当前位置:网站首页>Learn CV two loss function from scratch (3)
Learn CV two loss function from scratch (3)
2022-07-08 02:19:00 【pogg_】
notes : Most of the content of this blog is not original , But I sort out the data I collected before , And integrate them with their own stupid solutions , Convenient for review , All references have been cited , And has been praised and collected ~
Preface : In the last part, we finished image classification 、 The loss function commonly used in target detection , Let's continue with this article , It mainly talks about the loss function of face recognition .
Face recognition is CV Landing in the most mature direction , The loss function is too important for face models , Common face recognition framework facenet、insightface Will spend a lot of time in the paper to introduce their loss function .
So this chapter , We are in accordance with the softmax→Triplet Loss→Center Loss→Sphereface→Cosface→Arcface Introduce the loss function commonly used in face recognition in the order of .
1. Face recognition
1.1 Softmax Loss
softmax It has been introduced in detail in the chapter of activation function , Students who don't know much can turn over the previous content
https://zhuanlan.zhihu.com/p/380237014
softmax It can act as an activation function , It can also be used as a loss function ( But the activation function mentioned before softmax Another one is different ), In the classic face recognition framework facenet in , One of the loss functions is softmax( The others are tripet loss and center loss, Let's talk about ), For specific applications, you can see the official open source code :
https://github.com/davidsandberg/facenet/blob/master/src/train_softmax.py
1.2 Tripet Loss( Triplet loss )
Triples consist of three parts , Namely anchor, positive, negative:
- anchor It's the benchmark
- positive Is aimed at anchor A positive sample of , To express with anchor From the same person
- negative Is aimed at anchor The negative sample of

triplet loss Our goal is to make : - Have the same label The sample of , Their embedding stay embedding The space is as close as possible
- It's different label The sample of , Their embedding Keep the distance as far as possible
As shown in the figure below , In the picture anchor And positive Belong to the same id, namely y a n c h o r = y p o s i t i v e y_{anchor}=y_{positive} yanchor=ypositive; and anchor And negative Belong to different id, namely y a n c h o r ≠ y p o s i t i v e y_{anchor}\ne y_{positive} yanchor=ypositive. After continuous learning , bring anchor And positive The European distance of becomes smaller ,anchor And negative The European distance of becomes larger . among , there anchor、Positive、negative It's all pictures d Dimensions are embedded in vectors ( We call it embedding).
Use mathematical formulas to express ,triplet loss What we want to achieve is :
among , d ( ) d() d() Represents the Euclidean distance between two vectors , α α α Represents the... Between two vectors margin , prevent d ( x i a , x i p ) = d ( x i a , x i n ) = 0 d\left(x_{i}^{a}, x_{i}^{p}\right)=d\left(x_{i}^{a}, x_{i}^{n}\right)=0 d(xia,xip)=d(xia,xin)=0. therefore , It can be minimized triplet loss Loss function to achieve this :
Sum up :
- triplet loss The ultimate optimization goal is to narrow a , p a, p a,p Distance of , Pull away a , n a, n a,n Distance of
- easy triplets : L = 0 L = 0 L=0 namely d ( a , p ) + m a r g i n < d ( a , n ) d ( a , p ) + m a r g i n<d(a,n) d(a,p)+margin<d(a,n) , In this case, there is no need to optimize , In most cases a , p a, p a,p The distance is very close , a , n a, n a,n Far away
- hard triplets : d ( a , n ) < d ( a , p ) d ( a , n ) <d ( a , p ) d(a,n)<d(a,p) , namely a , p a, p a,p Far away
- semi-hard triplets : d ( a , p ) < d ( a , n ) < d ( a , p ) + m a r g i n d ( a , p ) d ( a , p ) <d ( a , n )<d ( a , p ) + m a r g i n d(a, p) d(a,p)<d(a,n)<d(a,p)+margind(a,p)
- FaceNet Is randomly selected semi-hard triplets Training , ( You can also choose hard triplets Or train together )
How to train :
- offline mining
Training everyone epoch Initial stage , Calculate all of the training sets embedding, And pick all hard triplets and semi-hard triplets, And in time epoch Train these inside triplets.
This method is not very efficient , Because of every epoch We all need to traverse the entire data set to produce triplets.
- online mining
This idea is for everyone batch The input of , Dynamically calculate useful triplets. Given batch size by B B B ( B B B It has to be for 3 Multiple ) The sample of , We calculate its corresponding B e m b e d d i n g s B_{embeddings} Bembeddings , At this point, the best we can find B 3 t r i p l e t s B^3 triplets B3triplets. Of course, many of them triplet Are not legal ( because triplet Need to have 2 Are the same label,1 One is different label)
1.3 Center Loss
Center Loss The function comes from ECCV2016 A paper on , Thesis link :
http://ydwen.github.io/papers/WenECCV16.pdf
In order to improve the distinguishing ability of features , The author puts forward center loss Loss function , It can not only narrow the differences within the class , And can expand the differences between classes .
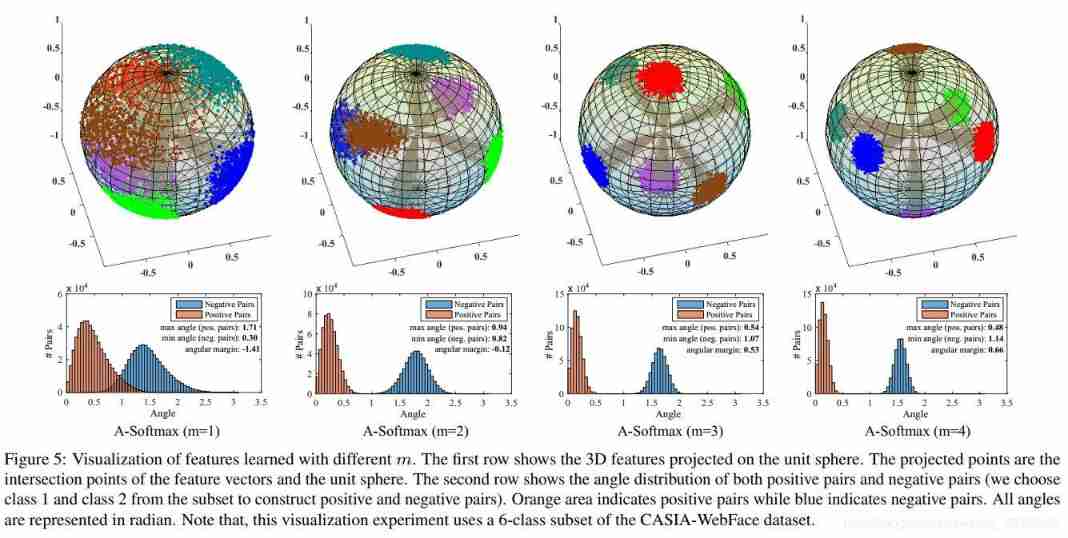
The author begins with MNIST Data sets , Change the last output dimension of the hidden layer to 2, Use softmax+ Cross entropy as a loss function , Visualize the results , As shown in the figure below . It can be seen that , Cross entropy can separate each class , The data distribution is radial , But it is not enough to distinguish , That is, there are large differences within the category .

On the left for 50K Training set of , On the right is 10K Test set of , It also indirectly shows that a large enough amount of data can make the algorithm more robust
therefore , The author wants to maintain the separability of data , Further narrow the differences between classes . In order to achieve this goal , Put forward Center Loss Loss function :
Center Loss Is achieved by first generating vectors of all categories , Then calculate the Euclidean distance between these random vectors and the real vectors of this category , The obtained Euclidean distance is taken as center loss, Automatically adjust these initially random vectors through back propagation .
among , c y i c_{y_i} cyi It means the first one y i y_i yi The center of the class . therefore , Will usually Center Loss And cross entropy , Constitute the combined loss function :
among , λ λ λ Express center loss The intensity of punishment . Also in MNIST in , The results are shown in the figure below . You can see that with λ λ λ An increase in , More restrictive , Each class will gather in the center of the class .
In the use of Center Loss Loss function , You need to introduce two hyperparameters : α α α and λ λ λ . among , λ λ λ Express center loss The intensity of punishment ; and α α α Control the center point in the class c y i c_{y_i} cyi Learning rate of . Center point in class c y i c_{y_i} cyi It should follow the different characteristics , There will be changes . Usually in every mini-batch Update the center point in the class c y i c_{y_i} cyi:
Reference resources
[1] https://www.cnblogs.com/dengshunge/p/12252820.html
[2] https://zhuanlan.zhihu.com/p/295512971
[3] https://blog.csdn.net/u013082989/article/details/83537370
边栏推荐
- Leetcode featured 200 channels -- array article
- Force buckle 4_ 412. Fizz Buzz
- Kwai applet guaranteed payment PHP source code packaging
- UFS Power Management 介绍
- List of top ten domestic industrial 3D visual guidance enterprises in 2022
- Random walk reasoning and learning in large-scale knowledge base
- Thread deadlock -- conditions for deadlock generation
- excel函数统计已存在数据的数量
- Spock单元测试框架介绍及在美团优选的实践_第三章(void无返回值方法mock方式)
- 生命的高度
猜你喜欢

Monthly observation of internet medical field in May 2022
企业培训解决方案——企业培训考试小程序

What are the types of system tests? Let me introduce them to you
Spock单元测试框架介绍及在美团优选的实践_第四章(Exception异常处理mock方式)

List of top ten domestic industrial 3D visual guidance enterprises in 2022

Deep understanding of softmax

《通信软件开发与应用》课程结业报告

image enhancement
Yolo fast+dnn+flask realizes streaming and streaming on mobile terminals and displays them on the web
咋吃都不胖的朋友,Nature告诉你原因:是基因突变了
随机推荐
Yolo fast+dnn+flask realizes streaming and streaming on mobile terminals and displays them on the web
Discrimination gradient descent
电路如图,R1=2kΩ,R2=2kΩ,R3=4kΩ,Rf=4kΩ。求输出与输入关系表达式。
Semantic segmentation | learning record (5) FCN network structure officially implemented by pytoch
Semantic segmentation | learning record (3) FCN
Node JS maintains a long connection
Thread deadlock -- conditions for deadlock generation
Redisson distributed lock unlocking exception
力扣4_412. Fizz Buzz
Anan's judgment
文盘Rust -- 给程序加个日志
leetcode 869. Reordered Power of 2 | 869. Reorder to a power of 2 (state compression)
leetcode 865. Smallest Subtree with all the Deepest Nodes | 865.具有所有最深节点的最小子树(树的BFS,parent反向索引map)
Introduction to Microsoft ad super Foundation
How does the bull bear cycle and encryption evolve in the future? Look at Sequoia Capital
VIM string substitution
List of top ten domestic industrial 3D visual guidance enterprises in 2022
BizDevOps与DevOps的关系
Unity 射线与碰撞范围检测【踩坑记录】
excel函数统计已存在数据的数量