当前位置:网站首页>Zhou Jie: database system of East China Normal University
Zhou Jie: database system of East China Normal University
2020-11-06 21:24:00 【Meituan technical team】
【Top Talk/ Big guy says 】 Sponsored by meituan Institute of technology and scientific research cooperation department , For all technical students , Regularly invite senior technical experts of meituan 、 Industry leaders 、 University Scholars and bestsellers , Share best practices with you 、 Hot topics on the Internet 、 The development of advanced technology in academic circles , Help meituan broaden their horizons 、 Promote awareness .
2020 year 10 month 27 Japan ,Top Talk We invited Mr. Zhou Jie of East China Normal University , Ask him to bring in the title 《 Research on database system of East China Normal University 》 The share of . This article is a written version of the report shared by Mr. Zhou Jie , I hope it can be helpful or enlightening .

/ Guest speaker /

/ Summary of the report /
East China Normal University is a few universities in China that have long insisted on the research of database kernel technology , In the academic and industrial circles have established a good reputation . This lecture will share some recent scientific research ideas and research results of database team of East China Normal University . Firstly, the main factors that drive the development of database technology are analyzed , Let's talk about some valuable research directions in the future . Let's talk about some interesting research results the team has made recently , Areas include database adaptation for new hardware 、 Distributed transactions 、HTAP、 The system is modularized (Modularization) wait .
00 introduction
Today, I represent the database team of East China Normal University , Let's share some of the research experience and current research results on database technology or product . Actually , Universities and enterprises are actually in two different ecological fields , Colleges and universities pay more attention to some problems about research theory , But enterprises pay more attention to their own products and users , So the goals of the two are not the same . But after so many years of exploration in China Normal University , In particular, we have made some explorations in our own research , And the experience of working with enterprises , We think that in fact, universities and enterprises should work together to do what we call database system or basic software research , Because only in this way can we better promote the development of the industry itself .
My report will be divided into two parts . First of all, let's share our views on the development of database technology , Our team has also been working in the field of databases for many years , I also did database system in Renmin University of China before , I may not be in this field 20 Years of accumulation . I hope we can put forward our views , And get some feedback from you , It's just a discussion , Because of the exploration of the development direction of Technology , There is no standard answer . I think we should pool our ideas , Discuss together , In order to see this problem more clearly , This is the first part of the lecture .
In the latter part, I will focus on some of our research results , These research results may compare the technical details , It will be more suitable for technology 、 database 、 These students of the system , But I will try to make the form of lectures more popular , Try to introduce it in a more popular way . I hope that through the introduction of this kind of detail , It can also let you know , When we were designing the system , Usually an engineer 、 A researcher or a scholar , What is his idea , I can't represent everyone , But because our team is a typical system team , Therefore, this idea may only represent the ideas of some scholars who do systematic research .
01 The form change of database system
1.1 What causes the database system to change in shape ?
First of all, let's ask you a question , What causes the database system to change in shape ? We know that a database system is actually a system with a long history , Is a core component of modern software development . Any application is inseparable from some kind of database , But we can actually see , If you have some experience , For example, maybe 10 Years of working experience , You'll see that the shape of the database system is changing ,10 Something very popular a year ago , It's not widely adopted now . This system has a long history , Also very mature , But its shape is still changing .
What drives the shape of the database system to change ? This is a very important question , It's also an interesting question , But it's not a good answer or a comprehensive answer to the question . I'll just throw out some of our views on this issue , We feel that the shape of the database system has changed , There are three main driving forces :
- The first is the change in application requirements . Our software products have been getting richer and richer , There are more and more scenarios to deal with , In fact, application requirements are changing , It's changing with different requirements , It's changing the shape of the database system .
- The second aspect is seldom touched upon in the academic circles , It's the change of software development model . The database is 70 years 80 It was designed in the s , What we are facing is the software development mode at that time , We know that after the 1990s , The software development model has actually changed a lot . Changes in the pattern of software development , It's also causing changes in the way databases are used , It's also pushing the evolution of database systems .
- The third aspect is the innovation of hardware platform , The hardware is changing the processor 、 Memory devices , The whole platform used to be a large computer , The mainframe 、 medium-size computer , And now it's actually a cloud platform , The change of these things is actually a change in the form of the database itself .
The main driving forces we see are these three . We don't think these three factors will drive database change in the future , We can predict what aspects of the future should advance our database technology through this thing . Now I will do a simple expansion .
1.1.1 Changes in application requirements
First of all, the first point is the change of application requirements . We think it's actually driving the underlying technology , One of the main reasons for technological changes like database systems .

Through the above three pictures, you can easily understand the age when the database was born , At that time, disk was used as a storage medium , Just promoted in the market , Disk replaced tape , Random access to data becomes possible . At that time, the demand for data management functions suddenly increased , There were all kinds of databases , Including a mesh database , Including the following relational database , At that time, we called it the pre Internet era . But the scale of the application at that time was not big , The number of users of the database is average , There are very few end users , For a bank, it is the bank staff who are using the database , Ordinary users line up at the bank , Their end users are not .
After entering the Internet era , We found that the number of end-users has grown explosively . Now each of us has a cell phone , I'm always using my mobile phone App, And then this App He sends requests to the database in the background at any time . We've seen the scale of applications recently 20 There was a big increase in , If you look back , In the future, we think growth is likely to continue . Our industrial Internet 、 If the Internet of things is used , Our terminals will become more , He may be putting more pressure on the data management system .
So we see the expansion of applications , There is a growing pressure on the underlying systems like databases , To deal with this kind of pressure , Previous database design , It gradually becomes less practical , We have to innovate , It has to be changed .
This is one of the main driving forces we see . But beyond the scale of the application , Of course, there is an extension of the application field , In the beginning, the database was used in the field of finance or telecommunication , Not on the Internet 、 Sales or media and so on, to use on a large scale , But we found that IT After penetrating into all walks of life , Its range of applications is also increasing , Increasing the scope of application is not friendly to traditional systems , Or your traditional database system is not friendly to these applications , So this is also driving a change in it .

What's the change in application requirements ? If we look back on history , We see that distributed databases are becoming more and more needed , You see some of Google's distributed database products , It's now a benchmark product , Then there are some scenarios of distributed database in China , Including meituan , I heard that meituan is also developing its own distributed database , In fact, it's a response to the increasing demand load .
Dealing with it is actually not a very simple thing , If you want to increase the scalability of your database , Sometimes you have to redesign your database . We usually do system students should understand , In fact, when we do the system , You need to do a lot of trade-offs , Some things can't be taken into account , Like your functionality and applicability, right ? If a thing is very simple to use , It's functional and sometimes simple , Its complex functions can't handle , Or when your functions are complex , You can't expand again .
You have to make a trade-off when designing a system , To gain a part of this ability , You have to lose some other abilities . When you need it to be very scalable , You may have to rethink it , What are you going to throw away , You're going to put up with something else , And then there are architectural changes , And then we'll find new systems coming out , For example, it used to be SQL, We're talking about NoSQL People think it's easier to do better in terms of scalability , Then there will be other forms of data management products .
In response to this question , There is a lot of discussion in academia and industry ,Michael Stonebrake Probably 10 Some of the comments made years ago , Just say “One size does not fit all”, You can't expect a single system to handle all the application requirements . Because of different application requirements , You may have to make a different compromise 、 Reconsider , That's all you have to do , You can only lose the other , So this creates a variety of forms .
The database we're looking at now , If you're using it , You're going to have a lot of choices , In the end, you use MySQL still MongoDB Right ? What are you going to use in your analysis ? use Hadoop Or the traditional warehouse MPP product , There are different needs , There may be different considerations . Well, we see the changes in application requirements , Its increase , It actually plays a very important role in promoting the system , That's the first point I've developed .
1.1.2 The transformation of software development mode
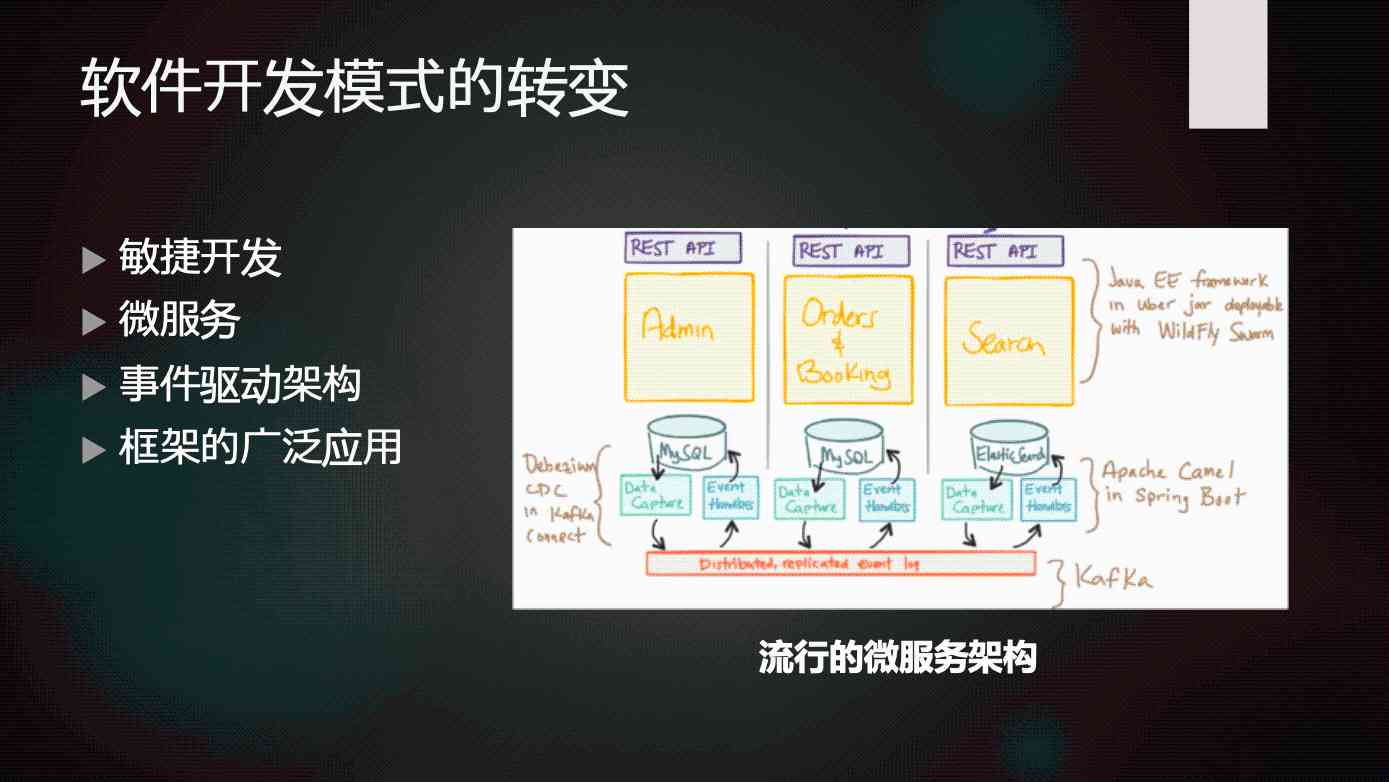
then , The second point is that we find changes in software development patterns , It's also promoting changes in the database itself . As I mentioned just now , Many of the software development models used now are not the same as before . In the past, when products like relational databases were just widely used , Software development at that time was data centric , A database design , There are a lot of apps that use it , It's a Shared The underlying system . At that time, the database design process , It's relatively independent ,DBA according to App Developer requirements 、 User needs , With DBA How to design a database , According to the understanding of the data model , It's designed to be very regular , To satisfy all kinds of paradigms , And then use it for different applications . But now we find that once we use the new development model of microservices , Most of the time, this horizontal segmentation becomes less important . The original data is a layer of 、 Application logic is a layer of , The decoupling between these two layers is very important , But now it's not .
Now it's in the form of microservices , It's a longitudinal cut , Divide the whole business into pieces , Each block has a separate database , There is a separate functional design , This weakens the boundaries between databases and Applications , Strengthen the boundaries of different modules in the application . In this case , Each module can use different database products , For example, a device uses MySQL, Another device might use MongoDB, A third device might use ES, The data between these modules has synchronization and interaction , You can use some architecture like event driven , image Kafka such MQ (Message Queue) To connect together , Form an overall framework .

This design is different from the previous database , The requirements for the database itself are also different . Different Service Can use different forms of database products , According to the needs or habits of software developers , To use a variety of caches 、 Message queuing, etc , Go and graft these things together . This form has different requirements for the database , therefore NoSQL Accepted by a lot of people .
In some software development scenarios ,NoSQL It's easier to use than a relational database . Then the transaction is handled differently , Now message queuing is in transaction processing , Its weight is very high , Instead of completely relying on the traditional database internal support transaction mode . This is something that we have seen as well , This is some of the changes that software development patterns have brought .
1.1.3 Hardware platform innovation

The third aspect is the innovation of the platform . In fact, we will not pay much attention to the flexibility of traditional database hardware platform , But now the database products are basically for the cloud platform , Not before IBM The mainframe , No Oracle The hardware platform of that time . We are facing a cloud platform , The cloud platform itself is developing . The future cloud platform can be foreseen , It's not just what we see now , It is a computing platform composed of virtual machines or containers , And it could be like a big computer , It's just this kind of large computer. It's very rich in resources , Any resource that needs to be called can be obtained , Need more memory 、CPU、 Storage , Can be obtained directly .
The cloud platform connects all these resources through a more efficient network , And then the interface to the user is very simple , Many maintenance functions are implemented within the cloud platform . The database should be rooted in such a cloud platform , In fact, there will be new requirements for database system . Previous databases , We all remember that there are several architectures to choose from , It's called Shared Everything、Shared Nothing、Shared Disk Some of these architectures .
But I feel like “ cloud ” On the level , Database is no longer so simple to partition , That is to say, the product of database system , You have to be flexible . Any resource is in short supply , You can quickly schedule resources through the cloud , So as to increase the capacity of the database . For users , It's just a database service , How much users use ? Just how much . Such a database under Cloud Architecture , There may be some changes in shape . In addition to this cloud system , In fact, there are some new hardware , There are more and more kinds of hardware . Different kinds of hardware , Under different conditions , Computing power is also increasing . Except for the calculation, of course , And storage has changed a lot , Put these in the clouds , The resources of the cloud have become richer , Database requirements will also become higher .
therefore , We see this kind of hardware platform change , It actually drives some of the development of databases . Now it is common for us to find a database of this architecture that is separate from storage and computing . I put the database itself into this system , Its computing layer is completely separated from the storage layer , The computing layer can extend itself , The storage layer can also expand itself , The two layers pass through the high-speed cloud 、 Interconnected channels can be connected together , This is actually a special treatment for the cloud . We know that storage is cheap , So when storage needs to be expanded , There is no need to add CPU Resources for , because CPU More expensive . If it's expanded separately , This will really increase the cost greatly .
After all kinds of resources are added in the future , It all has the possibility to expand the demand . Like caching , New memory , After the new memory is added , It may need to be separated from the underlying storage , Put in a quarantine , And then expand it separately , It's all possible . But today's database products are facing this kind of expansion ability , It's actually very limited , Storage and computing are expanded separately to a certain extent , In fact, its capacity has reached a peak . So how to push it to further increase this flexibility , It's actually a very difficult question , But it's also an interesting question .
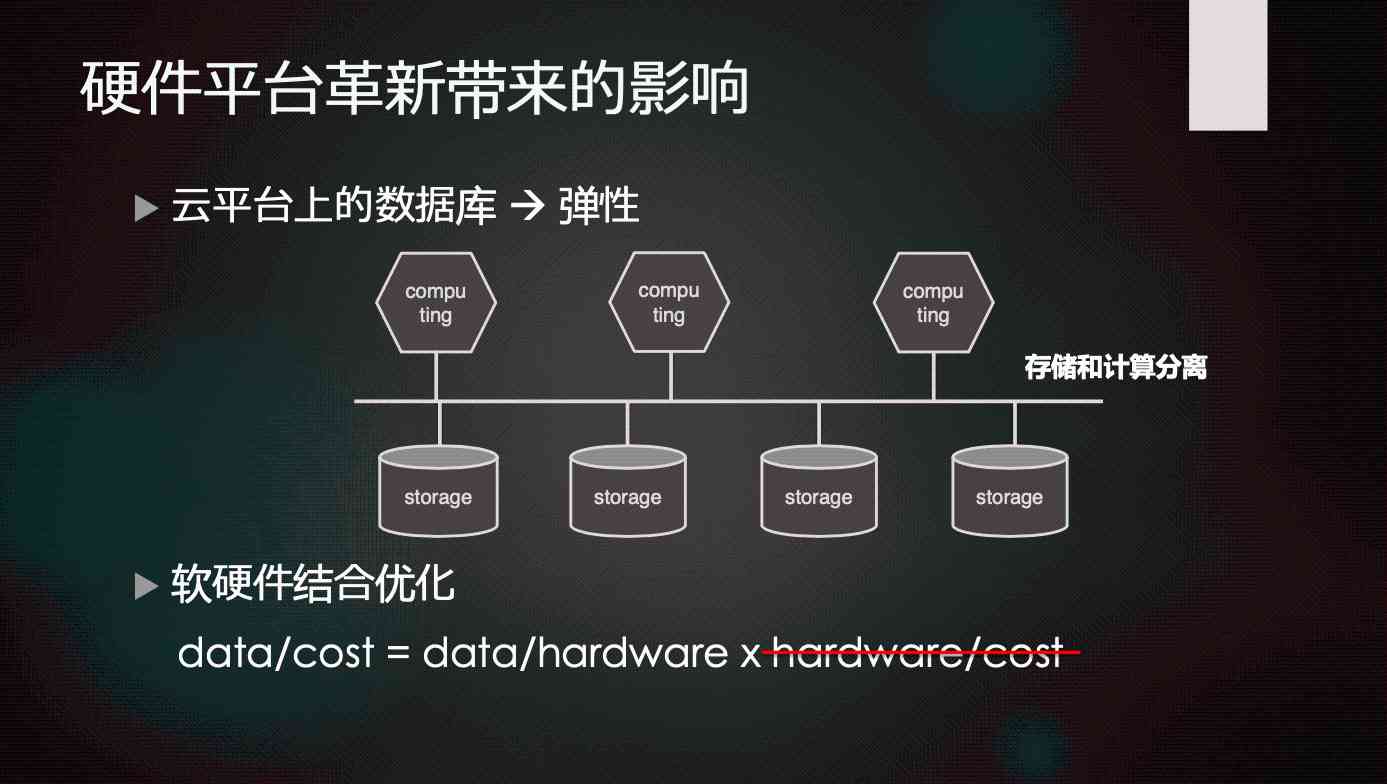
The impact of new hardware on database products , Here's a simple formula , The left side of the formula is called Data/Cost, Unit data processing , How much data can be processed per unit cost . This is what we need to improve , Because it can be imagined that the amount of data will be more and more large in the future , If you don't raise the value of the data that can be processed on the unit price , You can't improve your ability to deal with data . More data , The more resources or costs it takes , This is something we don't want to see . I hope that in the formula on the left Data/Cost As technology advances , It can gradually improve .
And then I'll break down the equation on the left , Decompose into Data/Hardware and Hardware/Cost A product of . This is actually a very simple factorization , You can see clearly . We find the following formula Hardware/Cost, In fact, its growth is gradually slowing down or even stagnating , One of the main problems is the hardware resources that can be purchased per unit price , We need to further improve on this , It's going to be very difficult .
Last , If you want to achieve Data/Cost If you want to be promoted , You can only improve the formula on the left Data/Hardware, This is an obvious trend in the future . How to improve Data/Hardware? It is how to improve the ability of data processing under the unit hardware ? We think there are only two ways , The first is hardware customization , Facing different application requirements , Special hardware is needed for this application . In fact, we can see things like GPU、TPU This kind of appearance , In fact, it is already revealing the law , Dedicated hardware is always better than generic hardware . Then the software is the same , The efficiency of specialized software is certainly better than that of general software .
I think this trend can be seen in the long run , The short term may not be so obvious , But in the long run , This process should be unstoppable , In other words, we may have to customize the system for the application , To configure the hardware for a specific system .
1.2 The future development trend of database system

We just talked about three points , The first point is that application changes are driving the evolution of the system ; The second is that the change of software development mode actually brings about a change of system function ; Finally, the hardware platform . therefore , We think the trend of database development in the future :
- The first is “One size fits a bunch”, Building different systems for different applications , Configure different hardware for different systems . It's like Michael Stonebraker That's what I said , Database is not a system that can handle all applications . I think Stenberg At that time, it was aimed at the problems caused by the increase of application load , But when the bottleneck of hardware development comes , It will also lead us to agree with this view ,“One size does not fit all”, It's impossible to produce a system for all applications , It should be a kind of application corresponding to a set of system , This is an obvious trend that we have seen .
- The second trend is that there are more systems now , It needs synergy , There will be all kinds of middleware , There will be databases in various forms , We need to bring it together , There are too many forms of these databases , For programmers , The maintenance personnel are all one Disaster, The price will increase , How to better coordinate it , This is also a development direction in the future , We'll see that these systems are becoming more and more compatible with each other , More and more integrated .
- The third is that after the cloud platform has become a mainstream hardware platform , We can see that the database will develop further towards the cloud , It will be more suitable for the cloud form , Its elasticity , Self preservation 、 The ability of self-healing will be further improved . This is our outlook for the future .
02 Research on the database system of China Normal University
2.1 Research team

Then I'd like to introduce our current team , The school of data science and engineering of East China Normal University probably has 20 Multiple teachers , Probably 10 A teacher is engaged in the research of the database kernel . The history of the whole team is more than 20 Year of , We are close 10 In fact, I did a lot of research and development of the system kernel , We also cooperate with many companies in the industry . Our students have actually done a lot of engineering work .
Last year we got a second prize of national science and technology progress , This is based on a database product we made with a bank at that time , We are based on OceanBase A system implemented on an early open source version of , I will not introduce this kind of content too much , In fact, this system has been more in-depth application in a bank , It is a research achievement that we are proud of .
2.2 research findings
Our team's research is actually quite extensive , We do research in both transactional and analytical databases , But we're still more focused on transactional databases . And then next , I will introduce some typical research results , Let's take a look at what our research is doing , It is mainly divided into three parts , The first is distributed transactions , The second is the decoupling of database systems , The third is new hardware .
2.2.1 Distributed transactions
Distributed transaction is a topic that has been discussed for decades , In fact, there are some controversies : Whether distributed transactions work or not ? When we use this function of transaction processing , Should we avoid distributed transactions ? Or should we further enhance the database's ability to support distributed transactions , Let programmers not deliberately avoid distributed thinking ? This is actually a question , At present, there is no clear answer .
If distributed transactions do not work , Then we should do some other things , To make up for the defects of distributed transaction itself , There are two ways to do this :
- The first is not to provide distributed transaction function in database , Push transactions to the application , According to the characteristics of the application to avoid some defects of this distributed transaction .
- The second is to improve the ability of centralized transaction processing as much as possible , Distributed transactions can achieve the same effect as centralized transactions , There's no need for distributed transactions .
We think that now with NoSQL For the promoters of these systems represented , Actually, I hold this view . For example, the typical NoSQL Customer system MongoDB, Its general transaction processing or database access , All are Single Document Document by document . actually , If you really want to do complex transactions , Then go to the upper application to deal with , Deal with this kind of business in the most customized way , It can be more efficient .
Another view is that distributed transactions themselves should be viable , We should improve the database's ability to handle distributed transactions , Free developers .
The point of view is that those who push NewSQL The point of view of people in this kind of system , For example, Google's Spanner 、TiDB、OceanBase. So I want to do distributed transactions well , How to optimize , Improve the ability of distributed transactions ? First deal with the exception , One of the biggest fears of distributed transactions is the occurrence of exceptions , After something goes wrong , If it's a distributed transaction , Once a transaction locks the data on a node , If another node fails , It's going to be a lot of trouble . So in order to handle the exception , And then to Spanner As a representative , A lot of highly available system architectures are used , use Paxos/Raft Create this in the cloud platform , There's also a high availability infrastructure on this cheap computer , On this, I can avoid this kind of abnormal problem encountered by distributed transactions .
But apart from the anomalies , There is also the problem of scalability of distributed transactions . Although distributed transactions can be applied to reliable 、 On highly available systems , But its performance will be worse . therefore , We have to optimize its performance , For this reason, the academic community has made a lot of attempts , For the team , Recent years , We have also done some research and try . Next, I'll give you a general idea .
First , We need to understand what limits the scalability of distributed transactions , One of the most widely accepted ideas is that the main constraint of distributed transaction expansion is the blocking between things Blocking. You can imagine , When a thing goes to access data , Especially after a modification , It will lock , And then in the process of locking , And then we have to communicate with other nodes .
In fact, this kind of communication is time-consuming sometimes , Sometimes it's even necessary to communicate with other nodes , For example, to make high availability , You need to establish communication with nodes in other places . To communicate in the process of locking , Because the communication process is very long , Then it will make the lock up a special length , The blockage will become very serious . Once the blocking time of transaction increases , The throughput of its things may be seriously affected , Especially for the data with some hot spots , It's not a doubling of the duration , The performance is doubled , Sometimes it doubles , Performance can be reduced several times , This is a very troublesome problem .
So , Really want to solve the distributed expansion capabilities , On the premise that there is already high availability , Our most important goal is to reduce congestion . How to reduce congestion ? There are a lot of technologies that can be used . for instance MVCC/OCC、 MVCC It's multi version data management , It can reduce congestion , This is intuitive , I have multiple versions of a data , When one of my transactions changes the data , I directly generated a new version , So you don't have to stop people from reading your old version .
Because you have multiple versions , The new version is in the process of being produced , You can't read , You can read the old version without blocking , This is it. MVCC Use . then OCC It's the same , Namely OCC It's optimistic concurrency control , That is to say, no lock is required by default , Finally, check whether the transaction is executed correctly , If the execution is not correct, just overturn it . Then there are some lock optimizations , Through a variety of technologies , To minimize the congestion , To improve the ability of distributed transaction extension .
MVCC Time stamp allocation decentralized
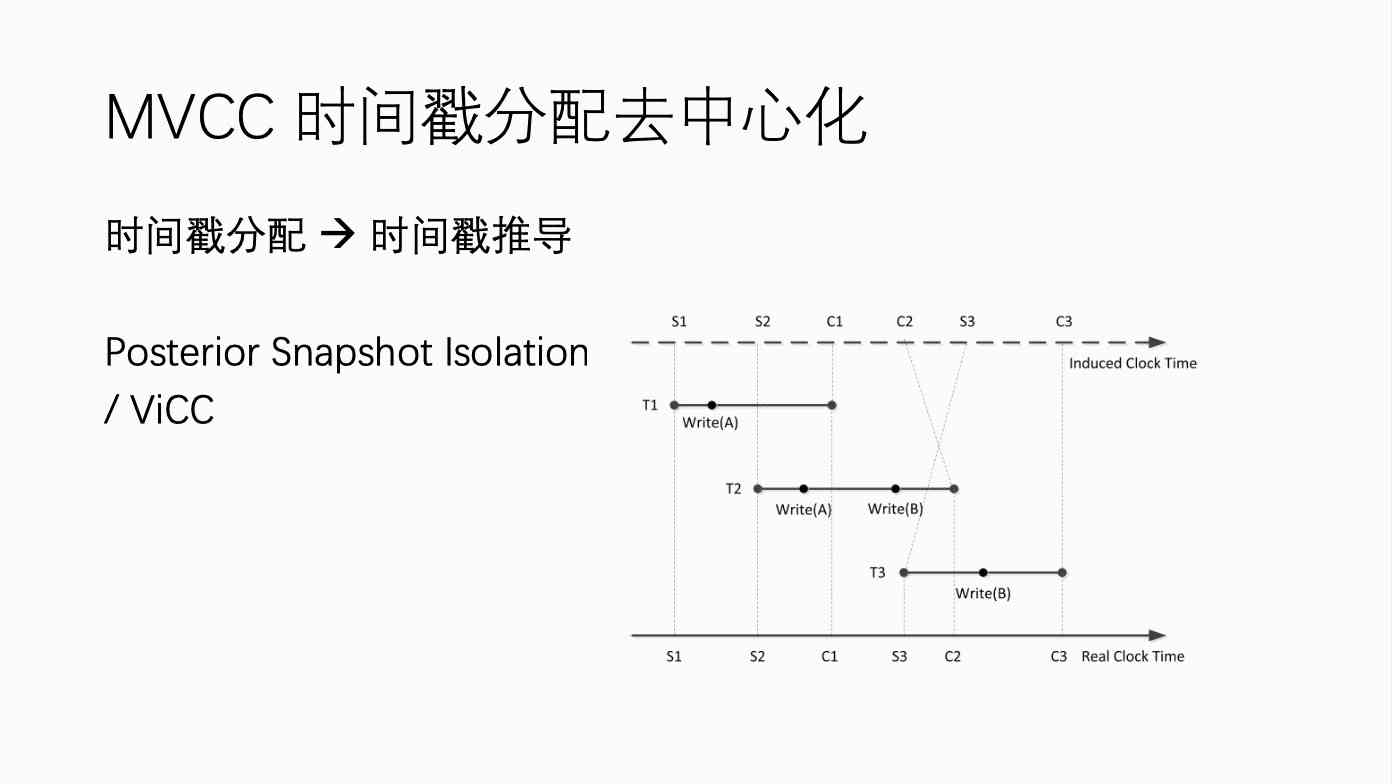
stay MVCC We've done some work . Of course MVCC There is a problem with timestamp allocation , That is to say, it is used to judge a transaction or a data or a version of a data , Whether it should be read by a transaction , It's going to be done by some time stamp judgment . The allocation of timestamps is cumbersome , Logically speaking , It should have a central clock , Everybody goes to the central clock to get the time stamp , This ensures that the transaction is correct . But usually if there is a central clock , Then the scalability is limited , Like Google's Spanner Use some atomic clocks to circumvent this problem . And then one of the research we did was decentralize , To optimize SI Isolation level .
SI It's a typical MVCC Isolation algorithm or concurrency control algorithm , It needs a timestamp . We did a decentralization . The idea is that when I assign a timestamp to a transaction , Not allocated at the beginning of a transaction , But at the end of the business , According to its relationship to other things 、 Conflict situation , To give it a proper timestamp , So it's called a posteriori timestamp ,Posterior SI. This way we can do this without having to do it with a central timestamp , But this thing is actually quite complicated to make , We're probably 5 I did it years ago , Finally, some experiments were not implemented in the real system , Because the implementation is relatively complex , In practice, a unified central timestamp is used , Basic applications can still be satisfied .
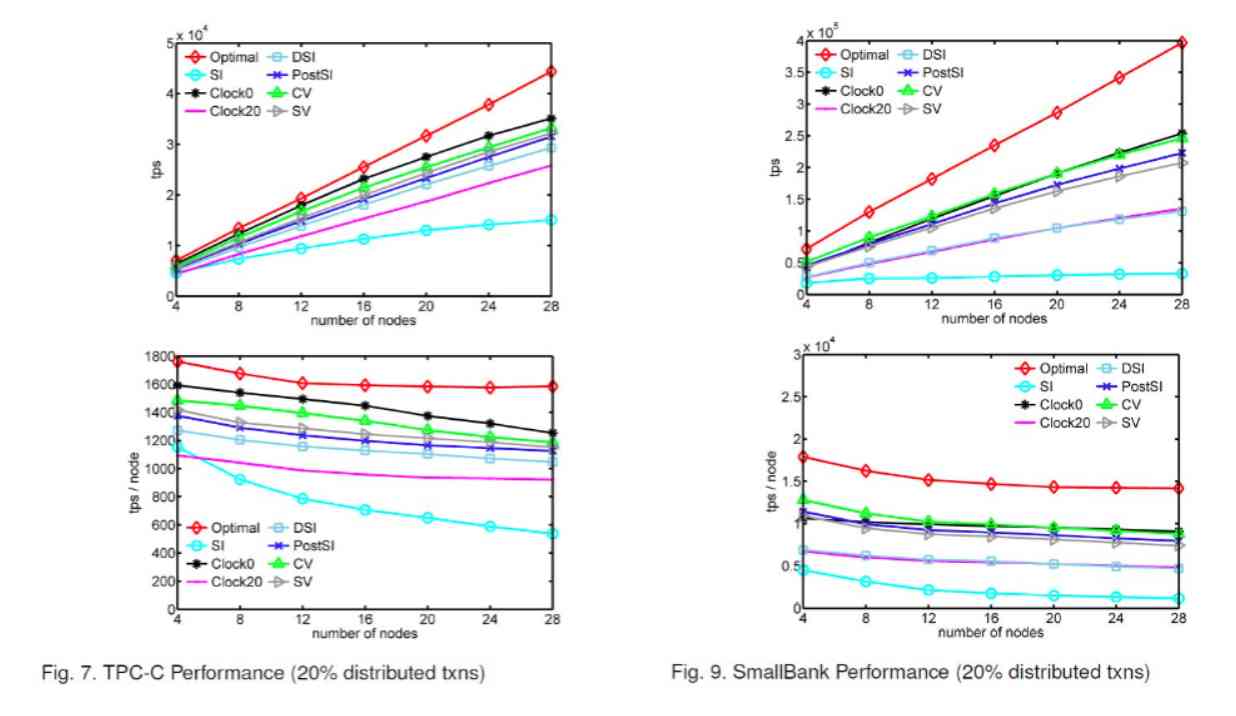
We did a lot of experiments , The experimental results show that our method , When it's expanded to a certain extent , This timestamp allocation is not going to be a scalability bottleneck .
Reduce OCC Blocking time of
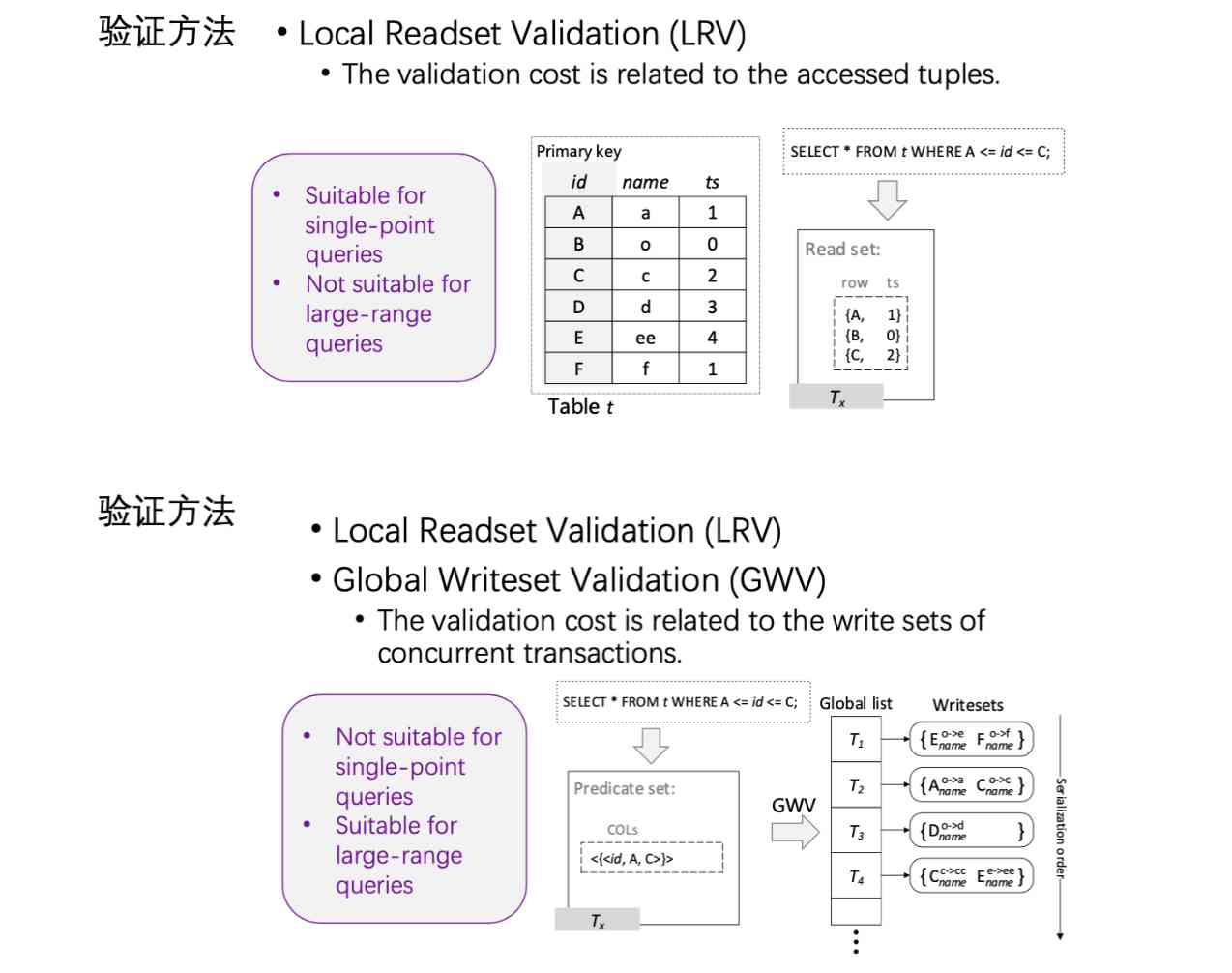
We've also done some OCC The job of .OCC When transactions access data , Let go of the business to visit , When the transaction is finished, a verification will be performed, called Validation, After verification , Then decide whether the transaction is committed or rolled back . This is also a way to reduce the blocking between transactions . In fact, the final correctness of this transaction is verified , Sometimes it takes time , So we did an optimization on this .
We think there are two ways to do correctness verification , One of the main ways is called Local Readset Validation, Each transaction records the data it has read , Finally, check whether the data you read has been changed . The disadvantage of this method is that when there is too much to read , It's going to cost a lot .
then , There's another way Global Writeset Validation, In this way, I don't record the data read by each transaction , Just keep track of how many running transactions are changing that data , In other words, it records the data that has been changed . And when I read it , Observe whether the scope of the data includes the modified data , If validation is included, it fails . This method is friendly to transactions with more data content , But for those small ones 、 Short business is not so friendly .
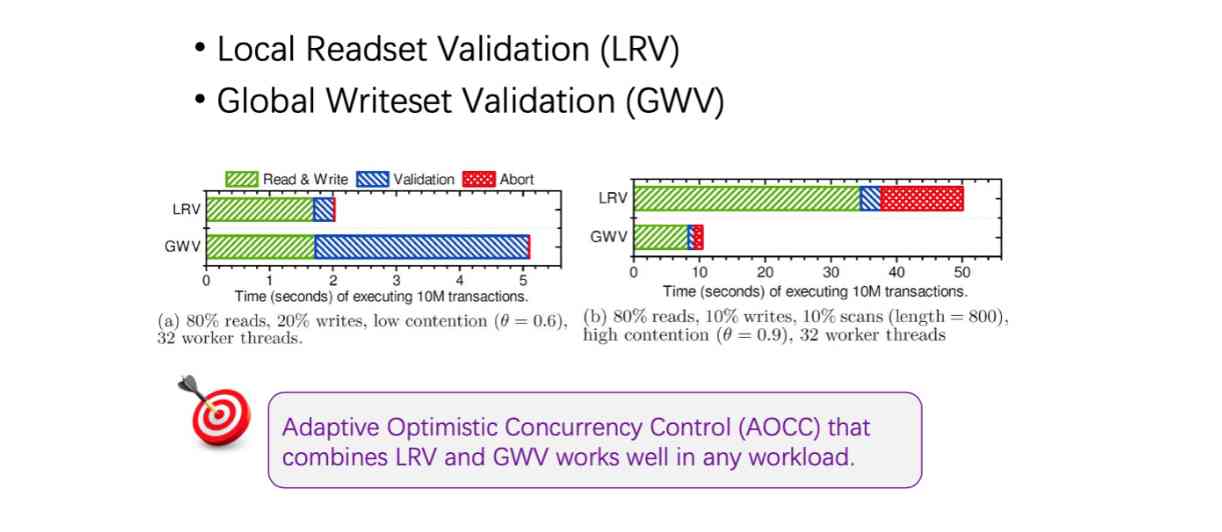
So we made one called AOCC,Adaptive OCC, It is to combine these two ways , We will judge the operation of a transaction , If you read a lot of data , Just use Writeset Validation; If you read very little , Just use Local Readset Validation, In this way, the advantages of the two methods are combined .

We did some experiments , In fact, it turns out that this approach has no flaws in extreme situations . Because the former one was reading books Receipt Validation and Receipt, Virtue in its own extreme cases will show a particularly poor performance . But our method is actually more balanced .
Lock duration of cross regional high availability system
And then the third one is about distributed transactions , It's that we did something like Spanner Such a system , High availability systems across regions .
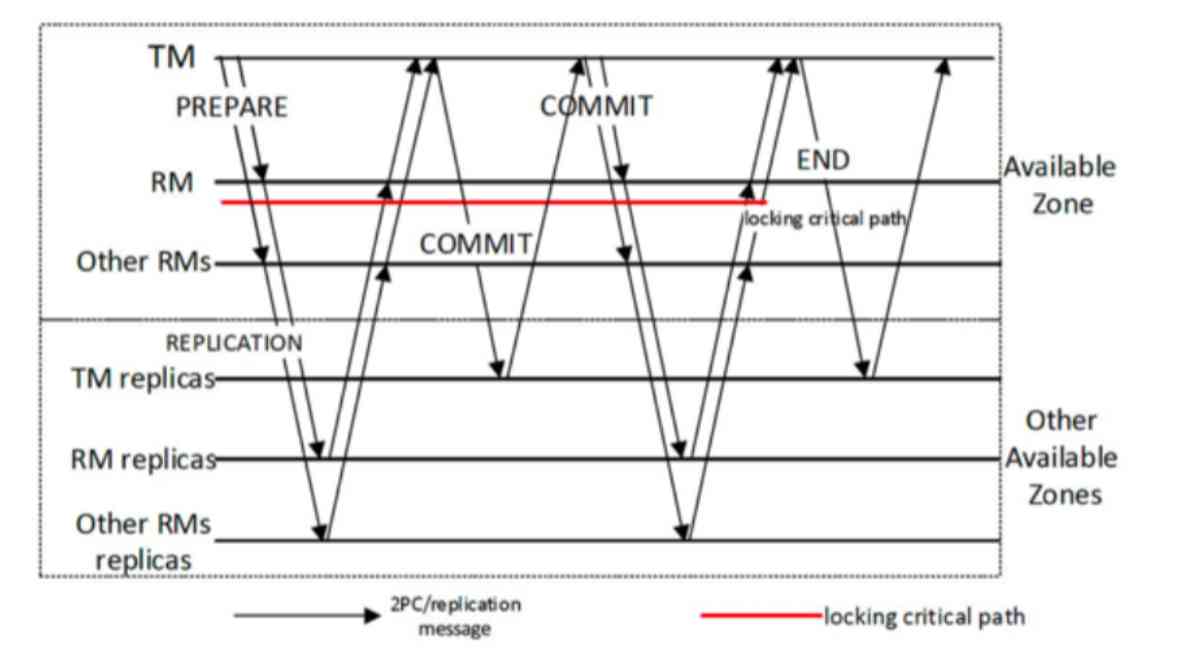
As I mentioned just now , Once locked , In the process of locking , There's cross regional data communication , This lock will last a long time . Here is an example , A two-phase commit on a cross regional highly available system . You can see that the red line is a locking process , This process is already the shortest locking process in a normal transaction , It locks before the transaction commit begins , Release the lock until the transaction is committed .
For a common business , It's locked in itself , But the lock time can be seen , In the process of locking ,Prepare There will be a large number of synchronization between local nodes and remote nodes , And then in Commit Stage , Similarly, there are a lot of synchronization between local nodes and remote nodes , Such a synchronization is time-consuming , If you do lock at this time , Once you encounter hot data access , The performance of this transaction will be extremely degraded . So under these conditions , We just want to know if we can avoid locking by releasing the lock in advance , Shorten the length of the lock , Directly reduce the blocking probability .
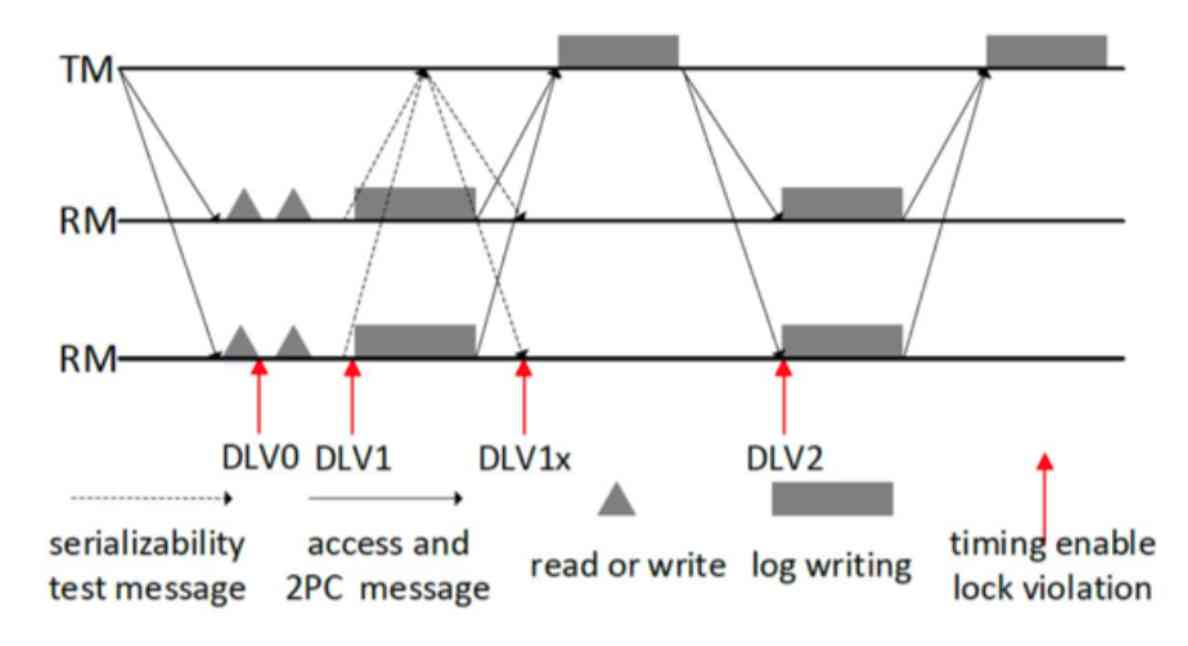
And then we designed something called DLV,LV It means Lock Violation, It's actually releasing the lock ahead of time .DLV Our name is Distributed Lock Violation, It's also a two-phase submission of an agreement . We'll see where the release facility is , Its efficiency is good . We chose four time points :
- The first is in prepare When accessing data before the phase , Access to a data, put a data lock , It's equivalent to not locking , This is one of the most extreme ways . But the rollback rate will be very high in this way , We can only judge whether the transaction is executed correctly by verification , Therefore, there will be a lot of deadlock situations , And then there are a lot of things that are not right .
- The second point in time is called DLV1, That is, in the transaction, data access is almost the same , But the coordination node is still unclear , In other words, it is not clear whether all transaction nodes have been completely completed , But all the transaction nodes think that when they finish themselves , This is the time to release the lock .
- The third point in time is an additional coordination process , The coordinating node will make a communication with all transaction nodes , After the communication is over , It thinks that all nodes are finished by this time , This is the time to release the lock .
- The fourth time point is after the end of the first phase of the two-phase submission , Release the lock again , This is the safest .
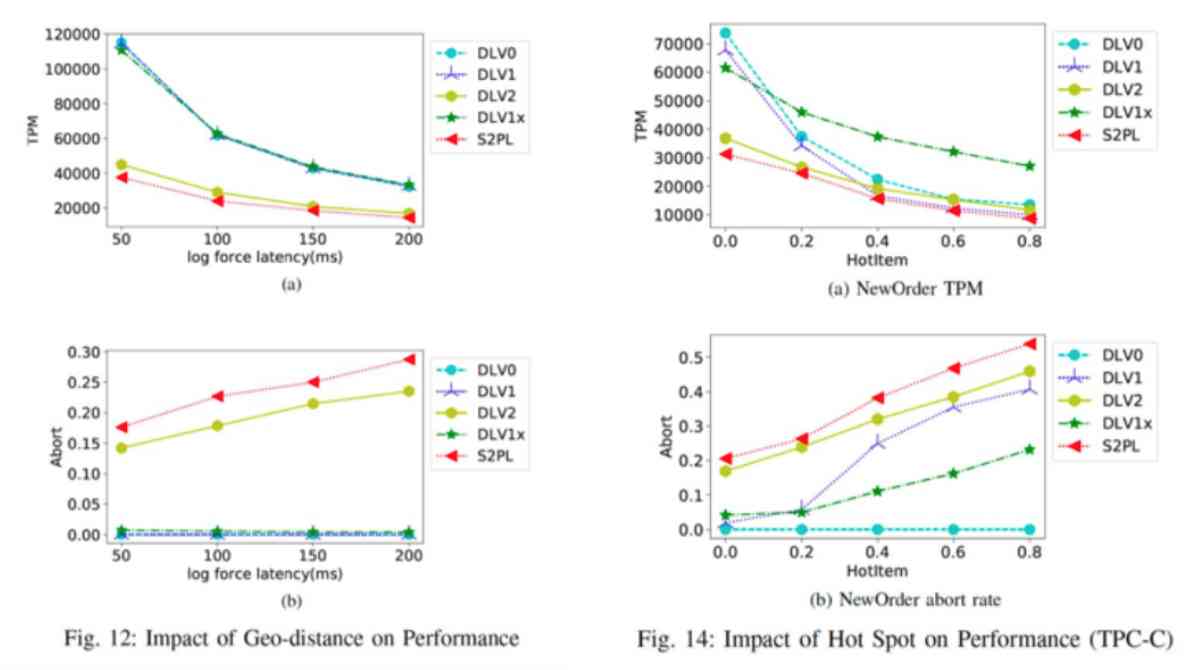
Then we experimented with these different ways of locking and releasing locks , One of the conclusions we got , The two pictures on the left ( The horizontal axis is the length of the telecommunication ) The further away the two computer centers are , The longer it takes to communicate , And then in this traditional way , You'll see that the longer it takes , The worse it's going to be . In high conflict situations , Distributed transaction processing performance will be poor . But if you use the way to release the lock in advance , Performance is the green blue line , It means that its performance will be greatly improved , This shows that it is useful to release the lock in advance .
But when is the best time to release the lock early ? And the last conclusion of an experiment we did on the right is that the third point in time is DLV1x This way, , The coordinator node has a short communication with the transaction phase , This is local communication , It's not remote communication , After communication, make sure that all nodes are finished , This is the time to release the lock , The least negative effect is that , And its lock time will be very short , In this way, it's the most efficient .
2.2.2 Database system decoupling
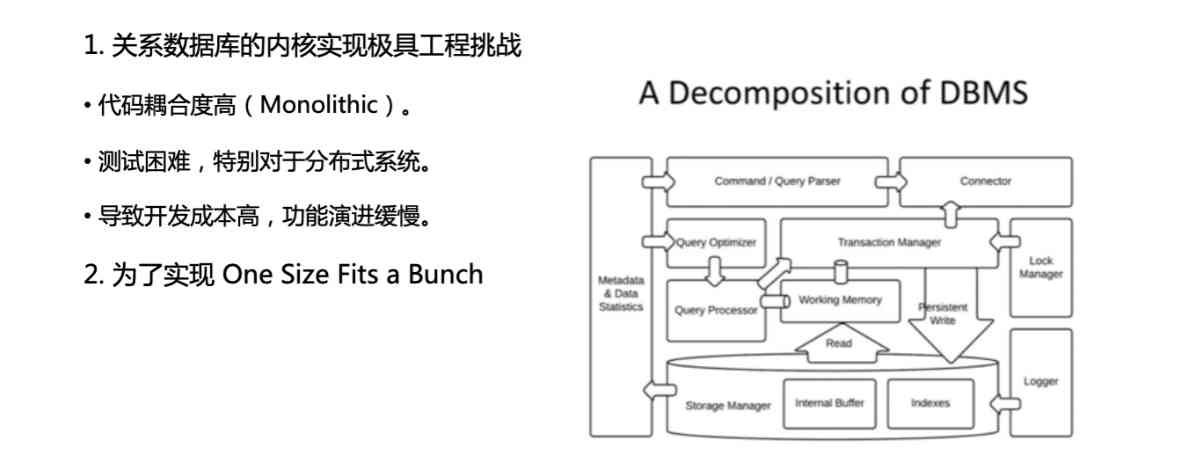
I just introduced three studies , It's all about distributed transaction processing , Then I'll talk about some of our research on database system decoupling , It's also a very interesting question . What is decoupling of database system ? In fact, textbooks break down the database system into modules , For example, this is collector It's the connector that connects to the application , also Query Optimize、Query Evaluator Or call it Query Processor, Is the query processing query optimization module ,New Storage Manager、New Transaction Manager, And all kinds of logs 、Lock、Manager wait , This is the segmentation of a database module in our textbook .
But actually, when we go to really look at the implementation of a database system , It will be found that these modules are actually not as clean as the segmentation , And sometimes it's really highly coupled between modules , It's tightly coupled . For someone who started to do a database, he would feel that it would be different from what we learned . And then very few people really explore why it's like this . When we implement a database system , In fact, this highly coupled system architecture brings us a lot of trouble .
We changed that in a bank OceanBase The system of , Changing a data type , It took me months to remember , A lot of people do it . This actually sounds quite surprising , But actually you look at the implementation of the system , That's what it's all about . A data type is used in many places , Every place has to be cleared away , At this time, you have to spend a lot of time reading code to understand and test . In fact, we think that if the coupling degree of a system can be reduced , Modules can be clearly separated , In fact, it has great benefits for system engineering .
Let's review the development trend of a database , It's called “One size fits a bunch”, In other words, we think the system will become very customized in the future . If a system is well modularized , It's easy to customize and change the system . Once a new hardware comes along , We're going to use new hardware to optimize the system , It's going to be easier .
In fact, the implementation of a database system , It is necessary to do further decoupling , There are many problems in this . We went to do some exploration , But it's a very limited exploration , I think this job can be done by more people . The exploration we're doing , That is to say, you want to take concurrency control out of the storage layer of the database , Then make the stored code and concurrency control code as unrelated as possible .

This is a B-Tree Of Search Function Example , In the textbook , About B-Tree Of Search, You might see a code like this , It's simple .

But actually one B-Tree Of Search It's not that simple , You can see that there are a lot of things in it , This is just an example . If you're familiar with open source systems , A general open source system B-Tree, Almost 100000 lines of code , Very complicated .
Why is this code so complicated ? You can see B-Tree There are lots of locks in it , For example Latch、Lock A lot of things like that , It's actually doing concurrency control . Of course, concurrency control is only one of the reasons for code complexity , But there are other reasons , Concurrency control makes this code far more complex than B-tree The degree of its function . In fact, this is one of the motivations for database decoupling , If you can untie the coupling , Concurrency control can be left to a separate module ,B-Tree The code can be written as in the first example , It becomes very simple .
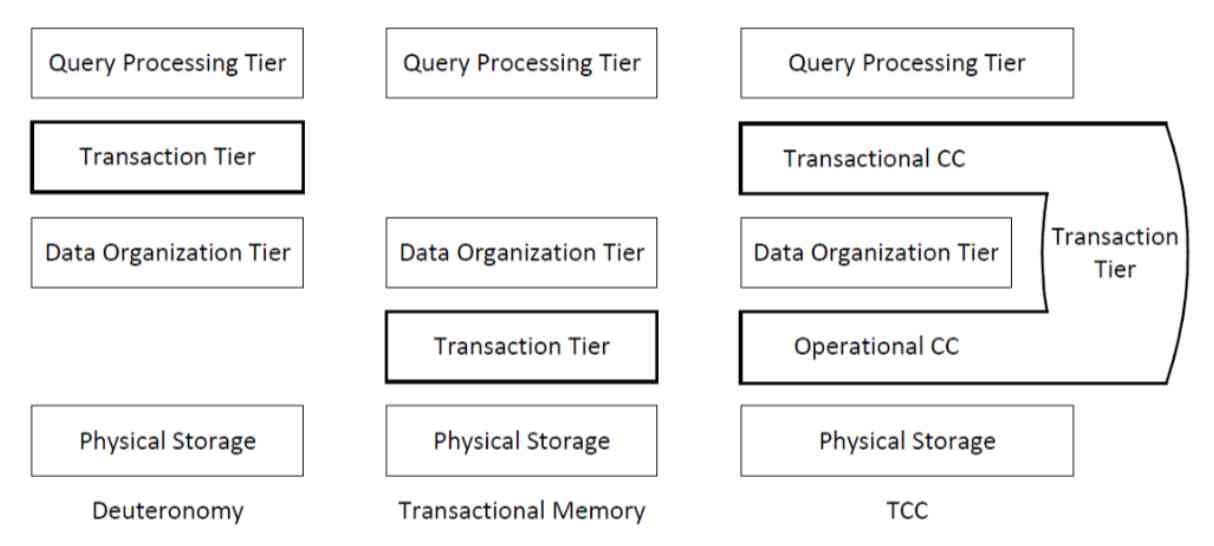
therefore , We thought if we put CC It is how to decouple concurrency control from the database system ? There are many ways , The one on the far left is actually a more traditional way , This approach doesn't actually make the database storage layer any easier , It's just a transaction layer on the storage floor , This is a relatively shallow approach . This is a very violent practice in the middle , It's a physical storage plus a Transaction Tier, And then we do storage and operations on it .
You should have heard Transactional Memory, It's transactional memory , This is to do transaction processing directly with transaction memory , It's a very violent way . On the far right is the way we propose it , The level of concurrency control is divided into two levels , One is the concurrency control we call the operation layer , One is concurrency control of transaction layer , Put them all together into a new module . In practice, the effect of our method is obviously better , This kind of violent transaction memory way , In fact, performance is not acceptable .
In fact, we see that there are some students doing storage now , He has some naive ideas , He thought that the transaction should be at the bottom of the storage , And then there's no need to care about things , In fact, that doesn't work . There are many coupling factors between transaction and system function , You can't throw it away completely . And then on the far left, the result is incomplete , Realization B-tree It's going to be complicated . And then we propose this approach , You can clearly put CC Take it out .
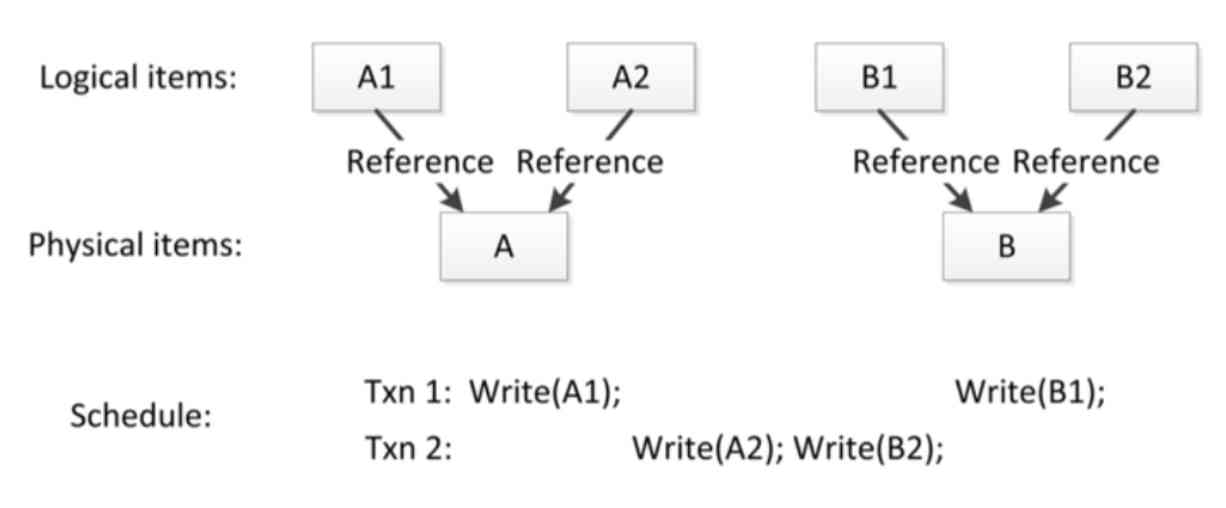
It's not that simple , The above is a very simple example ,A and B It's two physical data , And then in the data structure of the database , Define two quotes (Reference),A1 and A2,B1 and B2,A1 and A2 Is directed A Of ,B1 and B2 Is directed B Of . The transaction layer above is actually about A1、A2、B1、B2 visiting . At this time, if only through the logical level to determine whether things and things conflict , It's going to go wrong . Because the logical layer and the physical layer here , There is a relationship of repeated references , You can see the transaction below Schedule, from A1、A2、B1、B2 This way to see , It seems that the two transactions can be handled in this way , It has this serializable capability , But it didn't , because A1 and A2 It points to the same data .
This actually means that if you really want to pull this business out , There will be many problems to be solved , I can't go into it here , All in all, we made such an attempt , Our name is Transparent Concurrency Control(TCC), It's a mode of transparent concurrency control .
We split the transaction layer into two layers , One is concurrency control at transaction level , One is concurrency control at the operation level , Make these two things work together . And then when the user goes to write the program , He doesn't care about concurrency , He went straight to write his B-Tree That's it . But write well B-Tree after , This concurrency control at the transaction level , Some semantic information is needed to show which operation and which operation will not conflict in fact , In this way, the correctness and efficiency of the whole transaction processing can be guaranteed .
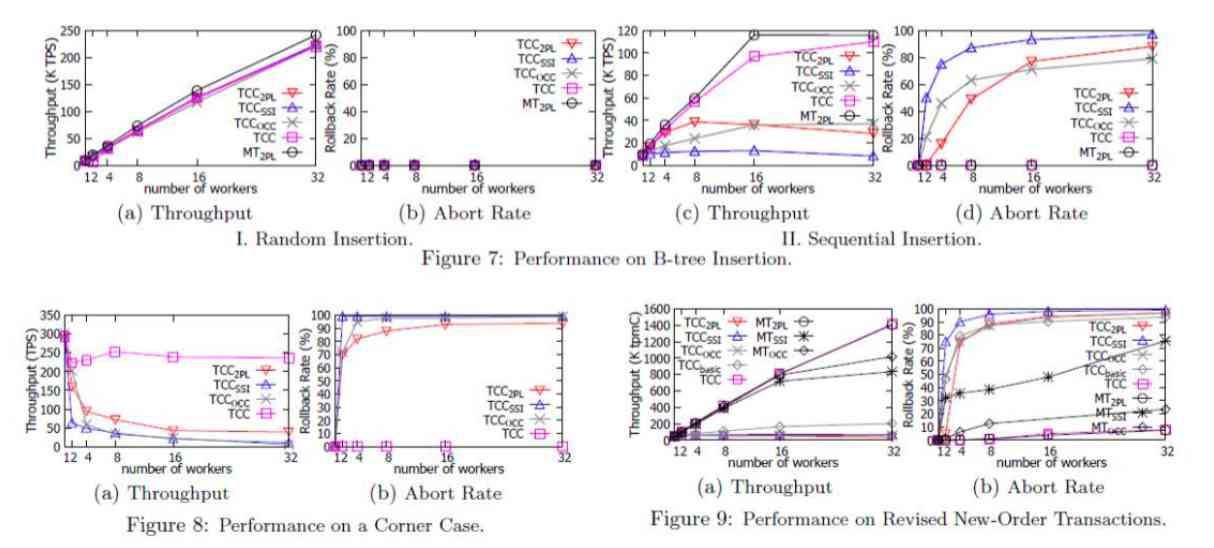
We did some experiments , To verify such a decoupling . The pictures on the right , This line of circles represents the performance of the original database implementation , You can see our way (TCC) In many cases, the performance of the original database can be close to that of the original database , This is how the database behaves after decoupling . In many cases, the performance after decoupling can approach the performance of the original database , So we think this decoupling is actually feasible . But if you really want to use it in a real system , It's not that simple . This is the second research work that I introduced , It's some of our interesting findings on database decoupling .
2.2.3 New hardware

Finally, let me talk about the new hardware , It's this kind of nonvolatile memory . Intel's Arten is the only true nonvolatile memory product on the market , In the picture are the relevant indicators of the product . For memory devices , We usually look at two indicators , One is bandwidth , One is delay .
You can see that its bandwidth and latency are far beyond SSD, Of course, more than this kind of hard disk . It will cost more than SSD And hard drives are a lot more expensive , But relative to memory , It's still cheap , We can predict that it will be cheaper and cheaper later , It goes with SSD The difference between a price will become smaller and smaller , So it's likely to replace SSD This kind of SSD , But it's not too early . This new storage , It has better performance , And it's cheaper than memory , So it must have a very important position in the system in the future . Now with this hardware , We need to discuss in the database system , What exactly does this hardware do , How a new database architecture should use it ? How to position its value and position ?

Our team has been talking about this for a long time , Finally, there's a design like this , First of all, nonvolatile memory , Of course, it needs to be used in the database , Databases have various forms of databases , Different forms of database use is not the same , But we ended up positioning it on the cloud database , Because we know that the cloud is the main architecture in the future . How to use this in the cloud database , We think it's like RDMA The use of should be combined .
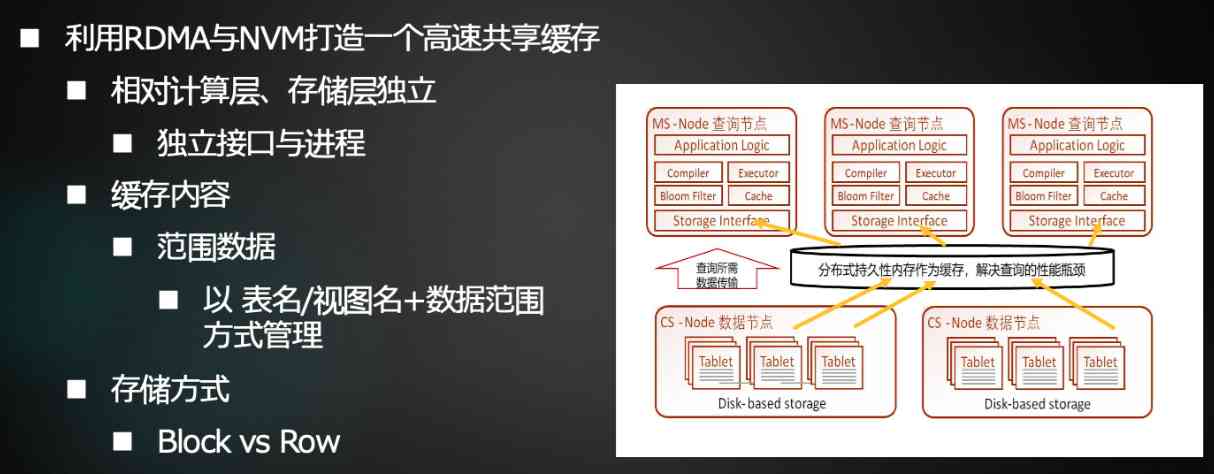
Now cloud database becomes a relatively separate architecture between computing nodes and storage nodes . And then once NVM After adding in , We want it to be a cache between computing nodes and storage nodes . We don't think it can be used to store full data for the time being , Because it's really expensive , A lot of cold data , There's no need to have such expensive storage , So it acts as a cache , More appropriate .
On the other hand , It serves as a cache , It shouldn't be a fragmented node , Because we're going to look at its performance indicators , You can see that in fact, this non-volatile memory throughput 、 Delay , And on high-speed networks RDMA The throughput and latency are close to each other . If it's closer , This is through the device RDMA Remote access to , Or the difference in the speed of local access may not be great . If the difference in speed is not big , We can actually put multiple nodes NVM United together , As a shared cache , Cache sharing has many advantages , It saves a lot of the cost of cache data synchronization , Then it can also make the load balancing of the system better .
The architecture of a system determines the design of such a system . This is NVM, We call it a cache between storage nodes and computing nodes .

We are in the process of doing this , So we have implemented a distributed cache so far , It can be used as a shared cache . We started to talk about it as a database , Is it a row level cache or a block level cache , Finally, our choice is block level caching , The main reason is that it is easier to implement . Let's have a try first , If you do line level caching , It's a lot of work , We may try again later .
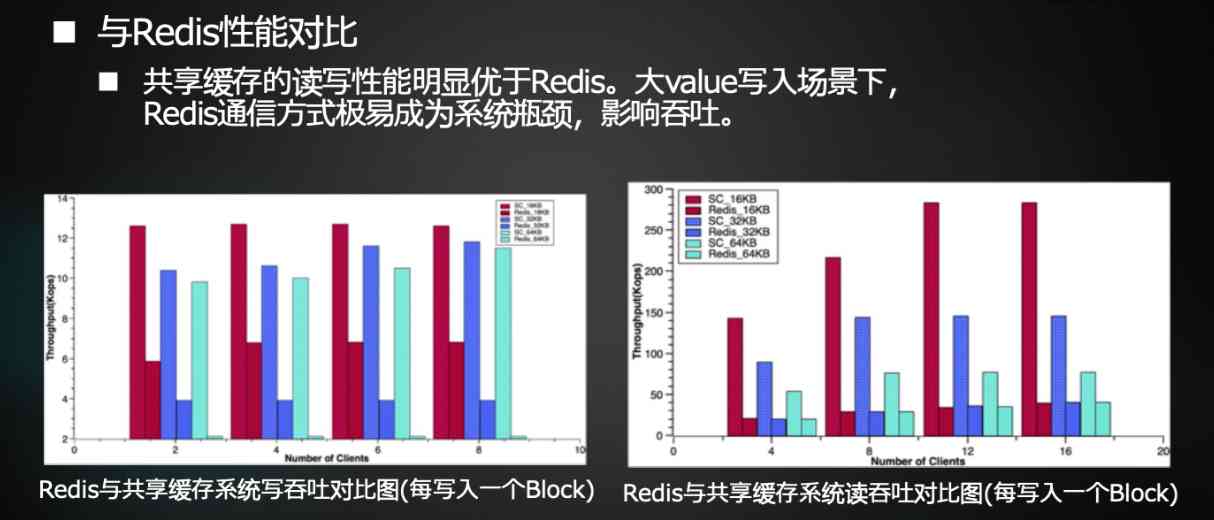
And then the basic cache test , We feel that our implementation is basically in place , It is that the bottleneck of its bandwidth is basically pressed to RDMA The bottleneck of access bandwidth , If you want to read and write it , Its bottleneck is basically RDMA The bottleneck of remote access , And then its performance is much better than that like Redis Such a systematic , We want to use this cache to put it in the database , To improve the performance of this cloud database , But this process is still in the process of implementation , We have some preliminary results , It has some effect , Especially in the face of the bottom SSD Or a system like disk . We hope there will be more definite results later , Let me introduce you to .
03 List of related papers

Here are some representative papers from our lab , Not very complete , Some of the technologies I just talked about are not listed , Because it hasn't been published yet . If you're interested , You can read it .
Written in the back
So is Professor Zhou Ji of East China Normal University 2020-2021 Cooperative scholar of the annual research project of meituan . At present, meituan's technical team is more than 30 Scholars from universities and scientific research institutes at home and abroad have established scientific research cooperation . Meituan scientific research cooperation program , Based on the scientific research proposition extracted by meituan in the field of life service , Seeking cutting edge solutions for academia .
We are committed to working with academia “ Working together to solve real world problems ”, We are willing to work with the academic community to promote the implementation of industry university research achievements .2021 The year will be even more exciting , Coming soon .
Want to read more technical articles , Please pay attention to meituan's technical team (meituantech) Official WeChat official account .

版权声明
本文为[Meituan technical team]所创,转载请带上原文链接,感谢
边栏推荐
- Zero basis to build a web search engine of its own
- 检测证书过期脚本
- All the way, I was forced to talk about C code debugging skills and remote debugging
- html+ vue.js Implementing paging compatible IE
- An article takes you to understand CSS pagination examples
- An article takes you to understand CSS gradient knowledge
- IPFs rudder filecoin landing at the same time, fil currency price broke a thousand
- Diamond standard
- Description of phpshe SMS plug-in
- Summary of front-end performance optimization that every front-end engineer should understand:
猜你喜欢

ORA-02292: 违反完整约束条件 (MIDBJDEV2.SYS_C0020757) - 已找到子记录
ERD-ONLINE 免费在线数据库建模工具
An article taught you to download cool dog music using Python web crawler
How to prepare for the system design interview
Look! Internet, e-commerce offline big data analysis best practice! (Internet disk link attached)
细数软件工程----各阶段必不可少的那些图
An article will introduce you to HTML tables and their main attributes
STM32F030F4P6兼容灵动微MM32F031F4P6
Novice guidance and event management system in game development
Road to simple HTML + JS to achieve the most simple game Tetris
随机推荐
Python 100 cases
STM32F030K6T6兼容替换灵动MM32F031K6T6
CCR coin frying robot: the boss of bitcoin digital currency, what you have to know
How much disk space does a file of 1 byte actually occupy
Try to build my mall from scratch (2): use JWT to protect our information security and perfect swagger configuration
Basic usage of Vue codemirror: search function, code folding function, get editor value and verify in time
Ronglian completed US $125 million f round financing
The legality of IPFs / filecoin: protecting personal privacy from disclosure
Using iceberg on kubernetes to create a new generation of cloud original data Lake
2020-09-04:函数调用约定了解么?
Share with Lianyun: is IPFs / filecoin worth investing in?
jenkins安装部署过程简记
事务的本质和死锁的原理
An article taught you to use HTML5 SVG tags
Metersphere developer's Manual
window系统 本机查找端口号占用方法
Road to simple HTML + JS to achieve the most simple game Tetris
[forward] how to view UserData in Lua
Stickinengine architecture 11 message queue
2020-08-20:GO语言中的协程与Python中的协程的区别?