当前位置:网站首页>Observation cloud and tdengine have reached in-depth cooperation to optimize the cloud experience of enterprises
Observation cloud and tdengine have reached in-depth cooperation to optimize the cloud experience of enterprises
2022-07-05 09:44:00 【Tdengine】
In recent years , Major manufacturers have embraced cloud native technology , The huge amount of data brought by this has brought a huge impact on the traditional technical architecture , Traditional monitoring bears the brunt . After the service goes to the cloud , Mostly based on Docker Container deployment 、Kubernetes Service governance , Resources are flexible and change in real time , Traditional monitoring is difficult to support the business requirements in this scenario , Observability (Observability) It has gradually developed into a hot direction in the cloud native field .
In this context , The system observable platform in the cloud era observes the cloud and the big data solution of the Internet of things. Shang Taosi data has reached in-depth strategic cooperation , Rely on domestic production Time series database TDengine Technical and performance advantages , Observing clouds will further satisfy the cloud 、 Cloud native 、 Application and business monitoring requirements , From the infrastructure to the log data to the full link application performance, we can achieve comprehensive and active observation , Let the enterprise experience the cloud more smoothly .
Multiple storage hybrid lookups , Observation cloud design DQL The engine focuses on query

In the data storage structure of observation cloud , Data acquisition software will be deployed to different user environments to collect required data , After data uploading, the system will classify the data according to the data type , After the classification is completed, all the data will pass through Worker Corresponding processing , According to the corresponding classification, it is written into various storage . After data storage , Users need to query data according to business requirements , But different data stores have different query languages , How to make up for language differences and complete query operations has become an urgent problem to be solved .
The storage used to observe the cloud can be summarized into three types , One is like TDengine General time series database (Time-Series Database), One is Elasticsearch( abbreviation ES), In addition, some data is stored in Redis、MySQL This kind of relational database , Corresponding to so many kinds of storage , Extremely unfriendly in traversing queries , Especially for the front end . The solution to observing the cloud is to redefine a query language that can query multiple data types , And from this design DQL engine , In a real sense, it realizes the vertical division of data query level .
In order to create a query language that can uniformly find multiple storage mixtures , The observation cloud has been deeply considered in its design , And rely on the concrete realization to polish constantly , Designed a query focused and simple syntax DQL engine , The code is shown as follows :
M(Metric)::nsq_nodes:(LAST(message_count) AS The number of messages ) BY
server_host
L(Log)::openway_gin:(MAX(cost_time)) {host = ‘prd-dataway’}
BY http_url
R(RUL)::view:(COUNT_DISTINCT(userid)) { app_id =
'appid_xyz' and view_path = re('.*/scene/.*') }After solving the problem of multiple storage coexistence , To meet the needs of business development , Further improve the front-end operating experience , Observation cloud decides to upgrade the existing storage system architecture .
And TDengine cooperation , promote User experience
The time series database used to observe the cloud is InfluxDB, Applied so far , It is increasingly difficult to support privatized deployment businesses , Multiple problems and bottlenecks limit business development , Finally, the observation cloud decided to InfluxDB Replace . They turned their attention to the domestic database field , Found in years of development , Some high-quality domestic time series databases have emerged ,TDengine Is one of them . In understanding TDengine After the various characteristics of , Observation cloud tests two time series databases .
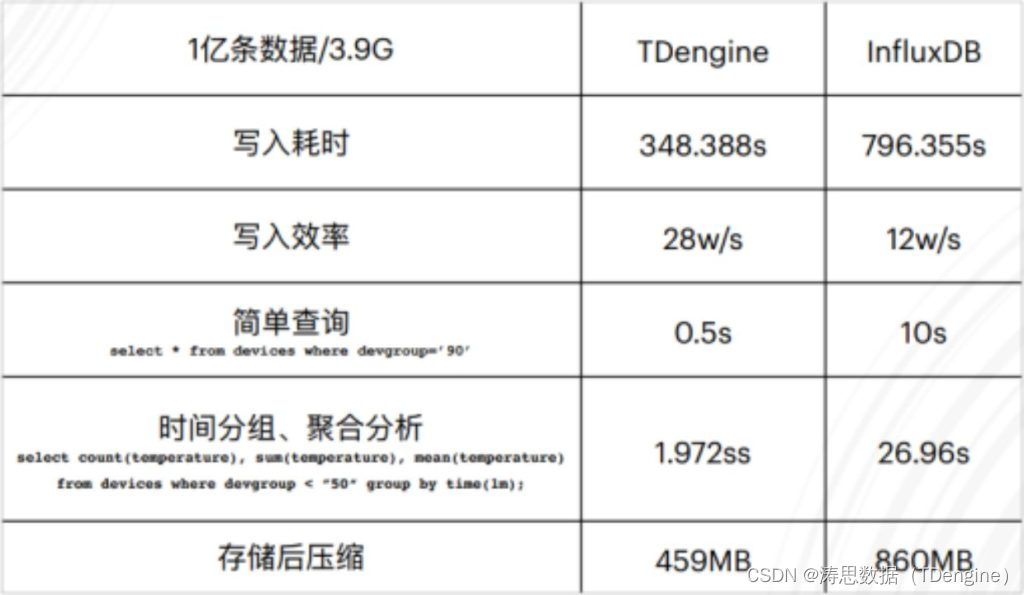
According to the above test results , Observe the cloud and find , Whether from writing 、 Query or storage ,TDengine In terms of performance, it can be said that it is comprehensively ahead of InfluxDB. Whether it's a simple query or a complex aggregate query , There are 10x~20x Performance improvement of , Storage space can be saved by about half , There is also a twofold improvement in write performance , In other words, two or three nodes may be used to meet the user's write requirements , application TDengine The latter node is about to resist , To some extent, it also saves part of the deployment cost .
at present , Observational clouds are gradually shifting data from InfluxDB Migrate to TDengine,TDengine Will be applied to multi tenant isolation 、 high frequency I/O、 In scenarios such as privatization deployment .
As a SaaS platform , Observation cloud needs to be connected to multi tenant for corresponding services , Therefore, the platform side should first consider how different tenants have different DB/Index In isolation . stay TDengine in , Multiple DB Can share one database service , Observing clouds can successfully implement this scheme .
Besides , Multi tenancy mode also generates high-frequency data writing , Each tenant may deploy multiple collection points , A collection point is equivalent to a writing client , For one tenant only , There may be ten 、 A hundred or more access clients , It is conceivable that the write volume of multi tenancy is huge .
Except for writing , The platform will also face considerable pressure at the query level , Generation of front-end indicators 、 Monitoring is always searching for data .TDengine Its logic design makes it possible to meet the requirements of high reliability , It can also meet the reading and writing requirements of big data , It can well support the system performance under the multi tenant mode .
except SaaS Out of service , Observation cloud will also be privatized and deployed according to the business needs of some customers , Privatize the deployment environment and SaaS Make a big difference , Not only to improve the deployment efficiency , You should also be able to connect with different cloud platforms , More convenient access to needed resources . Compared with InfluxDB, Domestic time series database TDengine It is obviously more friendly to privatized deployment .
Conclusion
stay TDengine With the help of , Observing the cloud greatly saves deployment and operation and maintenance costs , It also significantly improves the overall performance of the system , Let front-end users improve their experience . As TDengine Partners of , The observation cloud hopes TDengine In the future, there will be more support for mathematical functions , At the same time, strengthen some query functions to Unicode Support for , Promote the two sides to carry out more in-depth cooperation mode with richer functions .
“ Behind us SaaS And privatization deployment will use by default TDengine, Other public clouds (AWS、 Tencent, cloud, etc. ) All services on will be in the form of TDengine Mainly , For new users, we will also slowly migrate to TDengine node .”
In the future, with the continuous strengthening of bilateral cooperation , Predictably, , The technology support of the combination of strong and strong will build a more solid foundation for the intelligent monitoring of the cloud native industry “ Technology base ”, Provide technical support for enterprise digital transformation , Contribute a steady stream of creativity to the development of observability technology in China .
Introduction to observation cloud : Observation cloud , new generation SaaS Full link data observable platform , Realize unified collection 、 Uniform label 、 Unified storage and unified interface , Bring a fully functional, integrated and observable experience . Observation cloud energy full environment high base data collection , Support multi-dimensional information intelligent retrieval and analysis , And provide powerful user-defined programmability , Keep the system running under control , The root cause of the fault has nothing to hide . A smart team will observe , Observability uses observational clouds .
Introduction to Taosi data : Beijing Taosi Data Technology Co., Ltd (TAOS Data) Aim at the growing Internet of things data market , Focus on the storage of big data in time series space 、 Inquire about 、 Analysis and calculation , Do not rely on any open source or third-party software , Developed with independent intellectual property rights 、100% Autonomous and controllable high performance 、 Distributed 、 Support SQL Time series database TDengine. use AGPL license , Taosi data has TDengine The kernel of ( Storage 、 Computing engines and clusters )100% Open source , In the future, we will try our best to build a developer community , Maintain an open and open source business model .
Want to know more TDengine Database Specific details of , Welcome to GitHub View the relevant source code on .
边栏推荐
- Thermometer based on STM32 single chip microcomputer (with face detection)
- What are the advantages of the live teaching system to improve learning quickly?
- 【愚公系列】2022年7月 Go教学课程 003-IDE的安装和基本使用
- Node の MongoDB Driver
- Node の MongoDB Driver
- LeetCode 503. 下一个更大元素 II
- Gradientdrawable get a single color
- 从“化学家”到开发者,从甲骨文到 TDengine,我人生的两次重要抉择
- Lepton 无损压缩原理及性能分析
- 百度评论中台的设计与探索
猜你喜欢
植物大战僵尸Scratch
百度评论中台的设计与探索
解决Navicat激活、注册时候出现No All Pattern Found的问题
LeetCode 503. 下一个更大元素 II
Lepton 无损压缩原理及性能分析
Unity skframework framework (XXII), runtime console runtime debugging tool
Unity SKFramework框架(二十二)、Runtime Console 运行时调试工具
![[ctfhub] Title cookie:hello guest only admin can get flag. (cookie spoofing, authentication, forgery)](/img/78/d9d1a66fc239e7c62de1fce426d30d.jpg)
[ctfhub] Title cookie:hello guest only admin can get flag. (cookie spoofing, authentication, forgery)
Solve liquibase – waiting for changelog lock Cause database deadlock
正式上架!TDengine 插件入驻 Grafana 官网
随机推荐
基于STM32单片机的测温仪(带人脸检测)
移动端异构运算技术-GPU OpenCL编程(进阶篇)
oracle 多行数据合并成一行数据
Unity SKFramework框架(二十四)、Avatar Controller 第三人称控制
STM32简易多级菜单(数组查表法)
Android 隐私沙盒开发者预览版 3: 隐私安全和个性化体验全都要
Unity skframework framework (XXIII), minimap small map tool
Understanding of smt32h7 series DMA and DMAMUX
c语言指针深入理解
About getfragmentmanager () and getchildfragmentmanager ()
What about wechat mall? 5 tips to clear your mind
OpenGL - Coordinate Systems
百度评论中台的设计与探索
阿里十年测试带你走进APP测试的世界
如何正确的评测视频画质
百度智能小程序巡檢調度方案演進之路
[sorting of object array]
图神经网络+对比学习,下一步去哪?
7 月 2 日邀你来TD Hero 线上发布会
微信小程序获取住户地区信息