当前位置:网站首页>Introduction to deep learning (II) -- univariate linear regression
Introduction to deep learning (II) -- univariate linear regression
2022-07-03 05:07:00 【TT ya】
Beginner little rookie , I hope it's like taking notes and recording what I've learned , Also hope to help the same entry-level people , I hope the big guys can help correct it ~ Tort made delete .
One 、 The symbol States
- m: Represents the number of samples in the training set ;
- x: Represents the input variable ( Characteristic quantity ), Represents the characteristics of the input ;
- y: Represents the output variable ( Target variable ), That is our prediction ;
- (x,y): Represents a training sample ;
- (x(i),y(i)): To represent each training sample , We use x Superscript (i) and y Superscript (i) To express , It means the first one i Training samples ,i It's just an index , It means the number in the training set i That's ok , Not at all x and y Of i Power ;
- h:(hypothesis) Hypothesis function , Input x, Output y,h It is a slave. x To y Function mapping of .
Two 、 linear regression model (h(x))
The model formula of univariate linear regression :

3、 ... and 、 Cost function
In linear regression , We have a training set . What we need to do is get Ɵ0 and Ɵ1, Make the straight line represented by our hypothetical function fit these data points as much as possible . But how do we choose Ɵ0 and Ɵ1 Well ? Our idea is that choice can make h(x), That is input x Is the value of our prediction , Closest to the corresponding y Parameter of value Ɵ0 and Ɵ1.
Say abstractly : In linear regression problems , What we need to solve is a minimization problem , Write about Ɵ0 and Ɵ1 The minimization formula of , Give Way h(x) and y The difference between them is the smallest .
Cost function ( Squared error function ) The formula :
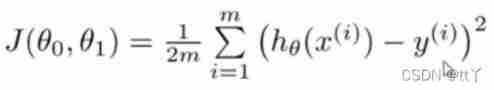
Without that 1/2, It's actually the variance formula , Combined with the 1/2 For the convenience of calculation
In this , Our goal translates into
![]()
How to get Ɵ0 and Ɵ1 Is the key
Four 、 gradient descent
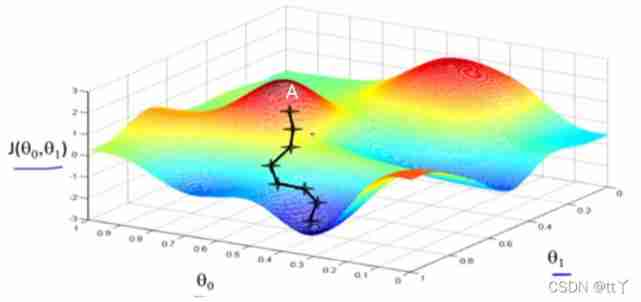
Let's take a look at the following figure for later understanding
If we want to start from A Point to find the fastest J Value reduction direction ( Direction of gradient descent ), It's like trying to get down the mountain as fast as possible , Then you can take the black path in the picture ( notes : Different starting points and different paths )
The specific formula
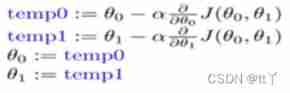
among := It's assignment ,α It's the learning rate ( That is, how far is it to walk down the mountain )
α If it's too small, it takes a long time to walk down the mountain ,α If it is too large, the gradient decline may cross the lowest point , It may not even converge
Gradient descent algorithm can not only minimize the linear regression function J, You can also minimize other functions .
It is not necessary to use gradient descent algorithm to minimize the cost function , There's another algorithm —— Normal equation method (normal equation method), But gradient descent algorithm is more suitable for large data sets .
For univariate linear regression , The idea applied here is the least square method .
边栏推荐
- appium1.22.x 版本后的 appium inspector 需单独安装
- Blog building tool recommendation (text book delivery)
- MPM model and ab pressure test
- 2022-02-11 daily clock in: problem fine brush
- leetcode452. Detonate the balloon with the minimum number of arrows
- Appium 1.22. L'Inspecteur appium après la version X doit être installé séparément
- Ueditor, FCKeditor, kindeditor editor vulnerability
- 编译GCC遇到的“pthread.h” not found问题
- [develop wechat applet local storage with uni app]
- leetcode860. Lemonade change
猜你喜欢
![[set theory] relationship properties (symmetry | symmetry examples | symmetry related theorems | antisymmetry | antisymmetry examples | antisymmetry theorems)](/img/34/d195752992f8955bc2a41b4ce751db.jpg)
[set theory] relationship properties (symmetry | symmetry examples | symmetry related theorems | antisymmetry | antisymmetry examples | antisymmetry theorems)
Overview of basic knowledge of C language
Prepare for 2022 and welcome the "golden three silver four". The "summary of Android intermediate and advanced interview questions in 2022" is fresh, so that your big factory interview can go smoothly
Basic knowledge of reflection (detailed explanation)
![[research materials] the fourth quarter report of the survey of Chinese small and micro entrepreneurs in 2021 - Download attached](/img/01/052928e7f20ca671cdc4c30ae55258.jpg)
[research materials] the fourth quarter report of the survey of Chinese small and micro entrepreneurs in 2021 - Download attached

JQ style, element operation, effect, filtering method and transformation, event object

leetcode406. Rebuild the queue based on height
Appium 1.22. L'Inspecteur appium après la version X doit être installé séparément

Online VR model display - 3D visual display solution

cookie session jwt
随机推荐
1118 birds in forest (25 points)
【实战项目】自主web服务器
Webapidom get page elements
Do you know UVs in modeling?
1094 the largest generation (25 points)
Actual combat 8051 drives 8-bit nixie tube
Distinguish between releases and snapshots in nexus private library
最大连续子段和(动态规划,递归,递推)
sql语句模糊查询遇到的问题
1107 social clusters (30 points)
Market status and development prospect prediction of the global fire extinguisher industry in 2022
Wechat applet waterfall flow and pull up to the bottom
String matching: find a substring in a string
Interface frequency limit access
Market status and development prospect forecast of global heat curing adhesive industry in 2022
[basic grammar] Snake game written in C language
Sprintf formatter abnormal exit problem
Oracle SQL table data loss
Notes | numpy-11 Array operation
MPM model and ab pressure test