL analysis It's through Yacc Realized , Again Pisa- Proxy Of SQL The parser is composed of Yacc Such tools realize , So this article will focus on SQL The parser introduces some compilation principles and Lex & Yacc Use , It will also show readers how to pass Lex & Yacc Implement a simple one SQL Parser . So as to help you better understand Pisa-Proxy in SQL How the parser works .
Two 、 Compiler exploration
A programming language, no matter what we often use Java,Golang Or is it SQL It is essentially a notation system , Like natural language , Its complete definition should include both syntax and semantics . The grammar of a language is actually a corresponding set of rules , It can be used to form and produce a suitable program . Currently, the most widely used method is context free grammar , Context free grammar is used as a tool to describe the syntax of programming language . Grammar just defines what kind of symbol sequence is legal , It has nothing to do with the meaning of these symbols . However, there are two categories in semantics : Static semantics and dynamic semantics . Static semantics refers to a series of qualification rules , And determine which syntax is appropriate for the program ; Dynamic semantics is also called running semantics or execution semantics , Specify what the program will calculate .
2.1 Compiler workflow
Pictured 2.1.1 As shown in , Generally, the compiler compiles the source code into executable files in the following steps :
- Scan the source file , Split the character stream of the source file into words (token), This is lexical analysis
- According to the grammar rules, these marks are constructed into a grammar tree , This is syntax analysis
- Check the relationship between the nodes of the syntax tree , Check whether semantic rules are violated , At the same time, the syntax tree is optimized as necessary , This is semantic analysis
- Traverse the nodes of the syntax tree , Convert each node into intermediate code , And put them together in a specific order , This is intermediate code generation
- Optimize the intermediate code
- Convert intermediate code into object code
- Optimize the object code , Generate the final target program
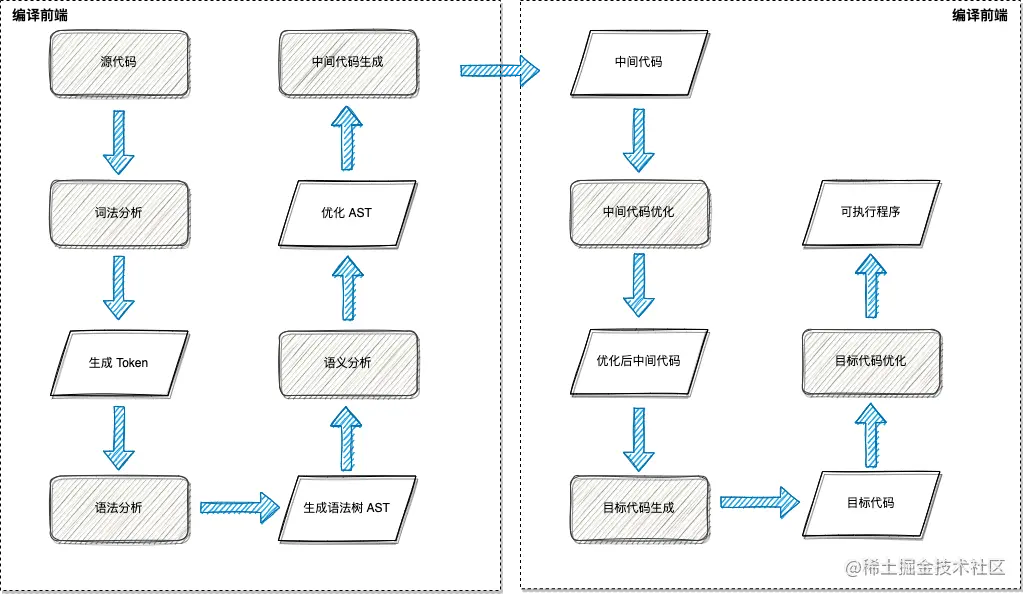
about SQL Analytically speaking , The steps in the above figure can be simplified as shown in the figure 2.1.2 In the form of , Source code input (SQL sentence ), take SQL Sentence for lexical analysis , Generate SQL In the specific token Sign flow . Then get the token stream and parse it to generate the final SQL AST.
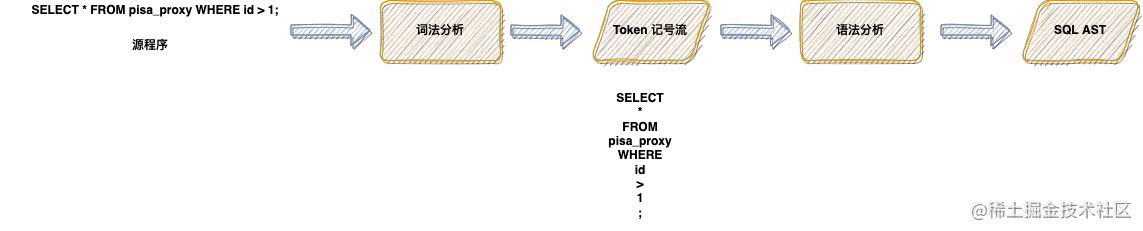
2.2 Lexical analysis
As mentioned above , Whether compiler or SQL A key step of the parser is to do lexical analysis on the source file , Lexical analysis can be understood as right SQL The sentence itself is processed by word segmentation . So at this stage ,SQL What the parser needs to do is scan the source file from left to right , take SQL Statements are divided into one by one token, here token Refer to SQL A string of characters that cannot be further divided in . For example, figure 2.1.2 Medium SQL sentence , After lexical analysis , Generated token by :SELECT、*、FROM、pisa_proxy wait .
stay SQL What can be used in the sentence token Categories are also limited , For example, reserved words SELECT、INSERT、DELETE wait . And operators , such as : arithmetic operator 、 Comparison operator . And identifiers , such as : Built in function name and so on . At this stage, each scan token Will be maintained in a data structure , Then in the next phase, the parsing phase uses . Generally speaking , Lexical analysis has direct scanning , Regular matching scanning mode .
2.2.1 Direct scanning method
The logic of direct scanning method is very clear , Each scan determines which type it belongs to according to the first character token, Then take different strategies to scan out a complete token, Then proceed to the next scan . stay Pisa-Proxy Medium SQL Parsing , Lexical analysis adopts this implementation , use Python Show how to implement a simple SQL Lexical analyzer pair SQL scan , The code is as follows :
# -*- coding: utf-8 -*-
single_char_operators_typeA = {
";", ",", "(", ")","/", "+", "-", "*", "%", ".",
}
single_char_operators_typeB = {
"<", ">", "=", "!"
}
double_char_operators = {
">=", "<=", "==", "~="
}
reservedWords = {
"select", "insert", "update", "delete", "show",
"create", "set", "grant", "from", "where"
}
class Token:
def __init__(self, _type, _val = None):
if _val is None:
self.type = "T_" + _type;
self.val = _type;
else:
self.type, self.val = _type, _val
def __str__(self):
return "%-20s%s" % (self.type, self.val)
class NoneTerminateQuoteError(Exception):
pass
def isWhiteSpace(ch):
return ch in " \t\r\a\n"
def isDigit(ch):
return ch in "0123456789"
def isLetter(ch):
return ch in "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
def scan(s):
n, i = len(s), 0
while i < n:
ch, i = s[i], i + 1
if isWhiteSpace(ch):
continue
if ch == "#":
return
if ch in single_char_operators_typeA:
yield Token(ch)
elif ch in single_char_operators_typeB:
if i < n and s[i] == "=":
yield Token(ch + "=")
else:
yield Token(ch)
elif isLetter(ch) or ch == "_":
begin = i - 1
while i < n and (isLetter(s[i]) or isDigit(s[i]) or s[i] == "_"):
i += 1
word = s[begin:i]
if word in reservedWords:
yield Token(word)
else:
yield Token("T_identifier", word)
elif isDigit(ch):
begin = i - 1
aDot = False
while i < n:
if s[i] == ".":
if aDot:
raise Exception("Too many dot in a number!\n\tline:"+line)
aDot = True
elif not isDigit(s[i]):
break
i += 1
yield Token("T_double" if aDot else "T_integer", s[begin:i])
elif ord(ch) == 34: # 34 means '"'
begin = i
while i < n and ord(s[i]) != 34:
i += 1
if i == n:
raise Exception("Non-terminated string quote!\n\tline:"+line)
yield Token("T_string", chr(34) + s[begin:i] + chr(34))
i += 1
else:
raise Exception("Unknown symbol!\n\tline:"+line+"\n\tchar:"+ch)
if __name__ == "__main__":
print "%-20s%s" % ("TOKEN TYPE", "TOKEN VALUE")
print "-" * 50
sql = "select * from pisa_proxy where id = 1;"
for token in scan(sql):
print token
The final output is as follows :
TOKEN TYPE TOKEN VALUE
--------------------------------------------------
T_select select
T_* *
T_from from
T_identifier pisa_proxy
T_where where
T_identifier id
T_= =
T_integer 1
T_; ;
We can see from the above code , At the beginning, we defined several token type , for example :reservedWords Array is maintained SQL Reserved word in , also SQL Operator in single_char_operators_typeA. We can see the final implementation result , The scanner will eventually be a SQL Sentences are segmented into their corresponding types token.
2.2.2 Regular expression scanning
In fact, the essence of a program is a set of strings , And language can be regarded as a collection of legal programs , So the compiler or SQL The essence of parsing is to judge that the input string is the legal type of the language , In addition, it is also a legal program that converts the legal program in the language into the target language . So the essence of regular expression scanning , That is to judge whether the string matches the regular expression in a finite state machine , In the following introduction, we will mention flex,flex The essence of is to construct a finite state automaton from the word segmentation matching pattern written by users in regular expressions .
2.3 Syntax analysis
After lexical analysis ,SQL The character stream of the statement is split into token, Then grammatical analysis is to analyze SQL The grammatical structure of , Will be linear token The flow is transformed into a tree structure , For subsequent semantic analysis and AST Prepare for generation . In the compiler , Regular expressions are still difficult to represent the set of sentences represented by programming languages , So we introduce context free grammar , Context free grammar can describe the grammatical structure of current programming languages .
Take our natural language as an example , Suppose a programming language is SQLX, It only contains the main - Predicate - Bin For this structure , The subject is only you 、 I 、 He , Predicate only Love , The object has Rust and Pisanix, Then the grammar can be in the following form :
sentence -> The subject Predicate The object
The subject -> I
The subject -> you
The subject -> He
Predicate -> Love
The object -> Rust
The object -> Pisanix
From the above example, we can replace the subject predicate object respectively , So as to write all the statements that meet this structure . On the contrary, we can compare any sentence with this structure to judge whether it meets SQLX Language . This leads to several concepts , In the above grammar, the form is “ The subject -> Predicate -> The object ” The formula of becomes Generative formula
The symbol on the left of production ( sentence 、 The subject 、 Predicate 、 The object ) be called non-terminal . and “ I , you , He , Love ,Rust,Pisanix” These symbols can no longer produce new symbols , So it's called Terminator , The terminator can only appear on the right of the production . The word "sentence" is the starting point of all sentences , So it's also called Start symbol .
Usually put a non The production of terminators is written together , use “|” separate , It can be summed up as follows :
sentence -> The subject Predicate The object
The subject -> you | I | He
Predicate -> Love
The object -> Rust | Pisanix
We start with a SQL Statements, for example : SELECT 1 + 1, We can write the push expression of this statement as , The analysis tree is shown in the figure 2.3.1
Expr => Expr Expr + Expr => SELECT Expr + Expr => SELECT number + Expr => SELECT number + number => SELECT 1 + 2
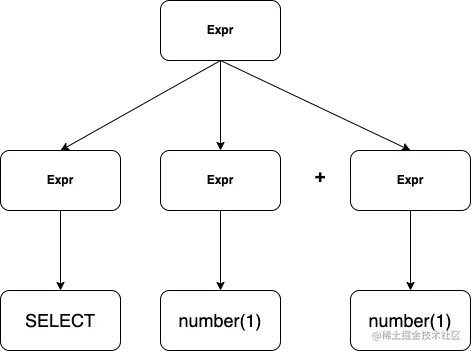
2.3.1 Two analytical methods
Grammar analysis includes two analysis methods :
Top down analysis : Top down analysis starts with the starting symbol , Keep picking out the right production , Expand the non terminator in the middle sentence , Finally, expand to the given sentence .
Bottom up analysis : The order of bottom-up analysis is just the opposite to that of top-down analysis , Start with the given sentence , Keep picking out the right production , Fold the substring in the middle sentence into a non terminator , Finally collapse to the starting symbol
In the process of derivation , At each step, only one production can be applied , Every step can eliminate all other production formulas . But in actual analysis , In the intermediate process, you may encounter that all productions are not applicable or there are multiple productions that can be applied . For the second case , Backtracking is required , First try to choose a production application , If it is deduced until the final sentence ( Or starting symbol ), Then it shows that this production is available , If we continue to deduce, we will encounter the first case , Then go back here , Choose another production . If all the production formulas here have been tried, all of them encounter the first case , It shows that the final sentence does not conform to the grammatical structure . If there are multiple production expressions here, they can be deduced to the final sentence ( Or starting symbol ), It shows that the grammar is ambiguous . Backtracking analysis is generally very slow , Therefore, we usually avoid backtracking by carefully constructing grammar .
2.4 Summary
The above content mainly introduces the related concepts of compiler , And through a simple example to intuitively feel the basic principle and working process of lexical analysis , Next, I will briefly introduce the two most commonly used tools in lexical analysis and grammatical analysis Lex and Yacc.
3、 ... and 、 know Lex and Yacc
3.1 know Lex
Flex( Fast lexical analyzer generator ) yes Lex Free open source software alternatives . It is a generated lexical analyzer ( Also known as “ Scanner ” or “ Lexical analyzer ”) A computer program for . Scanner is a program that recognizes lexical patterns in text , Used to recognize lexical patterns in text .
3.1.1 Lex It's made up of three parts
Definition section : The definition segment includes text blocks 、 Definition 、 Internal table declaration 、 Starting conditions and transitions .
The rules section : The rule segment is a series of matching patterns and actions , Patterns are usually written in regular expressions , The action part is C Code .
User subroutine segment : Here for C Code , Will be copied to c In file , Generally, some auxiliary functions are defined here , Such as the auxiliary function used in the action code .
Here we make a simple example , use Lex Implement a simple one SQL Lexical analyzer ,lex The code is as follows :
%{
#include <stdio.h>
%}
%%
select printf("KW-SELECT : %s\n", yytext);
from printf("KW-FROM : %s\n", yytext);
where printf("KW-WHERE : %s\n", yytext);
and printf("KW-AND : %s\n", yytext);
or printf("KW-OR : %s\n", yytext);
[*] printf("IDENTIFIED : %s\n", yytext);
[,] printf("IDENTIFIED : %s\n", yytext);
[=] printf("OP-EQ : %s\n", yytext);
[<] printf("KW-LT : %s\n", yytext);
[>] printf("KW-GT : %s\n", yytext);
[a-zA-Z][a-zA-Z0-9]* printf("IDENTIFIED: : %s\n", yytext);
[0-9]+ printf("NUM: : %s\n", yytext);
[ \t]+ printf(" ");
. printf("Unknown : %c\n",yytext[0]);
%%
int main(int argc, char* argv[]) {
yylex();
return 0;
}
int yywrap() {
return 1;
}
# flex sql.l # use flex compile .l File generation c Code
# ls
lex.yy.c sql.l
# gcc -o sql lex.yy.c # Compile and generate executable binaries
# ./sql # Execute binary
select * from pisaproxy where id > 1 and sid < 2 # Input test sql
KW-SELECT : select
IDENTIFIED : *
KW-FROM : from
IDENTIFIED: : pisaproxy
KW-WHERE : where
IDENTIFIED: : id
KW-GT : >
NUM: : 1
KW-AND : and
IDENTIFIED: : sid
KW-LT : <
NUM: : 2
We can see from the above example that ,Lex Successfully put a SQL The statement is split into separate token.
3.2 know Yacc
Yacc It is an industrial tool for developing compilers , use LALR(1) Grammar analysis method .LR(k) Analysis method , In brackets k(k>=0) Indicates to view the number of input string symbols to the right .LR The analysis method gives a method that can view the input string according to the symbol string in the current analysis stack and the right order k A symbol can uniquely determine whether the analyzer's action is to move in or to specify and which production specification to use .
Yacc and Lex equally , It also includes “%%” Three separate segments : Definition statement 、 Rule of grammar 、C Code segment .
- Define segments and predefined tag sections :
above %{ %} The code and Lex equally , Generally referred to as definition segment . Just some header file declarations , Macro definition 、 Variable definition declaration 、 Function declaration, etc . among %left It means left combination ,%right Right combination . The last listed definitions have the highest priority . Therefore, multiplication and division have higher priority than addition and subtraction .+ - * / All four arithmetic symbols are left combined . Use this simple technique , We can disambiguate grammar .
The rules section : Rule segments consist of grammatical rules and include C The action composition of the code . In the rule, the target or non terminal character is placed on the left , Followed by a colon (:), Then there is the right side of production , Then there is the corresponding action ( use {} contain )
Code section : This part is the function part . When Yacc When parsing error , Would call
yyerror(), Users can customize the implementation of functions .
Here we use a simple example to pass Yacc and Lex To achieve a simple SQL Parser
sql.l Code example
%{
#include <stdio.h>
#include <string.h>
#include "struct.h"
#include "sql.tab.h"
int numerorighe=0;
%}
%option noyywrap
%%
select return SELECT;
from return FROM;
where return WHERE;
and return AND;
or return OR;
[*] return *yytext;
[,] return *yytext;
[=] return *yytext;
[<] return *yytext;
[>] return *yytext;
[a-zA-Z][a-zA-Z0-9]* {yylval.Mystr=strdup(yytext);return IDENTIFIER;}
[0-9]+ return CONST;
\n {++yylval.numerorighe; return NL;}
[ \t]+ /* ignore whitespace */
%%
sql.y Some code examples
%{
%}
%token <numerorighe> NL
%token <Mystr> IDENTIFIER CONST '<' '>' '=' '*'
%token SELECT FROM WHERE AND OR
%type <Mystr> identifiers cond compare op
%%
lines:
line
| lines line
| lines error
;
line:
select identifiers FROM identifiers WHERE cond NL
{
ptr=putsymb($2,$4,$7);
}
;
identifiers:
'*' {$$="ALL";}
| IDENTIFIER {$$=$1;}
| IDENTIFIER','identifiers
{
char* s = malloc(sizeof(char)*(strlen($1)+strlen($3)+1));
strcpy(s,$1);
strcat(s," ");
strcat(s,$3); $$=s;
}
;
select:
SELECT
;
cond:
IDENTIFIER op compare
| IDENTIFIER op compare conn cond;
compare:
IDENTIFIER
| CONST
;
op:
'<'
|'='
|'>'
;
conn:
AND
| OR
;
%%
# Here, because the compilation process is cumbersome , Here are just the key results
# ./parser "select id,name,age from pisaproxy1,pisaproxy2,pisaproxy3 where id > 1 and name = 'dasheng'"
''Row #1 is correct
columns: id name age
tables: pisaproxy1 pisaproxy2 pisaproxy3
It can be seen through Lex First of all, will SQL It can be interpreted as token, And then by yacc Do grammar analysis , according to .y The rules in will column and tables Correctly solve .
Four 、Pisa-Proxy SQL Analysis and implementation
stay Pisa-Proxy Medium SQL The parser is through Grmtools This tool implements ,Grmtools yes Rust Realized lex and yacc library .Pisa-Proxy Of SQL Parsing mainly includes two parts , First of all lex.rs file , This document was passed Grmtools The method provided realizes the handwriting lexical analyzer , As mentioned earlier , This module will SQL Sentence segmentation , Generate token. And then there was grammar.y file , This document describes SQL The derivation of the statement ,Grmtools The file will be parsed and finally generated SQL AST.
5、 ... and 、 summary
This article mainly shares the relevant concepts and principles of compilers , We can see SQL Parser for SQL What is the meaning of the sentence , And how to SQL The form of statement string is transformed into the abstract syntax tree we need .Lex and Yacc Are two very powerful tools , It can help developers easily and quickly implement their own parser , However, the compilation principle is a very complex subject .Pisa-Proxy Of SQL The parser also encountered many problems in the implementation process , For example, how to resolve conflicts , Two senses , Priority and so on . There will continue to be an in-depth analysis of the article later SQL Statements in Rust The specific implementation of , This article will not repeat .
6、 ... and . Related links :
6.1 Pisanix:
Project address :github.com/database-me…
Official website address :Hello from Pisanix | Pisanix
Database Mesh:www.database-mesh.io/
SphereEx Official website :www.sphere-ex.com
6.2 Community
Tens of millions of steps for open source projects ,Pisanix Just started. . Open source is a door ,Pisanix Welcome to join us , Express your ideas , Share your insights , Whether it's code or documentation ,issue still pull request, The community welcomes . You guys who are willing to help with database management , Let's build Pisanix Community bar ~
at present Pisanix The community organizes online discussions every two weeks , The detailed arrangement is as follows , we will wait for you ~
| ----- | ----- | | Mailing list, | groups.google.com/g/database-…| | English community biweekly meeting (2022 year 2 month 27 The date of ), Wednesday 9:00 AM PST | meet.google.com/yhv-zrby-py… | | Chinese community biweekly meeting (2022 year 4 month 27 The date of ), Wednesday 9:00 PM GMT+8| meeting.tencent.com/dm/6UXDMNsH… | | Wechat assistant | pisanix | | Slack| databasemesh.slack.com/ | | Minutes of the meeting | bit.ly/39Fqt3x |
7、 ... and 、 Reference material
《 Compiler principle 》
《 Principles of modern compilation 》
边栏推荐
- Is it safe to open a stock account at present? Can I open an account online directly.
- 【奖励公示】第22期 2022年6月奖励名单公示:社区明星评选 | 新人奖 | 博客同步 | 推荐奖
- UVA 11080 – Place the Guards(二分图判定)
- object-c编程tips-timer「建议收藏」
- Spark 判断DF为空
- 凌云出海记 | 易点天下&华为云:推动中国电商企业品牌全球化
- Lingyun going to sea | yidiantianxia & Huawei cloud: promoting the globalization of Chinese e-commerce enterprise brands
- 使用枚举实现英文转盲文
- 让这个CRMEB单商户微信商城系统火起来,太好用了!
- 恶魔奶爸 A1 语音听力初挑战
猜你喜欢





随机推荐
[matrix multiplication] [noi 2012] [cogs963] random number generator
guava多线程,futurecallback线程调用不平均
Cantata9.0 | 全 新 功 能
字符串中数据排序
Is it safe to open an account of BOC shares in kainiu in 2022?
Nebula Importer 数据导入实践
Is embedded system really safe? [how does onespin comprehensively solve the IC integrity problem for the development team]
恶魔奶爸 指南帖——简易版
最新版本的CodeSonar改进了功能安全性,支持MISRA,C ++解析和可视化
死锁的产生条件和预防处理[通俗易懂]
使用高斯Redis实现二级索引
[concept of network principle]
Cocos2d-x 游戏存档[通俗易懂]
How to choose fund products? What fund is suitable to buy in July 2022?
sqlHelper的增删改查
微服务远程Debug,Nocalhost + Rainbond微服务开发第二弹
写了个 Markdown 命令行小工具,希望能提高园友们发文的效率!
Jetty:配置连接器[通俗易懂]
CodeSonar通过创新型静态分析增强软件可靠性
easyui 日期控件清空值