当前位置:网站首页>Reasons and solutions of redis cache penetration and avalanche
Reasons and solutions of redis cache penetration and avalanche
2022-07-05 00:28:00 【ZZYSY~】
High availability of services
Redis The use of caching , Greatly improve the performance and efficiency of the application , Especially in data query . But at the same time , It also brings some problems . among , The most important question , It's data consistency , Strictly speaking , There is no solution to this problem . If there is a high requirement for data consistency , Then you can't use caching .
Other typical problems are , Cache penetration 、 Cache avalanche and cache breakdown . at present , There are also popular solutions in the industry .
Cache penetration ( We can't find it )
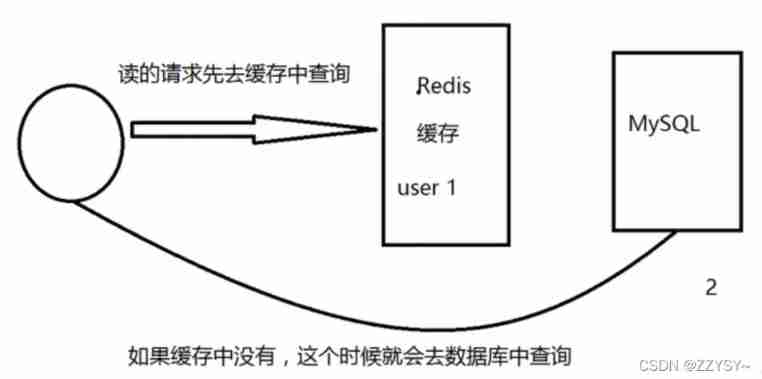
Concept
The concept of cache penetration is simple , The user wants to query a data , Find out redis Memory databases don't have , That is, cache miss , So query the persistence layer database . There is no , So this query failed . When there are a lot of users , No cache hits , So they all went to the persistence layer database , This will put a lot of pressure on the persistence layer database , This is equivalent to cache penetration .
Solution
- The bloon filter
A bloom filter is a data structure , For all possible query parameters, use hash stored , Check at the control level first , If not, discard , Thus, the query pressure on the underlying storage system is avoided 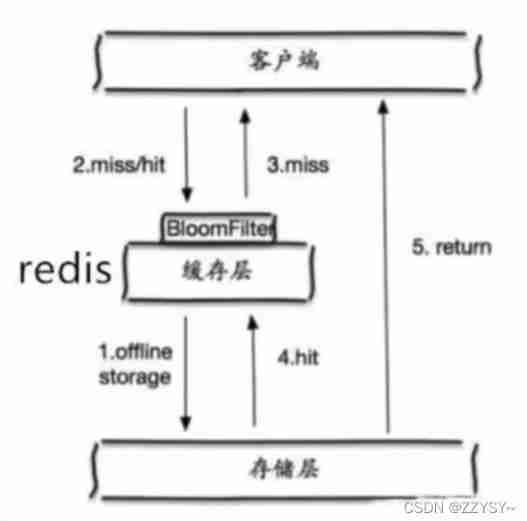
- Caching empty objects
When the storage tier misses , Even empty objects returned are cached , At the same time, an expiration time will be set , Then accessing this data will get from the cache , Protected back-end data sources 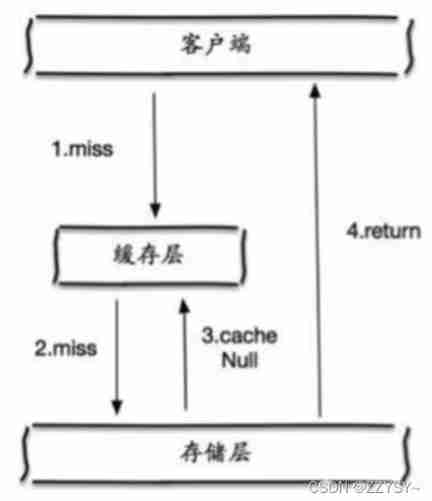
But there are two problems with this approach :
- If null values can be cached , This means that the cache needs more space to store more keys , Because there may be a lot of empty keys ;
- Even if expiration time is set for null value , There will be some inconsistency between the data of cache layer and storage layer for a period of time , This has an impact on businesses that need to be consistent .
Cache breakdown ( Too much , Cache expiration )
summary
We need to pay attention to the difference between this and cache breakdown , Cache breakdown , It means a key Very hot , Constantly carrying big concurrency , Large concurrent centralized access to this point , When this key At the moment of failure , Continuous large concurrency breaks through the cache , Direct request database , It's like cutting a hole in a barrier
When a key At the moment of expiration , There are a lot of requests for concurrent access , This kind of data is generally hot data , Due to cache expiration , Will access the database at the same time to query the latest data , And write back to the cache , Will cause the database transient pressure is too large .
Solution
- Never expired data settings
At the cache level , Expiration time is not set , So there will be no hot spots key Problems after expiration .
- Add mutex lock
Distributed lock ∶ Using distributed locks , Guarantee for each key At the same time, there is only one thread to query the back-end service , Other threads do not have access to distributed locks , So just wait . In this way, the pressure of high concurrency is transferred to distributed locks , So the test of distributed locks is great .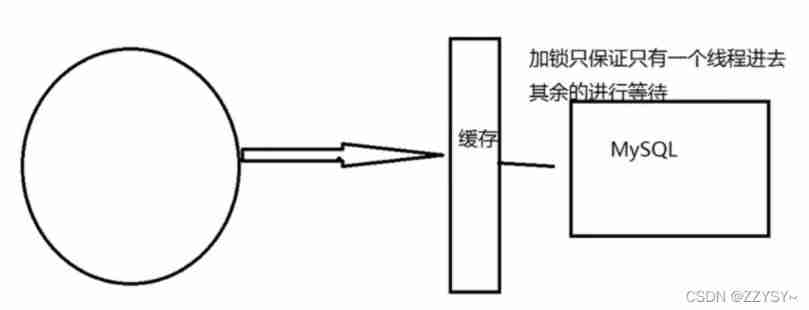
Cache avalanche
Concept
Cache avalanche , At a certain time , Expiration in cache set .Redis Downtime
One of the reasons for the avalanche , For example, when writing this article , It's about double twelve o'clock , There will soon be a rush , This wave of commodity time is put into the cache , Suppose you cache for an hour . Then at one o'clock in the morning , The cache of this batch of goods has expired . And the access to this batch of products , It's all in the database , For databases , There will be periodic pressure peaks . So all the requests will reach the storage layer , The number of calls to the storage layer will skyrocket , Cause the storage layer to hang up 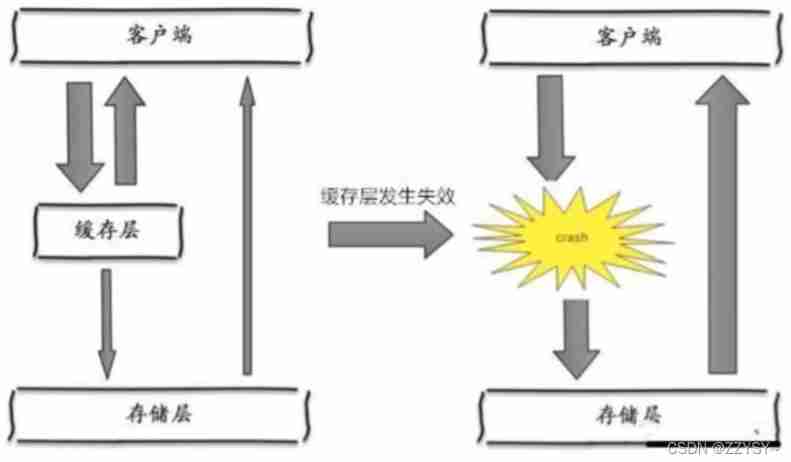
Actually, the concentration is overdue , It's not very deadly , More deadly cache avalanche , It means that a node of the cache server is down or disconnected . Because of the cache avalanche formed naturally , Cache must be created in a certain time period , This is the time , The database can also withstand the pressure . It's just periodic pressure on the database . The cache service node is down , The pressure on the database server is unpredictable , It's likely to crush the database in an instant .
( A double tenth : Shut down some services , Ensure availability of major services )
Solution
- redis High availability
The meaning of this idea is , since redis It's possible to hang up , I'll add more redis, After this one goes down, others can continue to work , In fact, it's a cluster built .( Different live )
- Current limiting the drop
The idea of this solution is , After cache failure , Control the number of threads that read the database write cache by locking or queuing . For example, to some key Only one thread is allowed to query data and write cache , Other threads wait .
- Data preheating
Data heating means before deployment , I'll go through the possible data first , In this way, some of the data that may be accessed in large amounts will be loaded into the cache . Manually trigger loading cache before large concurrent access occurs key, Set different expiration times , Make the cache failure time as uniform as possible .
边栏推荐
- Kibana index, mapping, document operation
- 2022.07.03(LC_6109_知道秘密的人数)
- It's too convenient. You can complete the code release and approval by nailing it!
- 22-07-02周总结
- 人脸识别5- insight-face-paddle-代码实战笔记
- Go step on the pit - no required module provides package: go mod file not found in current directory or any parent
- Complete knapsack problem (template)
- How to effectively monitor the DC column head cabinet
- npm install报错 强制安装
- 2022.07.03 (LC 6109 number of people who know secrets)
猜你喜欢
Recursive execution mechanism
分布式BASE理论

【雅思阅读】王希伟阅读P4(matching2段落信息配对题【困难】)
Detailed explanation of openharmony resource management

1189. Maximum number of "balloons"

海思3559万能平台搭建:YUV422的踩坑记录
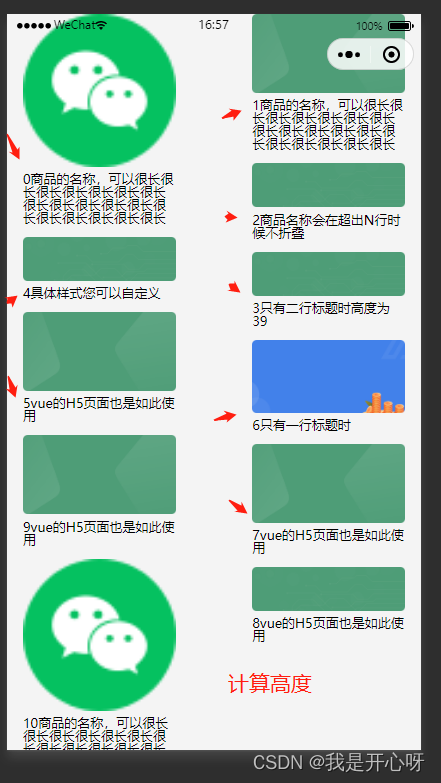
The waterfall flow layout demo2 (method 2) used by the uniapp wechat applet (copy and paste can be used without other processing)
![P3304 [SDOI2013]直径(树的直径)](/img/5c/984675bf4517481f80f54657c6c7ad.png)
P3304 [SDOI2013]直径(树的直径)
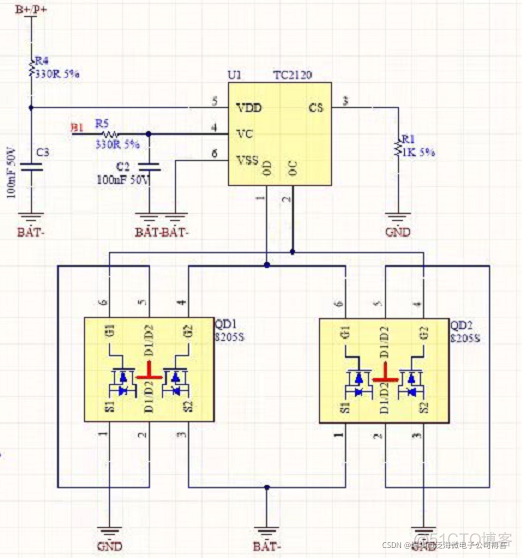
Specification for fs4061a boost 8.4v charging IC chip and fs4061b boost 12.6V charging IC chip datasheet
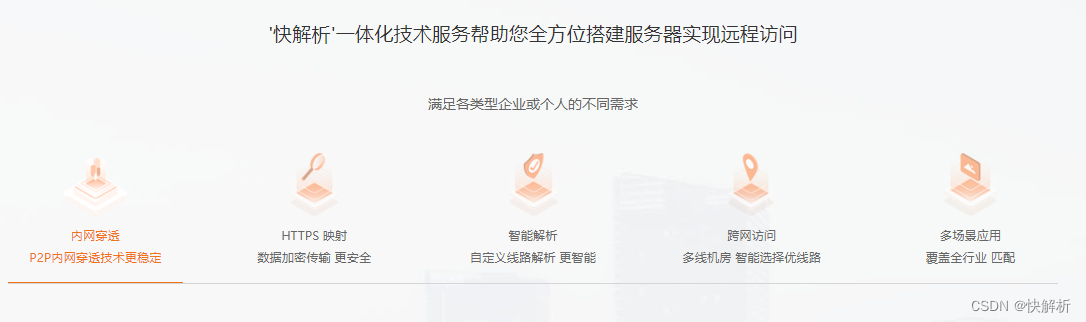
Fast parsing intranet penetration helps enterprises quickly achieve collaborative office
随机推荐
业务场景功能的继续修改
Go step on the pit - no required module provides package: go mod file not found in current directory or any parent
Consolidated expression C case simple variable operation
企业公司项目开发好一部分基础功能,重要的事保存到线上第一a
2022.07.03 (lc_6111_counts the number of ways to place houses)
How to do the project of computer remote company in foreign Internet?
Data on the number of functional divisions of national wetland parks in Qinghai Province, data on the distribution of wetlands and marshes across the country, and natural reserves in provinces, cities
Paper notes multi UAV collaborative monolithic slam
Netcore3.1 JSON web token Middleware
Two numbers replace each other
lambda expressions
The waterfall flow layout demo2 (method 2) used by the uniapp wechat applet (copy and paste can be used without other processing)
uniapp微信小程序拿来即用的瀑布流布局demo2(方法二)(复制粘贴即可使用,无需做其他处理)
[论文阅读] CarveMix: A Simple Data Augmentation Method for Brain Lesion Segmentation
AcWing164. 可达性统计(拓扑排序+bitset)
Fast analysis -- easy to use intranet security software
Specification for fs4061a boost 8.4v charging IC chip and fs4061b boost 12.6V charging IC chip datasheet
Upload avatar on uniapp
Summary of week 22-07-02
js如何实现数组转树