当前位置:网站首页>Building a new generation cloud native data lake with iceberg on kubernetes
Building a new generation cloud native data lake with iceberg on kubernetes
2020-11-06 20:17:00 【Tencent cloud native】
background
Big data has developed so far , according to Google 2003 Published in 《The Google File System》 The first paper starts with , Have passed by 17 A year . It is a pity Google There was no open source technology ,“ only ” Three technical papers have been published . So look back , It can only be regarded as opening the curtain of the era of big data . With Hadoop The birth of , Big data has entered an era of rapid development , The dividend and commercial value of big data are also being released . Nowadays, the demand for big data storage and processing is becoming more and more diversified , After Hadoop Time , How to build a unified data Lake storage , And carry out various forms of data analysis on it , It has become an important direction for enterprises to build big data ecology . How fast 、 Agreement 、 Atomically build on data Lake storage Data Pipeline, Has become an urgent problem . And with the advent of the cloud age , The cloud's inherent ability to automate deployment and delivery is also catalyzing this process . This article mainly introduces how to use Iceberg And Kubernetes Create a new generation of cloud native data Lake .
What is the Iceberg
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table.
Apache Iceberg By Netflix Open source development , In its 2018 year 11 month 16 The day enters Apache The incubator , yes Netflix Company data warehouse Foundation .Iceberg It's essentially a tabular standard designed for massive analysis , It can be a mainstream computing engine such as Presto、Spark Provides high-performance read-write and metadata management capabilities .Iceberg Don't focus on the underlying storage ( Such as HDFS) And table structure ( Business definition ), It provides an abstraction layer between the two , Organizing data and metadata .
Iceberg Key features include :
- ACID: Have ACID Ability , Support row level update/delete; Support serializable isolation And multiple concurrent writers
- Table Evolution: Support inplace table evolution(schema & partition), Iconicity SQL Same operation table schema; Support hidden partitioning, The user does not need to display the specified
- Interface generalization : Provide rich table operation interface for upper data processing engine ; Shielding the underlying data storage format differences , Provide right Parquet、ORC and Avro Format support
Depending on the above features ,Iceberg It can help users achieve low cost T+0 Level data Lake .
Iceberg on Kubernetes
In the traditional way , Users usually use manual or semi-automatic methods when deploying and maintaining big data platforms , This often takes a lot of manpower , Stability is not guaranteed .Kubernetes Appearance , Revolutionized the process .Kubernetes It provides application deployment and operation and maintenance standardization capabilities , The user business is being implemented Kubernetes After transformation , Can run on all other standards Kubernetes In the cluster . In the field of big data , This capability can help users quickly deploy and deliver big data platforms ( Big data component deployment is particularly complex ). Especially in the architecture of big data computing and storage separation ,Kubernetes Cluster provides Serverless Ability , It can help users run computing tasks out of the box . And then with the off-line hybrid scheme , In addition to unified management and control of resources to reduce complexity and risk , Cluster utilization will also be further improved , Cut costs dramatically .
We can base it on Kubernetes structure Hadoop Big data platform : 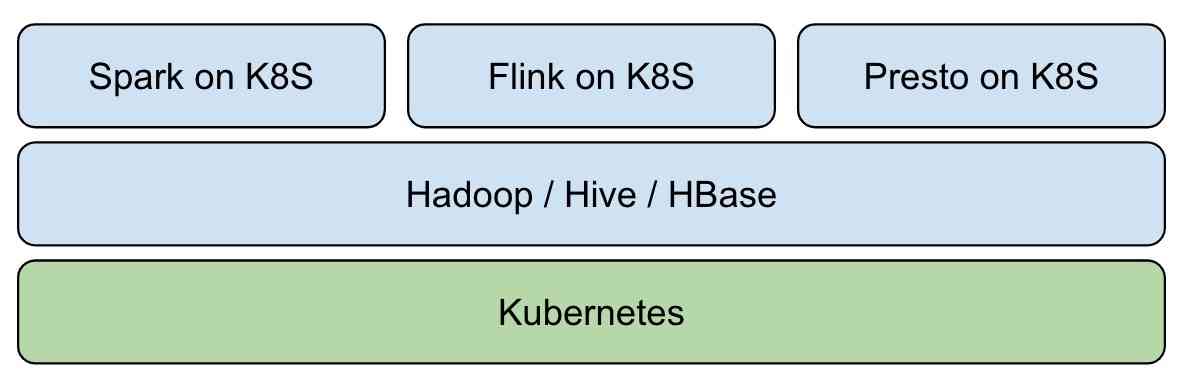 In the hot data Lake area in recent years , Through traditional Hadoop Ecological construction real-time data Lake , Subject to component positioning and Design , More complex and difficult .Iceberg The emergence of open source technology makes it possible to build a real-time data Lake quickly , This is also the future development direction of big data - Real time analysis 、 Canghu Lake integration and cloud origin . introduce Iceberg after , The overall architecture becomes :
In the hot data Lake area in recent years , Through traditional Hadoop Ecological construction real-time data Lake , Subject to component positioning and Design , More complex and difficult .Iceberg The emergence of open source technology makes it possible to build a real-time data Lake quickly , This is also the future development direction of big data - Real time analysis 、 Canghu Lake integration and cloud origin . introduce Iceberg after , The overall architecture becomes : 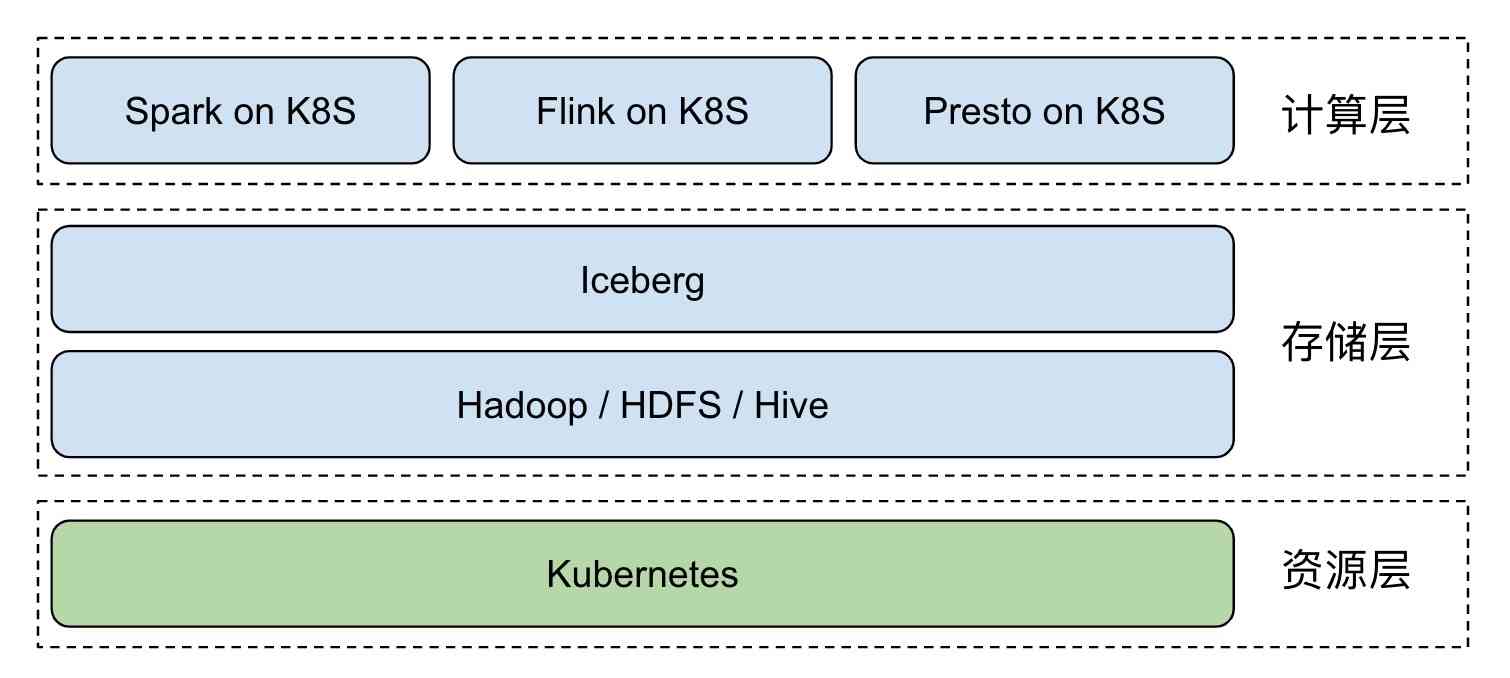 Kubernetes Responsible for application automation deployment and resource management scheduling , Shield the upper layer from the complexity of the underlying environment .Iceberg + Hive MetaStore + HDFS Based on Hadoop Real time data lake of Ecology , Provide data access and storage for big data applications .Spark、Flink Wait for the computing engine to native The way it works is Kubernetes In the cluster , Resources are available as soon as they are available . After mixing with online business , It can greatly improve the utilization of cluster resources .
Kubernetes Responsible for application automation deployment and resource management scheduling , Shield the upper layer from the complexity of the underlying environment .Iceberg + Hive MetaStore + HDFS Based on Hadoop Real time data lake of Ecology , Provide data access and storage for big data applications .Spark、Flink Wait for the computing engine to native The way it works is Kubernetes In the cluster , Resources are available as soon as they are available . After mixing with online business , It can greatly improve the utilization of cluster resources .
How to build cloud native real-time data Lake
Architecture diagram
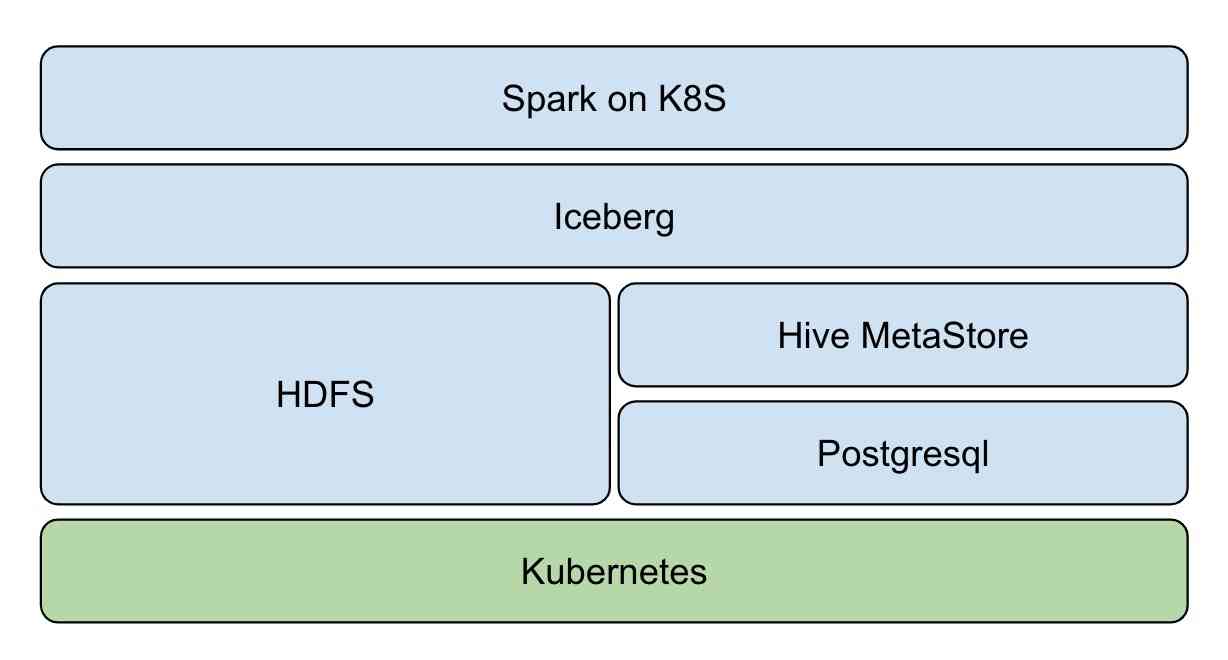
- Resource layer :Kubernetes Provide resource management capabilities
- The data layer :Iceberg Provide ACID、table Access to data sets
- Storage layer :HDFS Provide data storage capacity ,Hive MetaStore management Iceberg Table metadata ,Postgresql As Hive MetaStore Storage back end
- Computing layer :Spark native on Kubernetes, Provide streaming batch computing capability
establish Kubernetes colony
First, deploy through official binary or automated deployment tools Kubernetes colony , Such as kubeadm, It is recommended to use Tencent cloud to create TKE colony .  Recommended configuration is :3 platform S2.2XLARGE16(8 nucleus 16G) example
Recommended configuration is :3 platform S2.2XLARGE16(8 nucleus 16G) example
Deploy Hadoop colony
Open source Helm Plug in or custom image in Kubernetes Upper Department Hadoop colony , Main deployment HDFS、Hive MetaStore Components . Tencent's cloud TKE Recommended in k8s-big-data-suite Automatic deployment of big data applications Hadoop colony . 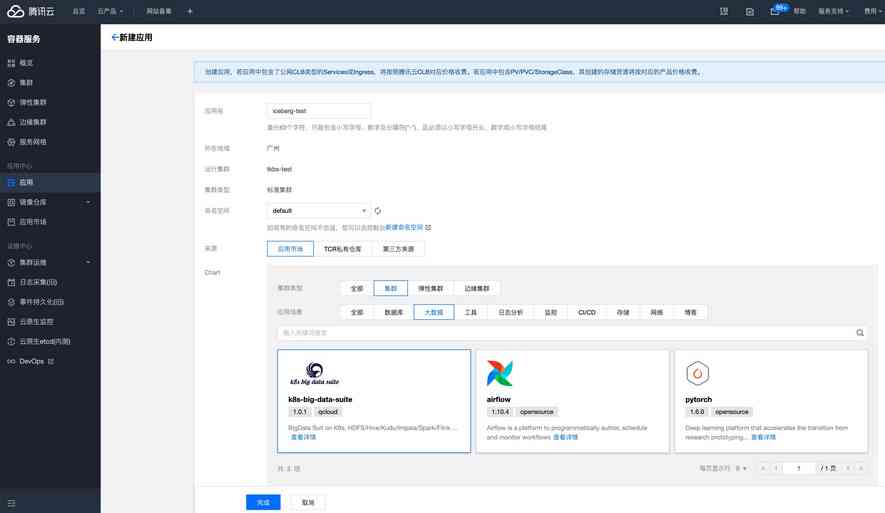 k8s-big-data-suite It's a big data suite developed by US based on our production experience , Support mainstream big data components in Kubernetes Last click to deploy . Before deployment, please do cluster initialization as required :
k8s-big-data-suite It's a big data suite developed by US based on our production experience , Support mainstream big data components in Kubernetes Last click to deploy . Before deployment, please do cluster initialization as required :
# Identify the storage node , At least three
$ kubectl label node xxx storage=true
After successful deployment , Link in TKE Cluster view component status :
$ kubectl get po
NAME READY STATUS RESTARTS AGE
alertmanager-tkbs-prometheus-operator-alertmanager-0 2/2 Running 0 6d23h
cert-job-kv5tm 0/1 Completed 0 6d23h
elasticsearch-master-0 1/1 Running 0 6d23h
elasticsearch-master-1 1/1 Running 0 6d23h
flink-operator-controller-manager-9485b8f4c-75zvb 2/2 Running 0 6d23h
kudu-master-0 2/2 Running 2034 6d23h
kudu-master-1 2/2 Running 0 6d23h
kudu-master-2 2/2 Running 0 6d23h
kudu-tserver-0 1/1 Running 0 6d23h
kudu-tserver-1 1/1 Running 0 6d23h
kudu-tserver-2 1/1 Running 0 6d23h
prometheus-tkbs-prometheus-operator-prometheus-0 3/3 Running 0 6d23h
superset-init-db-g6nz2 0/1 Completed 0 6d23h
thrift-jdbcodbc-server-1603699044755-exec-1 1/1 Running 0 6d23h
tkbs-admission-5559c4cddf-w7wtf 1/1 Running 0 6d23h
tkbs-admission-init-x8sqd 0/1 Completed 0 6d23h
tkbs-airflow-scheduler-5d44f5bf66-5hd8k 1/1 Running 2 6d23h
tkbs-airflow-web-84579bc4cd-6dftv 1/1 Running 2 6d23h
tkbs-client-844559f5d7-r86rb 1/1 Running 6 6d23h
tkbs-controllers-6b9b95d768-vr7t5 1/1 Running 0 6d23h
tkbs-cp-kafka-0 3/3 Running 2 6d23h
tkbs-cp-kafka-1 3/3 Running 2 6d23h
tkbs-cp-kafka-2 3/3 Running 2 6d23h
tkbs-cp-kafka-connect-657bdff584-g9f2r 2/2 Running 2 6d23h
tkbs-cp-schema-registry-84cd7cbdbc-d28jk 2/2 Running 4 6d23h
tkbs-grafana-68586d8f97-zbc2m 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-dn-6jng4 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-dn-rn8z9 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-dn-t68zq 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-jn-0 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-jn-1 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-jn-2 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-nn-0 2/2 Running 5 6d23h
tkbs-hadoop-hdfs-nn-1 2/2 Running 0 6d23h
tkbs-hbase-master-0 1/1 Running 3 6d23h
tkbs-hbase-master-1 1/1 Running 0 6d23h
tkbs-hbase-rs-0 1/1 Running 3 6d23h
tkbs-hbase-rs-1 1/1 Running 0 6d23h
tkbs-hbase-rs-2 1/1 Running 0 6d23h
tkbs-hive-metastore-0 2/2 Running 0 6d23h
tkbs-hive-metastore-1 2/2 Running 0 6d23h
tkbs-hive-server-8649cb7446-jq426 2/2 Running 1 6d23h
tkbs-impala-catalogd-6f46fd97c6-b6j7b 1/1 Running 0 6d23h
tkbs-impala-coord-exec-0 1/1 Running 7 6d23h
tkbs-impala-coord-exec-1 1/1 Running 7 6d23h
tkbs-impala-coord-exec-2 1/1 Running 7 6d23h
tkbs-impala-shell-844796695-fgsjt 1/1 Running 0 6d23h
tkbs-impala-statestored-798d44765f-ffp82 1/1 Running 0 6d23h
tkbs-kibana-7994978d8f-5fbcx 1/1 Running 0 6d23h
tkbs-kube-state-metrics-57ff4b79cb-lmsxp 1/1 Running 0 6d23h
tkbs-loki-0 1/1 Running 0 6d23h
tkbs-mist-d88b8bc67-s8pxx 1/1 Running 0 6d23h
tkbs-nginx-ingress-controller-87b7fb9bb-mpgtj 1/1 Running 0 6d23h
tkbs-nginx-ingress-default-backend-6857b58896-rgc5c 1/1 Running 0 6d23h
tkbs-nginx-proxy-64964c4c79-7xqx6 1/1 Running 6 6d23h
tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 6d23h
tkbs-postgresql-ha-pgpool-5cbf85d847-v5dsr 1/1 Running 1 6d23h
tkbs-postgresql-ha-postgresql-0 2/2 Running 0 6d23h
tkbs-postgresql-ha-postgresql-1 2/2 Running 0 6d23h
tkbs-prometheus-node-exporter-bdp9v 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-cdrqr 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-cv767 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-l82wp 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-nb4pk 1/1 Running 0 6d23h
tkbs-prometheus-operator-operator-f74dd4f6f-lnscv 2/2 Running 0 6d23h
tkbs-promtail-d6r9r 1/1 Running 0 6d23h
tkbs-promtail-gd5nz 1/1 Running 0 6d23h
tkbs-promtail-l9kjw 1/1 Running 0 6d23h
tkbs-promtail-llwvh 1/1 Running 0 6d23h
tkbs-promtail-prgt9 1/1 Running 0 6d23h
tkbs-scheduler-74f5777c5d-hr88l 1/1 Running 0 6d23h
tkbs-spark-history-7d78cf8b56-82xg7 1/1 Running 4 6d23h
tkbs-spark-thirftserver-5757f9588d-gdnzz 1/1 Running 4 6d23h
tkbs-sparkoperator-f9fc5b8bf-8s4m2 1/1 Running 0 6d23h
tkbs-sparkoperator-f9fc5b8bf-m9pjk 1/1 Running 0 6d23h
tkbs-sparkoperator-webhook-init-m6fn5 0/1 Completed 0 6d23h
tkbs-superset-54d587c867-b99kw 1/1 Running 0 6d23h
tkbs-zeppelin-controller-65c454cfb9-m4snp 1/1 Running 0 6d23h
tkbs-zookeeper-0 3/3 Running 0 6d23h
tkbs-zookeeper-1 3/3 Running 0 6d23h
tkbs-zookeeper-2 3/3 Running 0 6d23h
Be careful
At present TKE k8s-big-data-suite 1.0.3 Initializing Postgresql when , Missing right Hive transaction Support for , Which leads to Iceberg Table creation failed . Please execute the following command to manually repair :
$ kubectl get pod | grep postgresql
tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 7d18h
$ kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "UPDATE pg_database SET datallowconn = 'false' WHERE datname = 'metastore';SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'metastore'"; kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "drop database metastore"; kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "create database metastore"
$ kubectl get pod | grep client
tkbs-client-844559f5d7-r86rb 1/1 Running 7 7d18h
$ kubectl exec tkbs-client-844559f5d7-r86rb -- schematool -dbType postgres -initSchema
Integrate Iceberg
At present Iceberg Yes Spark 3.0 There is better support , contrast Spark 2.4 There are the following advantages : 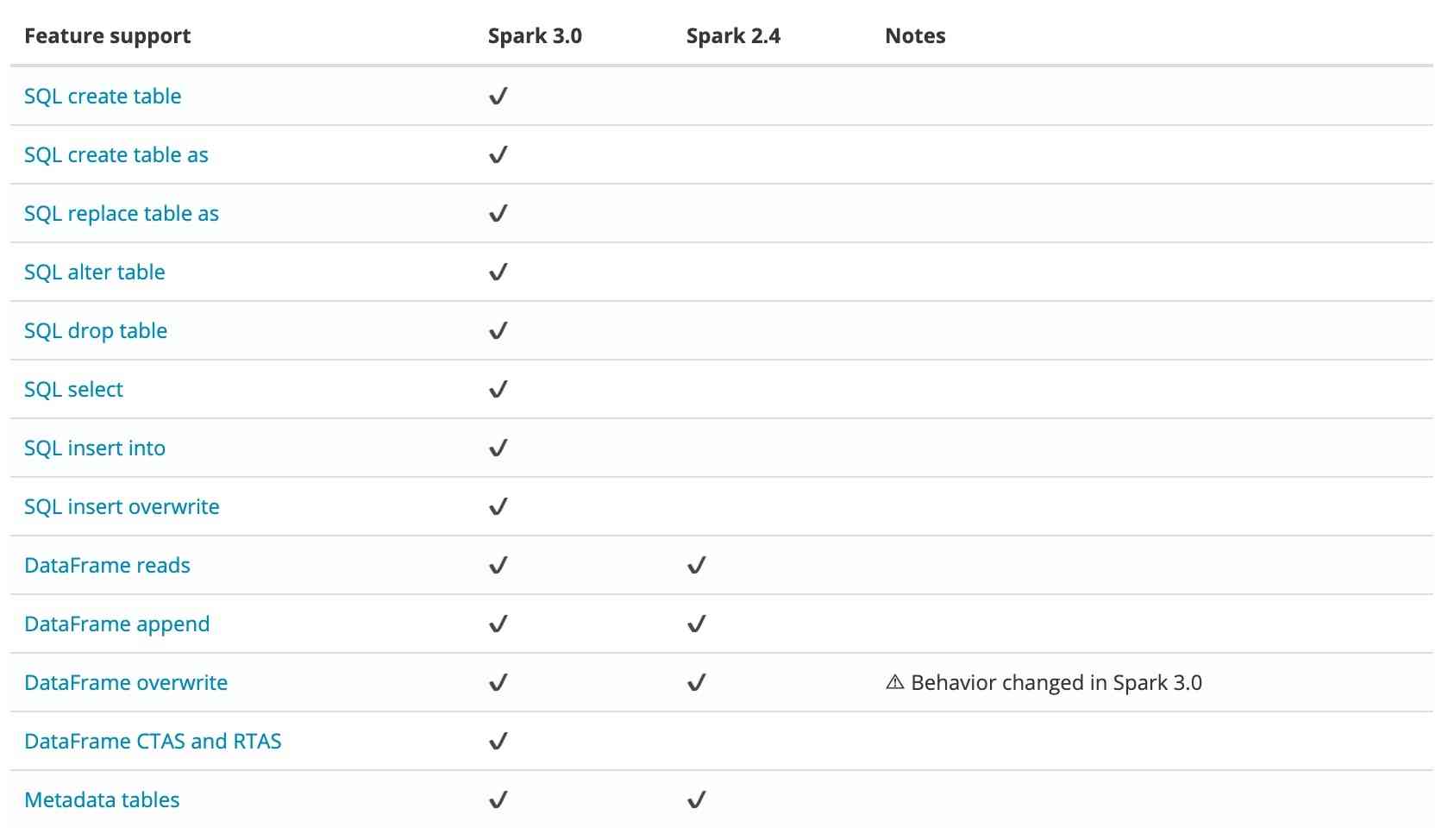 So we default to Spark 3.0 As a computing engine .Spark Integrate Iceberg, The first thing to do is to introduce Iceberg jar rely on . The user can manually specify , Or will jar Packages are introduced directly Spark The installation directory . For ease of use , We choose the latter . The author has packed Spark 3.0.1 Mirror image , For user testing :ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1.
So we default to Spark 3.0 As a computing engine .Spark Integrate Iceberg, The first thing to do is to introduce Iceberg jar rely on . The user can manually specify , Or will jar Packages are introduced directly Spark The installation directory . For ease of use , We choose the latter . The author has packed Spark 3.0.1 Mirror image , For user testing :ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1.
We use Hive MetaStore management Iceberg Table information , adopt Spark Catalog Access and use Iceberg surface . stay Spark Do the following configuration in :
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://metastore-host:port
If you use TKE k8s-big-data-suite Suite deployment Hadoop colony , It can be done by Hive Service visit Hive MetaStore:
$ kubectl get svc | grep hive-metastore
tkbs-hive-metastore ClusterIP 172.22.255.104 <none> 9083/TCP,8008/TCP 6d23h
Spark Change to configuration :
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://tkbs-hive-metastore
Create and use Iceberg surface
perform spark-sql To verify :
$ spark-sql --master k8s://{k8s-apiserver} --conf spark.kubernetes.container.image=ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1 --conf spark.sql.catalog.hive_prod=org.apache.iceberg.spaparkCatalog --conf spark.sql.catalog.hive_prod.type=hive --conf spark.sql.catalog.hive_prod.uri=thrift://tkbs-hive-metastore --conf spark.sql.warehouse.dir=hdfs://tkbs-hadoop-hdfs-nn/iceberg
The meaning of each parameter is as follows :
- --master k8s://{k8s-apiserver}:Kubernetes The cluster address
- --conf spark.kubernetes.container.image=ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1:Spark Iceberg Mirror image
- --conf spark.sql.catalog.hive_prod.type=hive:Spark Catalog type
- --conf spark.sql.catalog.hive_prod.uri=thrift://tkbs-hive-metastore:Hive MetaStore Address
- --conf spark.sql.warehouse.dir=hdfs://tkbs-hadoop-hdfs-nn/iceberg:Spark Data address
establish Iceberg surface :
spark-sql> CREATE TABLE hive_prod.db.table (id bigint, data string) USING iceberg;
See if it was created successfully :
spark-sql> desc hive_prod.db.table;
20/11/02 20:43:43 INFO BaseMetastoreTableOperations: Refreshing table metadata from new version: hdfs://10.0.1.129/iceberg/db.db/table/metadata/00000-1306e87a-16cb-4a6b-8ca0-0e1846cf1837.metadata.json
20/11/02 20:43:43 INFO CodeGenerator: Code generated in 21.35536 ms
20/11/02 20:43:43 INFO CodeGenerator: Code generated in 13.058698 ms
id bigint
data string
# Partitioning
Not partitioned
Time taken: 0.537 seconds, Fetched 5 row(s)
20/11/02 20:43:43 INFO SparkSQLCLIDriver: Time taken: 0.537 seconds, Fetched 5 row(s)
see HDFS Whether there is table information :
$ hdfs dfs -ls /iceberg/db.db
Found 5 items
drwxr-xr-x - root supergroup 0 2020-11-02 16:37 /iceberg/db.db/table
see Postgresql Whether there is table metadata information :
$ kubectl get pod | grep postgresql
tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 7d19h$ kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -d metastore -c 'select * from "TBLS"'
towards Iceberg Table insert data :
spark-sql> INSERT INTO hive_prod.db.table VALUES (1, 'a'), (2, 'b');
Check whether the insertion is successful :
spark-sql> select * from hive_prod.db.table;
...
1 a
2 b
Time taken: 0.854 seconds, Fetched 2 row(s)
20/11/02 20:49:43 INFO SparkSQLCLIDriver: Time taken: 0.854 seconds, Fetched 2 row(s)
see Kubernetes colony Spark Task running status :
$ kubectl get pod | grep spark
sparksql10-0-1-64-ed8e6f758900de0c-exec-1 1/1 Running 0 86s
sparksql10-0-1-64-ed8e6f758900de0c-exec-2 1/1 Running 0 85s
Iceberg Spark More operations supported can be seen :https://iceberg.apache.org/spark/
Go through the above steps , We can Kubernetes On the rapid deployment of production available real-time data Lake platform .
summary
In this era of data explosion , The traditional data warehouse has been difficult to meet the needs of data diversity . Data Lake relies on openness 、 Low cost and other advantages , Gradually taking the lead . And users and businesses are no longer satisfied with the lagging analysis results , More requirements for real-time data . With Iceberg、Hudi、Delta Lake For the representative open source data Lake Technology , Fill in this part of the market gap , It provides users with fast build, suitable for real-time OLAP Data Lake platform capability of . In addition, the arrival of cloud native Era , It has greatly accelerated the process . Big data is undoubtedly moving towards real-time analysis 、 Computational storage separation 、 Cloud native , As for the direction of the integration of lake and warehouse . Big data infrastructure is also because of Kubernetes、 The introduction of cloud native technologies such as containers , Great changes are taking place . Big data will be better in the future “ Grow on the clouds ”,Bigdata as a Service Era , I believe it will come soon .
Reference material
- https://iceberg.apache.org/
- https://github.com/apache/iceberg
- https://cloud.tencent.com/product/tke
- https://github.com/tkestack/charts/tree/main/incubator/k8s-big-data-suite
- be based on Apache Iceberg make T+0 Real time data warehouse
【 Tencent cloud native 】 Cloud said new products 、 Cloud research new technology 、 Travel new life 、 Cloud View information , Scan code is concerned about the official account number of the same name , Get more dry goods in time !!

版权声明
本文为[Tencent cloud native]所创,转载请带上原文链接,感谢
边栏推荐
- electron 實現檔案下載管理器
- Five vuex plug-ins for your next vuejs project
- Pattern matching: The gestalt approach一种序列的文本相似度方法
- Flink的DataSource三部曲之一:直接API
- The road of C + + Learning: from introduction to mastery
- What to do if you are squeezed by old programmers? I don't want to quit
- StickEngine-架构12-通信协议
- What are PLC Analog input and digital input
- Markdown tricks
- NLP model Bert: from introduction to mastery (1)
猜你喜欢
Jetcache buried some of the operation, you can't accept it

零基础打造一款属于自己的网页搜索引擎
【自学unity2d传奇游戏开发】如何让角色动起来
消息队列(MessageQueue)-分析
用一个例子理解JS函数的底层处理机制
游戏主题音乐对游戏的作用
DRF JWT authentication module and self customization
What are PLC Analog input and digital input
Outsourcing is really difficult. As an outsourcer, I can't help sighing.
理解格式化原理
随机推荐
What if the front end doesn't use spa? - Hacker News
Outsourcing is really difficult. As an outsourcer, I can't help sighing.
Analysis of serilog source code -- how to use it
Behind the first lane level navigation in the industry
一篇文章教会你使用Python网络爬虫下载酷狗音乐
With the advent of tensorflow 2.0, can pytoch still shake the status of big brother?
hdu3974 Assign the task線段樹 dfs序
Discussion on the development practice of aspnetcore, a cross platform framework
这个项目可以让你在几分钟快速了解某个编程语言
How to understand Python iterators and generators?
快速排序为什么这么快?
2020年第四届中国 BIM (数字建造)经理高峰论坛即将在杭举办
Markdown tricks
Flink的DataSource三部曲之一:直接API
DC-1靶機
How to hide part of barcode text in barcode generation software
前端未來趨勢之原生API:Web Components
Use modelarts quickly, zero base white can also play AI!
Using NLP and ml to extract and construct web data
Basic principle and application of iptables