当前位置:网站首页>[NLP] text classification still stays at Bert? Duality is too strong than learning framework
[NLP] text classification still stays at Bert? Duality is too strong than learning framework
2022-07-03 23:59:00 【Demeanor 78】
Brief introduction of the paper : Dual contrast learning : How to apply contrastive learning to supervised text classification
Paper title :Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation
Thesis link :https://arxiv.org/pdf/1905.09788.pdf
Code link :https://github.com/hiyouga/dual-contrastive-learning
Author of the paper :{Qianben Chen}
1
Abstract of paper
Contrastive learning has achieved remarkable success in representational learning through self-supervision in an unsupervised environment . However , Effectively adapting contrastive learning to supervised learning tasks is still a challenge in practice . In this work , The author proposes a dual contrastive learning (DualCL) frame , Simultaneously learn the features of input samples and the parameters of classifier in the same space . say concretely ,DualCL The parameters of the classifier are treated as enhanced samples associated with different tags , Then it is used for comparative learning between input samples and enhancement samples . Yes 5 The experimental study of a benchmark text classification dataset and its corresponding low resource version dataset shows that ,DualCL The classification accuracy has been significantly improved , And confirmed that DualCL It can realize the effect of sample discriminant representation .
2
DualCL brief introduction
Representation learning is the core of deep learning . In the context of unsupervised learning , Contrastive learning has recently been proved to be an effective method to obtain the general representation of downstream tasks . In short , Unsupervised contrastive learning uses a loss function , It forces differences in the same sample “ visual angle ” The representation vectors of are similar , The representation vectors of different samples are different . Recently, the effectiveness of comparative learning has been proved to be due to the simultaneous realization of “ Alignment ”【alignment】 and “ Uniformity ”【uniformity】.
The contrastive learning method is also suitable for supervised representation learning , Similar comparative losses have been used in previous studies , The basic principle is to insist that the representation of samples in the same class is similar , The sample representations of different classes are similar . Clear . However , Despite the success , But compared with unsupervised comparative learning , The principle of this method seems to be much worse . for example , The unity of representation is no longer valid ; It's not necessary either , Generally speaking, the spatial distribution of features is no longer uniform , Therefore, we believe that the standard supervised contrastive learning method is not natural for supervised representation learning . Another fact is that , That is, the result of this comparative learning method does not directly give us a classifier , Another classification algorithm needs to be developed to solve the classification task .
Let's talk about DualCL Proposed motivation , The author aims to develop a more natural method to realize comparative learning under supervised tasks . The author's key motivation is that supervised representation learning should include learning two parameters : One is to input the appropriate spatial features , Used to meet the needs of classification tasks , The other is the parameters of the classifier , Or the parameters acting on the classifier space ; We call this classifier “one example” classifier . In this view , Naturally associate the sample with two parameters : A dimension of , Used to represent a feature ; One is the classifier parameter , Which represents the total number of classifications in the sample . Then supervised representation learning can be considered as generating for input samples .
In order to ensure that the classifier is effective for features , Just make sure that it is aligned with the label of the sample , Can pass softmax The normalized probability is constrained by cross entropy . besides , In contrast, learning methods can be used to enforce these ,θ Means to constrain , In particular , We will record that the real label of the sample corresponds to the ideal parameter of the classifier , Here we can design two kinds of contrast loss . first loss Used to compare with multiple , Which represents the sample characteristics of different categories from the sample ; the second loss Used to compare with multiple , Among them, different categories representing samples correspond to classifier parameters , The author calls this learning framework dual contrastive learning(DualCL), Dual contrast learning .
On the basis of comparative learning , As the title of the paper ,DualCL It can be considered as a unique data enhancement method . say concretely , For each sample , Its θ Each column of can be regarded as “ Tag inspired input represents ”, Or an enhanced view with label information injected into the feature space . surface 1 The power of this approach is illustrated in , As can be seen from the two pictures on the left , Standard contrastive learning cannot use label information . contrary , From the two figures on the right ,DualCL Effectively use the label information to classify the input samples in its class .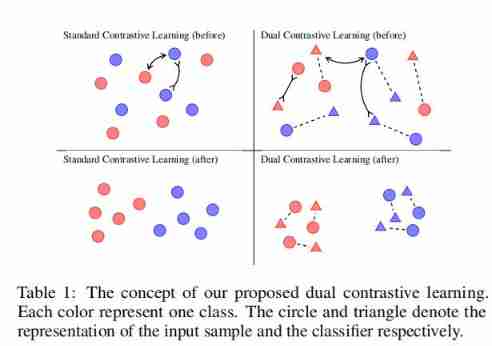
In the paper experiment , The author in 5 It is verified on a benchmark text classification data set DualCL The effectiveness of the . By using the dual ratio loss to the pre trained language model (BERT and RoBERTa) Fine tuning ,DualCL The best performance is obtained compared with the existing baseline of comparative learning supervision . The author also found that ,DualCL The classification accuracy is improved , Especially in low resource scenarios . In addition, by visualizing the learned representation and attention map , Yes DualCL Some interpretability analyses are given .
The contributions of this paper can be summarized as follows :
1) Double contrast learning is proposed (DualCL), Naturally combine comparative losses with supervised tasks ;
2) Tag aware data enhancement is introduced to obtain multiple views of input samples , be used for DualCL Training for ;
3) stay 5 It is empirically verified on a benchmark text classification data set DualCL The effectiveness of the framework ;
3
DualCL principle
 “ dual ” The purpose of supervised contrastive learning is : The first is to discriminate the input of the classification task in an appropriate space , The second is to build a classifier for supervisory tasks , Learn the parameters of the classifier in the classifier space . Now let's see DualCL The core of .
“ dual ” The purpose of supervised contrastive learning is : The first is to discriminate the input of the classification task in an appropriate space , The second is to build a classifier for supervisory tasks , Learn the parameters of the classifier in the classifier space . Now let's see DualCL The core of .
Data enhancement of tag heuristics
In order to obtain different views of training samples (views) Express , The author uses the idea of data enhancement to obtain the representation of features and classifiers . Specifically, it takes the corresponding parameters of each category of the classifier as the unique representation of the classifier , Write it down as , Called tag aware input representation , Inject tag information into the , As an additional enhanced view .
In practice , Insert the label set into the input sequence , A new input sequence can be obtained , And then through PLMS(Bert perhaps Roberta) Model as encoder , To get each of the input sequences token features , among [CLS] Characteristics as the characteristics of the sample , The inserted tag corresponds to the tag inspired input representation . The name of the tag is used as a marker , Form a sequence , Such as “positive”、“negative” etc. . For tags that contain multiple words , We use token Average pooling of features to obtain a tag aware input representation . This operation is very similar to the previous paper , If you are interested, you can read :Bert It can also be used in this way : Fuse the label vector to BERT
Dual contrast loss
Using the feature representation and classifier of input samples θ,DualCL What it does is it takes θ Of softmax The normalized probability is aligned with the label of . take θ Express θ A column of , Corresponding to the real label index ,DualCL expect θ The dot product is maximized . In order to learn better and θ,DualCL The dual contrast loss is defined by using the relationship between different training samples , If you have the same label as , Then try to maximize θ, And if there is a different label from , Minimize θ.
Given an anchor from the input sample , It's a positive sample set , It's a negative sample set , About z The comparative loss can be defined as follows :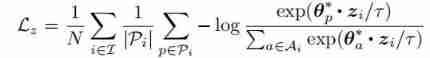
Empathy , Given an anchor from the input sample , It's a positive sample set , It's a negative sample set , About z The comparative loss can be defined as follows :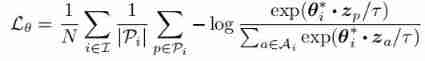
The dual ratio loss is the combination of the above two comparative loss terms :
Compare training with supervised prediction
In order to make full use of the supervision signal ,DualCL Also expected θ It's a good classifier . Therefore, the author uses an improved version of cross entropy loss to maximize the entropy loss of each input sample θ: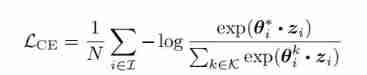
Last , Minimize these two training objectives to train the encoder . These two goals improve both the representation quality of features and the representation quality of classifiers . The total loss should be :
among ,λ It is a super parameter that controls the weight of double contrast loss term .
In the process of classification , We use the trained encoder to generate the feature representation and classifier of the input sentence θ. there θ Can be seen as a “one-example” Classifier , for example , We will θ Of argmax The results are predicted as a model :
chart 1 The framework of dual contrast learning is explained , Where is the feature representation , And are classifiers representing . In this particular case , We assume to have “positive” Class as an anchor , And there is a positive sample with the same class label , There is a negative sample with different class labels . The dual contrast loss aims to attract the feature representation to the classifier representation between positive samples at the same time , The feature representation is excluded to the classifier between negative samples .
Duality between representations
The comparison loss adopts the point product function as the measure of similarity between , This makes DualCL Feature representation and classifier representation in θ There is a dual relationship between . In linear classifier , A similar phenomenon occurs in the relationship between input features and parameters . Then we can put θ As a parameter of a linear classifier , In this way, the pre trained encoder can generate a linear classifier for each input sample . therefore ,DualCL Naturally learn how to generate a linear classifier for each input sample to perform the classification task .
4
Experimental setup
Data sets
The paper adopts SST-2、SUBJ、TREC、PC and CR Four data sets , The relevant statistics of the data set are as follows :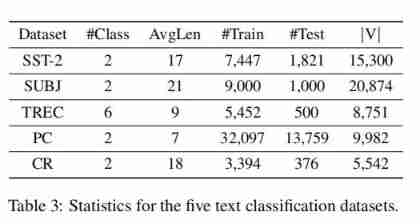
experimental result
As can be seen from the results , Besides using RoBERTa Of TREC Outside the data set , Use at the same time BERT and RoBERTa The encoder achieves the best classification performance in almost all settings . With complete training data CE+CL comparison ,DualCL Yes BERT and RoBERTa The average improvement rates are 0.46% and 0.39%. Besides , We observed that , stay 10% Training data ,DualCL The performance of is significantly greater than CE+CL Method , stay BERT and RoBERTa Above each other 0.74% and 0.51%. meanwhile ,CE and CE+SCL The performance cannot exceed DualCL. This is because CE The method ignores the relationship between samples ,CE+SCL Method can not directly learn the classifier of classification task .
 In addition, the paper finds that the double contrast loss term helps the model achieve better performance on all five data sets . It shows that using the relationship between samples is helpful for the model to learn better representation in comparative learning .
In addition, the paper finds that the double contrast loss term helps the model achieve better performance on all five data sets . It shows that using the relationship between samples is helpful for the model to learn better representation in comparative learning .

case analysis
In order to verify DualCL Is it possible to capture information characteristics , The author also calculated [CLS] The marked features and the attention score between each word in the sentence . First, fine tune the whole training set RoBERTa Encoder . Then we calculate the distance between features , And visualize 4 Notice the figure in . It turns out that , When classifying emotions , The captured features are different . The above example comes from SST-2 Data sets , We can see that our model focuses more on expression “ positive ” Emotional sentences “predictably heart warming”. The following example comes from CR Data sets , We can see that our model expresses “ negative ” Emotional sentences pay more attention to “small”. contrary ,CE The method does not focus on these distinguishing features . It turns out that DualCL Be able to successfully deal with informative keywords in sentences .

5
A summary of the paper
In this study , From the perspective of text classification task , A dual contrast learning method is proposed DualCL, To solve the task of supervised learning .
stay DualCL in , Author use PLMs Learn both expressions at the same time . One is the identification feature of the input example , The other is the classifier of this example . We introduce tag aware data enhancement to generate different views of input samples , It contains features and classifiers . Then a dual contrast loss is designed , Make the classifier valid for the input features .
Dual contrast loss uses the supervision signals between training samples to learn better representation , The effectiveness of dual contrast learning is verified by a large number of experiments .
6
Core code
About Dual-Contrastive-Learning Realization , You can check the open source code :
https://github.com/hiyouga/Dual-Contrastive-Learning/blob/main/main_polarity.py
def _contrast_loss(self, cls_feature, label_feature, labels):
normed_cls_feature = F.normalize(cls_feature, dim=-1)
normed_label_feature = F.normalize(label_feature, dim=-1)
list_con_loss = []
BS, LABEL_CLASS, HS = normed_label_feature.shape
normed_positive_label_feature = torch.gather(normed_label_feature, dim=1,
index=labels.reshape(-1, 1, 1).expand(-1, 1, HS)).squeeze(1) # (bs, 768)
if "1" in self.opt.contrast_mode:
loss1 = self._calculate_contrast_loss(normed_positive_label_feature, normed_cls_feature, labels)
list_con_loss.append(loss1)
if "2" in self.opt.contrast_mode:
loss2 = self._calculate_contrast_loss(normed_cls_feature, normed_positive_label_feature, labels)
list_con_loss.append(loss2)
if "3" in self.opt.contrast_mode:
loss3 = self._calculate_contrast_loss(normed_positive_label_feature, normed_positive_label_feature, labels)
list_con_loss.append(loss3)
if "4" in self.opt.contrast_mode:
loss4 = self._calculate_contrast_loss(normed_cls_feature, normed_cls_feature, labels)
list_con_loss.append(loss4)
return list_con_loss
def _calculate_contrast_loss(self, anchor, target, labels, mu=1.0):
BS = len(labels)
with torch.no_grad():
labels = labels.reshape(-1, 1)
mask = torch.eq(labels, labels.T) # (bs, bs)
# compute temperature using mask
temperature_matrix = torch.where(mask == True, mu * torch.ones_like(mask),
1 / self.opt.temperature * torch.ones_like(mask)).to(self.opt.device)
# # mask-out self-contrast cases, That is, you don't take yourself into account
# logits_mask = torch.scatter(
# torch.ones_like(mask),
# 1,
# torch.arange(BS).view(-1, 1).to(self.opt.device),
# 0
# )
# mask = mask * logits_mask
# compute logits
anchor_dot_target = torch.multiply(torch.matmul(anchor, target.T), temperature_matrix) # (bs, bs)
# for numerical stability
logits_max, _ = torch.max(anchor_dot_target, dim=1, keepdim=True)
logits = anchor_dot_target - logits_max.detach() # (bs, bs)
# compute log_prob
exp_logits = torch.exp(logits) # (bs, bs)
exp_logits = exp_logits - torch.diag_embed(torch.diag(exp_logits)) # Subtract diagonal elements , You can't
log_prob = logits - torch.log(exp_logits.sum(dim=1, keepdim=True) + 1e-12) # (bs, bs)
# in case that mask.sum(1) has no zero
mask_sum = mask.sum(dim=1)
mask_sum = torch.where(mask_sum == 0, torch.ones_like(mask_sum), mask_sum)
# compute mean of log-likelihood over positive
mean_log_prob_pos = (mask * log_prob).sum(dim=1) / mask_sum.detach()
loss = - mean_log_prob_pos.mean()
return loss7
Reference material
ICML 2020: from Alignment and Uniformity Understanding contrastive representation learning from the perspective of https://blog.csdn.net/c2a2o2/article/details/117898108
Past highlights
It is suitable for beginners to download the route and materials of artificial intelligence ( Image & Text + video ) Introduction to machine learning series download Chinese University Courses 《 machine learning 》( Huang haiguang keynote speaker ) Print materials such as machine learning and in-depth learning notes 《 Statistical learning method 》 Code reproduction album
AI Basic download machine learning communication qq Group 955171419, Please scan the code to join wechat group :
边栏推荐
- Briefly understand the operation mode of developing NFT platform
- Suggestions for improving code quality
- Is user authentication really simple
- 2022 chemical automation control instrument examination content and chemical automation control instrument simulation examination
- What are the securities companies with the lowest Commission for stock account opening? Would you recommend it? Is it safe to open an account on your mobile phone
- [PHP basics] cookie basics, application case code and attack and defense
- FPGA tutorial and Allegro tutorial - link
- Zipper table in data warehouse (compressed storage)
- Idea a method for starting multiple instances of a service
- 股票开户佣金最低的券商有哪些大家推荐一下,手机上开户安全吗
猜你喜欢
![[Happy Valentine's day]](/img/d9/9280398eb64907a567df6eea772adb.jpg)
[Happy Valentine's day] "I still like you very much, like sin ² a+cos ² A consistent "(white code in the attached table)

Schematic diagram of crystal oscillator clock and PCB Design Guide

"Learning notes" recursive & recursive

Smart fan system based on stm32f407

Analysis on the scale of China's smart health industry and prediction report on the investment trend of the 14th five year plan 2022-2028 Edition
![[MySQL] classification of multi table queries](/img/96/2e51ae8d52ea8184945e0540ce18f5.jpg)
[MySQL] classification of multi table queries

Entropy and full connection layer

Analysis of refrigeration and air conditioning equipment operation in 2022 and examination question bank of refrigeration and air conditioning equipment operation
Alibaba cloud container service differentiation SLO hybrid technology practice
Yyds dry goods inventory three JS source code interpretation - getobjectbyproperty method
随机推荐
Fudan 961 review
The first game of the new year, many bug awards submitted
Is the low commission link on the internet safe? How to open an account for China Merchants Securities?
[MySQL] sql99 syntax to realize multi table query
Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
Similarities and differences of text similarity between Jaccard and cosine
Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
2022 system integration project management engineer examination knowledge points: software development model
Selenium check box
Loop compensation - explanation and calculation of first-order, second-order and op amp compensation
Selenium library 4.5.0 keyword explanation (I)
Gossip about redis source code 78
Yyds dry goods inventory three JS source code interpretation - getobjectbyproperty method
What is the Valentine's Day gift given by the operator to the product?
I wrote a chat software with timeout connect function
After the Lunar New Year and a half
P1339 [USACO09OCT]Heat Wave G
Social network analysis -social network analysis
[PHP basics] cookie basics, application case code and attack and defense
ESP Arduino playing with peripherals (V) basic concept of interrupt and timer interrupt