当前位置:网站首页>Regular expression is incomplete
Regular expression is incomplete
2022-08-04 19:06:00 【sting】
准备工作.创建测试文件test.txt
一、使用grep to find a specific character
grep -n 表示显示行号
grep -i 表示不区分大小写
grep -v Indicates the opposite of the condition
grep -W 精准匹配
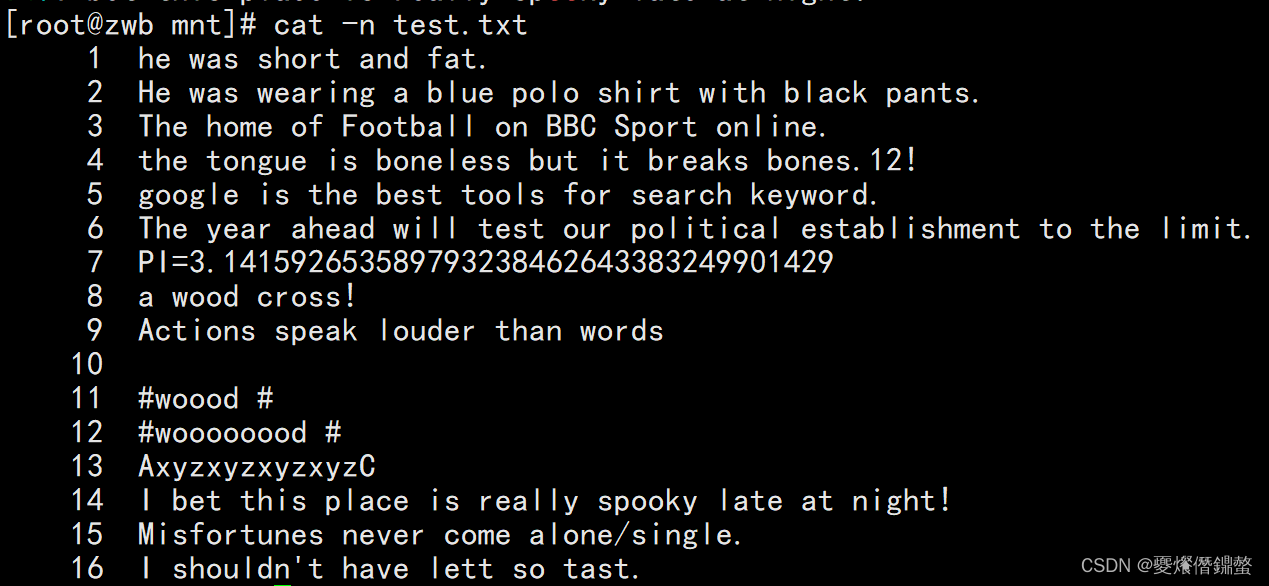
1、使用grep查找含有the的行
grep -n "the" test.txt (-n:表示显示行号)

2、使用grepCase-insensitive search contains the的行
grep -ni "the" test.txt (-ni 同-n -i :表示显示行号,且不区分the的大小写)

3、使用grepReverse lookup does not containthe的行
grep -n -v "the" test.txt
二、利用grep 配合[ ] to find the set of characters
^[a-z] 表示以小写字母开头
^[A-Z] 表示以大写字母开头
^[0-9]表示以数字开头
[^a-z] Indicates that so-and-so is not preceded by lowercase letters
.................................
大白话:"^"在[ ]Inside and outside have different meanings,Outside means that the content in parentheses is the beginning of the line,In it, it means that the reverse selection of the content in the brackets is the negation.
官方语言:“^”符号在元字符集合“[]”符号内外的作用是不一样的,在“[]”符号内表示反向选择,在“[]”符号外则代表定位行首.反之,若想查找以某一特定字符结尾的行则可以使用“$”定位符
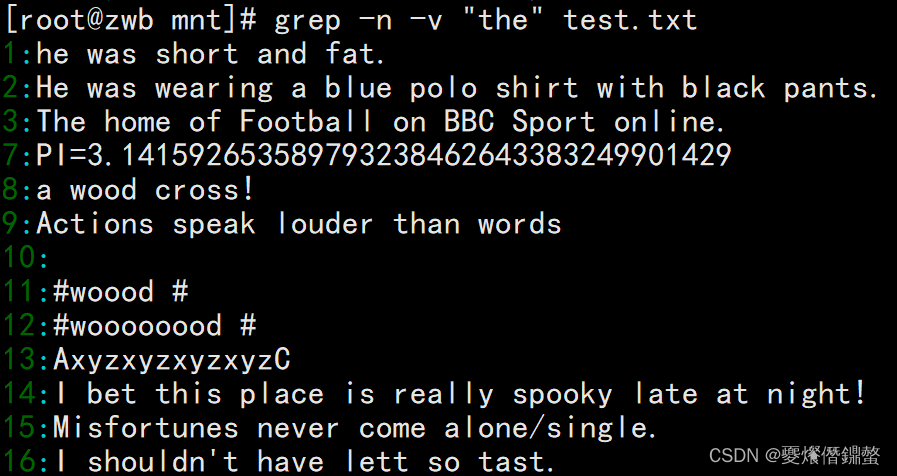
1、需求:想要查找“shirt”与“short”这两个字符串时
可以发现这两个字符串均包含“sh” 与“rt”,“[]”中无论有几个字符,都仅代表一个字符,也就是说“[io]”表示匹配“i”或者“o”.
grep -n "sh[io]rt" test.txt

2、需求: Finds only single characters that contain repeats“oo”时
[[email protected] mnt]# grep -n "sh[io]rt" test.txt
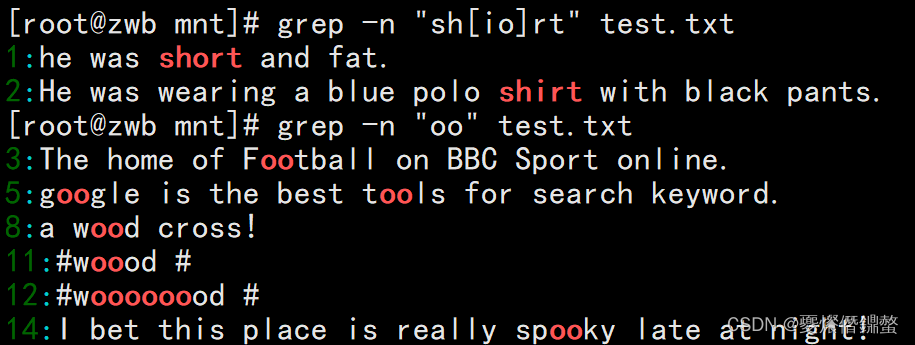
3、需求: 查找“oo”前面不是“w”的字符串.使用 “[^w]”来实现
[[email protected] mnt]# grep -n '[^w]oo' test.txt

解析:会发现11行和12行,也被匹配到了.此时,是这样的,11行有d三个"ooo",And we filter for two"oo",But he identifies the latter two“oo”时两个"oo"的前面就是o而不是w.12行同理.
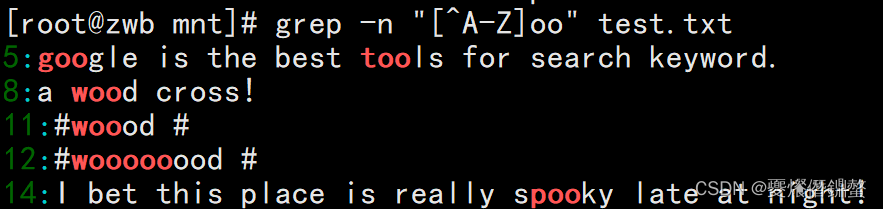
4、需求:若不希望“oo”前面存在小写字母,用[^a-z] 其中a-z表示小写字母,使用A-Zmeans uppercase,
[0-9]表示数字.
[[email protected] mnt]# grep -n "[^a-z]oo" test.txt

[[email protected] mnt]# grep -n "[^A-Z]oo" test.txt
[[email protected] mnt]# grep -n "[0-9]" test.txt

5、使用grep配合使用“^”(行首)表示以什么为开头、“$”(行尾)以什么为结尾
①需求:使用grepFind the beginning of the line withthe开头的.

②查询以小写字母开头的行可以通过“^[a-z]”规则来过滤,查询大写字母开头的行则使用“^[A-Z]”规则,若查询不以字母开头的行则使用“^[^a-zA-Z]”规则.
[[email protected] mnt]# grep -n '^[a-z]' test.txt
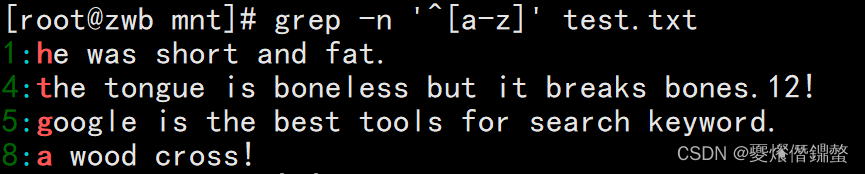
[[email protected] mnt]# grep -n '^[^a-zA-Z]' test.txt

6、grepFilter to find blank lines and dot endings
①需求:Queries with decimal points(.)结尾的行,The decimal point is a meta element in regex,具有特殊含义,用”\“,不进行转义.
[[email protected] mnt]# grep -n "\.$" test.txt
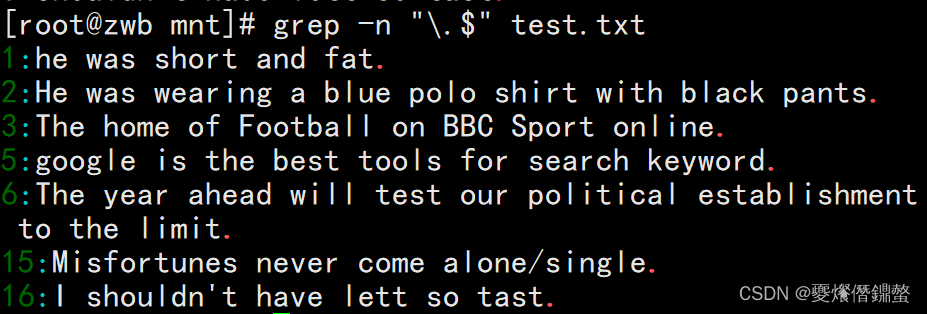
②使用grep查询空白行,"^$"
[[email protected] mnt]# grep -n "^$" test.txt

7、查找任意一个字符“.” 与重复字符“*”
在正则表达式中小数点(.)也是一个元字符,匹配任意一个字符,So you need to add the dots above to represent the end“\”
“*”stands for repeating zero or more of the preceding repeating characters,例如:“o*”表示拥有零个(即为空字符)或大于等于一个“o”的字符,因为允许空字符.
①需求:grep 查找w和dThere are two arbitrary characters in between.
[[email protected] mnt]# grep "w..d" test.txt

②”o*“表示含义0个o或者多个o
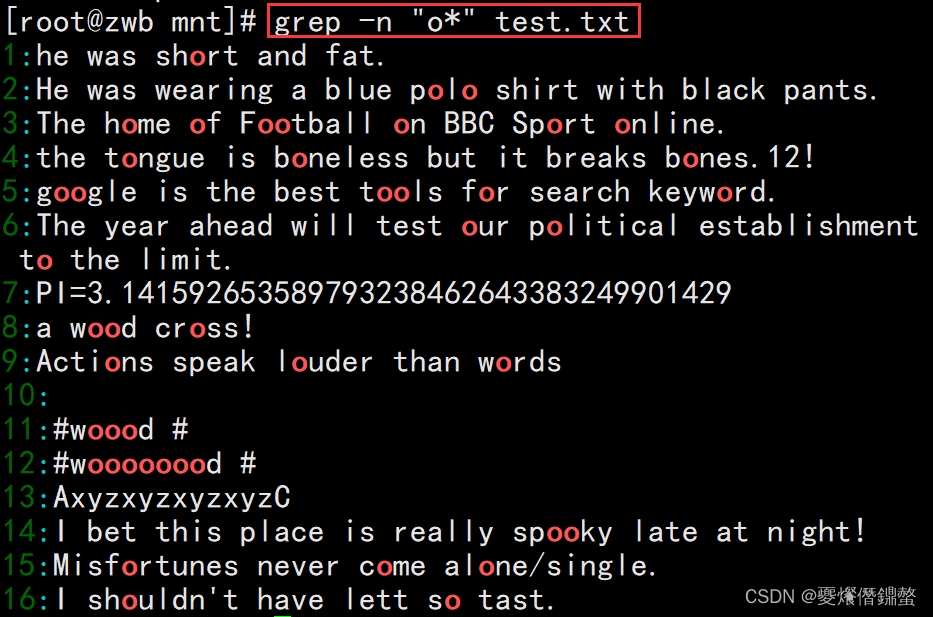
解析:表示含有0个o时,Printed all.
②”oo*“表示第一o存在,第二个o后面有个*号,表示第二个o可以是一个o或者多个o.
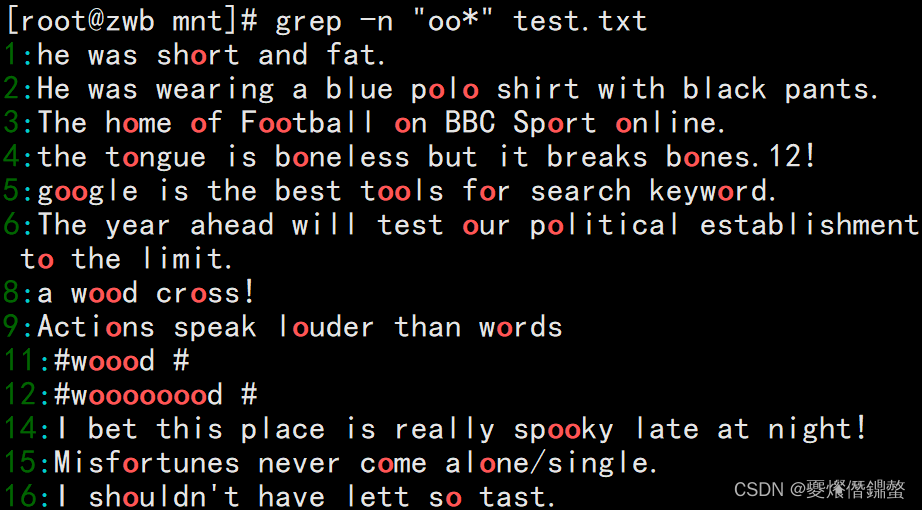
解析:The text contains at least oneo
③”ooo*“表示第一o存在,第二个o存在,第三个o后面有个*号,表示第三个o可以是一个o或者多个o.
[[email protected] mnt]# grep -n "ooo*" test.txt
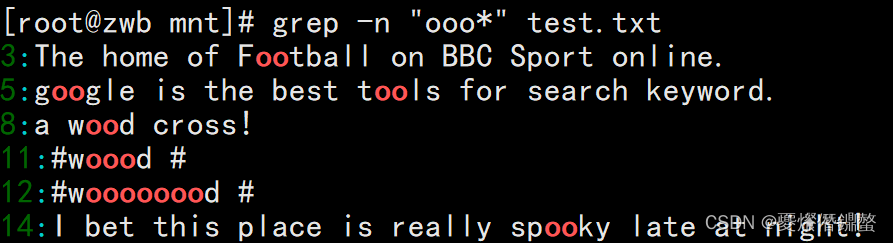
④ 查询以 w 开头 d 结尾,中间包含至少一个 o 的字符串.

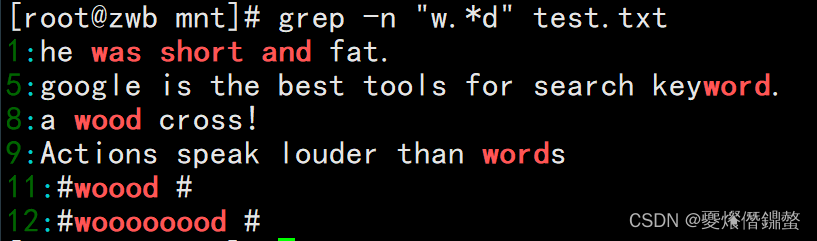
⑤ 查询以 w 开头 d 结尾,中间的字符可有可无的字符串
[[email protected] mnt]# grep -n "w.*d" test.txt
⑥查询任意数字所在行
[[email protected] mnt]# grep "[0-9][0-9]*" test.txt

8、查找连续字符范围“{}”
我们使用“.”与“*”来设定零个到无限多个重复的字符,If you want to limit a range of repeated strings,Use a range of characters from the underlying regular expression“{}”,因为“{}”在Shell中具有特殊意义,所以在使用“{}”字时,需要利用转义字符“\”,将“{}”字符转换成普通字符.
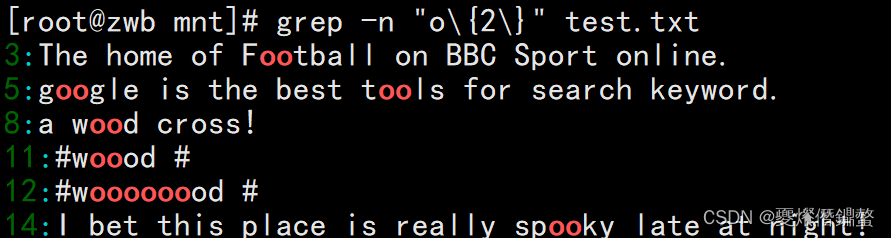
①查询两个 o 的字符
[[email protected] mnt]# grep -n "o\{2\}" test.txt
②查询以 w 开头以 d 结尾,中间包含 2~5 个 o 的字符串
[[email protected] mnt]# grep -n "wo\{2,5\}d" test.txt

③查询以 w 开头以 d 结尾,中间包含 2 以上 o 的字符串
[[email protected] mnt]# grep -n "wo\{2,\}d" test.txt

三、元字符汇总
| 元素符 | 作用(Need to express the original meaning of the symbol itself,It needs to be added before the symbol”\“) |
| ^ | "^"在[ ]Inside and outside have different meanings,Outside means that the content in parentheses is the beginning of the line,In it, it means that the reverse selection of the content in the brackets is the negation,要匹配“^” 字符本身,请使用“\^”. |
| $ | 匹配输入字符串的结尾位置,要匹配“$”字符本身,请使用“\$” |
| . | 匹配除“\r\n”之外的任何单个字符 |
| \ | 将下一个字符标记为特殊字符、原义字符、向后引用、八进制转义符.例如,‘n’匹配字符“n”. ‘\n’匹配换行符.序列‘\\’匹配“\”,而‘\(’则匹配“(” |
| * | 匹配前面的子表达式零次或多次.要匹配“*”字符,请使用“\*” |
| [] | 字符集合,匹配所包含的任意一个字符.例如,“[abc]”可以匹配“plain”中的“a” |
| [^] | Invert the contents of the square brackets. |
| [n1-n2] | 字符范围,匹配指定范围内的任意一个字符,n2>n1,范围为n1到n2Any character in the interval. |
| {} | n 是一个非负整数,匹配确定的 n 次. |
边栏推荐
- win10 uwp json
- LVS+NAT 负载均衡群集,NAT模式部署
- win10 uwp DataContext
- Switch node version and switch npm source tool
- VPC2187/8 current mode PWM controller 4-100VIN ultra-wide voltage startup, highly integrated power control chip recommended
- PHP代码审计9—代码执行漏洞
- Usage of collect_list in Scala105-Spark.sql
- Scala104-Spark.sql的内置日期时间函数
- ACP-Cloud Computing By Wakin自用笔记(1)云计算基础、虚拟化技术
- ”元宇宙“必须具备这些特点
猜你喜欢




随机推荐
运力升级助力算力流转,中国数字经济的加速时刻
vantui 组件 van-field 路由切换时,字体样式混乱问题
如何进行自动化测试?
”元宇宙“必须具备这些特点
手把手教你CSP系列之script-src
【最新资讯】2022下半年软考新增2个地区公布报名时间
当前最快的实例分割模型:YOLACT 和 YOLACT++
视频目标检测
win10 uwp xaml 绑定接口
机器学习之支持向量机实例,线性核函数 多项式核函数 RBF高斯核函数 sigmoid核函数
关于使用腾讯云HiFlow场景连接器每天提醒签到打卡
量化交易机器人系统开发
MMDetection 使用示例:从入门到出门
机器学习——线性回归
Finger Vein Recognition-matlab
直播回顾|7 月 Pulsar 中文开发者与用户组会议
Internship: changed the requirements
开篇-开启全新的.NET现代应用开发体验
gbase8s创建RANGE分片表
server