当前位置:网站首页>[basis of recommendation system] sampling and construction of positive and negative samples
[basis of recommendation system] sampling and construction of positive and negative samples
2022-07-07 23:58:00 【Evening scenery at the top of the mountain】
List of articles
- One 、 review word2vec Negative sampling in
- Two 、word2vec Implementation of negative sampling in
- 3、 ... and 、 Recommend recall related basis in the system
- Four 、 Recommend negative sampling in the system
- 4.1 Negative sample constructed 6 A common way
- (1) Expose non clicked data
- (2) Global random selection negative example
- (3)Batch Negative cases were randomly selected within the
- (4) Negative examples are randomly selected from the exposure data
- (5) be based on Popularity Negative cases were randomly selected
- (6) be based on Hard Select negative example
- Reference
One 、 review word2vec Negative sampling in
- word2vec Negative sampling in :CBOW perhaps skip-gram The training of this kind of model , When thesaurus scale is large and computing resources are limited , This kind of multi classification model will be because of the output layer (softmax) The effect of normalization of probability on calculation efficiency , To avoid training turtle speed .
- Negative sampling provides another angle : Given the current word and context , The task is to maximize the co-occurrence probability of the two .
The multi classification problem is also simplified to : in the light of (w, c) The dichotomous problem of ( Co-occurrence or No co-occurrence ), Thus, the normalization complexity on the large word list is avoided .
Such as P ( D = 1 ∣ w , c ) P(D=1 \mid w, c) P(D=1∣w,c) Express c and w The probability of co-occurrence P ( D = 1 ∣ w , c ) = σ ( v w ⋅ v c ′ ) P(D=1 \mid w, c)=\sigma\left(v_{w} \cdot v_{c}^{\prime}\right) P(D=1∣w,c)=σ(vw⋅vc′)
1.1 The sliding window
In order to get the high quality of each word embedding( Of words in similar contexts vector Should be similar ),word2vec Is sliding through a sliding window , Calculate at the same time P ( w t + j ∣ w t ) P\left(w_{t+j} \mid w_{t}\right) P(wt+j∣wt). Here is a chestnut ,window_size=2.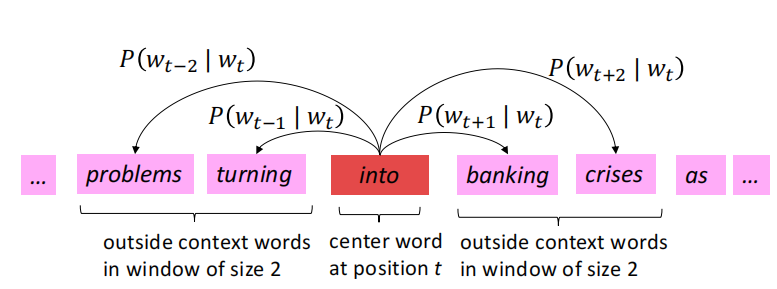
1.2 Objective function
(1) At the beginning, we will take the lump we just got P ( w t + j ∣ w t ) P\left(w_{t+j} \mid w_{t}\right) P(wt+j∣wt) Multiply , And for every t, So there is 2 A tired ride :
(2) Because generally we minimize the objective function , So we took log And negative average operation , Modified objective function :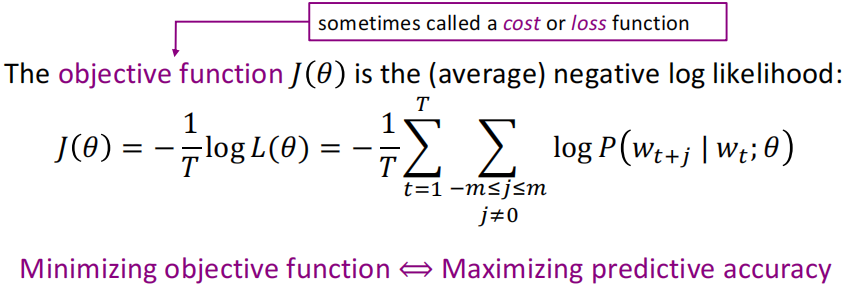
In order to find the innermost probability of the above loss function P ( w t + j ∣ w t ; θ ) P\left(w_{t+j} \mid w_{t} ; \theta\right) P(wt+j∣wt;θ), Use... For each word 2 individual vector Express :
- When w When is the central word , Expressed as v w v_w vw
- When w When it is a contextual word , Expressed as u w u_w uw
But why use two vector For each word —— More easily optimization.
1.3 Prediction function
So for a central word c And a context c Yes : P ( o ∣ c ) = exp ( u o T v c ) ∑ w ∈ V exp ( u w T v c ) P(o \mid c)=\frac{\exp \left(u_{o}^{T} v_{c}\right)}{\sum_{w \in V} \exp \left(u_{w}^{T} v_{c}\right)} P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc) Set any value x i x_i xi Map to the probability distribution , That is to say :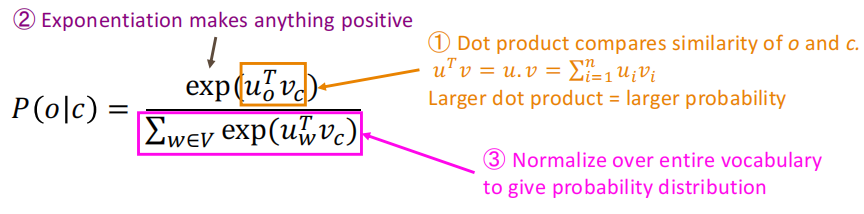
The dot product of molecules is used to represent o and c Degree of similarity between , The denominator is based on the whole vocabulary , The normalized probability distribution is given .
Two 、word2vec Implementation of negative sampling in
The following is based on negative sampling skip-gram Model , For each positive sample data that needs training , You need to generate the corresponding negative samples according to a certain negative sampling probability , There are two ways to do it :
- Generate corresponding negative samples when building data , In the training model, there is no need to build negative samples , But the disadvantage is that each iteration uses the same negative samples , Lack of diversity ;
- The following is to construct the corresponding negative samples during training , utilize
SGNSDatasetMediumcollate_fnRealization , Yes batch Negative sampling of internal samples .
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequence
from tqdm.auto import tqdm
from utils import BOS_TOKEN, EOS_TOKEN, PAD_TOKEN
from utils import load_reuters, save_pretrained, get_loader, init_weights
class SGNSDataset(Dataset):
def __init__(self, corpus, vocab, context_size=2, n_negatives=5, ns_dist=None):
self.data = []
self.bos = vocab[BOS_TOKEN]
self.eos = vocab[EOS_TOKEN]
self.pad = vocab[PAD_TOKEN]
for sentence in tqdm(corpus, desc="Dataset Construction"):
sentence = [self.bos] + sentence + [self.eos]
for i in range(1, len(sentence)-1):
# Model input :(w, context) ; Output is 0/1, Express context Whether it is a negative sample
w = sentence[i]
left_context_index = max(0, i - context_size)
right_context_index = min(len(sentence), i + context_size)
context = sentence[left_context_index:i] + sentence[i+1:right_context_index+1]
context += [self.pad] * (2 * context_size - len(context))
self.data.append((w, context))
# Number of negative samples
self.n_negatives = n_negatives
# Negative sampling distribution : If parameter ns_dist by None, Then use uniform Distribution
self.ns_dist = ns_dist if ns_dist is not None else torch.ones(len(vocab))
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
def collate_fn(self, examples):
words = torch.tensor([ex[0] for ex in examples], dtype=torch.long)
contexts = torch.tensor([ex[1] for ex in examples], dtype=torch.long)
batch_size, context_size = contexts.shape
neg_contexts = []
# Yes batch Negative sampling shall be conducted for the samples in the
for i in range(batch_size):
# Ensure that the negative sample does not include the current sample context
ns_dist = self.ns_dist.index_fill(0, contexts[i], .0)
neg_contexts.append(torch.multinomial(ns_dist, self.n_negatives * context_size, replacement=True))
neg_contexts = torch.stack(neg_contexts, dim=0)
return words, contexts, neg_contexts
class SGNSModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(SGNSModel, self).__init__()
# Word embedding
self.w_embeddings = nn.Embedding(vocab_size, embedding_dim)
# Context embedding
self.c_embeddings = nn.Embedding(vocab_size, embedding_dim)
def forward_w(self, words):
w_embeds = self.w_embeddings(words)
return w_embeds
def forward_c(self, contexts):
c_embeds = self.c_embeddings(contexts)
return c_embeds
def get_unigram_distribution(corpus, vocab_size):
# Count... From the attributive material unigram A probability distribution
token_counts = torch.tensor([0] * vocab_size)
total_count = 0
for sentence in corpus:
total_count += len(sentence)
for token in sentence:
token_counts[token] += 1
unigram_dist = torch.div(token_counts.float(), total_count)
return unigram_dist
embedding_dim = 64
context_size = 2
hidden_dim = 128
batch_size = 1024
num_epoch = 10
n_negatives = 10
# Read text data
corpus, vocab = load_reuters()
# Calculation unigram A probability distribution
unigram_dist = get_unigram_distribution(corpus, len(vocab))
# according to unigram Distribution calculation negative sampling distribution : p(w)**0.75
negative_sampling_dist = unigram_dist ** 0.75
negative_sampling_dist /= negative_sampling_dist.sum()
# structure SGNS Training data set
dataset = SGNSDataset(
corpus,
vocab,
context_size=context_size,
n_negatives=n_negatives,
ns_dist=negative_sampling_dist
)
data_loader = get_loader(dataset, batch_size)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SGNSModel(len(vocab), embedding_dim)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.train()
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(data_loader, desc=f"Training Epoch {
epoch}"):
words, contexts, neg_contexts = [x.to(device) for x in batch]
optimizer.zero_grad()
batch_size = words.shape[0]
# extract batch Inner word 、 Context and vector representation of negative samples
word_embeds = model.forward_w(words).unsqueeze(dim=2)
context_embeds = model.forward_c(contexts)
neg_context_embeds = model.forward_c(neg_contexts)
# Classification of positive samples ( logarithm ) likelihood
context_loss = F.logsigmoid(torch.bmm(context_embeds, word_embeds).squeeze(dim=2))
context_loss = context_loss.mean(dim=1)
# Classification of negative samples ( logarithm ) likelihood
neg_context_loss = F.logsigmoid(torch.bmm(neg_context_embeds, word_embeds).squeeze(dim=2).neg())
neg_context_loss = neg_context_loss.view(batch_size, -1, n_negatives).sum(dim=2)
neg_context_loss = neg_context_loss.mean(dim=1)
# Loss : Negative log likelihood
loss = -(context_loss + neg_context_loss).mean()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Loss: {
total_loss:.2f}")
# Merge word embedding matrix and context embedding matrix , As the final pre training word vector
combined_embeds = model.w_embeddings.weight + model.c_embeddings.weight
save_pretrained(vocab, combined_embeds.data, "sgns.vec")
3、 ... and 、 Recommend recall related basis in the system
Recall model training and evaluation ( The corresponding loss function )
- Point-wise Sample construction :BCE Loss
- Pair-wise Sample construction :BPR Hinge Loss
- List-wise Sample construction :softmax Loss
- Vectorization recall : Use annoy
3.1 Three training methods in recall
In the recall , There are three general training methods :point-wise、pair-wise、list-wise. stay datawhale Of RecHub in , With the parameters mode To specify the training method , Each different training method also corresponds to different Loss.
Refer to the following figure for the corresponding three training methods (3 Kind of ), among a Express user Of embedding,b+ Indicates the of the positive sample embedding,b- Indicates the number of negative samples embedding.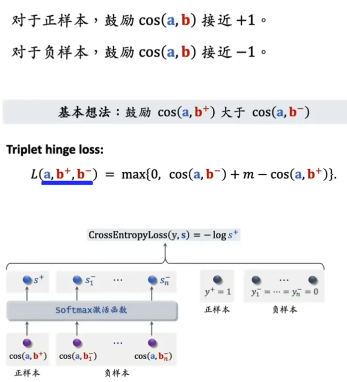
(1)Point wise (mode = 0)
thought : Consider recall as a second category , Look at each positive sample independently 、.
For a recall model :
- Input binary <User, Item>,
- Output P ( U s e r P(U s e r P(User, Item ) ) ), Express User Yes Item Of interest .
- The training goal is : If the article is a positive sample , The output should be as close as possible to 1 , Negative samples are output as close to 0 . Adopted Loss The most common is BCELoss(Binary Cross Entropy Loss).
(2)Pair wise (mode = 1)
thought : Users should be more interested in positive samples than negative samples .
For a recall model :
- Input triples <User, ItemPositive, ItemNegative>,
- Output interest score P ( P( P( User, ItemPositive ) , P ( ), P( ),P( User, ItemNegative ) ) ), Indicates that the user is satisfied with positive sample items and negative samples Interest score of this item .
- The training goal is : The interest score of positive samples should be greater than that of negative samples .
torch-rechub Used in the framework Loss by BPRLoss(Bayes Personalized Ranking Loss).Loss Put here the formula of A formula , Details can be referred to 【 Bayesian personalized ordering (BPR) Algorithm summary 】( The content in the link is slightly different from the formula below , But thought is one What kind of )
L o s s = 1 N ∑ N i i = 1 − log ( L o s s=\frac{1}{N} \sum^{N} i_{i=1}-\log ( Loss=N1∑Nii=1−log( sigmoid ( ( ( pos_score − - − neg_score ) ) )) ))
(3)List wise(mode = 2)
thought : Same thoughts Pair wise, But the implementation is different .
For a recall model :
- Input N + 2 \boldsymbol{N}+2 N+2 element Group * \langle * User, ItemPositive, ItemNeg_1,…, ItemNeg_N * \rangle *;
- Output user pairs 1 A positive sample and N \mathrm{N} N Interest scores of negative samples .
- The training goal is : The interest scores of positive samples should be greater than those of all other negative samples .
torch rechub Used in the framework Loss by torch.nn.CrossEntropyLoss, That is, the output is Softmax Cross entropy is taken after processing .
PS: there List wise The way is easy and Ranking Medium List wise confusion , Although they have the same name , but ranking Of List wise The order relation between samples is considered . for example ranking Will consider MAP、NDCP And other indicators considering sequence as evaluation indicators , and Matching Medium List wise Without considering the order .
Four 、 Recommend negative sampling in the system
In model training , Positive examples are required ( Users like products ) And negative examples ( Products that users don't like ) Give the model , However, due to the difficulty of data collection in the actual recommendation scenario , It is generally difficult to obtain explicit feedback behavior from non users ( If the user is right item Score of ), But users' implicit feedback ( Users consume or interact item) It is easier to get .
It is generally assumed that the products that users have interacted with are positive examples , And through sampling , Select a part of the product set that the user has not interacted with as a negative example .
Negative sampling (Negative Sampling): The process of negative example selection based on certain strategies from the set of products that users do not interact with .
- DSSM Among the recalled samples :
- Positive samples are exposed to the user and clicked by the user item;
- Negative sample : In fact, the common mistake is to use exposure directly and not be user Click on item, But it leads to SSB(sample selection bias) Sample selection bias problem —— because Recall online always from the full amount of candidates item Medium recall , Not from the exposed item Medium recall .
DSSM The practice in the original paper : Only positive samples , Write it down as D + D^{+} D+, For the user u 1 u_{1} u1, Its positive sample is what it has clicked item, Negative samples are random from D + D^{+} D+( It doesn't contain u 1 u_{1} u1 Clicked item) Choose... At random 4 individual item As a negative sample .
4.1 Negative sample constructed 6 A common way
(1) Expose non clicked data
If only this , It can lead to BBS problem , It depends on the scene .
(2) Global random selection negative example
From the original global material library , Randomly select negative samples as recall or rough arrangement .
(3)Batch Negative cases were randomly selected within the
Training in the same batch in , In addition to the positive example item, Choose to construct a negative example , To a certain extent SSB problem .
(4) Negative examples are randomly selected from the exposure data
(5) be based on Popularity Negative cases were randomly selected
The more popular item, If you haven't been clicked by the user , It is more likely to be a real negative example for the user .
(6) be based on Hard Select negative example
As easy negative A supplement to ,hard negative It is a difficult negative sample , That is, the matching degree is moderate , Users may or may not like —— But in fact, users don't like it ! You can refer to Airbnb Screening Hard Negative example attempt (hard Example brings to the model loss And more information ).
Business logic selection ( With airbnb For example )
- i Add rooms in the same city as positive samples as negative samples , Enhanced the regional similarity of positive and negative samples , It increases the difficulty of learning the model
- ii increase “ Rejected by the owner ” As a negative sample , Enhanced positive and negative samples in “ Match users' interests ” Similarity in , It increases the difficulty of learning the model
Mining model
- EBR Baidu Mobius The practice of is very similar , Are screened out by the recall model of the previous version " Not so similar " Of <user,doc> Yes , As an additional negative sample , Train the next version of the recall model .
- EBR The approach is : Using the previous version of the model, the recall location is 101~500 Upper item As hard negative( Negative samples are still in easy negative Mainly , The empirical value in the article is easy:hard=100:1)
Reference
[1] Word2Vec Why use negative sampling in ?
[2] Read and understand the negative sampling of the recommended system
[3] Negative sampling Negative Sampling
[4] 【 machine learning 】 Research summary of positive and negative sample selection methods of recommended algorithms
[5] CTR Definition of positive and negative samples in the prediction model 、 Selection and proportional control
[6] Discussion on the modeling and sampling method of recall module in Recommendation System
[7] Recommendation system ( Four )—— Negative sampling
边栏推荐
- Chisel tutorial - 03 Combinatorial logic in chisel (chisel3 cheat sheet is attached at the end)
- Chisel tutorial - 05 Sequential logic in chisel (including explicit multi clock, explicit synchronous reset and explicit asynchronous reset)
- Les mots ont été écrits, la fonction est vraiment puissante!
- 在网页中打开展示pdf文件
- 每日刷题记录 (十六)
- 【编程题】【Scratch二级】2019.03 垃圾分类
- QT creator add custom new file / Project Template Wizard
- 【推荐系统基础】正负样本采样和构造
- Go time package common functions
- Rock-paper-scissors
猜你喜欢

Magic fast power
【推荐系统基础】正负样本采样和构造
Seven years' experience of a test engineer -- to you who walk alone all the way (don't give up)

光流传感器初步测试:GL9306

Data Lake (XV): spark and iceberg integrate write operations

At the age of 35, I made a decision to face unemployment

Rectification characteristics of fast recovery diode

Chisel tutorial - 03 Combinatorial logic in chisel (chisel3 cheat sheet is attached at the end)
One click installation with fishros in blue bridge ROS
35岁那年,我做了一个面临失业的决定
随机推荐
507 field D - extraterrestrial relics
c—线性表
Opengl3.3 mouse picking up objects
UIC564-2 附录4 –阻燃防火测试:火焰的扩散
Enterprise application demand-oriented development of human resources department, employee attendance records and paid wages business process cases
Database interview questions + analysis
Kubectl's handy command line tool: Oh my Zsh tips and tricks
受限线性表
Rectification characteristics of fast recovery diode
[path planning] use the vertical distance limit method and Bessel to optimize the path of a star
正畸注意事项(持续更新中)
Chisel tutorial - 01 Introduction to Scala
Laser slam learning (2d/3d, partial practice)
保证接口数据安全的10种方案
自动化测试:Robot FrameWork框架90%的人都想知道的实用技巧
An example analysis of MP4 file format parsing
Dataguard 主备清理归档设置
Magic fast power
Visual Studio Deployment Project - Create shortcut to deployed executable
35岁真就成了职业危机?不,我的技术在积累,我还越吃越香了