当前位置:网站首页>How to simply implement the quantization and compression of the model based on the OpenVINO POT tool
How to simply implement the quantization and compression of the model based on the OpenVINO POT tool
2022-08-05 01:58:00 【Intel Edge Computing Community】
biweeklyNotebook系列
See you guys again!
We will introduce a different theme for each course
供大家学习讨论~
I hope you can find the joy of deep learning application development
用OpenVINOComplete more fulfilling moments.


The subject of this course is
如何基于OpenVINO POTThe tool is simple to realize the quantization and compression of the model
I hope that the little friends will be in the collision of thinking in the course learning
能与Nono中找到共鸣~
一、课程准备

see the course content,You may haveNono一样,A question popped into my head involuntarily,什么是int8 量化?

Improves the inference performance of the model in general,一般有两种途径.The first way is when the model is running,Use multi-threading and other technologies to achieve parallel acceleration and improve inference performance.Another is to compress our model file,通过量化、剪枝、Distillation and other techniques to compress the model space volume,Achieve less consumption of computing resources.OpenVINO的Post-training Optimization ToolIt is such a quantitative tool,It can convert the parameters of the model,从fp42The high precision floating point is mapped toint8low-precision fixed-point,thereby compressing the volume of the model,Get better performance.
Today's lesson sharing theme is,based on how to usePOT工具的simplify模式,To achieve the quantitative operation of the model.
二、Preliminary Operation Example
首先,import some regular libraries,Set relevant environment variables.The environment variables here are mainly the data sets we use and the file paths of the models.,并以其命名.

Next, you need to prepare the data set for verification.Since the model after quantization,Accuracy is bound to decrease,So we need to introduce the method of verifying the data set,Pull the model accuracy back to the level of the original accuracy,To achieve our model compression capability without loss of accuracy or too much loss.在这一步,我们会用到pytorchBuilt-in interface to downloadCIFAR这样一个数据集,This data is basically used to do some classification tasks,is a very famous dataset template.

下载完成以后,它会被保存在cifar路径下,But our original dataset is alreadybatchAfter the data set,So, in order to further to use or to occupy it,We need to restore it to the original image form.Here we will use anotherpytorch自带的接口——Python ToPILTImage,restore it to a sheetrgb格式图片,我们来运行一下.
可以看到,under another path,This image data has been generated,That's this onePNG格式的图片.

然后,We need to prepare the original model file,并对其进行压缩.Here is another onepytorch常用的接口,也就是通过pytorch预训练模型,and export it as onnxFormat of the model to achieve our download of the model file.Here we use theresnet20such a classified network,You can see that the model has been downloaded.

紧接着,我们需要调用mo工具.也就是说,通过model optimizertool to convert it intoOpenVINO所支持的IR中间表达式.After completion, you can see the modelmodelThe path has been successfully generatedxml和.bin的文件,也就是OpenVINO的模型格式.


三、Compress and quantize the model
The next step is the most critical step,Compress and quantize the model.
由于pot工具支持api接口调用以及 cmdThere are two ways to call the command line,为了方便演示,So we show here如何通过cmdcall it from the command line.
第一步,We need to specify the path to the input model.In the selection of the quantization compression method adopted this time,由于simplifiedmode compared to other quantization modes,配置简单,Considering the convenience of beginners to get started quicklypot工具,We have adopted heresimplifiedmode to demonstrate it.

第二步,to define the path to the dataset used for validation,and the path to the final generated model.
第三步,我们来跑一下这个pot工具.Due to the need to traverse300多数据,So the running time will be a little longer.在等待过程中,Let's take a look at the originalfp32model size,可以看到它的xmlThat is, the file of the model extension valley structure is70KB,它的.binThat is, the weight file,是1mb左右.


▲点击可查看大图
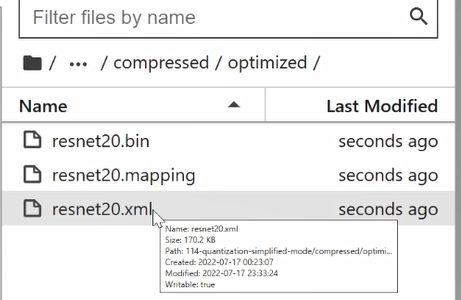
Wait until the model is successfully quantified,大家可以发现,在、under the new directory,已经生成了compressed路径.compressedThe path is punctuated with a new folder calledoptimized,That is, we store the model path after quantization.
最后,我们看一下这个.bin文件的体积.可以看到int8The weights file for the model has been minified to274k,xmlThe file has not changed significantly.The overall model volume is compressed by nearly3/4,这也是 potPresentation of tool capabilities.

▲点击可查看大图
四、性能验证
The next step is the most critical step,Compress and quantify the model
After the model file is compressed,Will its performance change??接下来就让我们通过 benchmark app这个性能测试工具,Further comparison of model performance.
Let's specify the time of its loop,将其设置成15秒,我们用benchmark apptest it15run performance in seconds.The first command is to convert this rawfp32model to run its performance metrics,The second is that we through after the compressionint8Model to run its performance indicators.

可以看到 fp32The final throughput obtained by the model is approximately1000fps左右,int8The throughput of the model has nearly doubled,达到了1630fps,It has to be said that the performance improvement is still very intuitive..


▲点击可查看大图
After the performance is improved,Will the accuracy be affected??Next we do a simple experiment,把 int8The model of running the reasoning tasks,See if its final output is correct.
The first step is also routine,去定义core的对象,Prepare some environment variables and label data,Prepare some more image visualization methods.We need to put the label in the originallabel标签,Draw on our image for a comparison.
接下来,is to define each image to doinference的任务了.We will traverse them one by one300张图片,and then do it separatelyinference,接着会把inferenceThe label of the final result is also the output of the classification to it allappend到一个list里去, 这个listwe'll do a comparison.
好,我们首先来看一下,After we obtain the final inference result,We go to query the results of the reasoning in the first three chapters and our original three chapterslabel的一个比较.

显然,You can see that our reasoning in the first three chapters iscat,ship和ship.

Since we are in random order,So see the original label也是cat,ship,ship,It can be said that the final result is consistent with that of the original labeled image,This further proves that there is not much loss in model accuracy after quantization,In other words, its accuracy is always equal to the model accuracy before the original model quantization.
边栏推荐
猜你喜欢






随机推荐
Short domain name bypass and xss related knowledge
蓝牙Mesh系统开发四 ble mesh网关节点管理
如何发现一个有价值的 GameFi?
[parameters of PyQT5 binding functions]
VOC格式数据集转COCO格式数据集
4. PCIe interface timing
Log an error encountered when compiling google gn "I could not find a ".gn" file ..."
高数_复习_第1章:函数、极限、连续
手把手基于YOLOv5定制实现FacePose之《YOLO结构解读、YOLO数据格式转换、YOLO过程修改》
刷爆朋友圈,Alibaba出品亿级并发设计速成笔记太香了
source program in assembly language
IJCAI2022 | DictBert:采用对比学习的字典描述知识增强的预训练语言模型
【TA-霜狼_may-《百人计划》】图形4.3 实时阴影介绍
How to create an rpm package
为什么他们选择和AI恋爱?
详细全面的postman接口测试实战教程
PHP技能评测
DDOS攻击真的是无解吗?不!
基于OpenVINO工具套件简单实现YOLOv7预训练模型的部署
"Configuration" is a double-edged sword, it will take you to understand various configuration methods