当前位置:网站首页>Hou Jie -- STL source code analysis notes
Hou Jie -- STL source code analysis notes
2022-07-03 10:38:00 【Twilight drainage software】
Hou Jie ——STL Source analysis note
1. The overview
1.STL The relationship between the six components
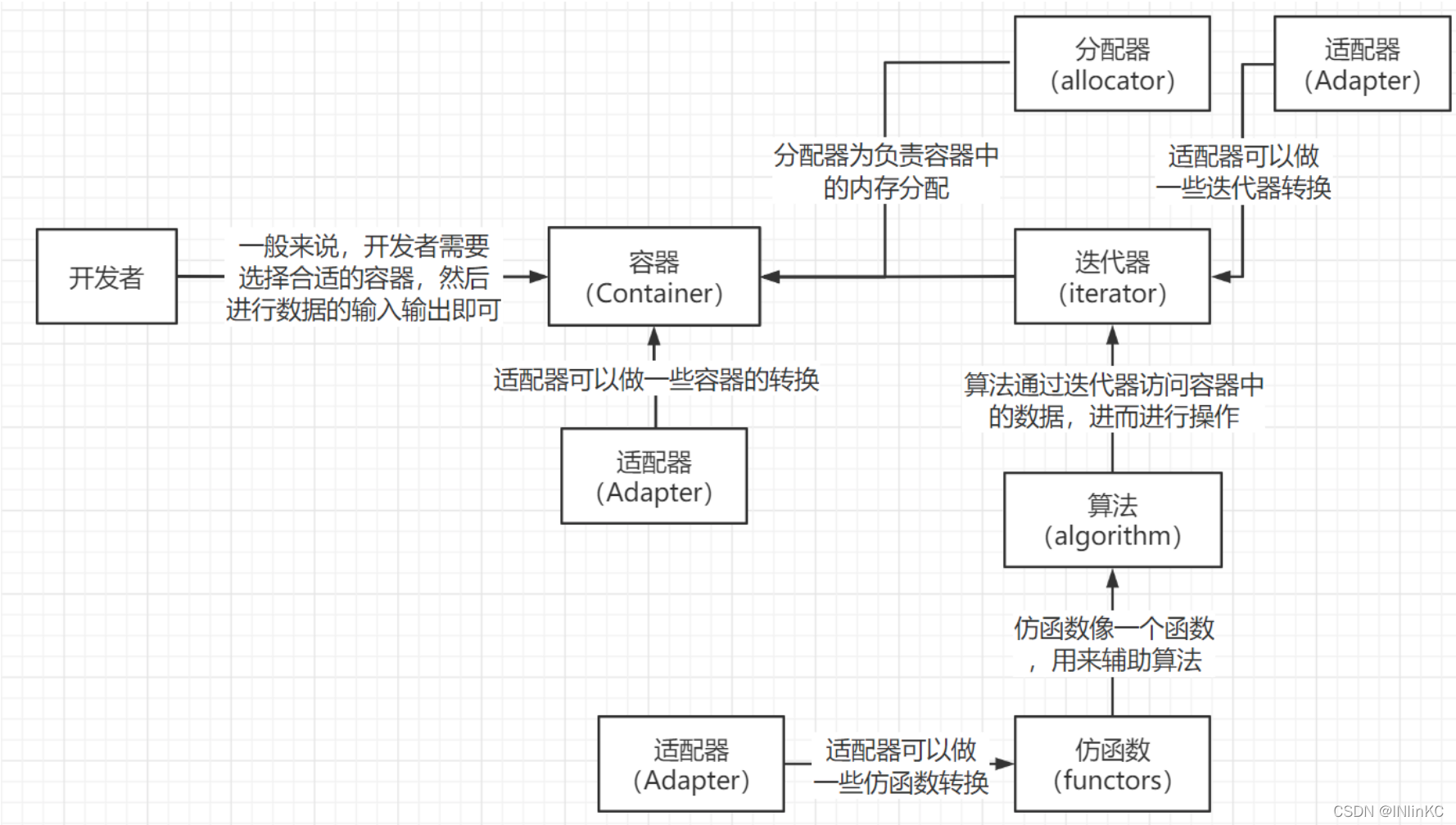
In the following illustration , We used the following :
1. One Containers vector
2. Use vector when , Use distributor Allocate memory
3. Use vi.begin(),vi.end() namely iterator , As a parameter of the algorithm
4. Use count_if Algorithm
5. Use functor less()
6. Using functions Adapter To further screen the results of our algorithm (not1, bind2nd)
2. Complexity

3. Iterator interval
An iterator is an interval that is left open and right closed , That is to say, iterator end Is the next element of the last element .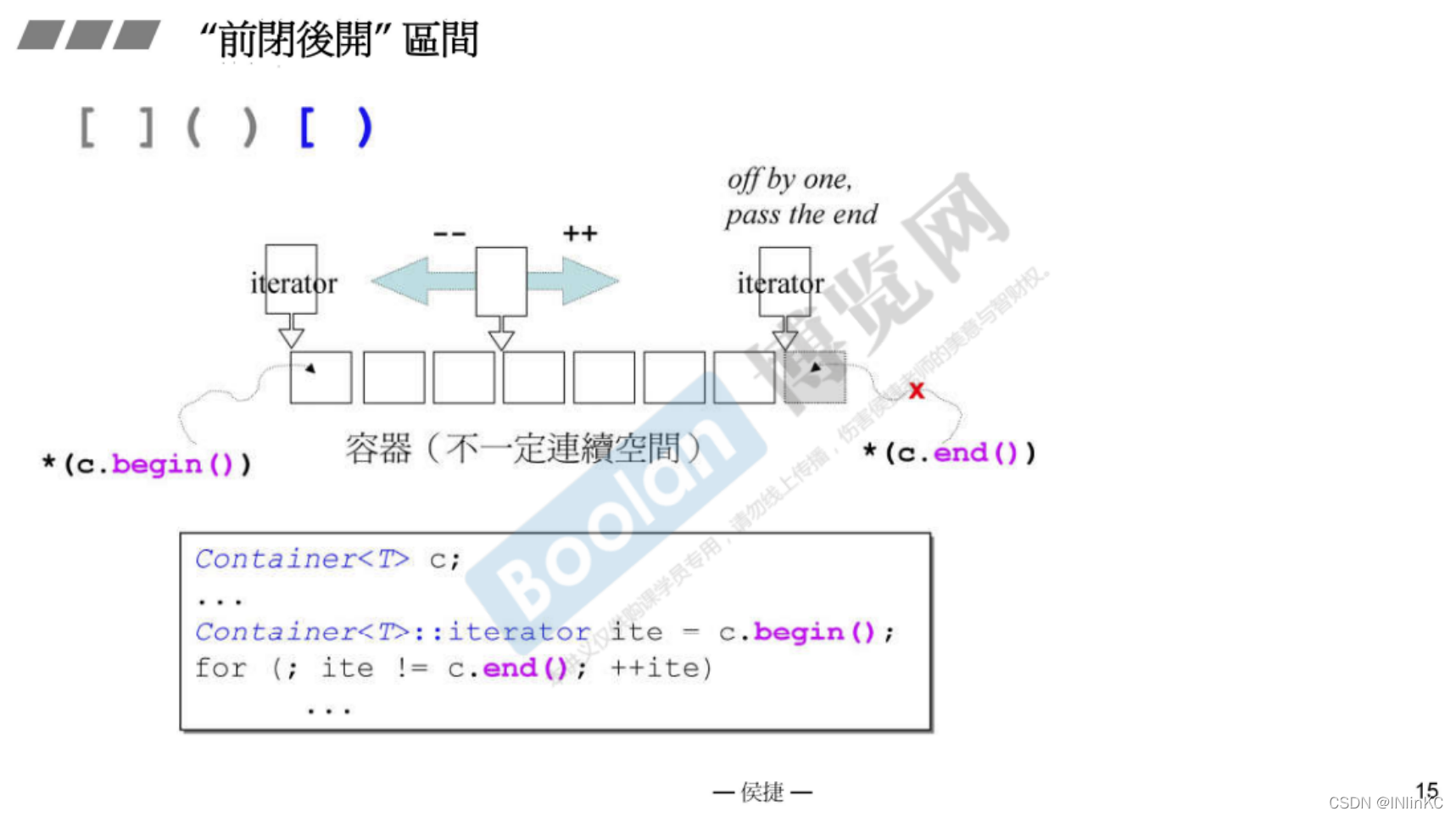
4. Structure and classification of containers

2. Container classification and testing
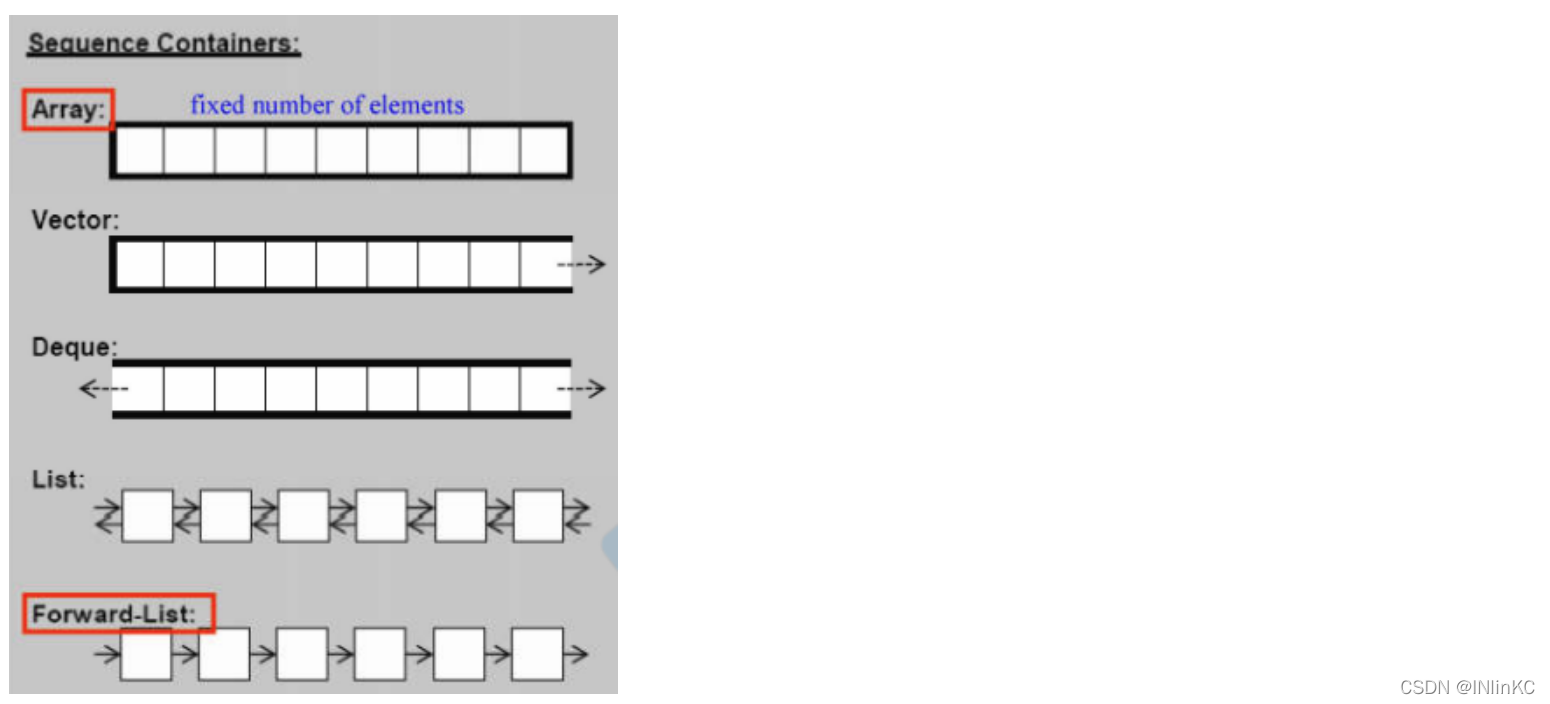
1. Sequential containers
Sequential containers are characterized by putting data into the container , It will be arranged according to the order in which users put it
Sequential containers
characteristic
Additional learning materials
array
A continuous space , Whether used or not , Will occupy all
vector
The tail can enter or exit , When the space is insufficient, it will automatically expand
deque
Both directions can be expanded , Both ends can be in and out
list
A two-way circular linked list , There are two pointers forward, backward and backward
forward_list
A one-way list , Only one pointer backwards
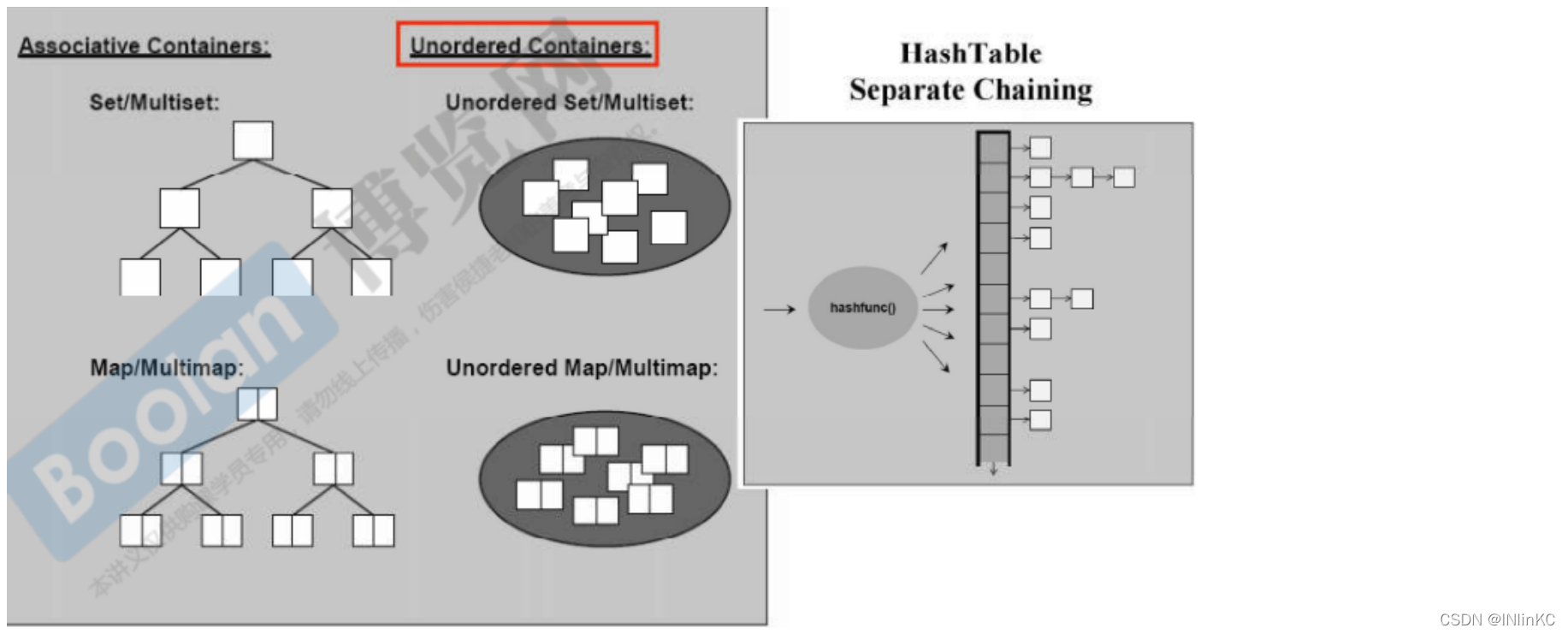
2. Associative containers
Associative containers are similar to key-value, It is very suitable for finding operations
Associative container name
characteristic
Realization
notes
Additional learning materials
set/multiset
key and value Is the same ,BST Storage is orderly
Red and black trees
add multi It means that key value pairs can be repeated
map/multimap
every last key Corresponding to one value,BST Storage is orderly
Red and black trees
add multi It means that key value pairs can be repeated
unordered_set/unordered_multiset
be relative to set/multiset, Storage is out of order
Hashtable
add multi It means that key value pairs can be repeated
unordered_set,unordered_multiset
unordered_map/unordered_multimap
be relative to map/multimap, Storage is out of order
Hashtable
add multi It means that key value pairs can be repeated
unordered_map,unordered_multimap
3. distributor (Allocator) Detailed explanation
1. The overview
The efficiency of the distributor is very important . Because containers must use allocators to allocate memory , Its performance is crucial .
stay C++ in , Memory allocation and operation through new and delete complete .
new There are two operations in , The first step is to use operator new Allocate memory , The second step is to call the constructor ;
delete There are two operations in , The first step is to call the destructor , The second step is to use operator delete Free memory .
1. The bottom layer of the distributor will return to malloc
C++ The memory allocation action of will eventually return to malloc,malloc Then according to different types of operating systems (Windows,Linux,Unix etc. ) The underlying system API To get memory
At the same time we can see ,malloc There is not only data in the allocated memory block , It also contains a lot of other data . It's easy to think that if you allocate more times , The more scattered the data in memory , The greater the additional data overhead .
So an excellent distributor , We should try our best to make these extra spaces take up a smaller proportion , Make it faster .

2.VC6,BC5,GC2.9 Source code analysis of the standard library allocator
Above we mentioned the evaluation criteria of the distributor , Now let's take a look at how the allocator in the standard library of the compiler is implemented .
VC6,BC5,GC2.9 Our standard library allocator is not specially designed . It's called malloc and free.
Drawbacks as follows :
1. Interface design is inconvenient . If we call the allocator alone , Then we need to remember the pointer to the allocated memory space , And the amount of memory space allocated . Otherwise we can't use deallocate To release this space . Although the container will not affect .
2. If we need to allocate space many times , The default allocator has a small space allocated each time , As a result, we need to allocate memory many times , It also requires a lot of extra space . Then the efficiency of this distributor without special design will become low in this case , Affect the efficiency of program operation 
BC5 Distributor and VC6 There is no essential difference .BC5 Its advantage is that the second parameter of its allocator has a default value , It makes it easier for us to call the allocator .
GC2.9 Self contained allocator Also almost 
although GC2.9 It is also basically consistent with the above , But it has an additional statement not to use the allocator of this standard library , At the same time, this standard library allocator is not used . The allocator it uses is self modifying
GC2.9 It uses a called alloc The distributor of 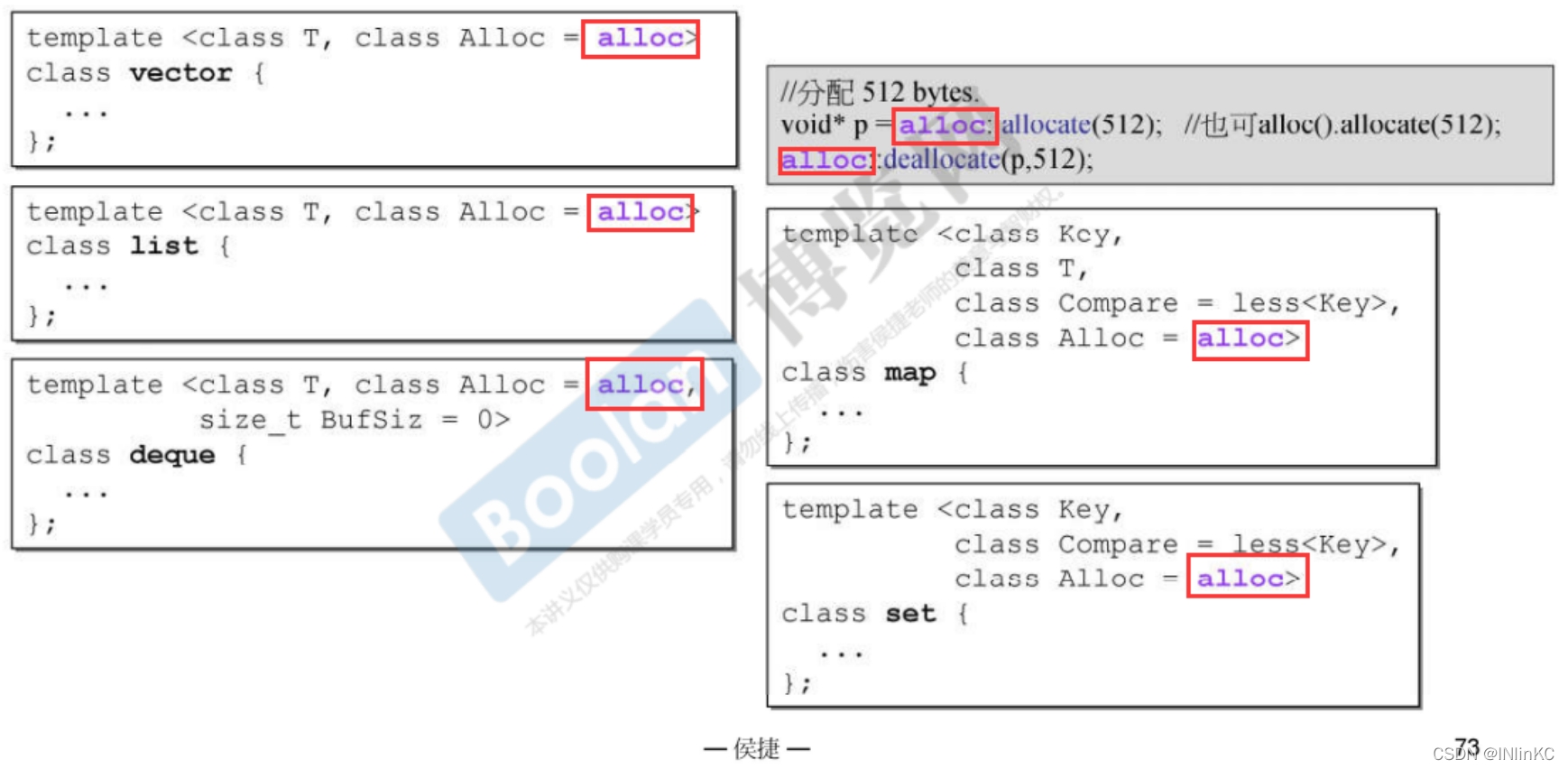
3.GC2.9 The idea of improving the efficiency of the distributor
1. Introduction to memory space
Through object-oriented advanced programming ( On ) Learning from , We can malloc The allocated memory block is divided into these parts .
2.G2.9 distributor ——alloc
From the above analysis of memory space, we can know ,malloc There needs to be a place in the allocated memory block to store the size of this memory block . However, for the same container , Its built-in type should be the same , So for the dispenser of the container , We can optimize this .
alloc Created 16 One way linked list is used to store data . These one-way linked lists are used to store data of different element sizes .
When the container needs memory ,alloc First check whether you have applied for this size of memory , If you have already applied , Then continue to put it at the end of the corresponding one-way linked list . Otherwise call malloc Apply for a piece of memory space from the system . See here for details 【C++ memory management 】G2.9 std::alloc Operation mode
Its advantage is , Because each linked list has only one size element , So for every element on this list , We no longer need to use memory space alone to record its size . This saves memory space 
In this picture, you can see many lines that look very messy , This is actually alloc Memory request mechanism of ,alloc The remaining memory margin will be considered when applying for memory ( There is pool among ), If there is memory allowance, when you next apply for space , The remaining memory space allocated last time will be cut according to the required size and mounted on the corresponding node . If the last remaining size is not enough to divide , Then the remaining memory space will be hung on the node with the same memory space size , Then reallocate memory . For details, please refer to here
stay G4.9 in , The distributor becomes new_allocator, Old distributor alloc Renamed as _pool_alloc.
4.( Add )SGI Two stage distributor

STL The distributor is used to encapsulate STL The underlying details of the container in memory management . stay C++ in , Its memory configuration and release are as follows :
new The operation is divided into two stages :
(1) call ::operator new Configure memory ;
(2) Call the object constructor to construct the object content
delete The operation is divided into two stages :
(1) Call the object destructor ;
(2) call ::operator delete Free memory
For precise division of labor ,STL allocator Separate the two phase operations :
Memory configuration has alloc::allocate() be responsible for , Memory is released by alloc::deallocate() be responsible for ;
Construct objects from ::construct() be responsible for , Object deconstruction consists of ::destroy() be responsible for .
At the same time, in order to improve the efficiency of memory management , Reduce the memory fragmentation problem caused by small memory application ,SGI STL Two level configurator is used
When the allocated space size exceeds 128B when , Will use the first level space configurator ; When the space allocated is less than 128B when , The second level space configurator will be used .
The first level space configurator directly uses malloc()、realloc()、free() Function to allocate and release memory space , The second level space configurator uses memory pool technology , Manage memory through free list .
Of course ,alloc It can also be directly used as the first stage distributor .
4. Depth exploration list
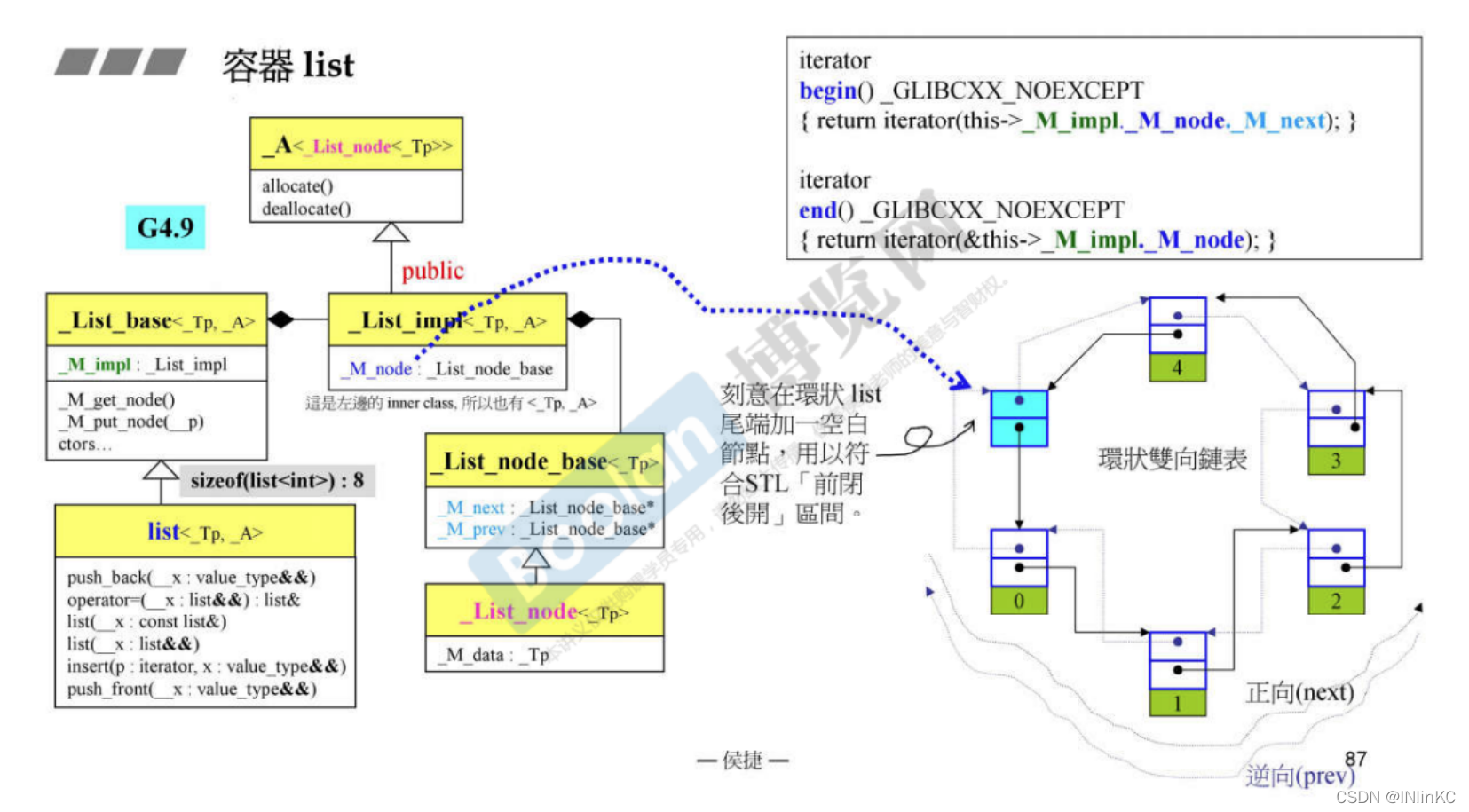
1.list Basic composition of
list It's a two-way list , Its basic composition is
member
effect
prev The pointer
Point to the previous element
next The pointer
Point to the next element
data
To hold data

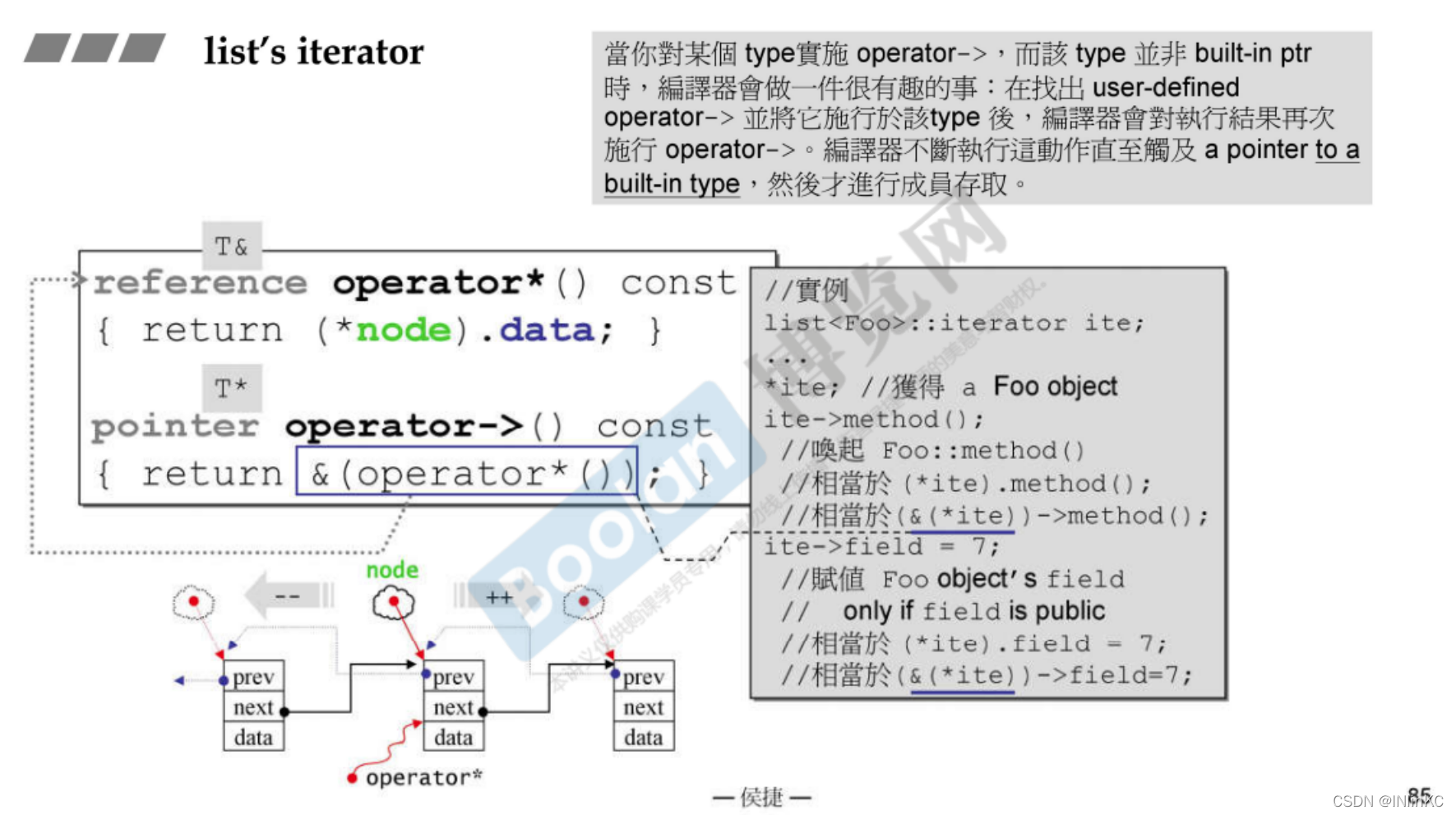
2.list The iterator
Because people are generally used to : iterator ++ Is to find the next element , iterator – Is to find the last element . In double linked list list in , We can know that the next element is next Reference element , The last element is prev Reference element .
If we want to implement iterators ++ The operation of , You need to visit list Node corresponding next The pointer . So an iterator is a class , These operations need to be encapsulated for us , Or to be more precise , The iterator class is a Intelligent pointer .
list The insertion and joining operations of the will not cause the original list Iterator failure , For delete operations , There is only a ” Point to the deleted element “ The iterator of failed , Other iterators are unaffected
1.++i and i++ overloaded
Q: stay C++ in , because ++i and i++ There is only one parameter , So how to overload these two types respectively ?
A: stay C++ in , It is specified that with parameters is post ++, What has no parameters is the prefix ++. for instance
operator++(int) {}; // Yes i++ Overload
operator++() {}; // Yes ++i Overload
2. Be careful :
1. After ++ Of * The operator is not dereference , Instead, the copy constructor is called to make a copy
2. To simulate C++ The integer of cannot be operated as follows :
(i++)++; // Don't allow
i++++; // Don't allow
(++i)++; // allow
++++i; // allow
C++ Allow preposition ++ continuity , But postposition is not allowed ++ continuity , So in the iterator , For pre ++, The return is the reference . And the rear ++ The operator does not return reference, It's a value ;
3.G4.9 Of list
1.G4.9 contrast G2.9 Some details of the correction
1.list The type of pointer in is no longer void*
2. The generator no longer needs to pass three forms of one type (T,* T,& T), But in T After that typedef.

2.G4.9 Of list More complicated
5. Iterators supplement
1. Design principles of iterators
Iterators are the bridge between algorithms and containers , So the algorithm will want to know some properties of iterators to assist the algorithm .
These properties are as follows :
Of the five iterators, you must typedef The nature of
explain
iteratior_category
Iterator type
value_type
The type of object the iterator refers to
difference_type
The distance between two adjacent iterators
pointer
Point to value type The pointer to
reference
Yes value type References to
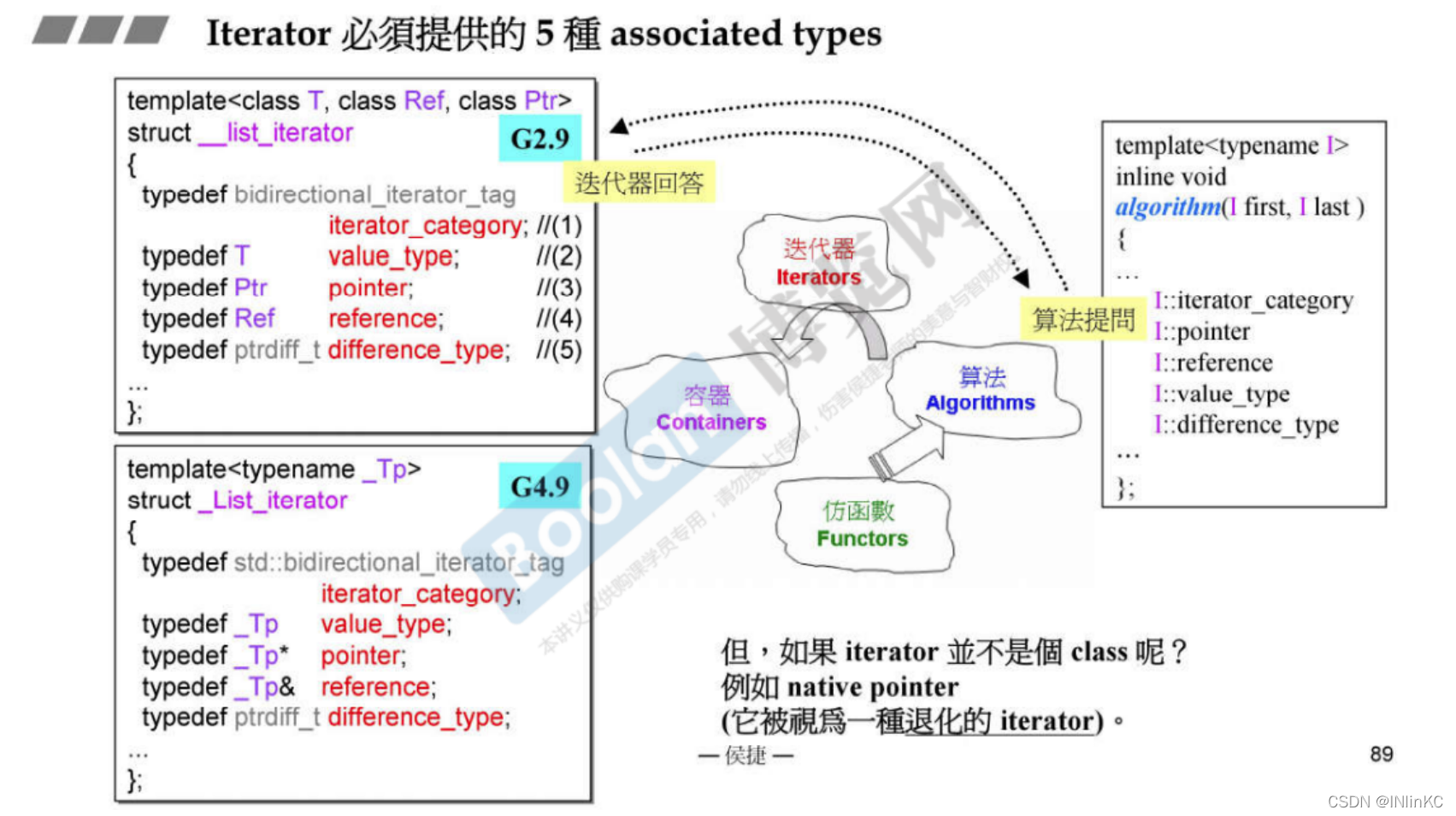
2.iterator traits Function and design of
1. effect
Because of the above design principles, we can know , Iterators must typedef Five properties . But if this pointer is not a class The pointer to , It's just an ordinary pointer , In this case , How can we tell ?iterator traits Have used the .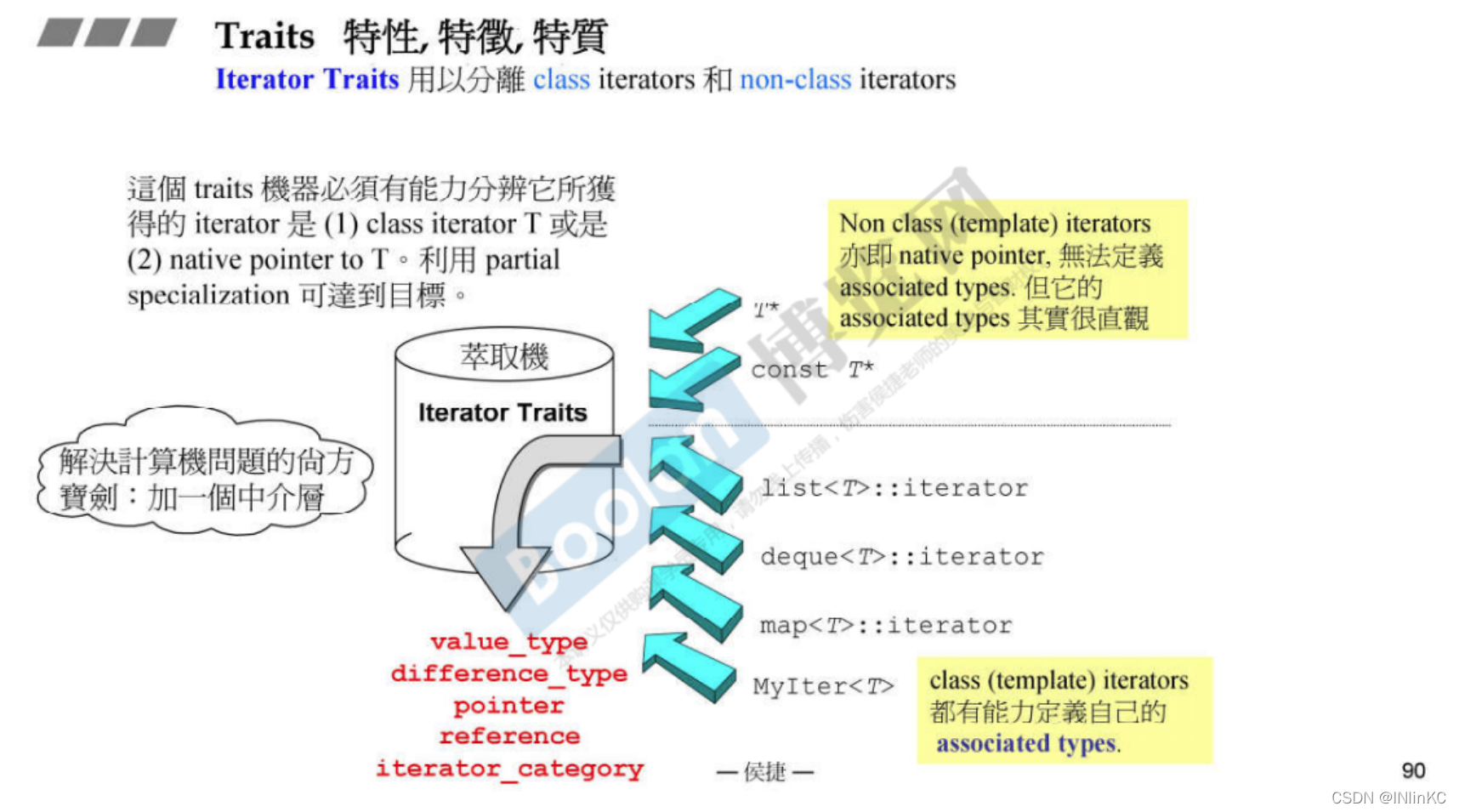
2. Design
Design an intermediate layer as the medium between the iterator and the algorithm , This middle layer is iterator traits
It's actually using C++ The partial specialization of the template in .
Pay attention to even const The pointer , In order that it can create a non const Variable , We should also return a non const The type of .
chart 1 Here are just examples , Complete in Figure 2

6. Depth exploration vector
vector It is an automatic expansion array.
1. The source code parsing
vector It is mainly maintained through three pointers , They are the starting point , Current end point , And the current maximum space 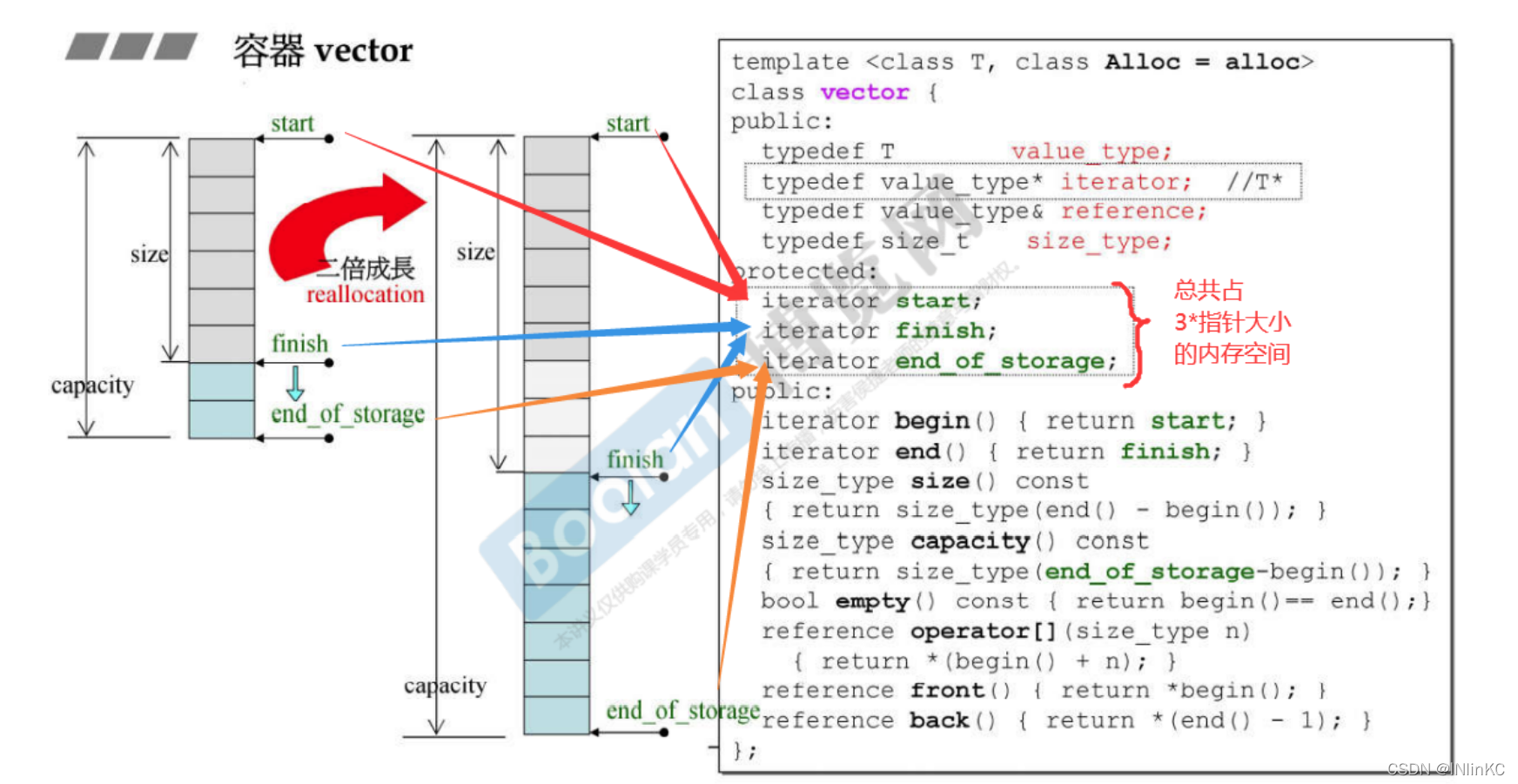
2.vector The form of growth —— Double the growth
vector Whenever you encounter different situations in space , Will apply for space according to twice the current maximum space .vector Each expansion will cause copies of elements depending on the number of elements , And the deletion of elements .
If you apply for less than twice the space , Life will end automatically .
Interview questions :C++vector Dynamic expansion of , Why? 1.5 Times or 2 times ?
1. Homemade vector Growth flow chart :
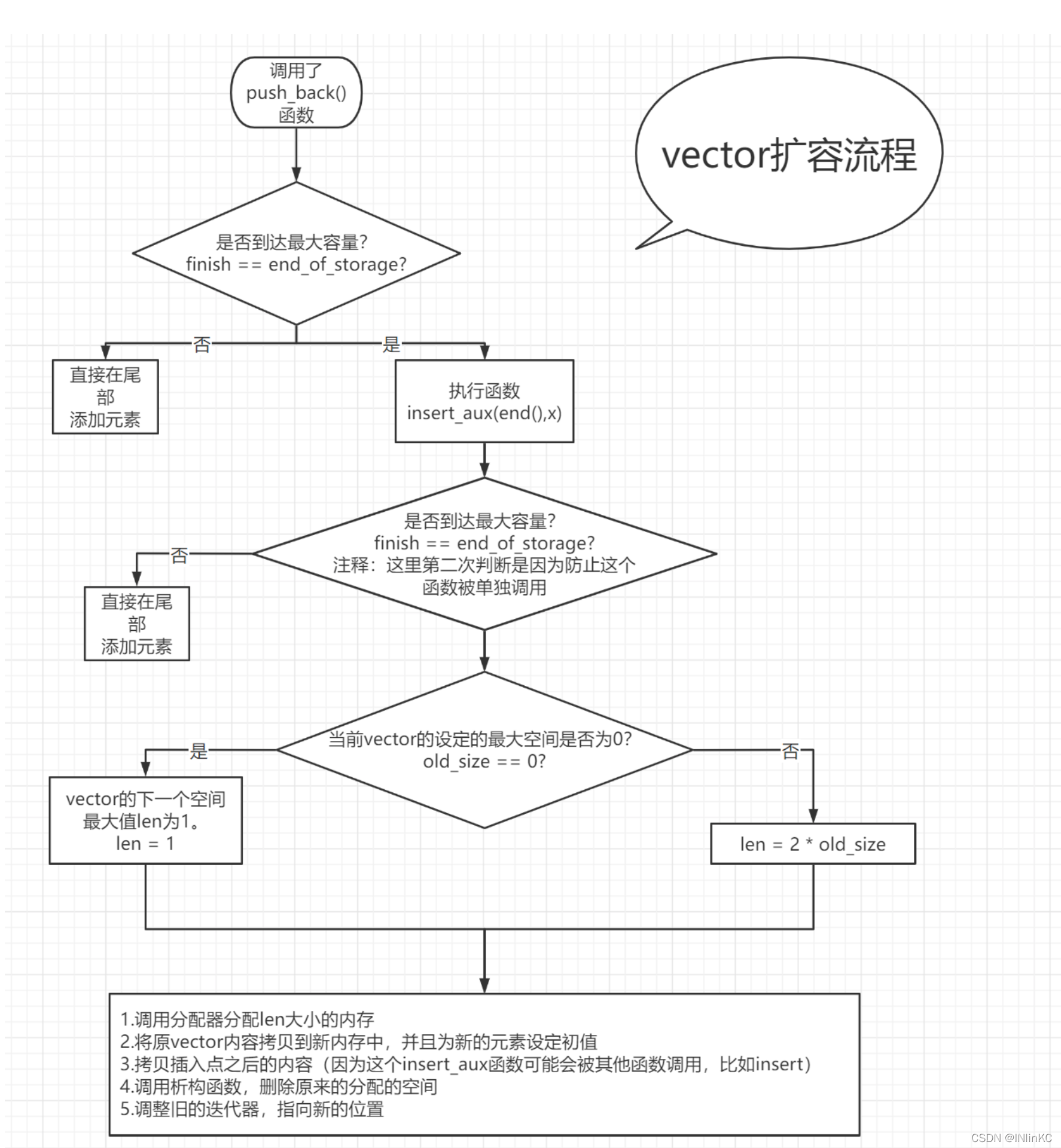
2. Code


3.vector The iterator
Be careful : The insertion operation may cause vector Of 3 Pointer reconfiguration , Cause all the original iterators to fail
1.G2.9 Version of vector iterator
because vector Itself is continuous , Memory is also continuous , So normally vector The iterator of does not have to be set up very complex , Just one pointer is enough . in fact ,G2.9 That's exactly what we do in China .
stay G2.9 In the version ,vector The iterator is a pointer . If you put it in iterator traits In the middle , Because this iterator is a separate pointer rather than a class , Therefore, we will take the route of partial specialization to provide the required properties for the algorithm .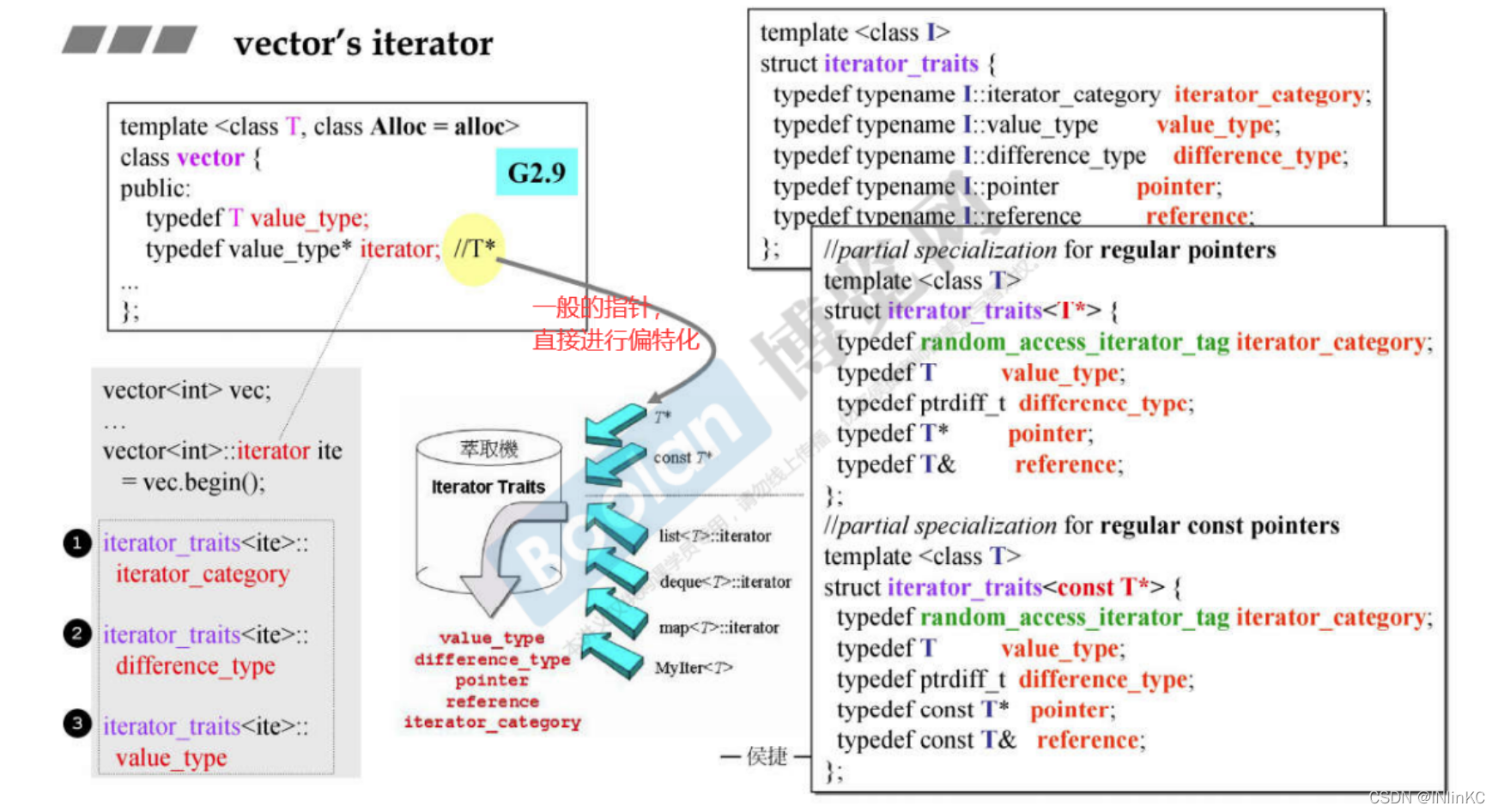
2.G4.9 Version of vector iterator
However, in G4.9 in ,vector The iterator of is designed to be very complex , At the same time, it becomes a class . therefore G4.9 After that vector Iterators will no longer go pointer specialization iterator traits 了 .
But this operation is very complicated , And it didn't affect the final result , in other words G2.9 and G4.9 There is no essential difference between iterators of .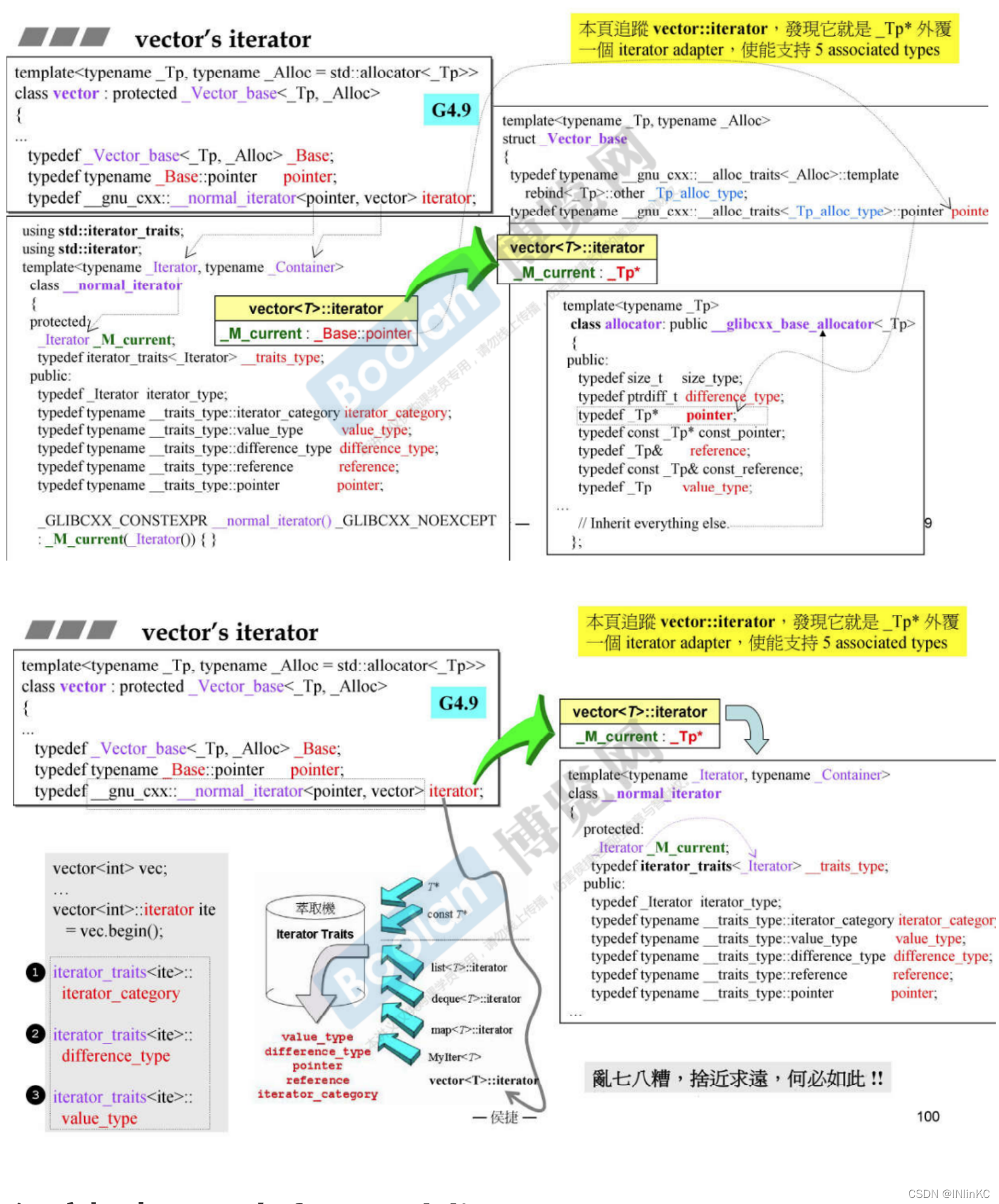
7. Depth exploration array And forward_list
array Is a fixed length array .
Q: Why would you array Designed as a container class ?
A: Because it can make array Return the five properties required by the algorithm , In this way, the algorithm can be adapted array To do some operations to improve the performance of the algorithm .
1.array The source code parsing
stay TR1 in ,array The source code is relatively simple .
Because it's a continuous space , So iterators are implemented with pointers , adopt iterator traits Take the partial specialization route .
stay G4.9 in ,array The source code of and the above vector Become complex , Its iterator becomes a class
Actually and TR1 There is no difference in the final effect .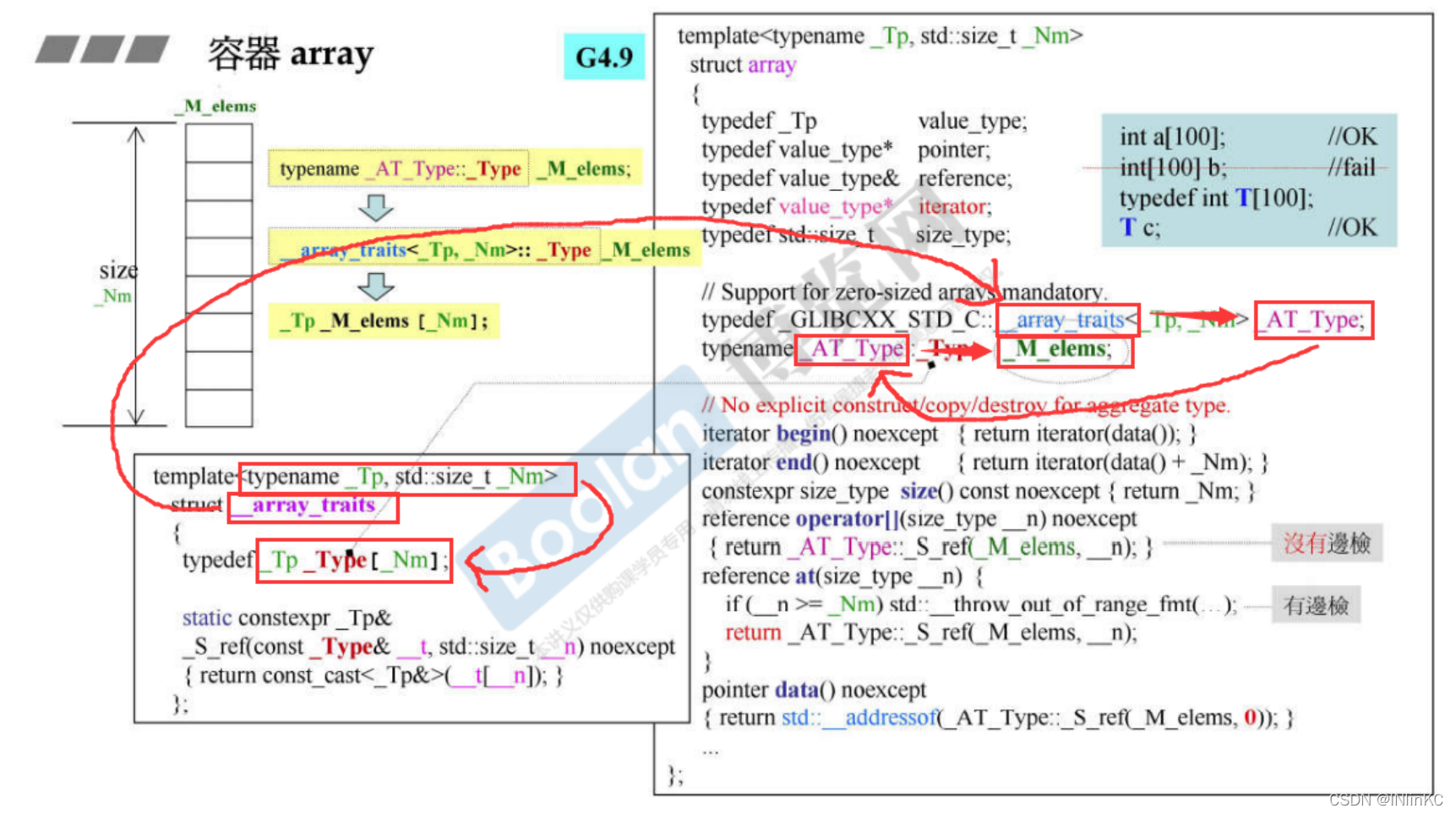
2.forward_list The source code parsing
forward_list It's the one in front list One less forward pointer , Refer to previous list that will do 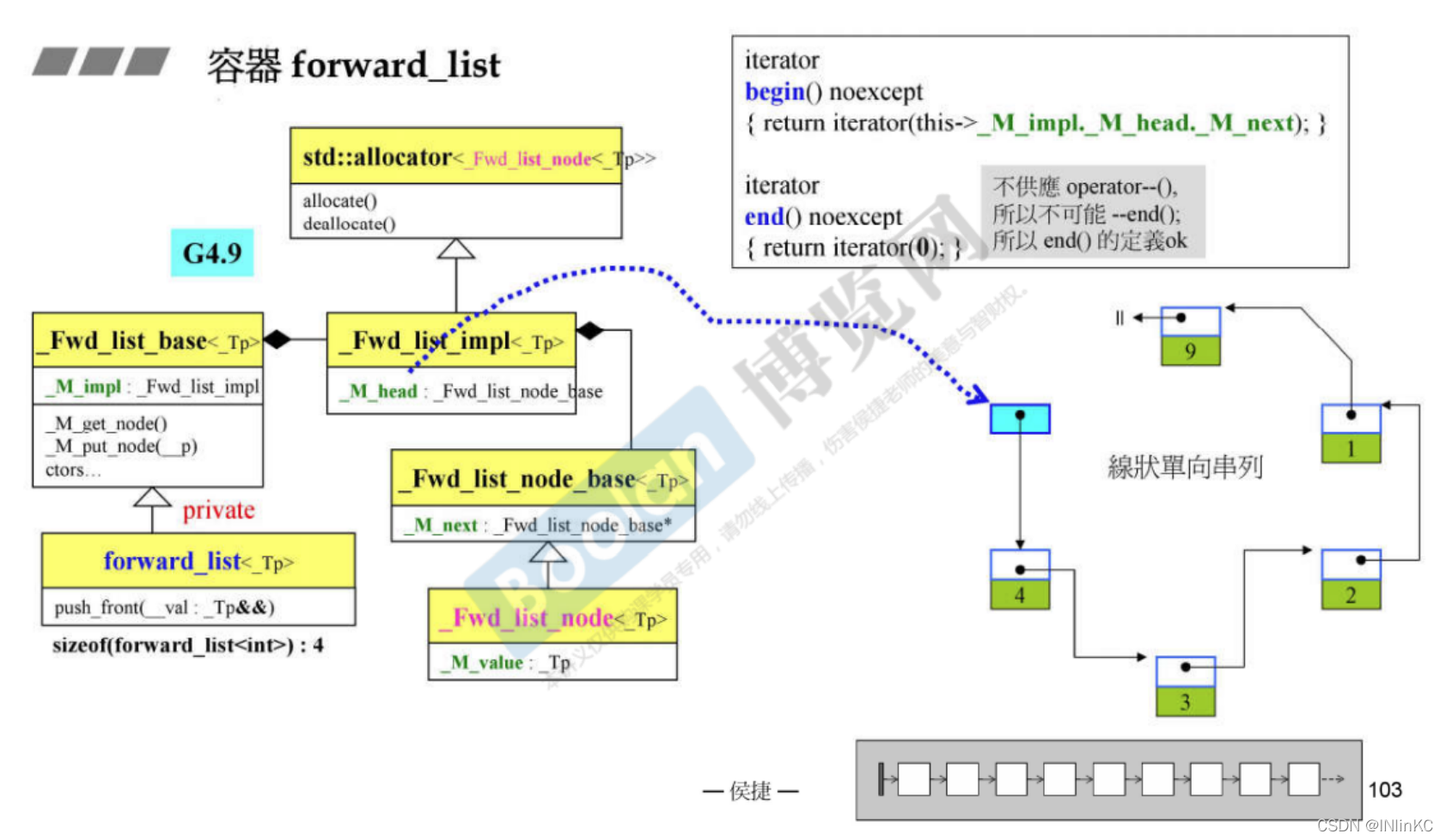
8. Depth exploration deque,queue,stack
1.deque
1.deque An overview of the structure
deque External is continuous , But the interior is not continuous .
deque Components
effect
One vector
Never store the iterator location of those memory spaces , imitation “ continuity ”
A number of buffer Size of memory space
To hold data
deque Analysis of the function of the four pointers in the iterator of
name
effect
cur
At present buffer The location of the current node on
first
At present buffer Position of the upper head node
last
At present buffer Position of the upper tail node
node
At present buffer stay map Position on
When every buffer When the size of memory space is not enough ,vector An iterator pointer will be created at the end and a buffer Size of the new space to put elements . If vector It's not big enough , that vector Will expand capacity by itself . After the expansion, the elements need to be copied again , because deque It's a two-way queue , It will copy the original elements to the expanded vector Of Middle part , In this way deque It has the ability to expand left and right at the same time .vector See the previous explanation for the capacity expansion mechanism 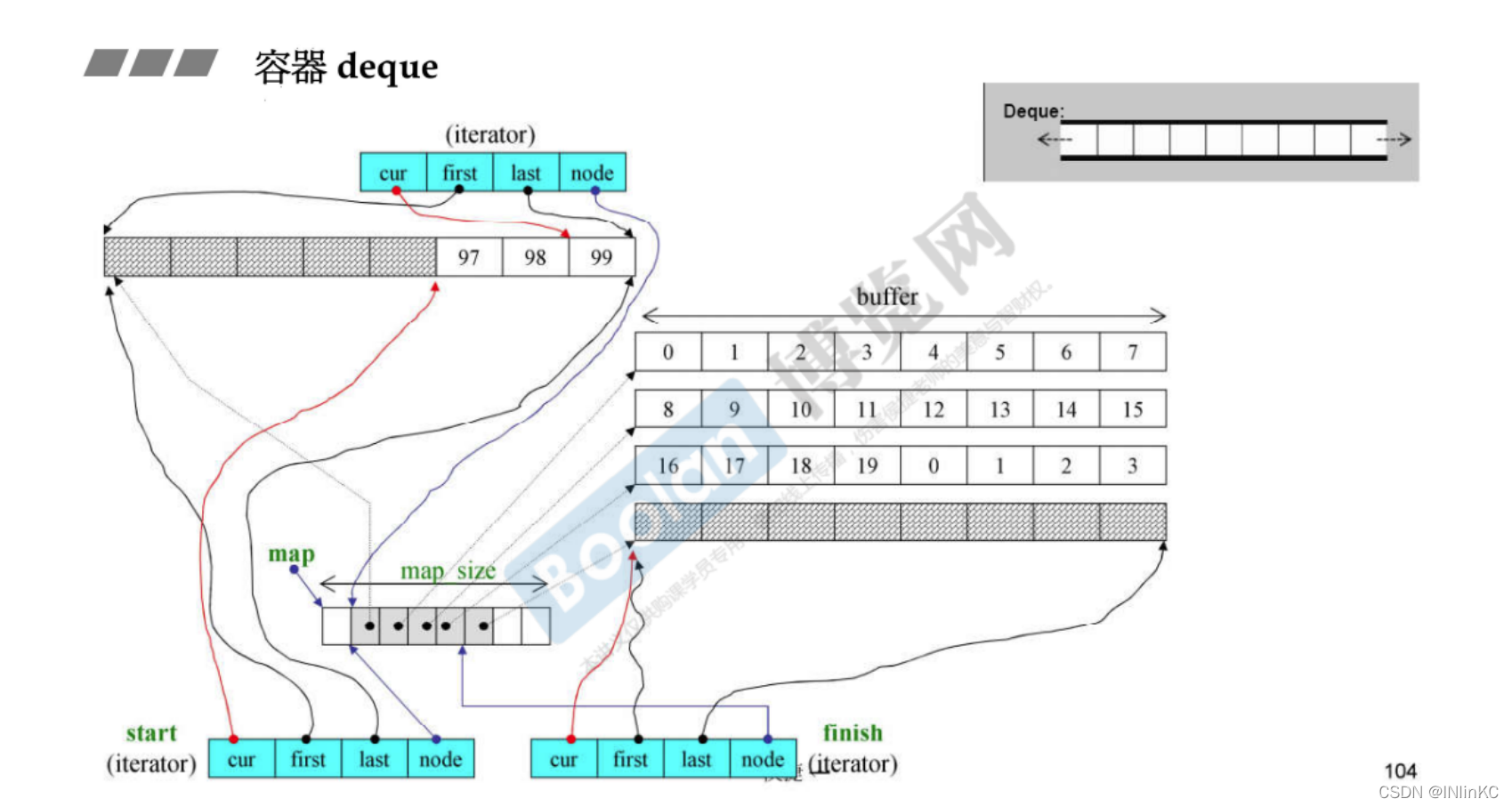
One deque I will occupy 40 Byte size ; stay G2.9 in ,deque You can specify the buffer size by yourself
These sizes of space have :
1.start,finish Two iterators . Point to the first element of the first buffer and the last element of the last buffer, respectively ( The next position of )
2. A pointer to a map The pointer to 
2.deque Of insert Operation analysis
The order of judgment :
1. First, judge whether it is head or tail insertion . If yes, insert elements directly from beginning to end .
2. If it's not head or tail , Then calculate the distance from this node to the head node and the tail node . Let's say it's close to the head node , Then let all the nodes from the head node to the insertion position move forward , Then insert the node ; vice versa .
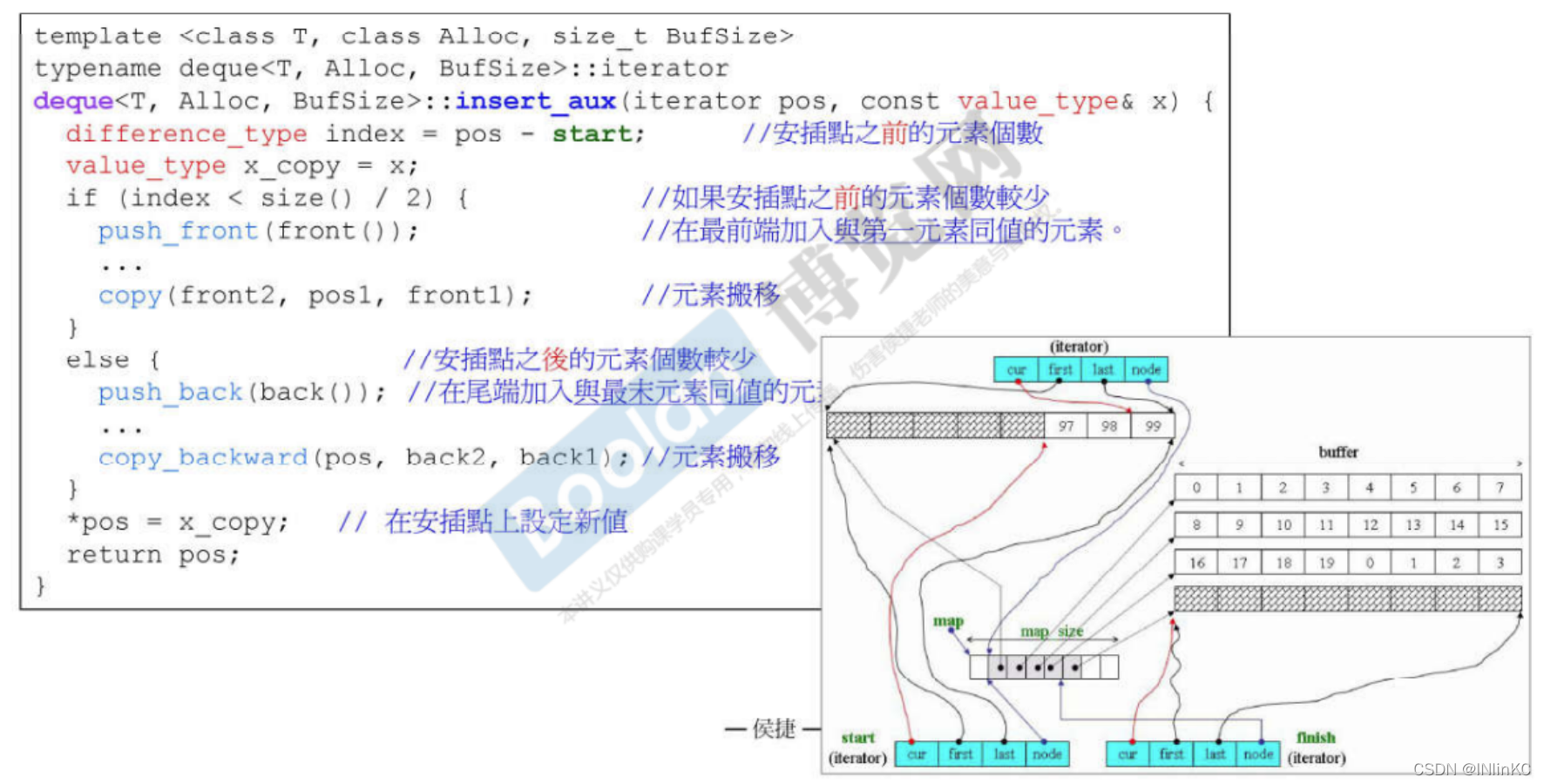
3.deque The technique of simulating continuous space
deque The length of needs to be considered buffer The size and vector in buffer The number of

deque Progress of ++ And retreat – The operation requires additional judgment on whether it exceeds the current buffer Set the size .

If there is a case of moving forward more than one at a time , Then it will be more complicated than the previous situation , Consider switching between buffers

4.G4.9 Of deque
stay G4.9 in ,deque The size of has not changed . The user cannot specify buffer size Size . It also becomes more complex

2.queue and stack
1.queue and stack The implementation of the
about queue and stack, Its function is just deque Subset . In fact, STL in ,queue and stack Often not classified as containers , And classified as Container adapter
queue and stack There is a deque, Then call the completed deque To do what we need .
2.queue and stack Similarities and differences
identical :
1. Traversal is not allowed , Iterators are not provided
2. have access to deque perhaps list As the underlying structure . But in general use deque, because deque Faster
3. Not available set perhaps map As the underlying structure .
Different :
queue Not available vector As the underlying structure , and stack Sure .
9. Deep exploration of red and black trees (RB-Tree), And based on it set,multiset,map,multimap
1. Red and black trees (RB-Tree)
The specific implementation details of red black tree are not involved here . The realization of red black tree depends on this Analysis of red and black trees (RBTree) Principle and Implementation
The red and black trees kept BST The nature of , But at the same time, ensure that the longest path does not exceed twice the shortest path , So approximate equilibrium , Avoid the imbalance between the left and right of the tree, which will reduce the efficiency of insertion and search .
Because the red black tree is a BST, In this way, the iterator should not modify the values of nodes that have been sorted and inserted . But because of C++ Medium red black tree is used as set and map The bottom of the , and map Support modification value, So in C++ in , Red and black trees It doesn't prevent us from modifying the node value .
Red and black trees provide two forms of insertion to the outside world ,insert_unique() and insert_equal(), The former stands for key It is the only one in this red black tree , Otherwise, the insertion fails ; The latter is not .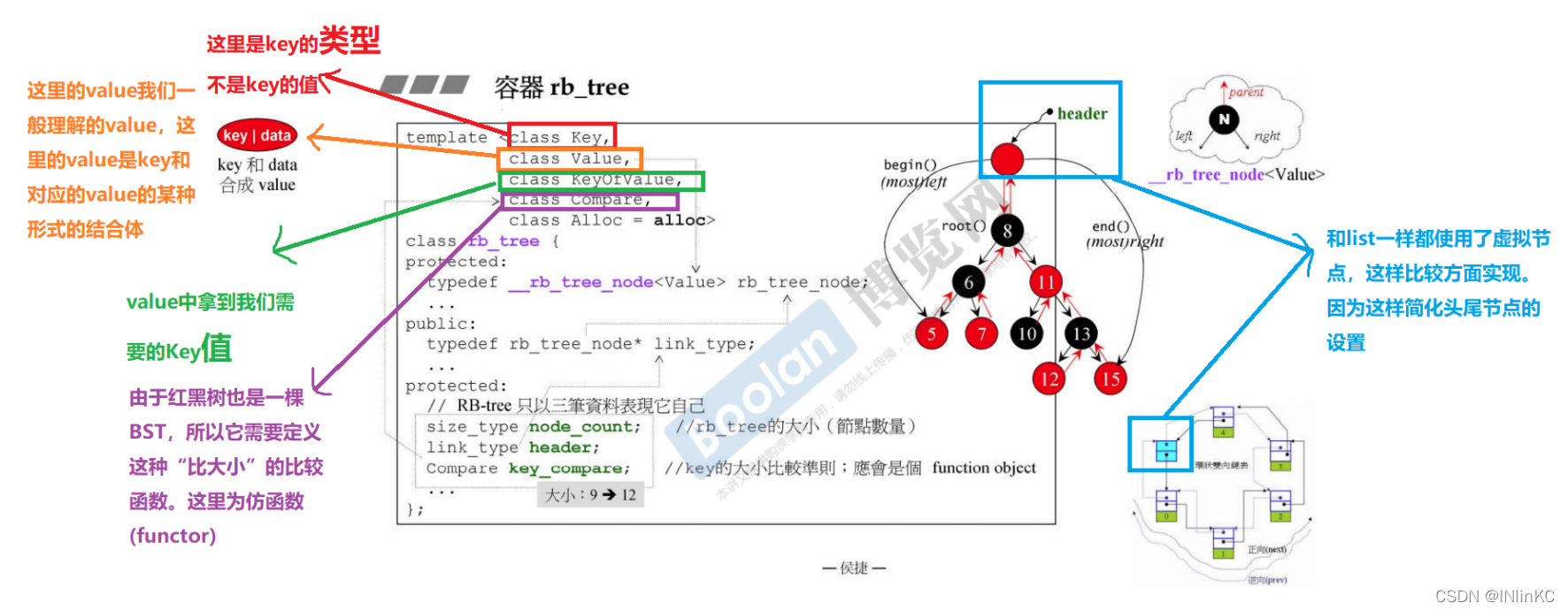
An example of a red black tree is as follows :
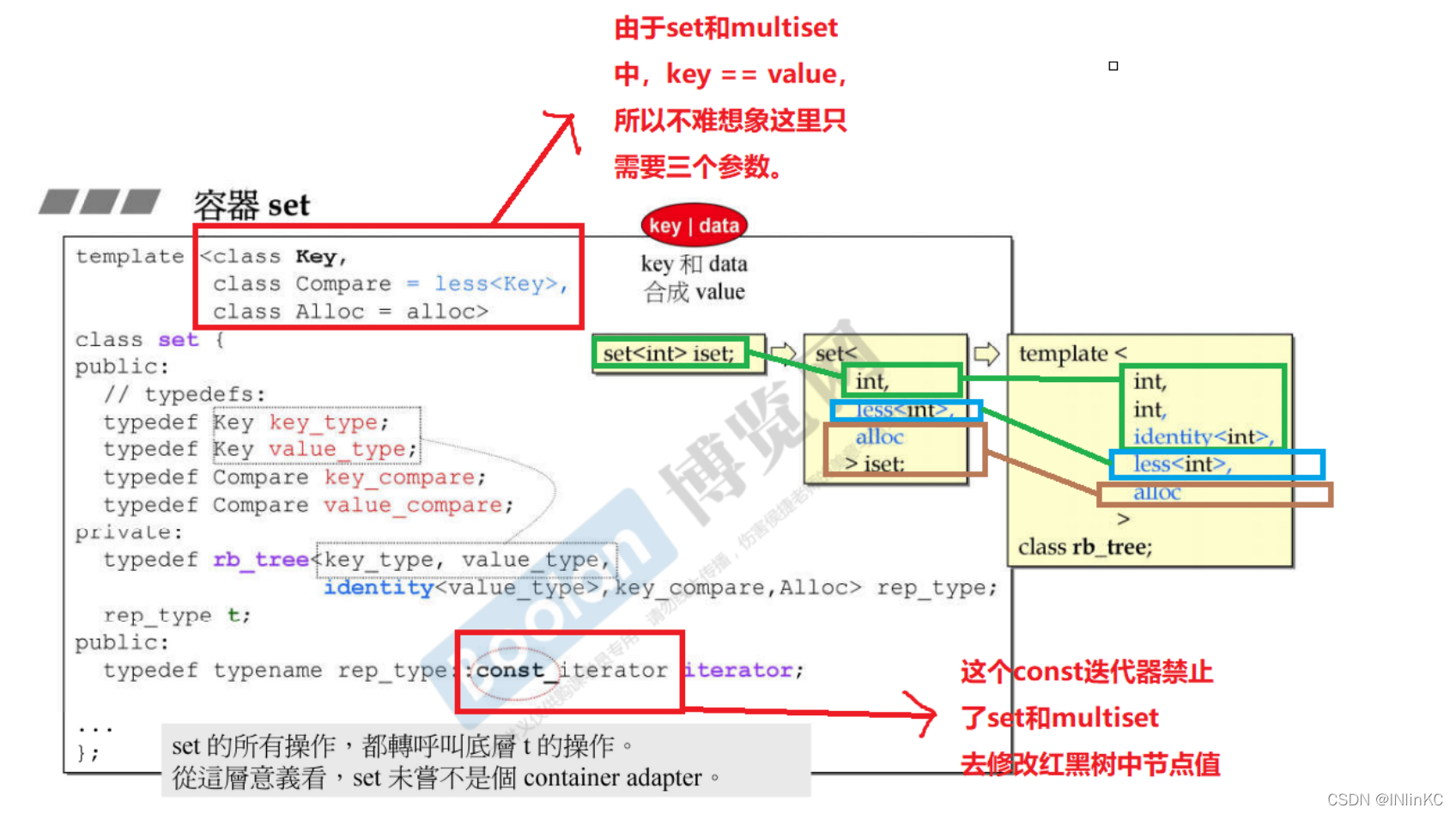
2.set and multiset
set and multiset In fact, it is only part of the functions of the red black tree , In a sense, it is just an adapter
1. Be careful :
1.set Of key == value
2. although set/multiset The underlying red black tree supports modifying node values , however set/multiset And Modifying node values is not supported
3.set and multiset The insertion function of is different
4. although C++ With global generalization ::find() function , But its efficiency is far less than set As defined in set::find(), We Functions defined in containers should be used first as much as possible

2.set and multiset The implementation of the
3.map and multimap
1. Be careful :
1.map Of key != value
2.map/multimap The iterator of does not allow modification key, However, it is allowed to modify value
3.map and multimap The insertion function of is different
2.map and multimap The implementation of the

3.map and multimap Unique [] Operator design
We go through [] visit map/multimap, If this key There is no such thing as map/multimap in , Then he will automatically map/multimap Create and add this key Corresponding value The default value of , Then return it to .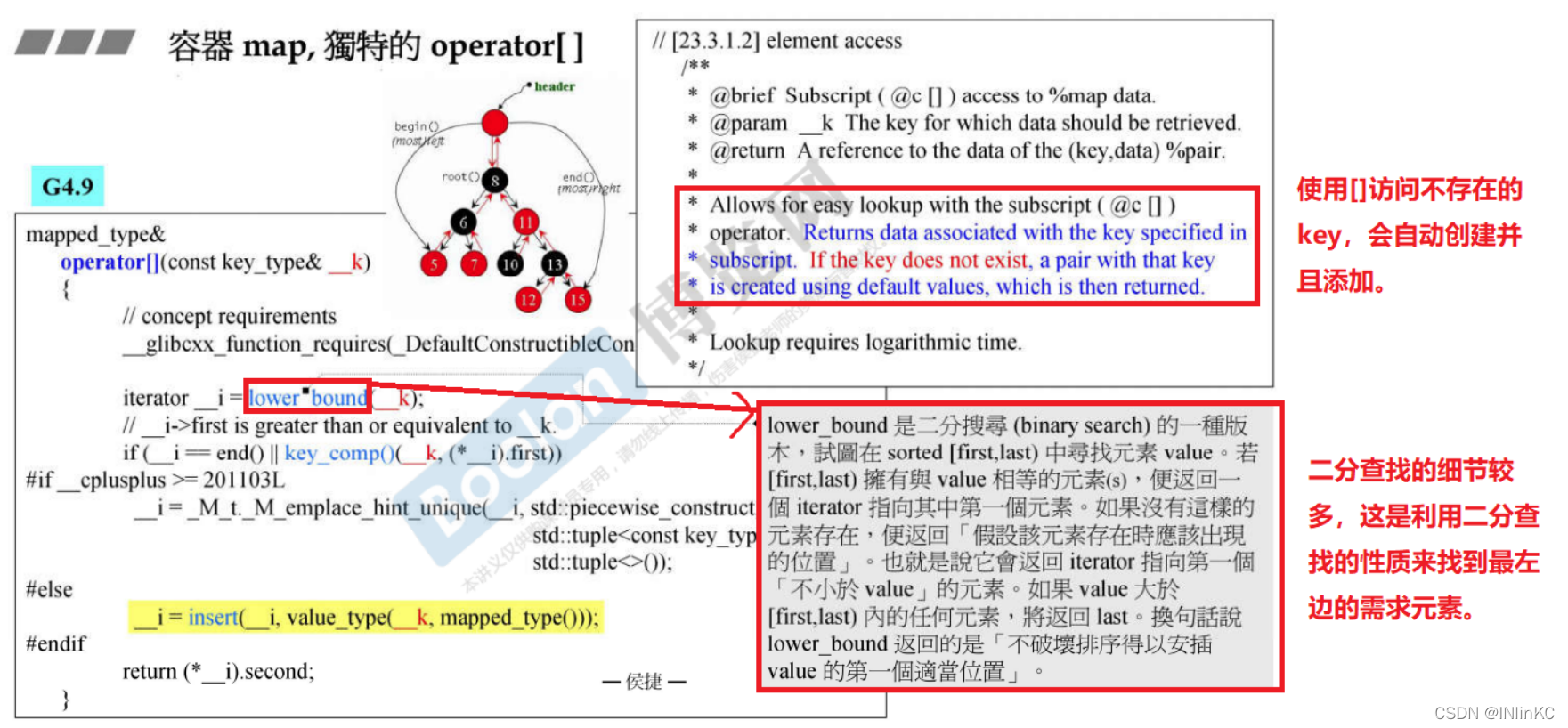
11. Explore hash tables in depth (hashtable), And based on it unordered_set,unordered_multiset,unordered_map,unordered_multimap
1. Hashtable (hashtable)
1. Basic concepts
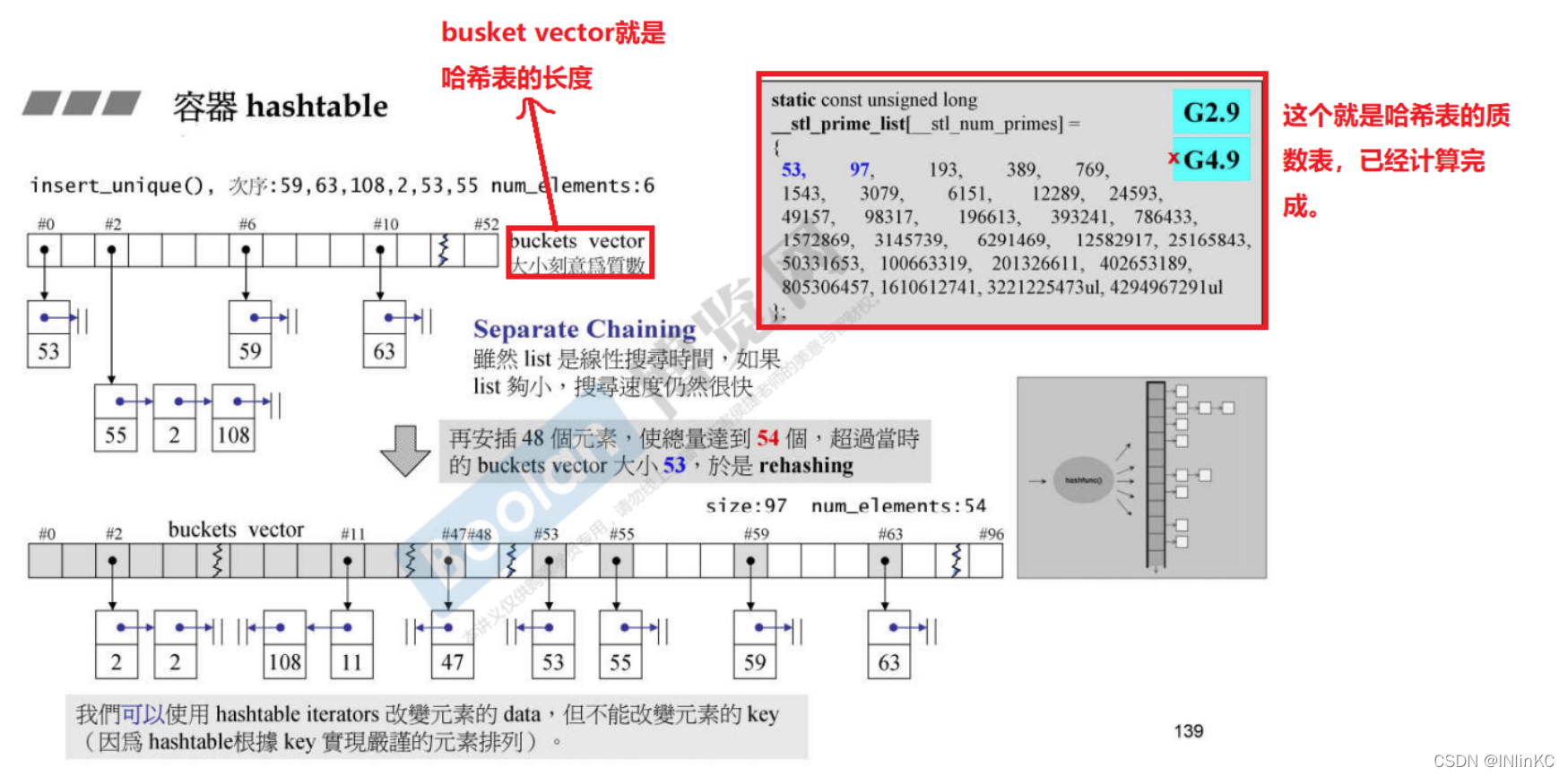
Hash tables are designed to be efficient Storage And efficient lookup The implementation of the . The specific operation is to hash the data we need to store and get the hash value , Then modulo the hash value , Insert the corresponding basket in the hash table (basket) In the middle .
The length of the hash table is a Prime number ;
Separate Chaining: When a hash collision occurs , Form a linked list of nodes with the same hash value and hang it behind the hash value corresponding to this value .
Rehashing: When the total number of elements in the hash table >= Hash table length , Expand the length of the hash table to the nearest prime number twice its original size ( No vector Double expansion , Instead, look for the prime number closest to the value of twice its size , As a new size ), Then reinsert the element .
2. Container analysis
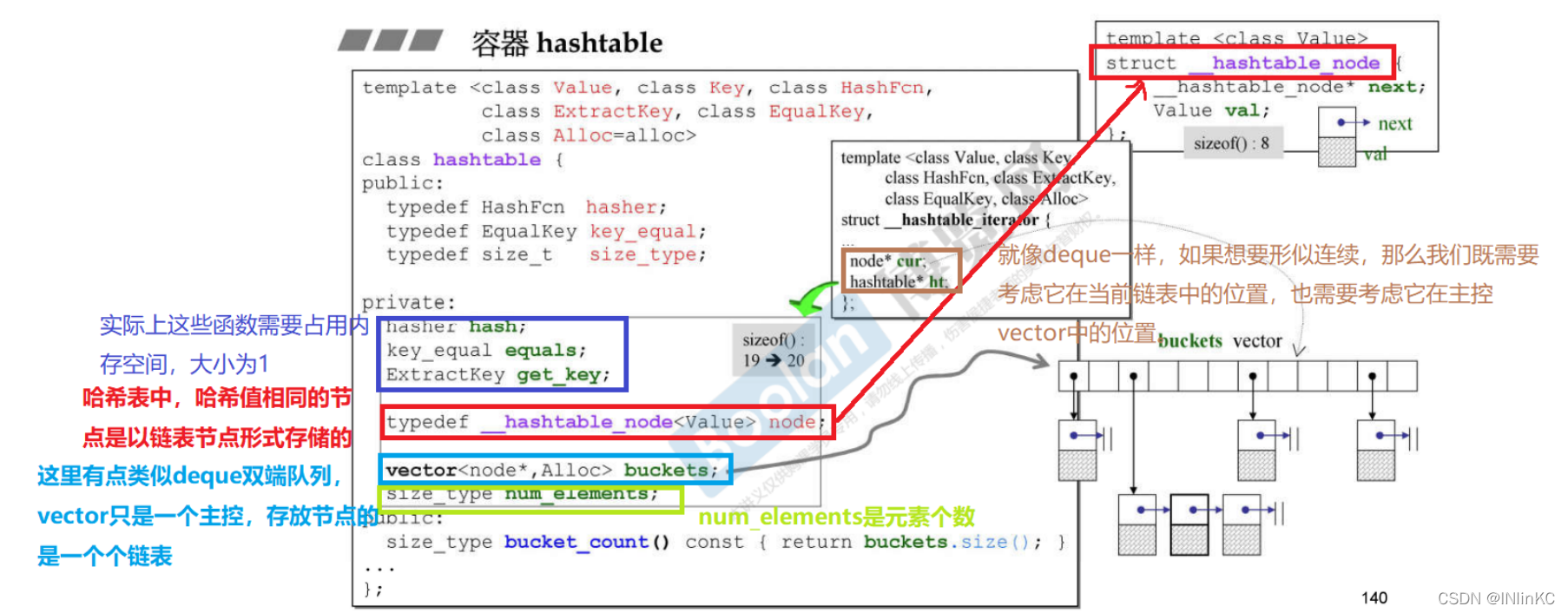
The hash table needs the following 6 Template parameters :
name
effect
Value
Like in red and black trees , Is a composite package of key values
Key
Type of key
HashFcn
Used to calculate incoming key Hash value of , obtain hashcode, So as to find the insertion position in the hash table
ExtractKey
Because the elements stored in the hash table are also key and value package ,ExtractKey Just to get out of this bag key value
EqualKey
Tell the hash table key“ equal ” The definition of
Alloc
distributor
3. hash function (HashFcn)
C++ Some existing hash functions are encapsulated for us in .
2. Unordered container (unordered Containers )
Compared with the ordered container above , The biggest difference is that the underlying implementation has changed . One is the red and black tree , One is the hash table .
3.( Add ) The difference between the red black tree implementation and the hash table implementation
1.map Always make sure that when traversing, you press key In the order of size , This is a major functional difference .( Order and disorder )
2. In terms of time complexity , The insertion, deletion and search performance of red black trees are O(logN) In theory, the insertion, deletion and lookup performance of hash table is O(1), He is relatively stable , In the worst case, it's efficient . Theoretically, the time complexity of inserting and deleting hash table is constant , There is a premise that the hash table does not have data collision . In the worst case of a collision , The insertion and deletion time complexity of hash table can reach... At worst O(n). notes : The worst case is that all hash values are on the same linked list
3.map You can do a range search , and unordered_map Can not be .
4.unordered_map Memory usage ratio map high .
5. Capacity expansion leads to iterator failure . map Of iterator Unless the pointing element is deleted , Otherwise it will never fail .unordered_map Of iterator In the face of unordered_map Sometimes it will be invalid when modifying . Because in operation unordered_map Container process ( In particular, add new key value pairs to the container ) in , Once the load factor of the current container exceeds the maximum load factor ( The default value is 1.0), The container will appropriately increase the number of barrels ( Usually double ), And automatically rehash() Member method , Readjust the storage location of each key value pair ( This process is also called “ Rehash ”), This process is likely to invalidate the iterator previously created .
Source 1
Source 2
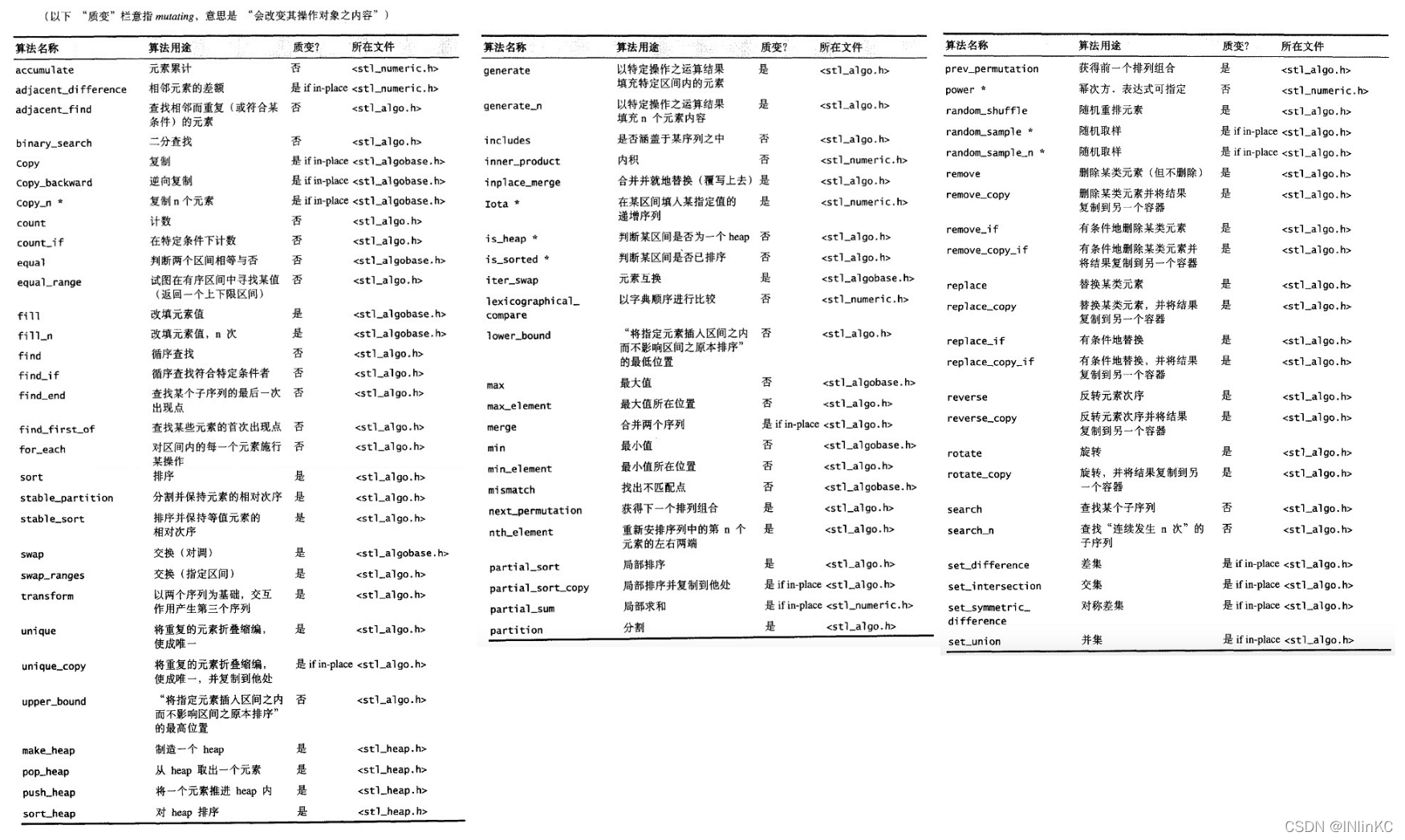
12. Algorithm
The algorithm can't actually see the container , It performs operations through iterators . The algorithm queries the iterator ( There are five related types that iterators need to provide ) To do your job .
The algorithm is a function template at the language level , Specifically, it is an imitative function .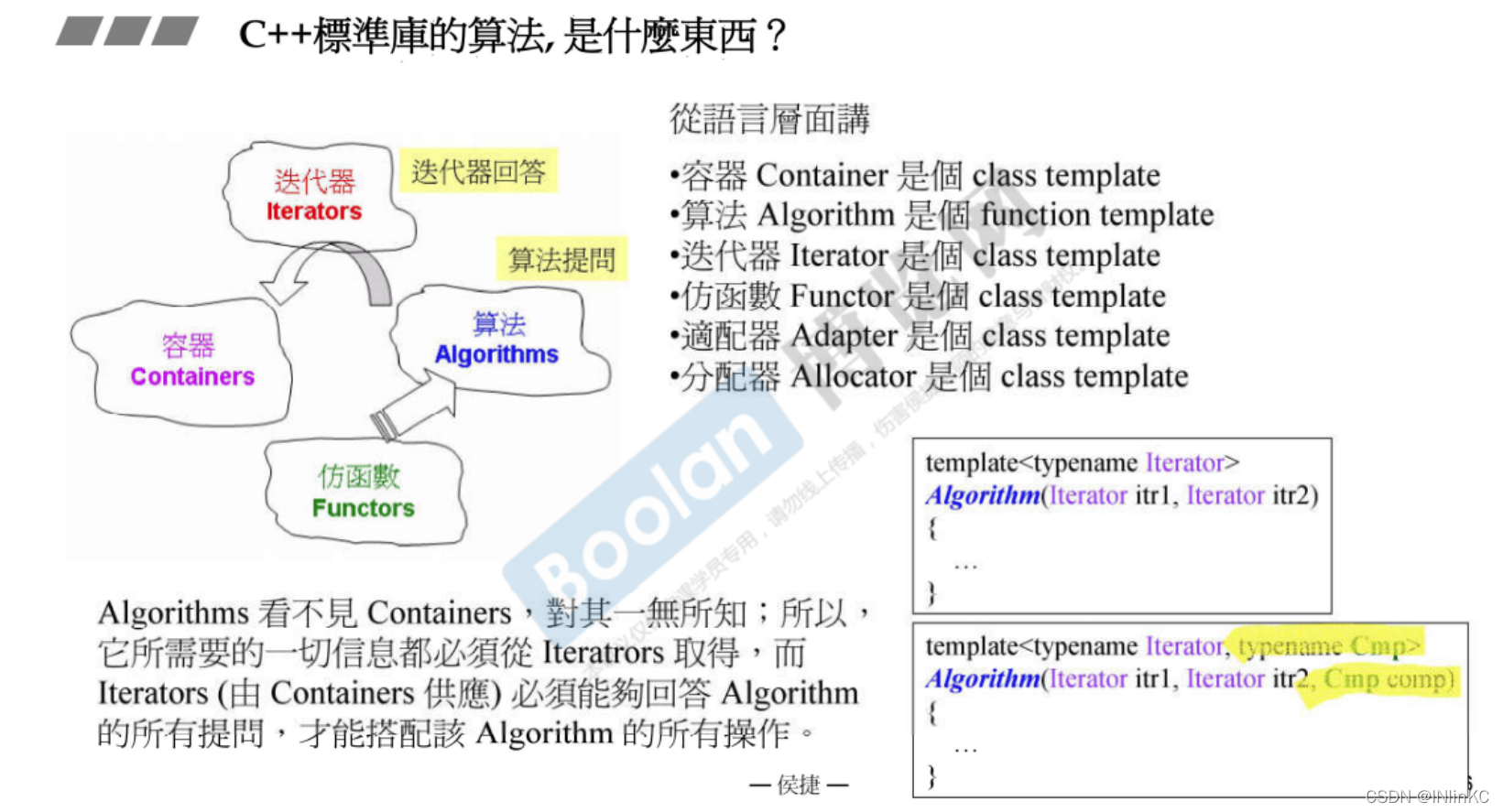
1. iterator
1. All kinds of containers iterator_category
There are five kinds iterator_category, Their relationship is shown in the figure
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-ftQ7gVZs-1643913242997)(en-resource://database/1125:1)]
iterator_category
sketch
Containers
forward_iterator_tag
Only one-way forward
forward_list,unordered_set,unordered_map,unordered_multiset,unordered_multimap
bidirectional_iterator_tag
two-way , Allow forward and backward
list,set,map,multiset,multimap
random_access_iterator_tag
Allow access to random subscripts
array,vector,deque
There are two other special , They each contain only one iterator
iterator_category
Included iterators
input_iterator_tag
istream_iterator
output_iterator_tag
ostream_iterator
adopt typeid() Can get iterator_category
You can notice these printed iterator_category There are some irregular characters and numbers before and after the name , These are determined by the library implementation method in the compiler , Compilers are different , These data are also different . But in fact, in order to meet C++ standard , Its actual type is the same .
2. Four examples of the impact of iterators on algorithms
distance

advance( and distance The approximate , A little )
and distance The practice is basically the same .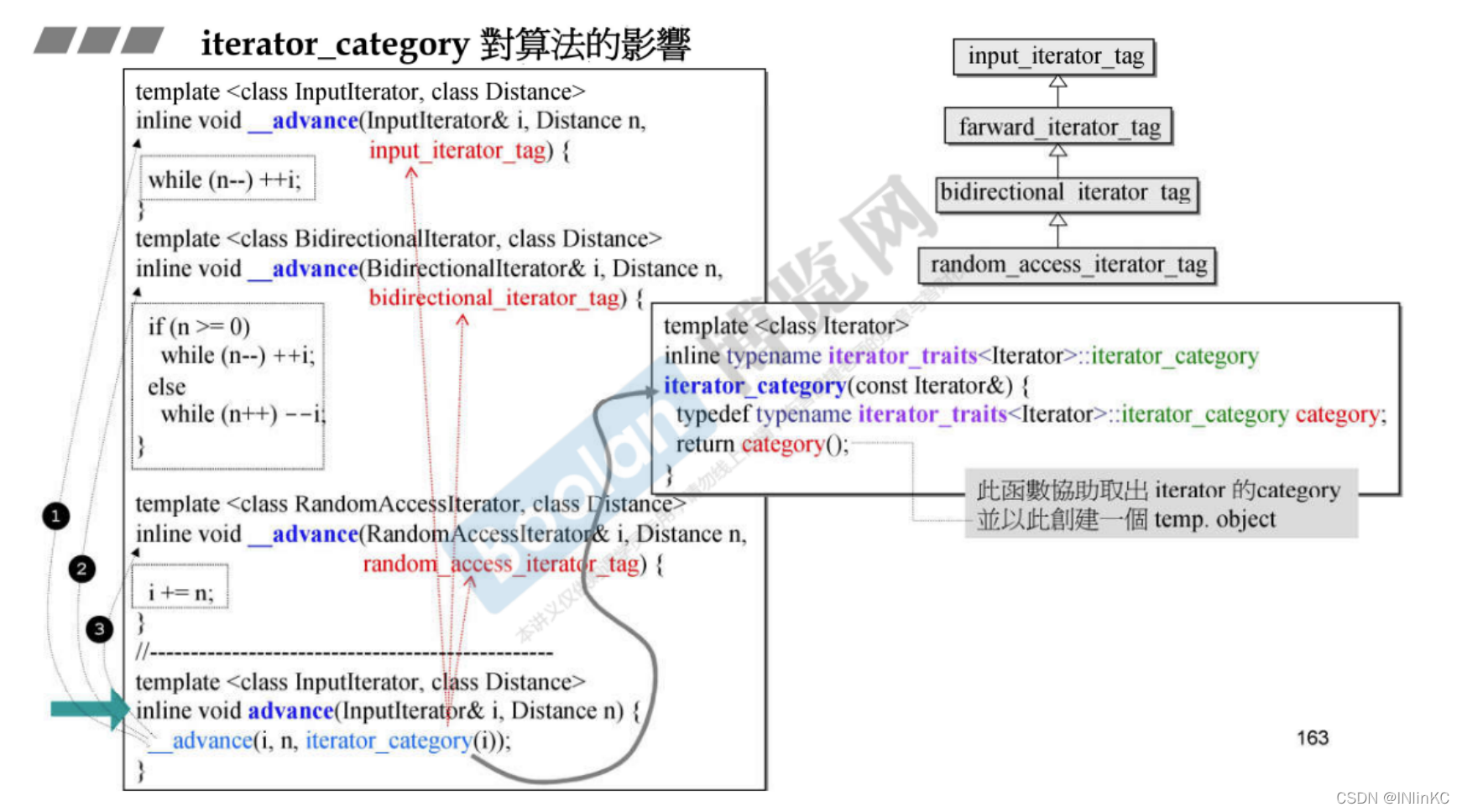
copy
copy Used many generalization and specialization , except iterator traits Besides type traits.
copy For its template The conditions required by the parameters are very loose . The input range only needs to be determined by inputIterators Just form , The output interval only needs to be determined by OutputIterator Just form . This means it can be used copy Algorithm , The contents of any section of any container , Copy to any section of any container 
destory( and copy The approximate , A little )

3. Special case of iterators
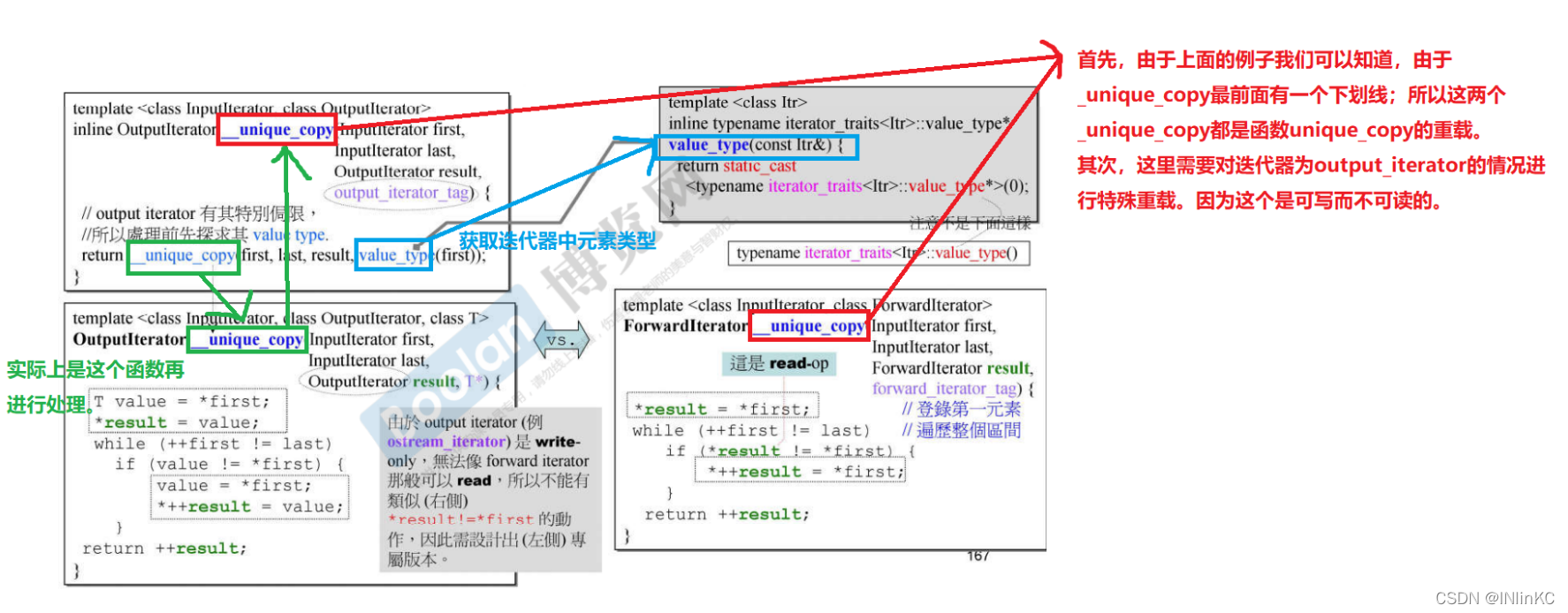
4. Algorithm for iterators iterator_category A hint of
Because the algorithm must accept all iterators , But the algorithm itself can choose not to deal with it . For iterators that these algorithms don't want to deal with , The algorithm will give some hints in the source code .
For example, the template parameter name has been specially modified here , To indicate the scope of application of this algorithm 
2. Algorithm example
Q: How to judge is C Our algorithm is still C++ Algorithm in ?
A: First C++ The algorithm should be in the standard library std in , Next, check its formal parameters ,C++ You need to accept at least two parameters to represent the iterator .

Eleven algorithms
13. functor functor
1.functor brief introduction
functor Serve the algorithm , When the algorithm needs some additional criteria , We use affine functions to assist in the implementation of the algorithm .
2. Give Way functor integrate into STL, Allowed to be adapter reform
We can write what we need functor, But if we want to include it STL, Allowed to be adapter reform
Then we must follow STL The specification of , Let it inherit something .
14. Adapter adapter
1. Adapter introduction
The adapter is in STL The flexible combination and application of components is functional , Acting as a bearing 、 The role of the converter
STL Among the various adapters provided :
1) Change the functor interface , Called function adapter ;
2) Change the container interface , Called container adapter ;
3) Change the iterator interface , Called iterator adapter
For function adapters , The adapter also needs to get some information about the corresponding functor .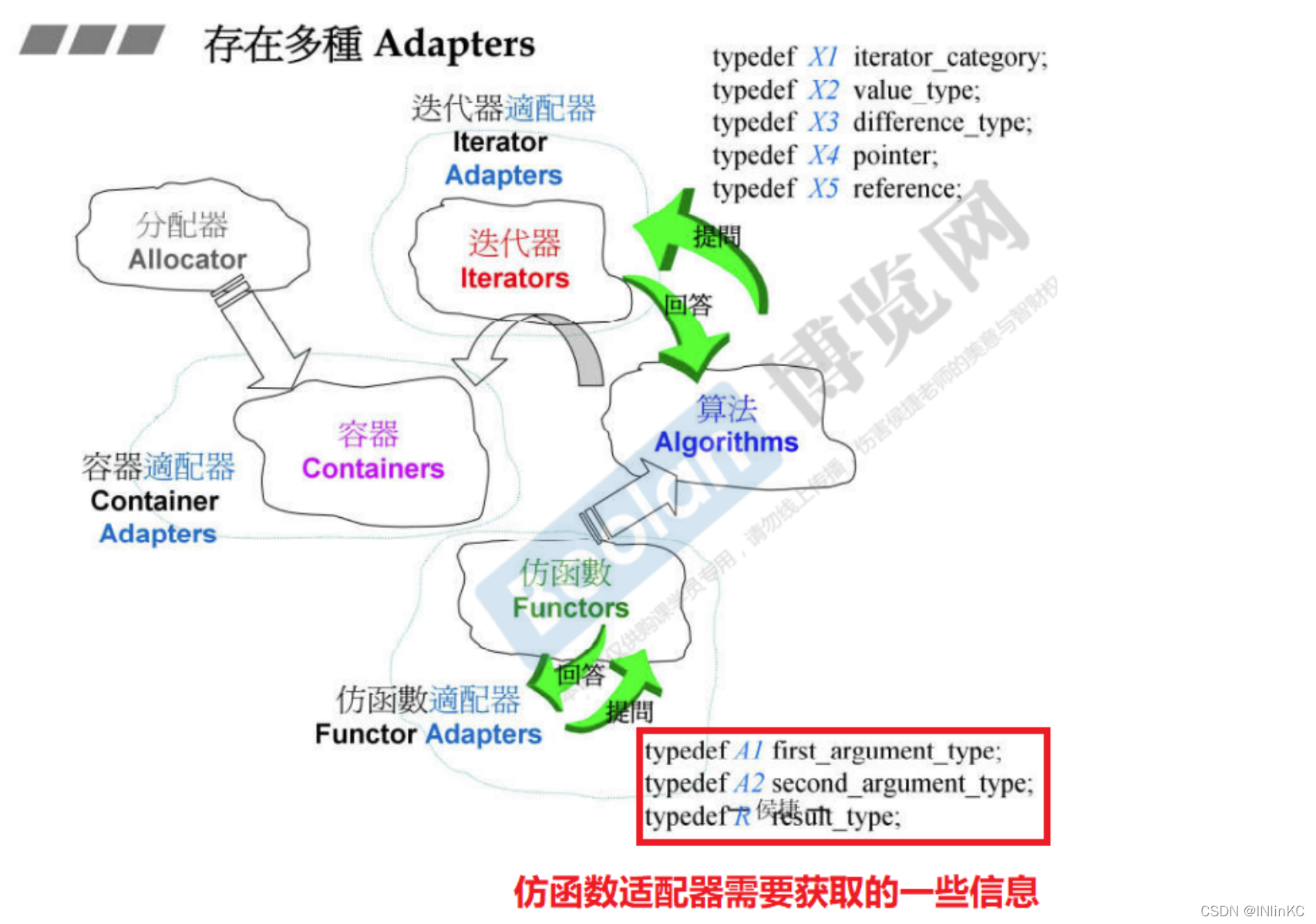
2. Container adapter
STL Provide two container adapters :queue and stack, They decorate deque And generate a new container style stack The bottom layer is composed of deque constitute .
stack Blocked all deque External interface , Only open in line with stack Several functions of the principle
queue The bottom layer of is also made up of deque constitute .queue Blocked all deque External interface , Only open in line with queue Several functions of the principle 
3. function adaptor

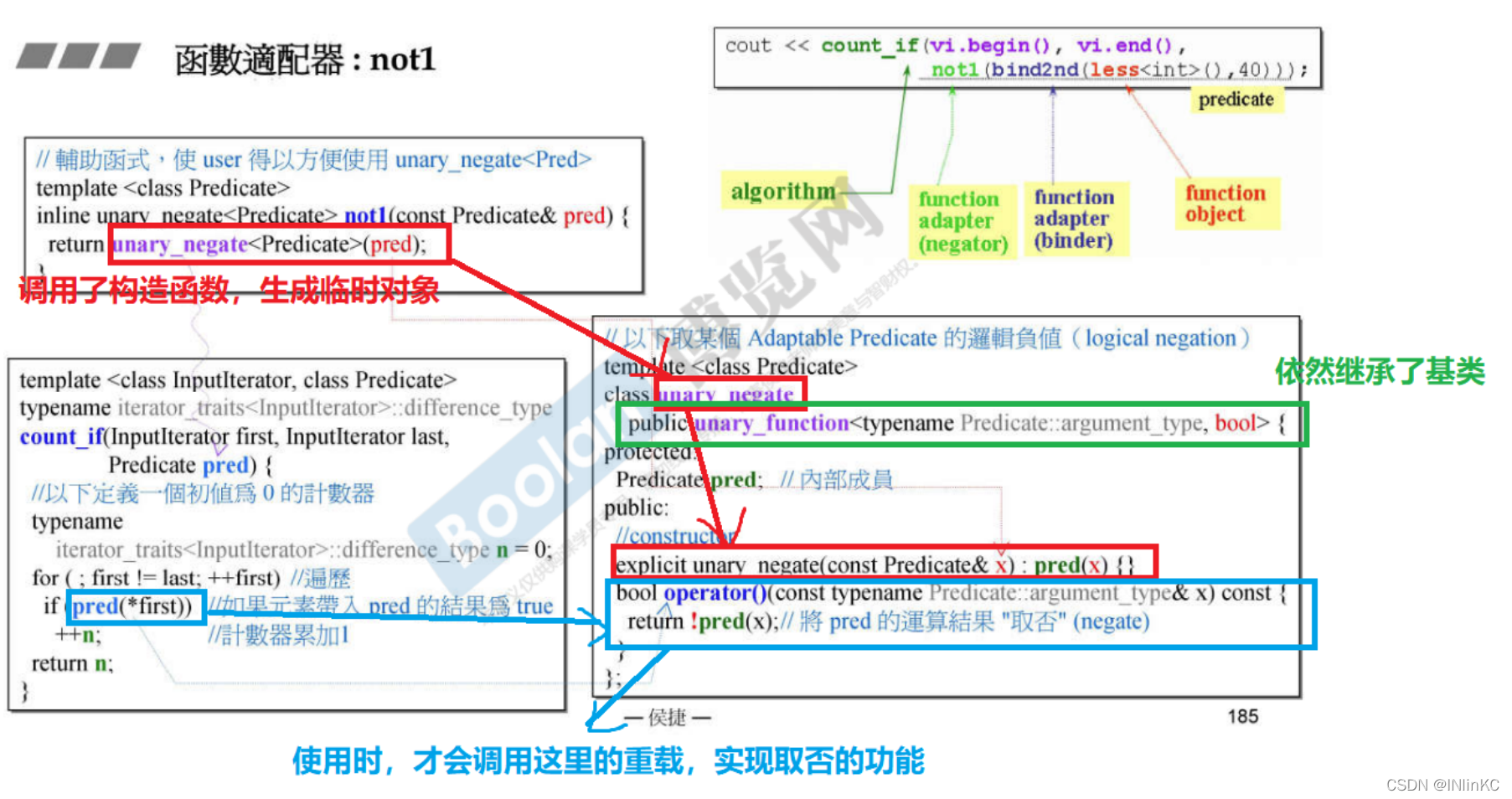
1.bind2nd
from bind2nd This function , We can see some cleverness of the function adapter
Here first review some pre knowledge
For templates , We know :
1. For class templates , It must indicate the type of element in the class , It cannot be deduced by the class itself
2. For function templates , It has the ability to deduce the type of parameters passed in by itself .
vector<int> vec; // This int Indicates that we must declare the element type in the class
max(1,2); // Even if we don't declare parameters 1 and 2 The type of , function max It can also automatically deduce their types for us .

2.not1
3.bind And placeholders (C++ 11)
stay C++11 in , Some of the previous adapters have been replaced , Pictured 
4. Iterator adapter
1.reverse_iterator
It can be called through a bidirectional sequential container rbegin(), and rend() To get the corresponding inverse iterator . As long as the bidirectional sequential container provides begin(),end(), its rbegin() and rend() It's like the following form .
One way sequential container slist Not to be used reserve iterators. Some containers like stack、queue、priority_queue It does not provide begin(),end(), Of course, there is no rbegin() and rend()
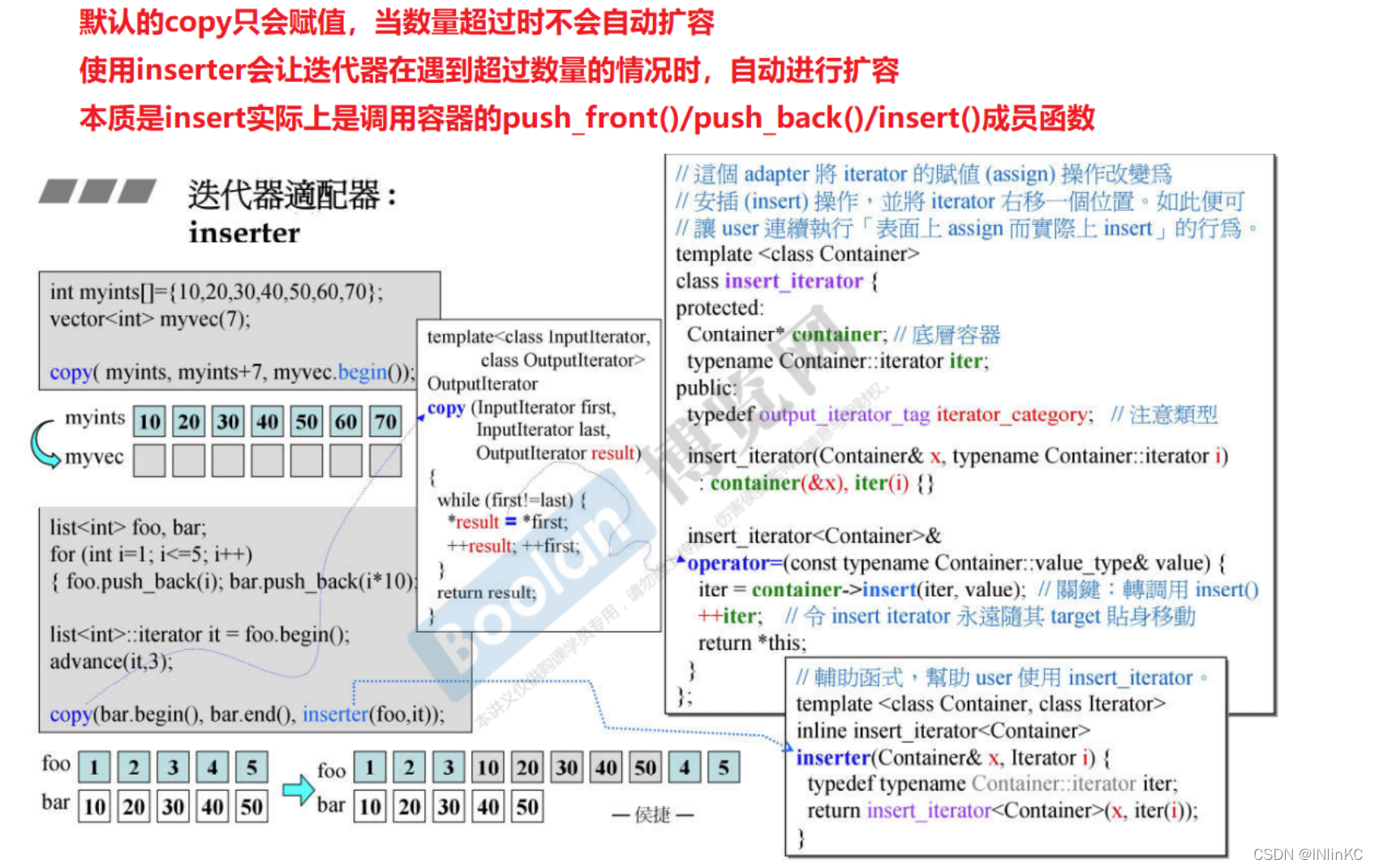
2.insert_iterator
insert iterators: The general iterative assignment operation can be transformed into an insertion operation , It can be divided into the following
insert iterators The main idea of realization is : every last insert iterators There is a container inside ( Must be specified by the user ); Containers, of course, have their own iterators , therefore , When the client insert iterators When doing the assignment operation , It's just insert iterators To insert the iterator of the container ( in other words , Call the... Of the underlying container push_front() or push_back() or insert())
insert iterator
effect
back_insert_iterator
Specially responsible for the insertion of the tail end
front_insert_iterator
Specially responsible for the insertion of the head
insert_iterator
You can insert from anywhere
5. Unknown adapter
iostream_iterator Strictly speaking, it does not belong to any of the above adapters , So we call it “ Unknown adapter ”
1.ostream_iterator

2.istream_iterator

15.STL Peripheral technology and application of
1. A versatile hash operation
In the hash table chapter , We mentioned that we need to provide a hash operation method to calculate hashcode, And the result of this hash operation should be as unordered as possible .
that C++ Is there such a function built-in , It is convenient to calculate the hash value for us ?
We can think roughly like this : No matter what classes we define ourselves , The basic data types in these classes are common , for instance int,string wait , If you can hash them one by one , This hash expression is a universal hash operation ? This function will be introduced below .
2.tuple
1.tuple brief introduction
tuple yes C++11 Types in the new standard . It's a similar pair Template of type .pair Type is each member variable can be any type , But there can only be two members , and tuple And pair The difference is that it can have any number of members . But every certain tuple The number of members of a type is fixed .
operation
explain
make_tuple(v1,v2,v3,v4…vn)
Returns an initialized with a given initial value tuple, The type is inferred from the initial value
t1 == t2
2 individual tuple Returns when there are the same number of members and the members correspond to the same true
get(t)
return t Of the i Data members
tuple_size::value
tuple Number of members in
tuple_element::type
return tuple pass the civil examinations i The type of the first element
2.tuple Realization
tuple The key to success is to use C++ Variable template parameters for , To achieve this layer by layer inheritance relationship .
3.type traits
1.type traits brief introduction
stay G2.9 in , If we want to use type traits, Then we need to adopt template specialization , then typedef A lot of attributes , It is used to ensure that when the algorithm asks in the future, it can answer .
The problem is conceivable , There are too many attributes , It's lengthy to write 
notes :POD The type is C++ Common concepts in , Used to describe a class / The properties of the structure , Specifically, it refers to classes designed without the idea of face objects / Structure .POD The full name is Plain Old Data,Plain It shows that it is a common type , There is no virtual function, virtual inheritance and other features ;Old Indicates that it is related to C compatible .
See here for details C++ Medium POD type
stay C++11 in , these type traits Become more , As many as a few dozen , So for our own classes , Want to use type traits It becomes more lengthy ; But in C++11 in , Not only C++ The built-in class can automatically provide the built-in type traits, Even our own classes can automatically provide the correct type traits result , We no longer need to write it ourselves , How can this be achieved ?

2.type traits Realization
For some simple traits, You can find the source code , It is realized through template specialization

Then for some complex type traits, Cannot be in C++ Find... In the standard library , The guess is derived by the compiler during runtime

4.cout
cout The reason why so many kinds of objects can be accepted , Because the standard pair operator << Made a lot of overloads 
If the object of the class we write ourselves wants to print , You need to be right << Overload 
5.std::move
c++ And std::move Principle implementation and Usage Summary
c++ L-value reference and right value reference
Reference
1.arkingc/note
2.C Chinese language network
3. Share more e-books and video materials
4.C++ Detailed explanation of memory allocation IV :std::alloc Behavioral profiling
5.C++11 Placeholder for new features -std::placehoders
6. Interview questions :C++vector Dynamic expansion of , Why? 1.5 Times or 2 times
7.C++ Virtual function table , Virtual pointer , Distribution of memory
8.C++ in tuple type
9.C++ Medium POD type
10.c++ And std::move Principle implementation and Usage Summary
11.c++ L-value reference and right value reference
12. Interview questions :C++vector Dynamic expansion of , Why? 1.5 Times or 2 times ?
边栏推荐
猜你喜欢
Linear regression of introduction to deep learning (pytorch)

A complete mall system
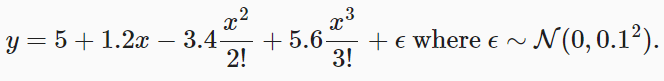
神经网络入门之模型选择(PyTorch)

6、 Data definition language of MySQL (1)

The imitation of jd.com e-commerce project is coming

Raspberry pie 4B installs yolov5 to achieve real-time target detection
侯捷——STL源码剖析 笔记
一个30岁的测试员无比挣扎的故事,连躺平都是奢望

Leetcode - the k-th element in 703 data flow (design priority queue)

Adaptive Propagation Graph Convolutional Network
随机推荐
Leetcode - 705 design hash set (Design)
Introduction to deep learning linear algebra (pytorch)
Leetcode skimming ---263
Tensorflow—Neural Style Transfer
What useful materials have I learned from when installing QT
Leetcode刷题---977
Leetcode - 5 longest palindrome substring
Leetcode skimming ---367
What did I read in order to understand the to do list
The imitation of jd.com e-commerce project is coming
A super cool background permission management system
深度学习入门之线性回归(PyTorch)
I really want to be a girl. The first step of programming is to wear women's clothes
神经网络入门之模型选择(PyTorch)
Type de contenu « Application / X - www - form - urlencoded; Charset = utf - 8 'not supported
Powshell's set location: unable to find a solution to the problem of accepting actual parameters
A complete mall system
Leetcode skimming ---35
[LZY learning notes dive into deep learning] 3.1-3.3 principle and implementation of linear regression
Several problems encountered in installing MySQL under MAC system