当前位置:网站首页>[Presto] Presto parameter configuration optimization
[Presto] Presto parameter configuration optimization
2022-07-06 11:31:00 【kiraraLou】
Preface
Former company presto The service has not been very stable , With resource group , Configuration optimization , Code secondary development .presto The service has basically stabilized . This record presto What optimization has been done to service parameter configuration .
The production environment here JVM Are configured as 40G.
config.properties
- Disable reservation pool
Reserved Pool : When you have one worker Of General Pool Out of memory ,reserved pool Will work . This is the time coordinator The cluster will select the query that consumes the most memory , And assign the query to all worker Of reserved pool.
Reserved Pool The value is equal to the query.max-total-memory-per-node Size . query.max-total-memory-per-node Is a single node User memory and system memory Maximum occupancy .
and Reserved Pool It is reserved by the system at startup , Moving together will occupy , So now there's a question , In reality , We seldom use Reserved Pool, And it also takes up a lot of memory resources .
So we can configure parameters
experimental.reserved-pool-enabled=false
- query.max-memory-per-node
In a single worker The largest one that can be used above user memory value ( Default JVM max memory * 0.1) To adjust to JVM max memory * 0.25
query.max-memory-per-node=10GB
- query.max-total-memory-per-node
Single Query In a single Worker The maximum allowed on the user memory + system memory To adjust to JVM max memory * 0.4
query.max-total-memory-per-node=16GB
- memory.heap-headroom-per-node
This memory is mainly the memory allocation of third-party libraries , Unable to track statistics . ( Default JVM max memory * 0.3) To adjust to JVM max memory * 0.2
memory.heap-headroom-per-node=8GB
- query.max-memory
The maximum memory that a single query can use instantly on all task scheduling nodes ( Peak memory for a single query ) To adjust to <= query.max-total-memory-per-node * workers * 0.8
query.max-memory=192GB
- query.low-memory-killer.policy
When presto Occurrence cluster OOM Memory protection strategy when , To configure total-reservation yes kill Lose the task that occupies the most memory .
query.low-memory-killer.policy=total-reservation
- More configuration
# Extend the waiting time
exchange.http-client.request-timeout=10s
# From the other Presto The number of threads that the node obtains data . Higher values can improve the performance of large clusters or clusters with high concurrency ( The default value is :25)
exchange.client-threads=50
exchange.http-client.idle-timeout = 10s
# Parallel operator ( For example, join and aggregate ) Default local concurrency . Lower values are better for clusters that run many queries at the same time ( The default value is :16, Must be 2 The power of )
task.concurrency=2
task.max-worker-threads=60
# You can create for processing HTTP The maximum number of threads responding . On a cluster with a large number of concurrent queries or on a cluster with hundreds or thousands of workers , It can be raised ( The default value is :100)
task.http-response-threads=200
join-distribution-type=AUTOMATIC
node-scheduler.max-splits-per-node=200
query.max-stage-count=400
# Automatically kill Run longer than 20 Minutes of sql( Replace script kill Mission , Give Way presto Automatic management ):
query.max-run-time=1200s
# Solve the new version remote too large Report errors
exchange.http-client.max-content-length=128MB
node-manager.http-client.max-content-length=64MB
jvm.config
-Xmx40G
-Xms40G
-XX:-UseBiasedLocking
-XX:+UseG1GC
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+UseGCOverheadLimit
-XX:OnOutOfMemoryError=kill -9 %p
-DHADOOP_USER_NAME=hive
-Duser.timezone=Asia/Shanghai
-Djdk.attach.allowAttachSelf=true
-Djava.security.krb5.conf=/etc/krb5.conf
-XX:G1ReservePercent=15
-XX:InitiatingHeapOccupancyPercent=40
-XX:ConcGCThreads=8
边栏推荐
- Heating data in data lake?
- nodejs连接Mysql
- When you open the browser, you will also open mango TV, Tiktok and other websites outside the home page
- [Blue Bridge Cup 2017 preliminary] grid division
- Tcp/ip protocol (UDP)
- AcWing 1298.曹冲养猪 题解
- ES6 Promise 对象
- [download app for free]ineukernel OCR image data recognition and acquisition principle and product application
- [BSidesCF_2020]Had_a_bad_day
- Knowledge Q & A based on Apache Jena
猜你喜欢
MySQL and C language connection (vs2019 version)
vs2019 使用向导生成一个MFC应用程序

QT creator design user interface

Kept VRRP script, preemptive delay, VIP unicast details
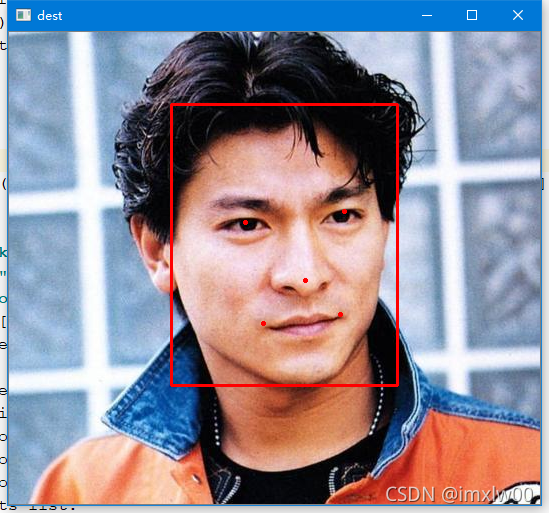
Mtcnn face detection
图像识别问题 — pytesseract.TesseractNotFoundError: tesseract is not installed or it‘s not in your path
学习问题1:127.0.0.1拒绝了我们的访问

{one week summary} take you into the ocean of JS knowledge
Integration test practice (1) theoretical basis
How to build a new project for keil5mdk (with super detailed drawings)
随机推荐
图像识别问题 — pytesseract.TesseractNotFoundError: tesseract is not installed or it‘s not in your path
error C4996: ‘strcpy‘: This function or variable may be unsafe. Consider using strcpy_ s instead
2020网鼎杯_朱雀组_Web_nmap
Aborted connection 1055898 to db:
自动机器学习框架介绍与使用(flaml、h2o)
Face recognition_ recognition
Kept VRRP script, preemptive delay, VIP unicast details
AcWing 1298. Solution to Cao Chong's pig raising problem
vs2019 桌面程序快速入门
C语言读取BMP文件
【yarn】Yarn container 日志清理
人脸识别 face_recognition
AI benchmark V5 ranking
L2-007 家庭房产 (25 分)
ES6 promise object
Why can't STM32 download the program
vs2019 使用向导生成一个MFC应用程序
UDS learning notes on fault codes (0x19 and 0x14 services)
牛客Novice月赛40
[BSidesCF_2020]Had_a_bad_day