当前位置:网站首页>Flink's datasource Trilogy 2: built in connector
Flink's datasource Trilogy 2: built in connector
2020-11-06 20:12:00 【Programmer Xinchen】
Welcome to visit mine GitHub
https://github.com/zq2599/blog_demos
Content : All original articles classified summary and supporting source code , involve Java、Docker、Kubernetes、DevOPS etc. ;
An overview of this article
This article is about 《Flink Of DataSource Trilogy 》 The second part of the series , Last one 《Flink Of DataSource One of the trilogy : direct API》 To study the StreamExecutionEnvironment Of API establish DataSource, What we are going to practice today is Flink Built in connector, That is, the position of the red box in the figure below , these connector Can pass StreamExecutionEnvironment Of addSource Methods use :
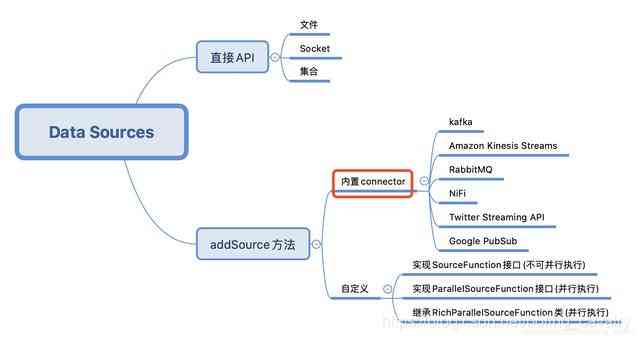 Today's practical choice Kafka Operate as a data source , First try to receive and process String The news of type , Then receive JSON Type of message , take JSON Antisequential formation bean example ;
Today's practical choice Kafka Operate as a data source , First try to receive and process String The news of type , Then receive JSON Type of message , take JSON Antisequential formation bean example ;
Flink Of DataSource Trilogy article links
- 《Flink Of DataSource One of the trilogy : direct API》
- 《Flink Of DataSource Trilogy two : built-in connector》
- 《Flink Of DataSource Trilogy three : Customize 》
Source download
If you don't want to write code , The source code of the whole series can be found in GitHub Download to , The address and link information is shown in the following table (https://github.com/zq2599/blog_demos):
| name | link | remarks |
|---|---|---|
| Project home page | https://github.com/zq2599/blog_demos | The project is in progress. GitHub Home page on |
| git Warehouse address (https) | https://github.com/zq2599/blog_demos.git | The warehouse address of the source code of the project ,https agreement |
| git Warehouse address (ssh) | [email protected]:zq2599/blog_demos.git | The warehouse address of the source code of the project ,ssh agreement |
This git Multiple folders in project , The application of this chapter in flinkdatasourcedemo Under the folder , As shown in the red box below : 
Environment and version
The actual combat environment and version are as follows :
- JDK:1.8.0_211
- Flink:1.9.2
- Maven:3.6.0
- operating system :macOS Catalina 10.15.3 (MacBook Pro 13-inch, 2018)
- IDEA:2018.3.5 (Ultimate Edition)
- Kafka:2.4.0
- Zookeeper:3.5.5
Please make sure that all of the above are ready , Only then can we continue the actual battle ;
Flink And Kafka Version match
- Flink Official match Kafka The version is explained in detail , The address is :https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/kafka.html
- What we should focus on is the general version mentioned by the official (universal Kafka connector ), This is from Flink1.7 Starting with , about Kafka1.0.0 Or later versions can use :
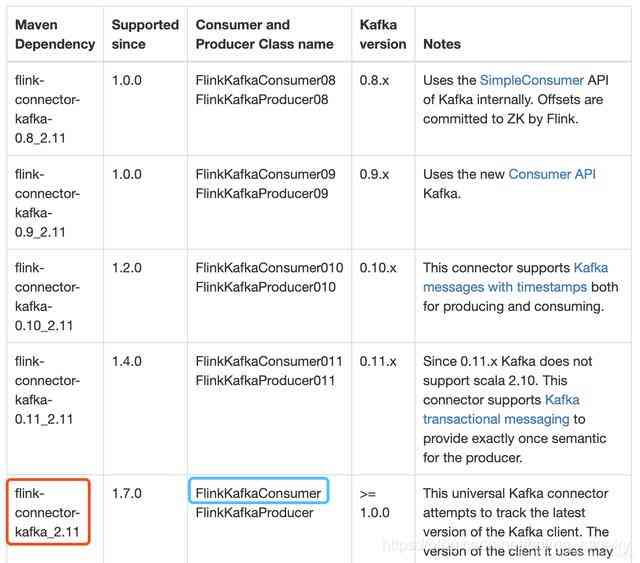
 3. In the red box below is the library my project depends on , In the blue frame is the connection Kafka Classes used , You can read according to your Kafka Version finds the appropriate libraries and classes in the table :
3. In the red box below is the library my project depends on , In the blue frame is the connection Kafka Classes used , You can read according to your Kafka Version finds the appropriate libraries and classes in the table :
Actual string message processing
- stay kafka Created on named test001 Of topic, Refer to the order :
./kafka-topics.sh \
--create \
--zookeeper 192.168.50.43:2181 \
--replication-factor 1 \
--partitions 2 \
--topic test001
- Continue to use the flinkdatasourcedemo engineering , open pom.xml File add the following dependencies :
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
- The new class Kafka240String.java, The function is to connect broker, Do... For the received string message WordCount operation :
package com.bolingcavalry.connector;
import com.bolingcavalry.Splitter;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
import static com.sun.tools.doclint.Entity.para;
public class Kafka240String {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Set parallelism
env.setParallelism(2);
Properties properties = new Properties();
//broker Address
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
//zookeeper Address
properties.setProperty("zookeeper.connect", "192.168.50.43:2181");
// Consumers' groupId
properties.setProperty("group.id", "flink-connector");
// Instantiation Consumer class
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
"test001",
new SimpleStringSchema(),
properties
);
// Specify to start consumption from the latest location , It's like giving up historical news
flinkKafkaConsumer.setStartFromLatest();
// adopt addSource Method to get DataSource
DataStream<String> dataStream = env.addSource(flinkKafkaConsumer);
// from kafka After getting the string message , Split into words , Statistical quantity , The window is 5 second
dataStream
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.print();
env.execute("Connector DataSource demo : kafka");
}
}
- Make sure kafka Of topic Created , take Kafka240 Run up , It can be seen that the function of consuming messages and word statistics is normal :
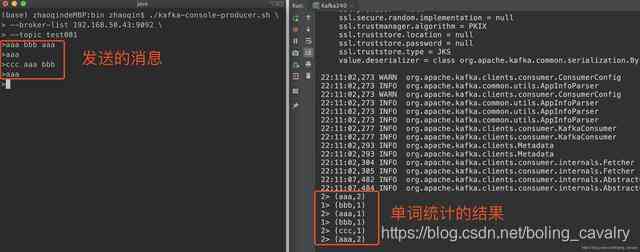 5. receive kafka The actual combat of string message has been completed , Next try JSON Formatted message ;
5. receive kafka The actual combat of string message has been completed , Next try JSON Formatted message ;
actual combat JSON Message processing
- The next thing to accept JSON Format message , Can be reversed into bean example , use JSON library , I chose gson;
- stay pom.xml increase gson rely on :
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
- Add class Student.java, This is an ordinary Bean, Only id and name Two fields :
package com.bolingcavalry;
public class Student {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
- Add class StudentSchema.java, This category is DeserializationSchema Interface implementation , take JSON Antisequential formation Student The example uses :
ackage com.bolingcavalry.connector;
import com.bolingcavalry.Student;
import com.google.gson.Gson;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import java.io.IOException;
public class StudentSchema implements DeserializationSchema<Student>, SerializationSchema<Student> {
private static final Gson gson = new Gson();
/**
* Deserialization , take byte The array is converted to Student example
* @param bytes
* @return
* @throws IOException
*/
@Override
public Student deserialize(byte[] bytes) throws IOException {
return gson.fromJson(new String(bytes), Student.class);
}
@Override
public boolean isEndOfStream(Student student) {
return false;
}
/**
* serialize , take Student The example turns into byte Array
* @param student
* @return
*/
@Override
public byte[] serialize(Student student) {
return new byte[0];
}
@Override
public TypeInformation<Student> getProducedType() {
return TypeInformation.of(Student.class);
}
}
- The new class Kafka240Bean.java, The function is to connect broker, Yes, I received JSON The news turned into Student example , Count the number of each name , The window is still 5 second :
package com.bolingcavalry.connector;
import com.bolingcavalry.Splitter;
import com.bolingcavalry.Student;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class Kafka240Bean {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Set parallelism
env.setParallelism(2);
Properties properties = new Properties();
//broker Address
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
//zookeeper Address
properties.setProperty("zookeeper.connect", "192.168.50.43:2181");
// Consumers' groupId
properties.setProperty("group.id", "flink-connector");
// Instantiation Consumer class
FlinkKafkaConsumer<Student> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
"test001",
new StudentSchema(),
properties
);
// Specify to start consumption from the latest location , It's like giving up historical news
flinkKafkaConsumer.setStartFromLatest();
// adopt addSource Method to get DataSource
DataStream<Student> dataStream = env.addSource(flinkKafkaConsumer);
// from kafka Obtained JSON To be reversed into Student example , Count each one name The number of , The window is 5 second
dataStream.map(new MapFunction<Student, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(Student student) throws Exception {
return new Tuple2<>(student.getName(), 1);
}
})
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.print();
env.execute("Connector DataSource demo : kafka bean");
}
}
- During the test , Want to kafka send out JSON Format string ,flink This way, we'll count out every name The number of :
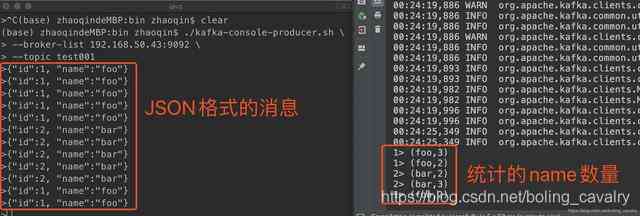 thus , built-in connector The actual battle of is finished , The next chapter , We are going to work together to customize DataSource;
thus , built-in connector The actual battle of is finished , The next chapter , We are going to work together to customize DataSource;
Welcome to the official account : Xinchen, programmer
WeChat search 「 Xinchen, programmer 」, I'm Xinchen , Looking forward to traveling with you Java The world ... https://github.com/zq2599/blog_demos
版权声明
本文为[Programmer Xinchen]所创,转载请带上原文链接,感谢
边栏推荐
- JNI-Thread中start方法的呼叫與run方法的回撥分析
- Cglib 如何实现多重代理?
- Brief introduction of TF flags
- Jetcache buried some of the operation, you can't accept it
- MeterSphere开发者手册
- Introduction to Google software testing
- What are Devops
- WeihanLi.Npoi 1.11.0/1.12.0 Release Notes
- StickEngine-架构12-通信协议
- Advanced Vue component pattern (3)
猜你喜欢

Elasticsearch数据库 | Elasticsearch-7.5.0应用搭建实战
如何在终端启动Coda 2中隐藏的首选项?
【转发】查看lua中userdata的方法

Individual annual work summary and 2019 work plan (Internet)
JVM内存分配 -Xms128m -Xmx512m -XX:PermSize=128m -XX:MaxPermSize=512m
Three Python tips for reading, creating and running multiple files
零基础打造一款属于自己的网页搜索引擎
StickEngine-架构11-消息队列(MessageQueue)
FastThreadLocal 是什么鬼?吊打 ThreadLocal 的存在!!
Live broadcast preview | micro service architecture Learning Series live broadcast phase 3
随机推荐
How to turn data into assets? Attracting data scientists
DC-1靶機
Introduction to the structure of PDF417 bar code system
游戏开发中的新手引导与事件管理系统
C#和C/C++混合编程系列5-内存管理之GC协同
一篇文章教会你使用Python网络爬虫下载酷狗音乐
Interface pressure test: installation, use and instruction of siege pressure test
use Asponse.Words Working with word templates
Vite + TS quickly build vue3 project and introduce related features
[C / C + + 1] clion configuration and running C language
Gather in Beijing! The countdown to openi 2020
01. SSH Remote terminal and websocket of go language
開源一套極簡的前後端分離專案腳手架
How to get started with new HTML5 (2)
If PPT is drawn like this, can the defense of work report be passed?
The data of pandas was scrambled and the training machine and testing machine set were selected
Electron application uses electronic builder and electronic updater to realize automatic update
Building and visualizing decision tree with Python
一篇文章带你了解CSS3 背景知识
Introduction to Google software testing