当前位置:网站首页>超标量处理器设计 姚永斌 第5章 指令集体系 摘录
超标量处理器设计 姚永斌 第5章 指令集体系 摘录
2022-07-04 15:52:00 【岐岇】
指令集体系(Instruction Set Architecture, ISA)是规定处理器的外在行为的一系列内容的统称,它包括基本数据类型data type,指令instruction,寄存器register,寻址模式addressing modes,存储体系memory architecture,中断interrupt,异常exception,以及外部IO等内容。
指令集体系是软件人员和处理器设计师之间的桥梁,软件人员不必关心处理器的硬件实现细节,只需要根据指令集体系就可以开发软件,而处理器设计人员则需要设计出符合指令集体系的处理器。
对于一个指令集体系的硬件实现方式称为微结构microarchitecture。
5.1 复杂指令集合精简指令集
指令集从本质上可以分为复杂指令集CISC和精简指令集RISC两种,复杂指令集的特点是能够在一条指令内完成很多事情。
早期程序使用汇编语言甚至是机器语言来编写,为方便程序员编写汇编程序,处理器设计师设计了越来越复杂的指令,这些指令可以使编程人员的工作得到简化。当时内存的容量很有限,内存中的每一个字节都是宝贵的,于是业界就更倾向于使用高度编码、多操作数和长度不等的指令,能够使一条指令尽量做很多事情,并且减少内存的占用。同时,寄存器是一种更昂贵的东西,当时的处理器中无法放入数量比较多的通用寄存器,而且,随着通用寄存器个数的增多,也就占用了更多的内存,这些原因导致处理器设计师会让一条指令中完成尽可能多的任务的。复杂指令集的设计方式在当时看起来是顺理成章的,只有在RISC的概念提出来之后,这种复杂的指令集才被称为CISC。
尽管复杂指令集的很多特性让代码编写更加便捷,当时这些复杂特性的指令需要好几个周期才能够执行完,而且大部分复杂的指令都没有被程序使用,同时复杂指令集中通用寄存器的个数太少,导致处理器需要经常访问存储器,而随着处理器和存储器之间速度代沟加大,经常访问存储器会导致处理器执行效率降低。要克服这些缺点,就需要降低处理器设计的复杂度,以让出更多的硅片面积来放置寄存器,这就产生了精简指令集。它只包括程序中经常使用的指令,这样就大大减少处理器的硅片面积,而且便于流水线来实现,使处理器的执行速度和功耗都得以降低,而那些复杂的操作则通过子程序的方式来实现。
精简指令集使用了数量丰富的通用寄存器,所有的操作都是在通用寄存器之间完成的,要和存储器进行交互,就需要使用专门访问存储器的load/store指令,它们负责在寄存器和处理器之间交换数据。
RISC指令的长度一般是等长的,大大简化了处理中解码电路的设计,也便于流水线的实现,但是相比复杂指令集,精简指令集需要更多的指令来完成同一的功能,导致其占用更多的程序存储器,虽然现在储存器很廉价,但是这会导致Cache缺失率的上市,在一定程度上使RISC处理器的执行效率有所降低。当前比较流行的RISC有ARM,MIPS和PowerPC等等。
现在RISC也可以达到上百条,而且执行周期也是不固定的;而CISC,例如x86指令集,也在处理器内部将大部分指令转换为RISC指令来执行。
5.2 精简指令集概述
5.2.1 MIPS指令集
不同于ARM,MIPS是一个坚定的RISC主义者,MIPS指令集是最简单纯粹的精简指令集。在MIPS指令集中有下述三种基本的指令。
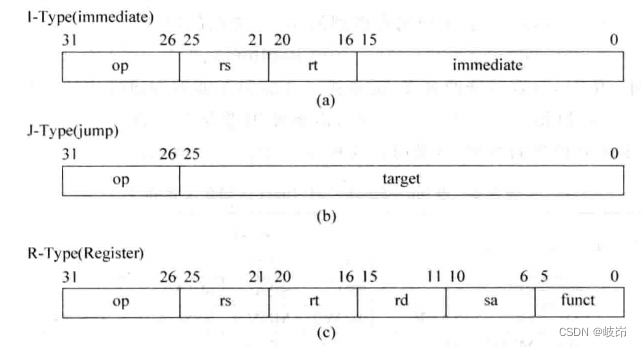
MIPS指令的长度都是32位,它会被分为不同的区域,其中op称为操作码,用来给出指令的类型,在MIPS中,所有指令的可以划分为三种基本类型I-Type,J-Type,R-Type。
JRI-Type类型都可以直接使用16位立即数;
J-Type格式的指令则使用了26位的立即数,即target,一般用于跳转类型的指令;
R-Type类型的指令对寄存器进行操作,rs和rt分别用作源寄存器和目的寄存器;R-Type包括了数量众多的指令,所以需要使用func对指令进行进一步的区分,而sa则专门用于移位指令。
MIPS指令集的指令使用op进行区分,op位于Bit[31:26];op有分支和跳转,load、store、special类型;
CLZ指令用来找出一个指定寄存器的数据中,从高位开始连续的0的个数,而CLO指令则是用来找出从高位开始连续的1的个数;
在MIPS指令集中支持分支指令的延迟槽branch delay slot,位于分支指令的后面,通常由编译器来讲一条比较独立的,不依赖分支指令的指令放到延迟槽中,这条指令一般来自于分支指令的前面,不管分支指令是否调整,它都会执行。这样即使分支指令发生跳转,也不需要将延迟槽中的指令从流水线中抹掉。这种方法对于早期流水线很短的普通处理器使比较有效率的,但是在深流水线的超标量处理器中,延迟槽中包含的指令的个数也随之增多,已经没有办法找到那么多不相干指令放到延迟槽中,所以只能向延迟槽中填充控制领NOP,这样并不会增加处理器的执行效率。
现代超标量处理器要依靠精确的分支预测技术来处理分支指令,延迟槽在这种处理器中已经失去了存在的意义。
在决定指令类型的op区域,还有一个COP0,它使用来定义一些访问协处理器的特殊指令,不过期都不能够使用rs寄存器。这部分定义 了两条指令,MTCO和MFCO,用来在协处理器的寄存器和处理器的寄存器之间传递数据。处理器无法直接操作协处理器中的寄存器,因为在指令的编码已经没有办法对协处理器中的寄存器进行直接的编码。
5.2.2 ARM指令集
ARM指令的长度都是32位。arm指令集或多或少地借鉴了复杂指令集的一些特点,在一条指令中尽量做了很多的任务,这有别于MIPS指令。ARM指令集概括分为三种类型Data Processing,Data Transfer和Branch。
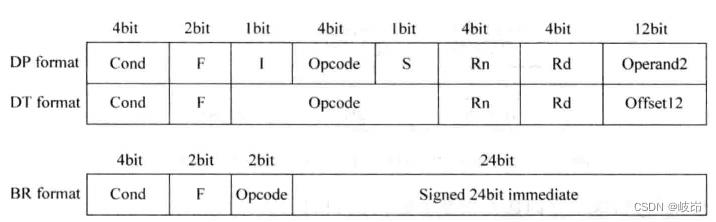
(1)Cond:condition,由于ARM指令集中,每条指令都可以条件执行,这部分就用来判断指令执行的条件是否成立;
(2)F:instruction format,用来区分指令的类型,如DP,DT,BR类型;
(3)I:immediate,如果这一位是0,则指令中的第二个操作数operand2是寄存器,否则第二个操作数是立即数;
(4)Opcode:指令的基本操作类型;
(5)S:set condition code,当一条指令的这一位被置为1,表示该指令的操作会影响状态寄存器CPSR的值,通常将一条指令后面附加S来表示这个功能;
(6)Rn:指令中的第一个操作数,来自于寄存器;
(7)Operand2:指令中的第二个操作数,它有可能来自于寄存器,也有可能是立即数;
(8)Rd:目的寄存器,存放指令运算的结果
当第二个操作数是立即数时,并不是简答地将指令中12位的Operand2都用来表示12位立即数,ARM认为12位的立即数表示范围太小,为了扩大立即数的表示范围,将指令中12位的Operand2分为了两部分,

图中rotate_imme和imme_8两部分,通过将8位的数据immed_8循环右移偶数位,可以得到一个32位的立即数。但是尽管如此,ARM中很多32位的立即数是不合法的,不能够在指令中直接被编码,只有少部分32位立即数才是合法的。
如果编译器发现LDR伪指令中32位立即数是不合法的,就需要将这个32位的立即数放到文字池中literal pool,然后使用一条PC相关的load指令来获得这个立即数。在ARM的程序中,文字池是指程序存储器位于程序区的后面,用来存放常数的一段空间。MIPS的处理方式则更加简洁高效,直接使用普通的两条指令来获得32位立即数,因此在超标量处理器中可以获得高效地执行。
在ARM中,由于PC寄存器是指令集定义的一个通用寄存器,所以可以直接在指令中使用。
在超标量处理器中,访问存储器需要经过TLB和Cache等一系列的部件,任何的miss都会造成执行效率的降低。
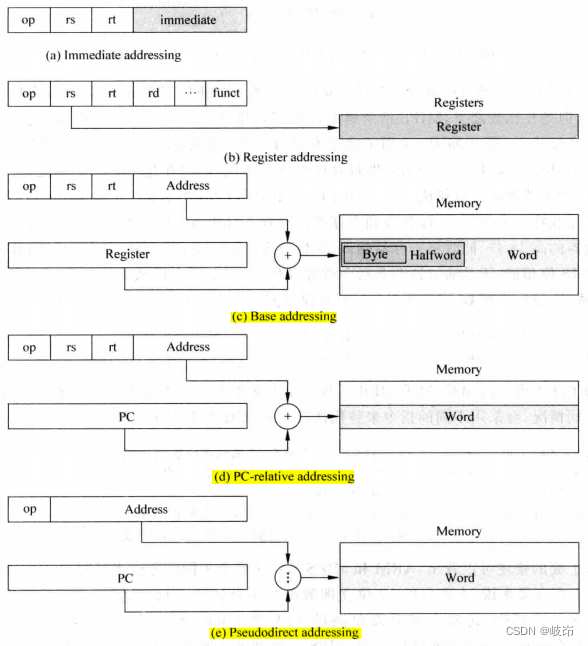
在寻址模式上,由于MIPS和ARM都是RICS处理器,没有本质的区别,一个操作数可以以立即数的形式存在于指令中,也可以存在于处理器内的通用寄存器中,还可以存在于存储器中,存在于指令中的立即数可以直接被处理器使用,因此这种寻址方式效率最高。
但是在处理器内部,由于指令编码长度、硅片面积和速度等限制,寄存器的个数一般是有限的,所以寄存器中只能保存少部分使用的数据。在存储器中可以存储任意的数据,它的容量很大,但是访问速度一般比较慢,这种寻址方式虽然效率不是很高,但是应用最广发。为了加快这种寻址方式,一般都会在处理器中使用Cache。
寻址模式:
5.3 load和store指令
5.3.1 load指令
在MIPS指令集中,基本的load包括LB,LBU,LH,LHU和LW五条指令:
(1)LB指令用来从存储器中读取一个字节的数据,将其符号扩展为32位,然后将其放到处理器内部的通用寄存器中,处理有符号数;
(2)LBU指令用来从存储器中读取一个字节的数据,将其无符号扩展为32位,然后将其放到处理器内部的通用寄存器中,处理无符号数;
(3)LH指令用来从存储器中读取半个字的数据,将其符号扩展为32位,然后将其放到处理器内部的通用寄存器中,处理有符号数;
(4)LHU指令用来从存储器中读取半个字的数据,将其无符号扩展为32位,然后将其放到处理器内部的通用寄存器中,处理无符号数;
(5)LH指令用来从存储器中读取一个字的数据,然后将其放到处理器内部的通用寄存器中;
在MIPS中,所有的load指令使用的存储器地址来自于基址和偏移量的加和,Rs+offset,其中Rs是一个通用寄存器的值,offset来自于指令中的16位立即数。
5.3.2 store指令
在MIPS指令集中,基本的store指令包括SB、SH和SW三条:
(1)SB指令用来将32位通用寄存器的低8位放到存储器中;
(2)SH指令用来将32位通用寄存器的低16位放到存储器中;
(3)SW指令用来将32位通用寄存器的放到存储器中;
因为对于存储器中写数据来说,只要将寄存器制定的内容放到指定的位置即可,不需要理会它是否是有符号数。
在RISC处理器中,Load/store指令在使用的时候需要注意大小端的问题。
小端格式little endian将一个数据的低位字节放在存储器的低位地址,而大端格式big endian则将一个数据的低位字节放到存储器的高位地址。
在load/store指令上,ARM和MIPS主要有两大方面不同:
(1)支持前/后变址(pre-index/post-index)的寻址方式,这种寻址方式概括起来完成了两个任务。
任务一:执行普通的load/store操作;
任务二:改变load/store指令中地址寄存器的值。
也就是说,使用前后变址的寻址方式,一条load/store指令在执行完成后,可以自动将存放地址的寄存器进行自加减,通过这样方式么就可以对一片连续的地址空间进行操作。
MISP不采用这种寻址方式?原因有二:一是这种前后变址的寻址方式已不符合RISC当初的理念,在RISC的理念中,更多的事情交给软件来处理,这样可以降低硬件设计的复杂度,从而获得更高的硬件性能;二是在32位的MIPS指令集的编码中,对于load/store类型的指令,已经没有空间在进行这种前后变址功能的编码了。
(2)度寄存器传送指令LDM/STM,能够在一条指令中,将存储器中一片连续地址的数据放到多个寄存器中,或者将多个寄存器的内容放到存储器内一片连续的地址空间,同时还能够改变指令中地址寄存器的内容。但是实际上在ARM处理前后中,LDM/STM这样的指令也是需要消耗多个周期才能够完成的,需要的周期数取决于要传送的寄存器的个数。此时给程序员造成一种假象:在一条指令中完成了如此多的任务,而且还能够节省指令存储空间。节省程序存储空间也就意味着更低的I-Cache的miss rate。但是到了超标量处理器中,LDM/STM由于含有多个目的寄存器和源寄存器,很难直接进行处理,需要采取一些 特殊的措施。
5.4 计算指令
MIPS指令集中计算指令的类型包括算数、逻辑、移位。
5.4.1 加减法
在MIPS中,加法指令分为有符号和无符号加法。当加法发生溢出overflow时,ADD指令会产生一个异常exception,此时计算的结果不会写到目的寄存器中;而ADDU则不会关注溢出,也不会产生异常仍旧会将结果写到目的寄存器中。
流水线处理器中如果发生异常,在这条发生异常的指令之后进入流水线的指令都应该从流水线中抹掉,这些指令不应该更改处理器的状态,流水线会从异常处理程序对应的入口地址开始取新的指令来来执行。在短流水线的普通处理器中,这种操作不会太大的性能损失,但是对于流水线很深的超标量处理器,异常的处理需要等到产生异常的指令变为流水线中最旧的指令(也就是退休的时候),然后需要将整个流水线中的指令都抹掉,并且对处理器的状态进行恢复。
减少操作SUB和SUBU类似,处理器内部其实没有减法器,而是使用加法器来实现的,因为在二进制补码的运算中,A-B=A+(~B)+1。
相比较之下,ARM对于加减运算指令产生溢出时的处理效率更高,例如其执行ADD指令时,可以选择将结果的状态保存到状态寄存器中,在ARM中这个状态寄存器称为CPSR,后面的指令值来决定自身是否执行。
当然,ARM指令这样做也是有代价的,由于每条指令都可以条件执行,则在每条指令都需要包含4位的条件码,这就使指令中可以用来寻址寄存器的编码空间变小了,所以ARM中通用寄存器只有16个,而MIPS中有32个。通用寄存器数目多时,处理器就可以减少访问存储器的次数,也就增加了程序执行的效率。
5.4.2 移位指令
MIPS的移位指令中,不带V的移位指令,一个操作数是立即数,而带V的移位指令,两个操作数都是通用寄存器。
左移的指令会在低位部分补0,而对于右移的操作,则分为逻辑右移和算术右移。对于逻辑右移,高位空出的部分用0补充;而算术右移,高位空出的部分用原来数据的符号位来填充。因此对于有符号数进行右移,就需要使用算术右移,而对于无符号右移就需要逻辑右移。
在ARM中没有专门的移位指令,这是因为ARM中大部分运算指令都可以将操作数在运算之前进行移位操作。即将移位操作和运算操作集成到一条指令中。
5.4.3 逻辑指令
MIPS中的逻辑指令主要完成与、或、非、异或等操作。在ARM中也有类似功能的指令,逻辑运算指令配合立即数,可以完成很多功能,例如:
(1)位屏蔽功能,有选择地屏蔽掉一个寄存器中的某些位;
(2)计算余数的功能,限制要求除数必须是2的整数次幂;
5.4.4 乘法指令
MIPS中MUL指令将两个32位源寄存器相乘,并将乘法结果的低32位放到目的寄存器中,当乘法结果大于32位时,肯定会导致乘法的结果不能够完全放到寄存器的情况下,编程时候需要注意;
在ARM指令集中国,可以直接在指令中指定两个通用寄存器来存储乘法的结果,这样就可以直接对乘法的结果进行其他的运算。
5.4.5 乘累加指令
乘累加指令MADD对两个操作数进行有符号乘法,并将乘法的结果自动与Hi/Lo寄存器中的数据相加,然后在将相加之后的结果写到Hi/Lo寄存器中。
乘累减MSUB也是将两个源操作数进行有符号乘法与少奶奶,然后从{Hi,Lo}寄存器中减去乘法的结果,从本质来说,也是一种乘累加运算。
5.4.6 特殊计算指令
MIPS有两条特殊的计算指令,即CLZ和CLO,CLZ指令用来计算一个通用寄存器中,从最高位开始连续的0的个数。CLO本质跟CLZ一样,只需要将寄存器的内容取反,就可以使用CLZ指令的硬件来实现CLO指令的功能。
5.5 分支指令
所有能改变程序中执行顺序地指令称为分支指令,MIPS中分支指令包括两种:(1)无条件执行,在MIPS中称为Jump指令(2)有条件执行,在MIPS中称为分支指令,这些指令只有在满足特定条件时才会执行,等同于ARM中条件分支指令。
分支指令的PC值和立即数相加而计算出新的目标地址。
所有以B开头的分支指令都需要条件判断,只有条件成立时候才会真正执行分支指令,如果条件不成立,就可以忽略这条分支指令,就好像这条分支指令不存在一样。
ARM中分支指令时判断CPSR寄存器中的状态是否满足要求。
例如MIPS的BEQ使用方式如:
BEQ r1, r2, offset;
而ARM则是:
BEQ LABLE1
这条指令在执行的时候,直接读取CPSR寄存器的内容,判断Zero标志位Z是否有效,如果有效,表示上一条指令满足相等的条件(例如上一条指令是比较指令),则跳转到LABLE1的地方执行,否则就继续顺序地执行。
在MPIPS中,分支类型指令的跳转范围只有+-/128KB,如果想要获得更大的跳转范围,可以使用J或JAL指令,这两条指令包含26位立即数。
相比于PC-relative分支方式,这种PC-region方式的好处是?如果一个程序位于256MB对齐的范围之内,则使用这种PC-region的分支指令,可以直接跳转到程序的任意一个地方;
如果256MB的跳转范围还是不够要求,则需要使用JALR指令了,这条指令直接使用一个32位通用寄存器的值作为跳转的目标地址,这样就可以跳转到4GB的任意地方。
在ARM指令集中,每次执行完一条指令,都可以选择是否将这条指令结果的状态写到状态寄存器CPSR中,在CPSR中记录指令的结果是否为0、正值、负值,是否溢出等信息,后面的指令可以根据CPSR寄存器的状态来决定是否执行。而且由于没有分支指令,也就不存在分支预测失败时引起性能下降问题。
但是这种优势不是绝对的,当一个分支块branch block变得很大时,需要条件执行的指令的个数会变得很多,此时这种方法的优势就会变成劣势,而且还会给寄存器重命名带来额外的麻烦。
不仅如此,每条指令想要执行还需要其他代价,在每条指令中,都需要包括对条件进行编码的条件码condition code,它用来对这条指令使用何种条件进行编码,在ARM指令集中这个条件码占据指令的Bit[31::28]。
但是,不管这条指令是否需要执行,每条指令都会有4位的条件码,所以指令中可以用来对通用寄存器编码的资源就少了。
5.6 杂项指令
例如访问协处理器的指令,产生软件中断的指令,以及调试相关的指令等。
在MIPS处理器中,用来控制处理器执行情况的所有控制寄存器都放在第一个协处理器中,这个协处理器的编号为0,。但是处理器无法直接通过指令来操纵协处理器0中的寄存器,因为在指令中已经没有空间对其进行编码了。
如果一个处理器能够直接将存储器中的数据作为操作数,那么处理器肯定不能成为RISC处理器了。
5.7 异常
除分支类型的指令之外,很多其他情况也能打断程序的执行,这些情况统称为异常exception。异常包括:
(1)处理器的外部事件引起的异常,更多时候被称为中断interrupt,因为发生在处理器的外部,中断本质上和处理器中执行的指令没有必然的关系,处理器在执行的任何阶段都有可能受到中断,因此也称作异步的异常。
(2)虚拟地址到物理地址的转换引起的异常,例如当这个关系不存在与TLB中,就会产生TLB缺失的异常,而这个转换关系如果在页表中也不存在,就会发生Page Fault页表,又或者一个程序访问了一个受保护的页,那么也会产生一个访问权限错误的异常,当然,如果处理器没有实现虚拟存储器,那么这些异常也就不存在。
(3)指令自身引起的错误,例如未定义的指令,用户状态下非法指令,整数运算时溢出,访问存储器的地址未对齐等。很多处理器还支持数据的完整性检查,例如处理器对L2 Cache送来的数据进行奇偶校验或ECC校验,如果校验失败,产生异常。
(4)指令自身的异常,例如MIPS中SYSCALL和Trap。
从处理器外部来看,产生异常的指令之前的所有指令都已经完成,而这条产生异常的指令及其之后的所有指令都不允许完成。处理器会跳转到对应异常处理程序入口地址,开始执行这个异常处理程序,当其执行完成后,会返回刚才发生异常的地方,重新开始讲这条指令取到流水线中,就好像这个异常没有发生过一样,这种方式也叫作精确异常precise exception。
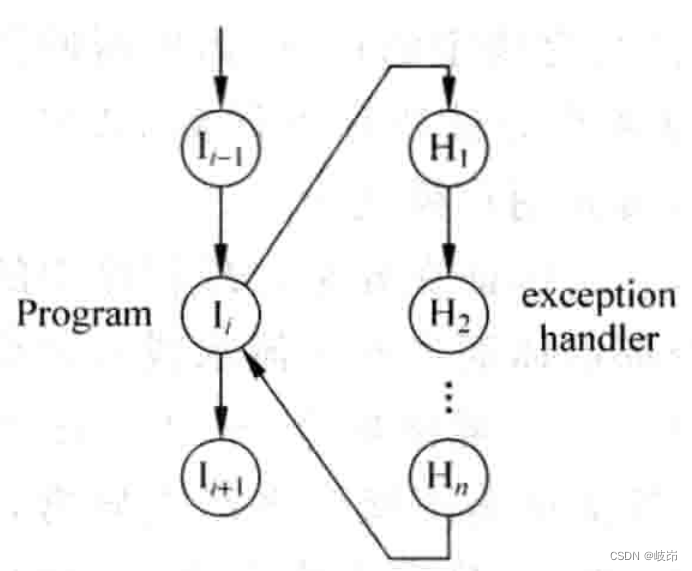
对于大部分发生异常的指令来说,都需要重新被执行一遍,但是这不是绝对的,有些类型的异常不能这样做,典型例子是SYSCALL/Trap。
在异常发生时,为了能够顺利地从异常处理程序中返回,还需要在发生异常时,将返回地址保存起来,这个返回地址就是当前发生异常指令的PC值。
对于RISC处理器来说,一般都是将它保存到一个专用的寄存器中。例如MIPS中使用EPC寄存器来保存异常发生时的PC值;而对于CISC指令集来说,通常使用堆栈来保存这个PC值,堆栈实际就是位于存储器中一段空间。
异常发生时,还需要考虑通用寄存器的处理,因为在异常处理程序中可能会更改通用寄存器的内容,所以在异常处理程序开始的时候,需要对涉及的寄存器进行保存,不管是CISC和RISC处理器,都将寄存器的内容保存到堆栈中。不过对于RISC处理器来说,要访问存储器,只能使用load/store指令,所以讲寄存器保存到堆栈的这个过程,只能使用store指令,堆栈的指针使用一个通用寄存器来模拟。
而在CISC处理器中,则设置了专门操作堆栈的PUSH和POP指令,并使用专门的寄存器作为堆栈,使用PUSH/POP指令,不需要软件对堆栈指针进行管理,硬件会自动将其增加或减少,x86处理器就采用了这种方式。其实在ARM指令集中,也采用了PUSH/POP指令和专用的堆栈指针寄存器。
在一个流水线的处理中,流水线的各个阶段都有可能发生异常。
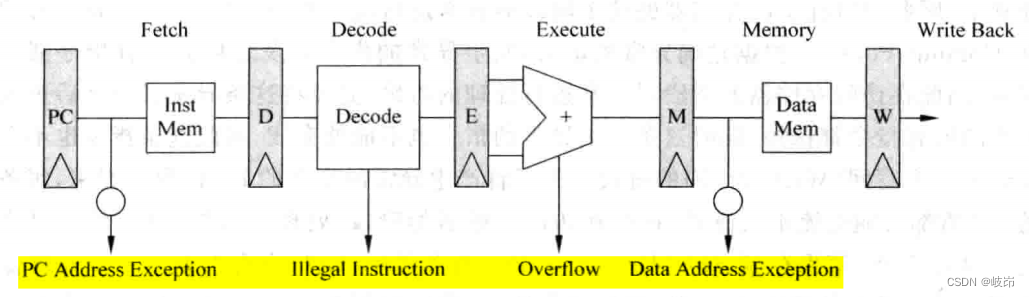
(1)取指令阶段fetch,取指令时发生I-TLB缺失甚至Page Fault,或者取指令的地址不存在,又或者到受保护的区域取指令;
(2)解码decode:遇到未定义的指令;
(3)执行execute:算术运算发生溢出,或者除0运算;
(4)访问存储器:访问数据存储器时发生D-TLB缺失甚至Page Fault,或者访问数据存储器的地址不存在,又或者非对齐访问等。
对于异常的处理要遵循程序中的原始顺序,为了满足这个条件,可以 使处理器在流水线的最后一个阶段才对异常进行统一的处理,在流水线的其他阶段产生的异常,都需要随着指令在流水线中流动,直到流水线的最后阶段才进行处理,这样能够保证对异常的处理按照程序中指定的顺序进行。
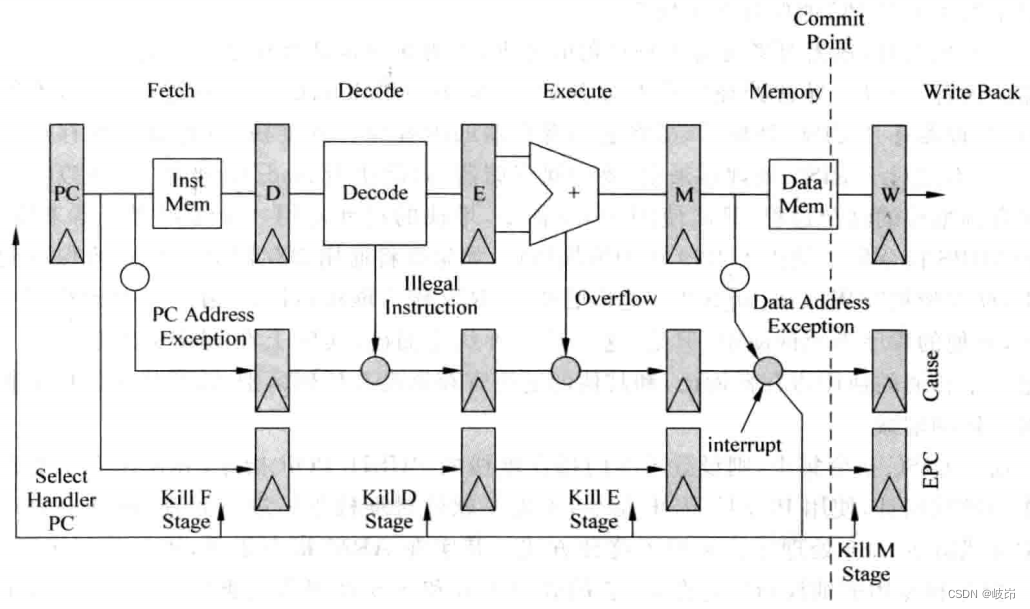
在流水线的访问存储器Memory阶段之后,就不会产生异常了,因此可以在访问存储器的这个阶段对异常进行统一处理,称这个阶段是异常的处理点Commit Point。根据精确异常的定义,发生异常的指令以及之后的所有指令都不能够完成,因此在访问存储器的阶段对异常进行处理的时候,需要将这条指令之后进入到流水线的所有指令都抹掉,同时这条产生异常的指令也不能够完成,因此这条指令也不允许进入下一个写回write back阶段。
为了将产生异常的指令的PC值保存起来,每条指令对会随着流水线流动,这样在访问存储器的阶段,就可以将这条指令对应的PC值保存到EPC Exception PC及村中,EPC寄存器是MIPS处理器中专门用来保存发生异常指令的PC值的寄存器,而异常的类型会被记录在另外一个专门的寄存器中,这个寄存器称为Cause寄存器,供异常处理程序查询使用。
边栏推荐
- 整理混乱的头文件,我用include what you use
- Oppo Xiaobu launched Obert, a large pre training model, and promoted to the top of kgclue
- Solution du système de gestion de la chaîne d'approvisionnement du parc logistique intelligent
- curl 命令妙用
- What is low code development?
- With an annual income of more than 8 million, he has five full-time jobs. He still has time to play games
- MD5加密的两种方式
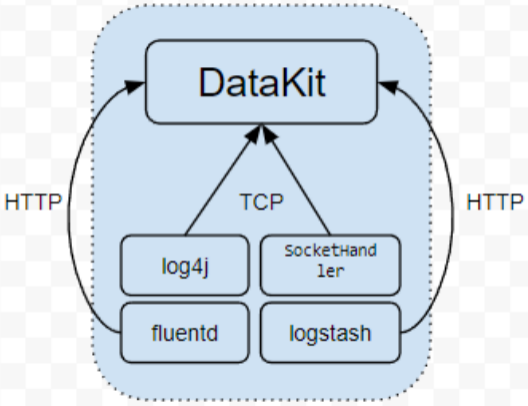
- DataKit——真正的统一可观测性 Agent
- 【Go ~ 0到1 】 第六天 文件的读写与创建
- Interpretation of data security governance capability evaluation framework 2.0, the fourth batch of DSG evaluation collection
猜你喜欢

To sort out messy header files, I use include what you use
一文掌握数仓中auto analyze的使用
PingCode 性能测试之负载测试实践
整理混乱的头文件,我用include what you use
Datakit -- the real unified observability agent

Zhijieyun - meta universe comprehensive solution service provider

KS007基于JSP实现人个人博客系统

World Environment Day | Chow Tai Fook serves wholeheartedly to promote carbon reduction and environmental protection
C# 服务器日志模块
VSCode修改缩进不成功,一保存就缩进四个空格
随机推荐
ble HCI 流控机制
tx.origin安全问题总结
La 18e Conférence internationale de l'IET sur le transport d'électricité en courant alternatif et en courant continu (acdc2022) s'est tenue avec succès en ligne.
【华为HCIA持续更新】SDN与FVC
7 RSA密码体制
Ble HCI flow control mechanism
完美融入 Win11 风格,微软全新 OneDrive 客户端抢先看
智慧物流園區供應鏈管理系統解决方案:數智化供應鏈賦能物流運輸行業供應鏈新模式
2022年国内云管平台厂商哪家好?为什么?
Face_recognition人脸识别之考勤统计
Summary of tx.origin security issues
居家打工年入800多万,一共五份全职工作,他还有时间打游戏
Implementation of super large-scale warehouse clusters in large commercial banks
What is low code development?
CANN算子:利用迭代器高效实现Tensor数据切割分块处理
Difference between redis' memory obsolescence strategy and expiration deletion strategy
detectron2安装方法
公司要上监控,Zabbix 和 Prometheus 怎么选?这么选准没错!
C# 更加优质的操作MongoDB数据库
R语言plotly可视化:plotly可视化互相重叠的直方图(historgram)、并在直方图的顶部边缘使用geom_rug函数添加边缘轴须图Marginal rug plots