当前位置:网站首页>A comprehensive summary of MySQL transactions and implementation principles, and no longer have to worry about interviews
A comprehensive summary of MySQL transactions and implementation principles, and no longer have to worry about interviews
2022-07-06 13:36:00 【Li bohuan】
One . Business transanction The four basic elements of
Simply speaking , Transaction is to ensure a set of database operations , All or nothing , All or nothing , It has the following four basic elements .
ACID: Atomicity (Atomicity)、
Uniformity (Correspondence)、
Isolation, (Isolation)、
persistence (Durability)
1、 Atomicity : All operations after the transaction begins , Or all of them , Or not at all , It's impossible to stay in the middle . If an error occurs during the execution of a transaction , Transaction will be rolled back (Rollback) Status to the beginning of the transaction ;
2、 Uniformity : Before and after the transaction starts , The database integrity constraint is not broken . such as A towards B Transfer accounts , impossible A The money was withheld ,B But I didn't receive the transfer . Ensure that the final reality logic is consistent with the data after database operation
3、 Isolation, : The isolation of transactions means that concurrent transactions are isolated from each other . That is, the internal operation of a transaction and the data being operated must be blocked , Not seen by other transactions attempting to modify .
4、 persistence : After the transaction completes , All updates of the transaction to the database will be saved , No rollback .
Consistency is the ultimate goal of a transaction , Atomicity 、 Isolation, 、 Persistence is all about consistency !! The execution process of the transaction is shown in the following figure : The relevant logs and the execution process will be explained in detail below
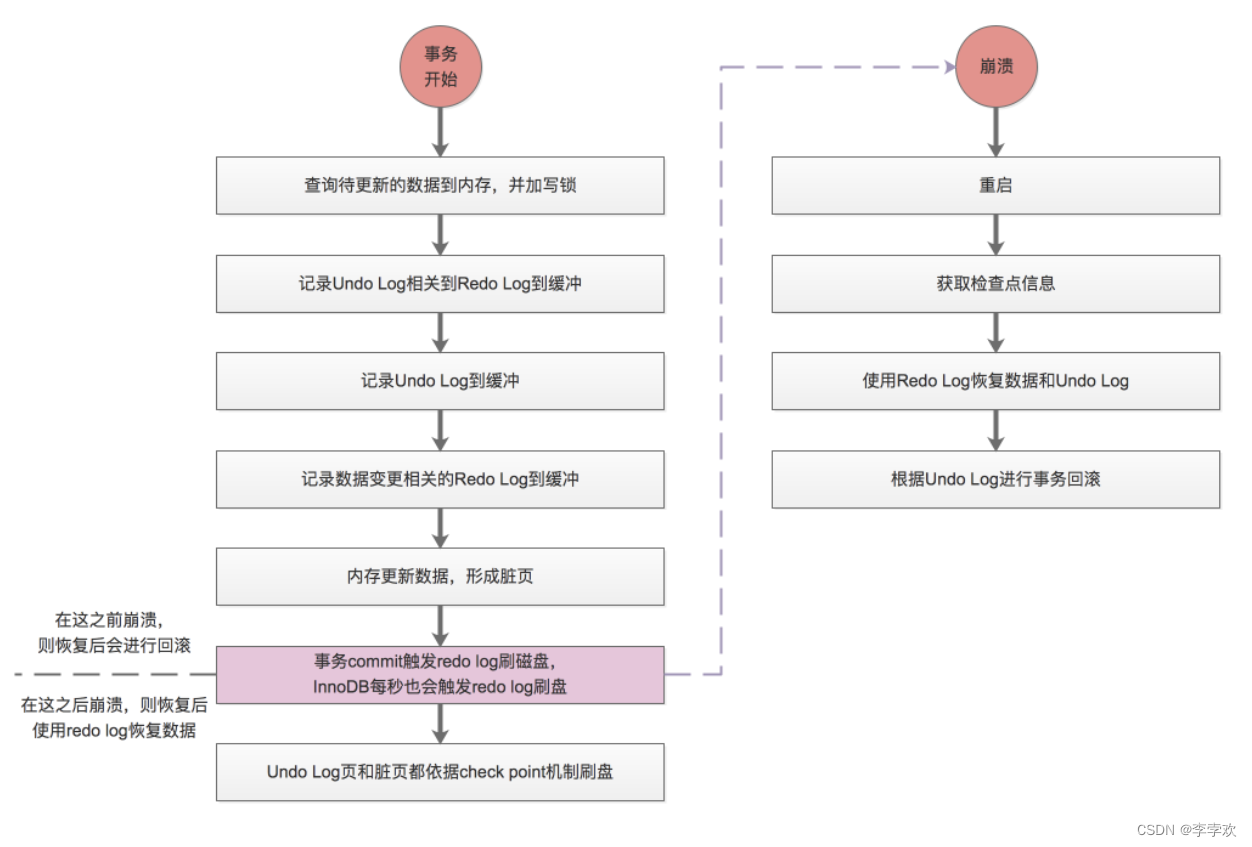
Two . Atomicity
Before understanding the principle of atomicity , Let's get to know MySQL Of WAL technology ,WAL Its full name is Write-Ahead Logging, Pre write log system . It mainly refers to MySQL When performing a write operation, it is not immediately updated to the disk , But first record it in the log , And update memory , Then update the system to disk when it is idle . Logs are mainly divided into undo log、redo log、binlog.
The realization of atomicity mainly depends on Undo log journal . Atomicity is mainly embodied in sql Rollback occurs when an error occurs during execution . Rollback is to return to a state before execution , So how to return to the state before execution ? Do we have to record the status before execution .Undo log It is a log to realize this function .
This rollback log Undo log, The record is very simple :
- For example, if you execute a insert sentence , So at this time undo log The primary key of the inserted data must be recorded ID, When rolling back, you can delete this data from the cache page ;
- If a delete sentence , that undo log The deleted data must be recorded , When rolling back, you have to reinsert a piece of data
- If a update sentence , Then at least record the value before the update , When rolling back update once , Update the old value that was updated before .
- If a select sentence , Because there is no change buffer pool, So you don't need any undo log.
Redo log Used to record the modified value of a data block , Can be used to recover unwritten data file Data updated by the successful transaction of ;Undo log Is used to record the value before data update , Ensure that the data update fails and can be rolled back .
3、 ... and . persistence
We need to get to know InnoDB How to read and write data . We know that the data in the database is stored on disk , But disk I/O The cost is very high , If you have to access the disk every time you read or write data , The efficiency of the database will be very low . To solve this problem ,InnoDB Provides Buffer Pool As a buffer for accessing database data .
Buffer Pool It's in memory , Contains the mapping of some data pages in the disk . When you need to read data ,InnoDB Will first try from Buffer Pool Read from , If it cannot be read, it will be read from the disk and put in Buffer Pool; When writing data , Will first write Buffer Pool The page of , And mark such pages as dirty, And put it in a special flush list On , These modified data pages will be flushed to disk at a later time ( This process is called brushing , Other background threads are responsible for ) .
Through the previous introduction , We know InnoDB Use Buffer Pool To improve the performance of reading and writing . however Buffer Pool It's in memory , It's volatile , If a transaction has committed the transaction ,MySQL Sudden downtime , And now Buffer Pool If the modified data in has not been refreshed to the disk , This results in the loss of data , The persistence of a transaction cannot be guaranteed . To solve this problem ,InnoDB Introduced redo log To realize the persistence of data modification . According to what we introduced above WAL Mechanism , Write the log , Write the disk again , With redo log,InnoDB It can guarantee that even if the database is restarted abnormally , No records submitted before will be lost , This Ability is called crash-safe.
redo log It's made up of two parts : One is redo log buffer in memory (redo log buffer); Second, redo log files for persistence (redo log file). Our data was originally in memory , When we commit a transaction ,redo log There are three ways to submit , To write the data in memory to disk , These three methods can be set
- Write from user space to log space , Then write from the log space to the operating system memory every second , And then call fsync() Write to disk ( No loss of data , Low efficiency )
- Write from memory space to operating system memory , And then call fsync() Write directly to disk ( Highest efficiency , Some data will be lost )
- Write from memory space to operating system memory , And then call... Every second fsync() Write directly to disk ( No loss of data , Low efficiency )
When the transaction is submitted , write in redo log There are three main advantages over direct brushing :
- Brush dirty is random I/O, But to write redo log In sequence I/O, The order I/O Than random I/O fast .
- Scrubbing is a data page (Page) Unit , Even if one Page Only a few changes need to be written on the whole page ; and redo log It contains only the parts that are actually modified , The amount of data is very small , Invalid IO Greatly reduce .
- When you brush dirty, you may have to brush many pages of data , There is no guarantee of atomicity ( For example, writing only part of the data failed ), and redo log buffer towards redo log file Write log block, Is in accordance with the 512 Bytes , That is, the size of a sector to write to , The sector is the smallest unit of writing , Therefore, it can be guaranteed that the writing will be successful .
Four . Isolation,
Finally, let's take a look at the isolation that is most asked in the interview . When there are multiple transactions in the database executing at the same time , There may be dirty reading (dirty read)、 It can't be read repeatedly (non- repeatable read)、 Fantasy reading (phantomread) The problem of , To solve these problems , And then there is “ Isolation level ” The concept of .
- Dirty reading : If a transaction A Changes have been made to the data , But it hasn't been submitted yet , And another thing B You can read the transaction A Uncommitted update results . such , When a transaction A When rolling back , The transaction B The data read at the beginning is a dirty data .
- It can't be read repeatedly : The same transaction pair The same Read data , The results read are different . for example , Business B In the transaction A Data read before the update operation of , Follow the business A Data read after submitting this update operation , It may be different .
- Fantasy reading : That is, one transaction reads the newly added and submitted data of another transaction (insert). In the same transaction , about The same group The results read by the data are inconsistent . such as , Business A A new record has been added , Business B stay Business A A query operation was performed before and after the submission , I found that the last one had one more record than the previous one . The reason why unreal reading occurs is due to the concurrency of transactions and the addition of new records .
Unrepeatable reading and unreal reading are easily confused , Unrepeatable reading focuses on revision , Unreal reading focuses on deleting or adding !!
Let's look at the isolation level to solve these problems . The first thing to know is , The tighter the isolation , The less efficient . So many times , We all want to Find a balance between the two .SQL Standard transaction isolation levels include : Read uncommitted (read uncommitted)、 Read the submission (read committed)、 Repeatable (repeatable read) And serialization (serializable ). The specific explanation is as follows :
- Read uncommitted means , When a transaction has not yet been committed , The changes it makes can be seen by other things .
- Read submitted means , After a transaction is committed , The changes it makes will be seen by other things .
- Repeatable reading means , Data seen during the execution of a transaction , Always with this business Data seen at startup It's one To . Of course, at the level of repeatable read isolation , Uncommitted changes are also invisible to other transactions .
- Serialization , As the name suggests, for the same line of records ,“ Write ” Will add “ Write lock ”,“ read ” Will add “ Read the lock ”. When a read-write lock conflict occurs When , Subsequent transactions must wait for the previous transaction to complete , In order to proceed .
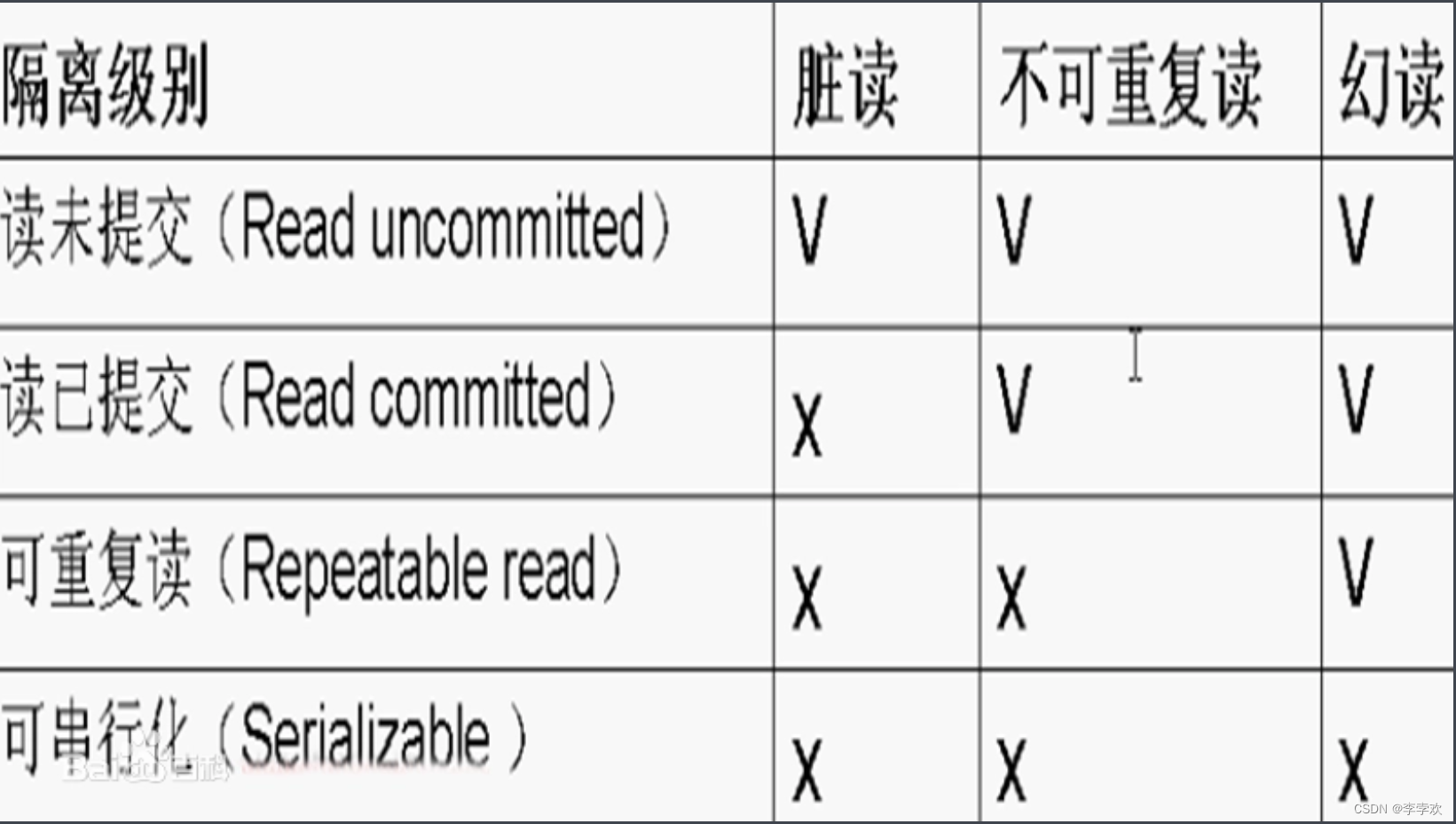
Database isolation By locking and MVCC To achieve . You can see from above , The isolation level of repeatable reading will cause unreal reading , and MySQL The default isolation level of is repeatable read , And solve the problem of unreal reading . Simply speaking ,MySQL The default isolation level of resolves dirty read 、 Fantasy reading 、 Non repeatable problems . Let's first look at the database concurrency scenarios
There are three scenarios for database concurrency , Respectively :
- read - read : There is no problem , There is no need for concurrency control
- read - Write : There are thread safety issues , May cause transaction isolation problems , May encounter dirty reading , Fantasy reading , It can't be read repeatedly
- Write - Write : There are thread safety issues , There may be a loss of updates , For example, the first type of update is missing , The second type of update is missing
Write - Thread safety of write operations is achieved by locking , For details, please see an article I summarized before :MySQL Lock summary ( Comprehensive and concise + Graphic, )_ Li bohuan's blog -CSDN Blog . But the operation of locking will seriously affect the performance and concurrency of the database , So it's happening MVCC--- Multi version concurrency control .MVCC It's a solution to reading - No lock concurrency control for write conflicts ,MVCC Implementation in database , Is to solve the problem of reading ( Read the snapshot ) Write conflict , Its implementation principle mainly depends on the 3 Implicit fields ,undo journal ,Read View To achieve .MVCC You can solve the following problems for the database :
- When reading and writing database concurrently , You can read without blocking the write operation , Write operations do not block read operations , Improve the performance of database concurrent read and write
- At the same time, it can also solve the problem of dirty reading , Fantasy reading , Non repeatable read and other transaction isolation issues , But it can't solve the problem of missing updates
Let's take a look at MVCC The concrete implementation principle of , Reference resources : Ali P7 Is the requirement so low ? Brother, tell you what is MySQL Of MVCC_ Bili, Bili _bilibili
What is current read and snapshot read ?
- The current reading
image select lock in share mode( Shared lock ),select for update;update,insert,delete( Exclusive lock ) These operations are all a current read . It reads the latest version of the record , When reading, ensure that other concurrent transactions cannot modify the current record , Will lock the read record .
- Read the snapshot
Like unlocked select Operation is snapshot reading , Non blocking read without lock ; The premise of snapshot read is that isolation level is not serial level , Snapshot reads at the serial level degrade to current reads ; The reason why snapshot reading occurs , It is based on the consideration of improving concurrent performance , The implementation of snapshot read is based on multi version concurrency control , namely MVCC, It can be said that MVCC It's a variant of a line lock , But it's in many cases , Avoid lock operation , Lower the cost ; Since it's based on multiple versions , That is to say, what the snapshot read may not be the latest version of the data , It could be the previous version of history
Implicit fields
In addition to our custom fields, each line of records , And the database is implicitly defined DB_TRX_ID,DB_ROLL_PTR,DB_ROW_ID Etc
- DB_TRX_ID
6byte, Recently revised ( modify / Insert ) Business ID( Self increasing ): Record create this record / The transaction that last modified the record ID - DB_ROLL_PTR
7byte, rollback pointer , Point to the previous version of this record ( Store in rollback segment in ) - DB_ROW_ID
6byte, Implied self increasing ID( Hide primary key ), If the data table has no primary key ,InnoDB Will automatically use DB_ROW_ID Generate a clustered index
 Pictured above ,DB_ROW_ID Is the only implicit primary key generated by the database for this row by default ,DB_TRX_ID Is the transaction currently operating the record ID, and DB_ROLL_PTR It's a rollback pointer , Used for coordination undo journal , Point to the previous old version .
Pictured above ,DB_ROW_ID Is the only implicit primary key generated by the database for this row by default ,DB_TRX_ID Is the transaction currently operating the record ID, and DB_ROLL_PTR It's a rollback pointer , Used for coordination undo journal , Point to the previous old version .
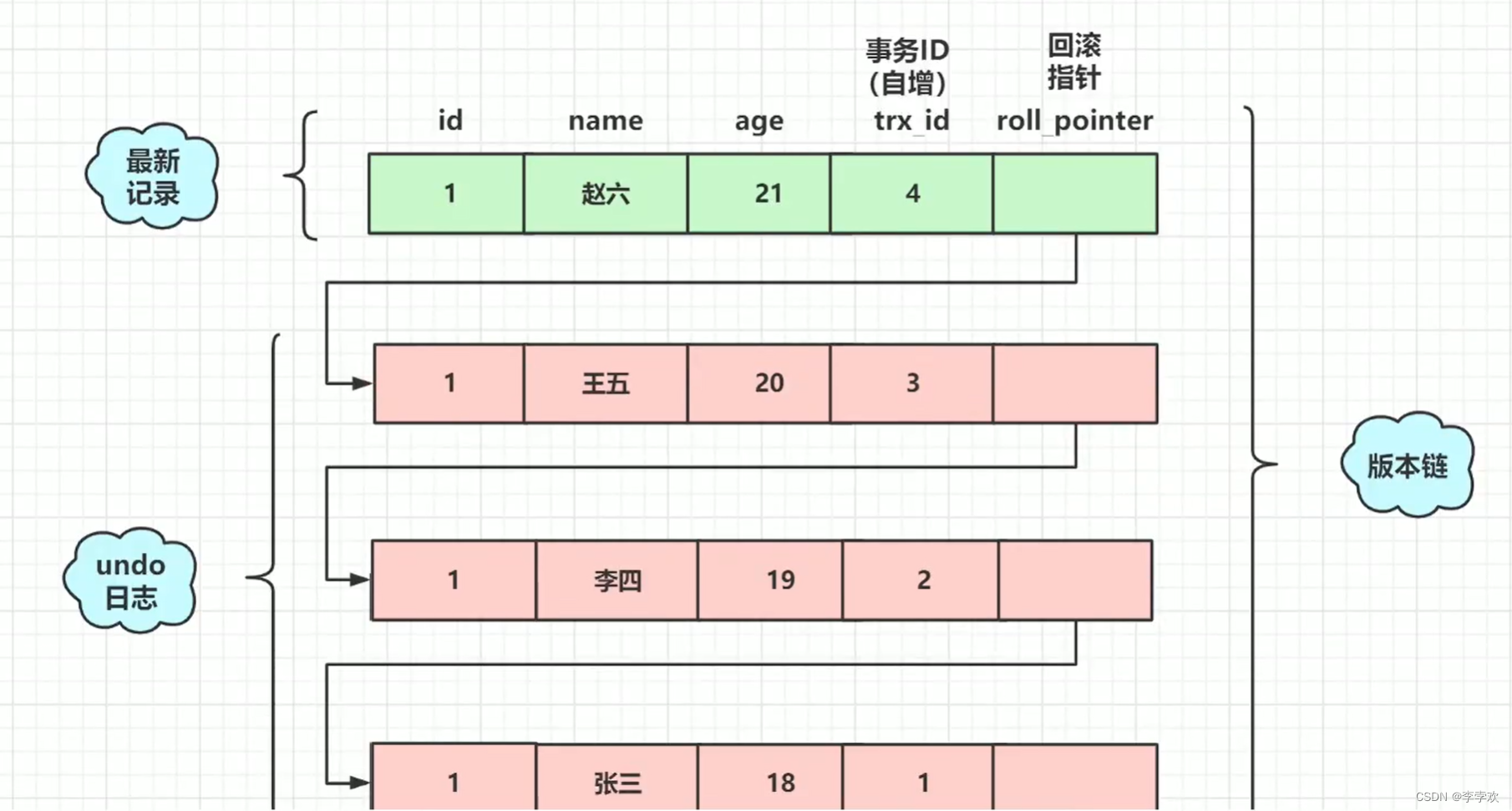
As shown above ,undo log And rollback pointer connect the latest record and history to form a version chain . So which version do I choose when I read data ? This is about to use read view Come to decide .
 read view It consists of the following four parts . The so-called active affairs ID Just not yet commit The business of id. that readview How to judge ? As shown in the figure below :
read view It consists of the following four parts . The so-called active affairs ID Just not yet commit The business of id. that readview How to judge ? As shown in the figure below :

there trx_id Is the transaction of each version id, As shown in the previous figure , Zhang San's trx_id by 1, Li Si's is 2.
- The first case shows , The current record is created by myself , Of course, you can read .
- The second situation is trx_id Less than the smallest active transaction id,min_trx_id, That explains. trx_id Is already commit 了 , Then the data can be accessed .
- The third case is if trx_id > max_trx_id, Cannot read , Because it has exceeded the version chain .
- The fourth situation , If trx_id stay min and max Between , It depends on trx_id Is it in m_ids in , If in , No access to , Because there is not yet commit.
I understand MVCC Principle , Let's see RC and RR How to get through MVCC Realized
RC、RR Below the level of InnoDB What's the difference between snapshot reading ?
It is Read View The timing of generation is different , As a result RC、RR The result of snapshot reading at level is different .
- stay RR The first snapshot read of a record by a transaction under level creates a snapshot and Read View, Record other active transactions in the current system , After that, when calling snapshot read , Or the same Read View, So as long as the current transaction has used snapshot read before other transactions commit updates , Then all subsequent snapshot reads use the same Read View, So it's not visible for later changes ;
- namely RR Below grade , Snapshot read generation Read View when ,Read View A snapshot of all other active transactions at this time is recorded , Changes to these transactions are invisible to the current transaction . And earlier than Read View The changes made by the created office are visible
- And in the RC Below the level of , Transaction , Each snapshot read generates a new snapshot and Read View, This is where we are RC You can see the reasons for the updates committed by other transactions in the transactions below the transaction level
All in all RC Under isolation level , yes Each snapshot read generates and gets the latest Read View; And in the RR Under isolation level , In the same transaction The first snapshot read will be created Read View, The subsequent snapshot reads all capture the same Read View, This also solves the phantom reading problem of snapshot reading . The current unreal reading problem is solved by gap lock .
边栏推荐
- Set container
- Questions and answers of "basic experiment" in the first semester of the 22nd academic year of Xi'an University of Electronic Science and technology
- 12 excel charts and arrays
- Data manipulation language (DML)
- Tyut Taiyuan University of technology 2022 introduction to software engineering summary
- System design learning (III) design Amazon's sales rank by category feature
- 学编程的八大电脑操作,总有一款你不会
- 六种集合的遍历方式总结(List Set Map Queue Deque Stack)
- The latest tank battle 2022 - Notes on the whole development -2
- 2.C语言矩阵乘法
猜你喜欢
Cookie和Session的区别
5.函数递归练习

1.C语言初阶练习题(1)
Alibaba cloud microservices (II) distributed service configuration center and Nacos usage scenarios and implementation introduction
Common method signatures and meanings of Iterable, collection and list
MySQL锁总结(全面简洁 + 图文详解)
Service ability of Hongmeng harmonyos learning notes to realize cross end communication
4.分支语句和循环语句

8.C语言——位操作符与位移操作符
12 excel charts and arrays
随机推荐
The latest tank battle 2022 - Notes on the whole development -2
[the Nine Yang Manual] 2017 Fudan University Applied Statistics real problem + analysis
MySQL事务及实现原理全面总结,再也不用担心面试
【毕业季·进击的技术er】再见了,我的学生时代
E-R graph to relational model of the 2022 database of tyut Taiyuan University of Technology
仿牛客技术博客项目常见问题及解答(一)
9. Pointer (upper)
[the Nine Yang Manual] 2019 Fudan University Applied Statistics real problem + analysis
View UI plus released version 1.3.1 to enhance the experience of typescript
ArrayList的自动扩容机制实现原理
西安电子科技大学22学年上学期《射频电路基础》试题及答案
【话题终结者】
Rich Shenzhen people and renting Shenzhen people
View UI plus releases version 1.1.0, supports SSR, supports nuxt, and adds TS declaration files
View UI Plus 发布 1.1.0 版本,支持 SSR、支持 Nuxt、增加 TS 声明文件
arduino+DS18B20温度传感器(蜂鸣器报警)+LCD1602显示(IIC驱动)
Set container
[中国近代史] 第九章测验
Differences and application scenarios between MySQL index clock B-tree, b+tree and hash indexes
5月27日杂谈