当前位置:网站首页>Reinforcement learning series (I): basic principles and concepts
Reinforcement learning series (I): basic principles and concepts
2022-07-06 13:41:00 【zhugby】
Catalog
One 、 What is reinforcement learning ?
Two 、 Structure of reinforcement learning
3)Q And V Transformation between
3)Q Value update —— Behrman formula
Four 、 The characteristics of reinforcement learning
5、 ... and 、 The advantages of reinforcement learning
One 、 What is reinforcement learning ?
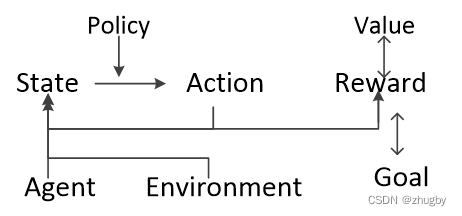
In recent years, intensive learning has been very popular in academia , Presumably everyone has heard this term more or less . What is reinforcement learning ? Reinforcement learning is a branch of machine learning , refer to agent In the process of interaction with the environment, the learning process to achieve a goal . With TSP The question is :agent It's a travel agent , He observes the environment environment change ( Geographical location map of the customer point to visit ) According to the current situation state( That is, where you are now ) To make a action( The next node location to access ), Every time you make one action,environment Will change ,agent Will get a new state, Then choose the new action Keep implementing . In the current state choice action On the basis of Policy, For each action Assign the probability of choice . Generally speaking TSP The goal of the problem is to minimize the path distance , that reward It can be set as a negative number of the distance between two nodes , The purpose of the training goal Is to make the path total reward And the biggest .
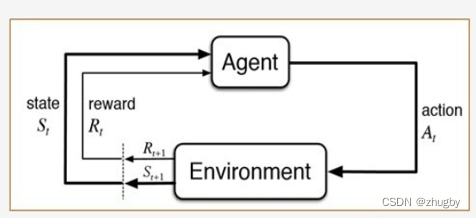
Two 、 Structure of reinforcement learning
Let's briefly sort out the basic elements and relationships of reinforcement learning , Change the common figure above , The structure of reinforcement learning is divided into three layers as follows :
first floor :
agent: The subject of the action
environment: Strengthen the learning environment
goal: The goal of strengthening learning
Reinforcement learning is agent In the process of interaction with the environment, the learning process to achieve a goal .
The second floor :
state: At present agent The state of
action: The action performed / Behavior
reward: Real time rewards for performing actions
state and action The cyclic process of reinforcement learning constitutes the main part of reinforcement learning .
It should be noted that :reward And goal It's not the same concept ,reward It is a real-time reward obtained after performing a certain action ,goal Is the ultimate goal of reinforcement learning ( Generally speaking, make reward The sum is the greatest ), but goal To determine the reward.
The third level :
It is also the core element , Including two functions , Value function (Value function) And policy functions (Policy function). The next section details .
3、 ... and 、 Value function
1)Policy function:
Policy Decide a state Which one should be selected action, in other words , In the state of Policy The input of ,action yes Policy Output . Strategy Policy Assign probability to each action , for example :π(s1|a1) = 0.3, Description in status s1 Next, choose the action a1 Is the probability that 0.3, And the strategy only depends on the current state , State independent of previous time , Therefore, the whole process is also a Markov decision-making process . The core and training goal of reinforcement learning is to choose an appropriate Policy/ , bring reward The sum of the
, bring reward The sum of the  Maximum .
Maximum .
2)Value function:
There are two kinds of value functions , One is V State value function (state value function), One is Q State action function (state action value function).Q Value evaluates the value of action , representative agent The expected value of the total reward after doing this action until the final state ;V Value evaluates the value of the state , representative agent The expectation of the total reward from this state to the final state . The higher the value , Indicates that I am from current state To A final state Available Average reward Will be higher , So I choose the action with high value .
Generally speaking , State value function V It is defined for specific policies , Because the expectation of calculating the reward depends on choosing each action Probability . State action function V On the surface, it is related to strategy policy It doesn't matter , It depends on the probability of state transition , But in reinforcement learning, the state transition function is generally unchanged . it is to be noted that ,Q Values and V Values can be converted to each other .
3)Q And V Transformation between
A state of V value , It's all the actions in this state Q Values in Policy The next expectation , Expressed as :
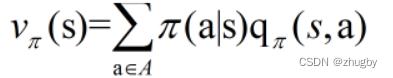
One action Q value , It is the new state transferred after the action is executed  Of V Value expectations plus real-time reward value . Expressed as :
Of V Value expectations plus real-time reward value . Expressed as :
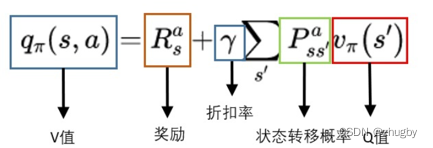
To sum up , state S The value of is the child node action action Of Q Value expectation ; action act The value of is the child node state S Of V Value expectation . Different strategies Policy Next , Calculated expectations Q、V It's different , Therefore, it can be evaluated through the value function Policy The quality of the .
3)Q Value update —— Behrman formula
The process of reinforcement learning is to constantly update the value Q The process of , That is, Behrman formula :
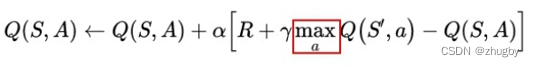
among ![]() It stands for Q Realistic value of ;γ yes Discount factor , be located [0,1) Between , Indicates the degree of foresight of the model ,γ The smaller it is , It means the present reward More important than the future ;
It stands for Q Realistic value of ;γ yes Discount factor , be located [0,1) Between , Indicates the degree of foresight of the model ,γ The smaller it is , It means the present reward More important than the future ; It's the learning rate ;
It's the learning rate ;![]() yes Q The estimate of ;Q Update equals Q Estimate plus learning rate Multiply by the difference between the real value and the estimated value .
yes Q The estimate of ;Q Update equals Q Estimate plus learning rate Multiply by the difference between the real value and the estimated value .
Four 、 The characteristics of reinforcement learning :
1.trial and error( Trial and error learning )
Learn from trial and error , Give higher rewards to good behavior .
2.delayed reward( Delay reward )
choice action When , It's not real-time reward value , Instead, consider the expected value of the total reward from the action to the final state Q, choice Q The most valuable action .
5、 ... and 、 The advantages of reinforcement learning :
1. Modeling is difficult 、 The problem of inaccurate modeling ,RL Can pass Agent Continuous interaction with the environment , Learn the optimal strategy ;
2. Traditional methods are difficult to solve high-dimensional problems ,RL It provides approximation algorithms including value function approximation and direct strategy search ;
3. It is difficult to solve dynamic and random problems ,RL Can be found in Agent Random factors are added in the process of interaction with the environment and state transition ;
4. Compared with supervised learning , Overcome the constraint that requires a large number of annotation data sets , Fast solution speed , Suitable for solving real large-scale problems ;
5. Transferable learning , Strong generalization ability , It is robust to unknowns and disturbances .
about OR Field , Many combinatorial optimization problems (TSP、VRP、MVC etc. ) Can become a sequential decision / Markov decision problem , And reinforcement learning “ Action selection ” Have characteristics similar to natural movements , And RL Of “ Offline training , Online solution ” It makes online and real-time solution of combinatorial optimization possible . In recent years, many new methods of reinforcement learning to solve combinatorial optimization problems have emerged , It provides a new perspective for the research of operational research optimization , Has become a OR A major research hotspot in the field .
Limited by my limited level , The above content is looking through the literature 、 You know 、B After the video station, summarize and summarize according to your own understanding , Welcome to point out the mistakes !
边栏推荐
- JS interview questions (I)
- Zatan 0516
- MySQL中count(*)的实现方式
- MySQL锁总结(全面简洁 + 图文详解)
- [the Nine Yang Manual] 2020 Fudan University Applied Statistics real problem + analysis
- FAQs and answers to the imitation Niuke technology blog project (I)
- [during the interview] - how can I explain the mechanism of TCP to achieve reliable transmission
- [modern Chinese history] Chapter V test
- Have you encountered ABA problems? Let's talk about the following in detail, how to avoid ABA problems
- 7.数组、指针和数组的关系
猜你喜欢
(original) make an electronic clock with LCD1602 display to display the current time on the LCD. The display format is "hour: minute: Second: second". There are four function keys K1 ~ K4, and the fun
Wei Pai: the product is applauded, but why is the sales volume still frustrated

8.C语言——位操作符与位移操作符

6. Function recursion

优先队列PriorityQueue (大根堆/小根堆/TopK问题)

5. Download and use of MSDN
The latest tank battle 2022 - Notes on the whole development -2
A comprehensive summary of MySQL transactions and implementation principles, and no longer have to worry about interviews
强化学习系列(一):基本原理和概念
8. C language - bit operator and displacement operator
随机推荐
重载和重写的区别
Mode 1 two-way serial communication is adopted between machine a and machine B, and the specific requirements are as follows: (1) the K1 key of machine a can control the ledi of machine B to turn on a
自定义RPC项目——常见问题及详解(注册中心)
C语言入门指南
简述xhr -xhr的基本使用
Differences among fianl, finally, and finalize
[the Nine Yang Manual] 2017 Fudan University Applied Statistics real problem + analysis
[graduation season · advanced technology Er] goodbye, my student days
3.C语言用代数余子式计算行列式
This time, thoroughly understand the MySQL index
PriorityQueue (large root heap / small root heap /topk problem)
使用Spacedesk实现局域网内任意设备作为电脑拓展屏
MPLS experiment
Floating point comparison, CMP, tabulation ideas
Zatan 0516
[面試時]——我如何講清楚TCP實現可靠傳輸的機制
JS interview questions (I)
vector
6.函数的递归
受检异常和非受检异常的区别和理解